EM算法原理解释及公式推导 |
您所在的位置:网站首页 › em算法的e步 › EM算法原理解释及公式推导 |
EM算法原理解释及公式推导
|
本文参考的是 人人都懂EM算法 - August的文章 - 知乎 这篇文章 目录 一、极大似然概述 二、EM算法 2.1 EM算法描述 2.2 EM公式推导 三、EM算法案例 一、极大似然概述假设我们需要调查我们学校学生的身高分布。我们先假设学校所有学生的身高服从正态分布 学校的学生这么多,我们不可能挨个统计吧?这时候我们需要用到概率统计的思想,也就是抽样,根据样本估算总体。假设我们随机抽到了 200 个人(也就是 200 个身高的样本数据,为了方便表示,下面“人”的意思就是对应的身高)。然后统计抽样这 200 个人的身高。根据这 200 个人的身高估计均值 用数学的语言来说就是:为了统计学校学生的身高分布,我们独立地按照概率密度 那么问题来了怎样估算参数 问题一:抽到这 200 个人的概率是多少呢? 由于每个样本都是独立地从
n 为抽取的样本的个数,本例中 n=200 ,这个概率反映了,在概率密度函数的参数是 这个函数反映的是在不同的参数 对 L 取对数,将其变成连加的,称为对数似然函数,如下式:
Q:这里为什么要取对数? 取对数之后累积变为累和,求导更加方便概率累积会出现数值非常小的情况,比如1e-30,由于计算机的精度是有限的,无法识别这一类数据,取对数之后,更易于计算机的识别(1e-30以10为底取对数后便得到-30)。问题二:学校那么多学生,为什么就恰好抽到了这 200 个人 ( 身高) 呢? 在学校那么学生中,我一抽就抽到这 200 个学生(身高),而不是其他人,那是不是表示在整个学校中,这 200 个人(的身高)出现的概率极大啊,也就是其对应的似然函数
问题三:那么怎么极大似然函数? 求 极大似然估计总结 极大似然估计你可以把它看作是一个反推。多数情况下我们是根据已知条件来推算结果,而极大似然估计是已经知道了结果,然后寻求使该结果出现的可能性极大的条件,以此作为估计值。 比如说, 假如一个学校的学生男女比例为 9:1 (条件),那么你可以推出,你在这个学校里更大可能性遇到的是男生 (结果);假如你不知道那女比例,你走在路上,碰到100个人,发现男生就有90个 (结果),这时候你可以推断这个学校的男女比例更有可能为 9:1 (条件),这就是极大似然估计。极大似然估计,只是一种概率论在统计学的应用,它是参数估计的方法之一。说的是已知某个随机样本满足某种概率分布,但是其中具体的参数不清楚,通过若干次试验,观察其结果,利用结果推出参数的大概值。 极大似然估计是建立在这样的思想上:已知某个参数能使这个样本出现的概率极大,我们当然不会再去选择其他小概率的样本,所以干脆就把这个参数作为估计的真实值。 求极大似然函数估计值的一般步骤: (1)写出似然函数; (2)对似然函数取对数,并整理; (3)求导数,令导数为 0,得到似然方程; (4)解似然方程,得到的参数。 二、EM算法 2.1 EM算法描述 上面我们先假设学校所有学生的身高服从正态分布 简单啊,我们可以随便抽 100 个男生和 100 个女生,将男生和女生分开,对他们单独进行极大似然估计。分别求出男生和女生的分布。 假如某些男生和某些女生好上了,纠缠起来了。咱们也不想那么残忍,硬把他们拉扯开。这时候,你从这 200 个人(的身高)里面随便给我指一个人(的身高),我都无法确定这个人(的身高)是男生(的身高)还是女生(的身高)。用数学的语言就是,抽取得到的每个样本都不知道是从哪个分布来的。那怎么办呢? 这个时候,对于每一个样本或者你抽取到的人,就有两个问题需要估计了,一是这个人是男的还是女的,二是男生和女生对应的身高的正态分布的参数是多少。这两个问题是相互依赖的: 当我们知道了每个人是男生还是女生,我们可以很容易利用极大似然对男女各自的身高的分布进行估计。反过来,当我们知道了男女身高的分布参数我们才能知道每一个人更有可能是男生还是女生。例如我们已知男生的身高分布为但是现在我们既不知道每个学生是男生还是女生,也不知道男生和女生的身高分布。这就成了一个先有鸡还是先有蛋的问题了。鸡说,没有我,谁把你生出来的啊。蛋不服,说,没有我,你从哪蹦出来啊。为了解决这个你依赖我,我依赖你的循环依赖问题,总得有一方要先打破僵局,不管了,我先随便整一个值出来,看你怎么变,然后我再根据你的变化调整我的变化,然后如此迭代着不断互相推导,最终就会收敛到一个解(草原上的狼和羊,相生相克)。这就是EM算法的基本思想了。 EM的意思是“Expectation Maximization”,具体方法为: 先设定男生和女生的身高分布参数(初始值),例如男生的身高分布为总结 上面的学生属于男生还是女生我们称之为隐含参数,女生和男生的身高分布参数称为模型参数。 EM 算法解决这个的思路是使用启发式的迭代方法,既然我们无法直接求出模型分布参数,那么我们可以先猜想隐含参数(EM 算法的 E 步),接着基于观察数据和猜测的隐含参数一起来极大化对数似然,求解我们的模型参数(EM算法的M步)。由于我们之前的隐含参数是猜测的,所以此时得到的模型参数一般还不是我们想要的结果。我们基于当前得到的模型参数,继续猜测隐含参数(EM算法的 E 步),然后继续极大化对数似然,求解我们的模型参数(EM算法的M步)。以此类推,不断的迭代下去,直到模型分布参数基本无变化,算法收敛,找到合适的模型参数。 2.2 EM公式推导2.2.1 凸函数定义: 设是定义在实数域上的函数,如果对于任意的实数,都有:
那么是凸函数。若不是单个实数,而是由实数组成的向量,此时,如果函数的 Hesse 矩阵是半正定的,即:
是凸函数。特别地,如果 2.2.2 Jensen不等式 如下图,如果函数 特别地,如果函数 2.2.3 期望 对于离散型随机变量 X 的概率分布为
若连续型随机变量X的概率密度函数为 以上讲的是基础知识,如果不熟悉的同学可以再复习一下概率论。 2.2.4 EM算法推导 对于 m 个相互独立的样本 假如没有隐含变量 增加隐含变量 这里的 不就是多了一个隐变量 理论上是可行的,然而如果对分别对未知的
上面第(1)式引入了一个未知的新的分布
第(2)式用到了 Jensen 不等式 (对数函数是凹函数):
也就是说
上式我实际上是我们构建了 假设
其中: 边缘概率公式: 条件概率公式: 从上式可以发现 如果
至此,我们推出了在固定参数 去掉上式中常数的部分
2.2.5 EM 算法流程 输入:观察数据 1) 随机初始化模型参数 2)
输出:模型参数 假设有两枚硬币A、B,以相同的概率随机选择一个硬币,进行如下的掷硬币实验:共做 5 次实验,每次实验独立的掷十次,结果如图中 a 所示,例如某次实验产生了H、T、T、T、H、H、T、H、T、H (H代表正面朝上)。a 是在知道每次选择的是A还是B的情况下进行,b是在不知道选择的是A还是B的情况下进行,问如何估计两个硬币正面出现的概率?
a 情况: 已知每个实验选择的是硬币A 还是硬币 B,重点是如何计算输出的概率分布,这其实也是极大似然求导所得。
b情况: 由于并不知道选择的是硬币 A 还是硬币 B,因此采用EM算法。 E步:初始化
计算出每个实验为硬币 A 和硬币 B 的概率,然后进行加权求和。 M步:求出似然函数下界
针对L函数求导来对参数求导,例如对
求导等于 0 之后就可得到图中的第一次迭代之后的参数值:
当然,基于Case a 我们也可以用一种更简单的方法求得:
第二轮迭代:基于第一轮EM计算好的
|
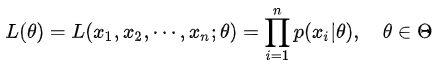
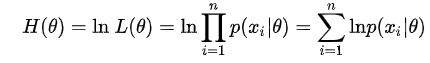
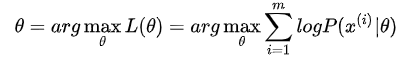

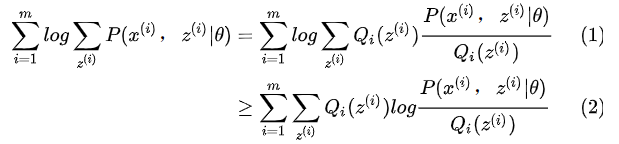

 其中:
其中:
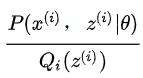 为第 i 个样本,
为第 i 个样本, 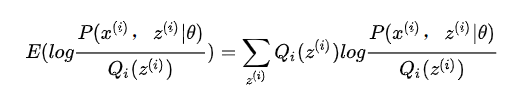
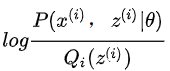 的加权求和,由于上面讲过权值
的加权求和,由于上面讲过权值 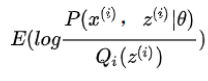 是
是  其中 c 为常数,对于任意
其中 c 为常数,对于任意  由于
由于  。 从上面两式,我们可以得到:
。 从上面两式,我们可以得到: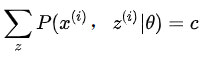



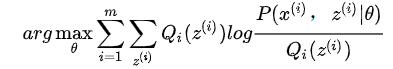
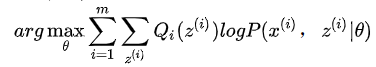
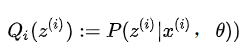

 上面这个式子求导之后发现,5 次实验中A正面向上的次数再除以总次数作为即为
上面这个式子求导之后发现,5 次实验中A正面向上的次数再除以总次数作为即为 
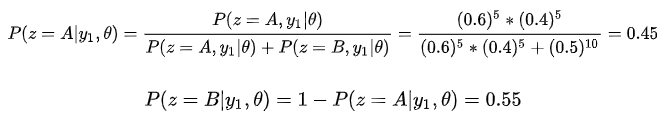



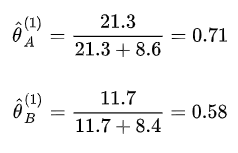
【本文地址】
今日新闻 |
推荐新闻 |