MoCo、SimCLR、BYOL、SwAV、iBot、DiNoV2、MAE、Beit、SimMIM、MaskFeat对比学习总结 |
您所在的位置:网站首页 › edition与moco › MoCo、SimCLR、BYOL、SwAV、iBot、DiNoV2、MAE、Beit、SimMIM、MaskFeat对比学习总结 |
MoCo、SimCLR、BYOL、SwAV、iBot、DiNoV2、MAE、Beit、SimMIM、MaskFeat对比学习总结
|
CPC(Representation Learning with Constrastive Predictive Encoding)
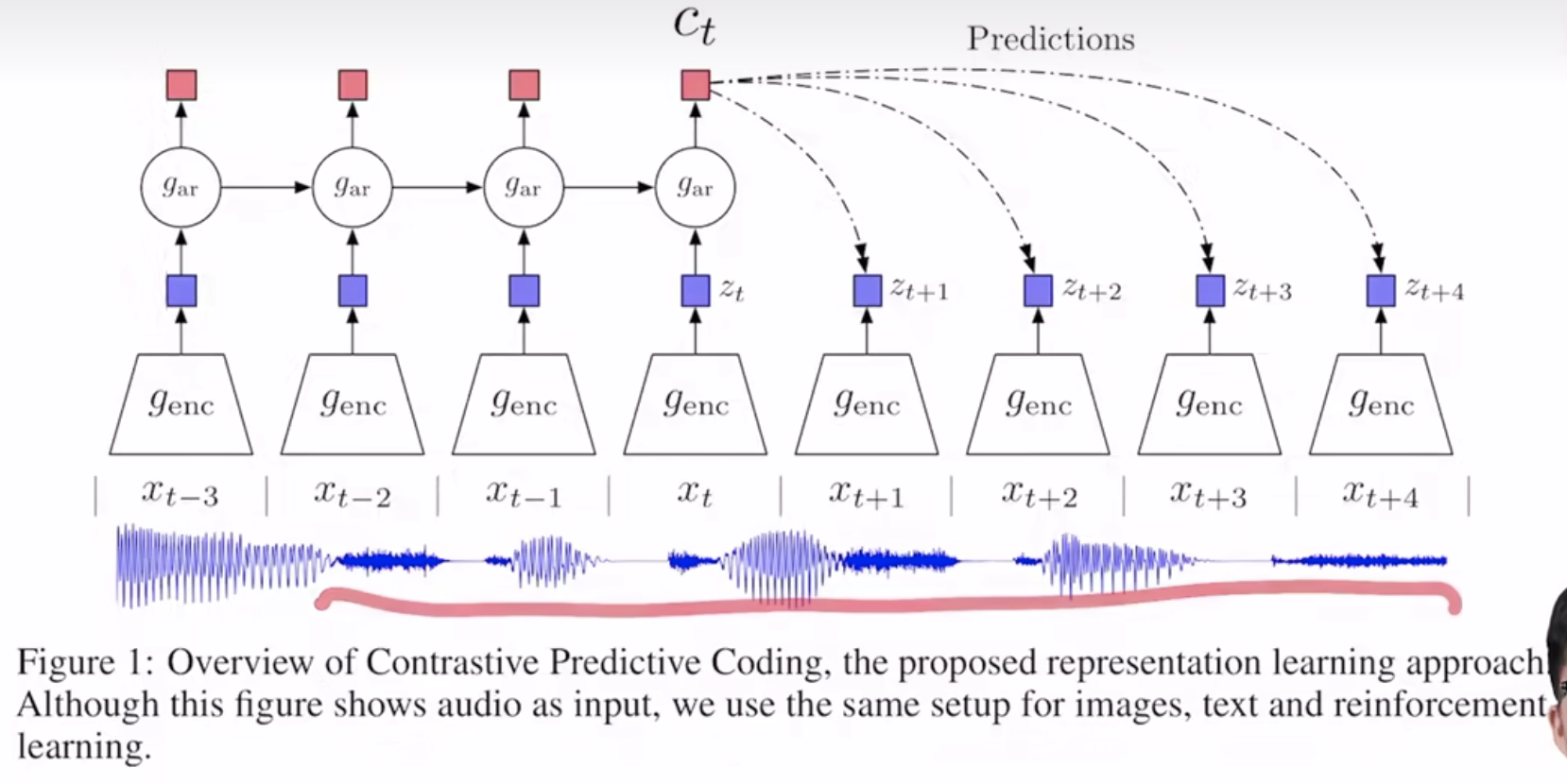
时间序列预测的代理任务
MoCo的想法主要是在之前end-to-end和memory bank基础上产生的。q表示query,也就是对比的left;k表示key,也就是对比的right,k中既包含和q相似的样本(可能会标记为k+),也包含也q不相似的样本 关于end-to-end方式(The end-to-end update by back-propagation is a natural mechanism. It uses samples in the current mini-batch as the dictionary, so the keys are consistently encoded (by the same set of encoder parameters). But the dictionary size is coupled with the mini-batch size, limited by the GPU memory size. It is also challenged by large mini-batch optimization),实际上就是编码器q和k都可以通过梯度回传来传递参数,q和k都是在一个mini-batch中生成的,q和k可以用相同的编码器也可以用不同的编码器。因此end-to-end模式中字典大小和mini-batch size是等价的,受限于字典大小。SimCLR本质上也是一种end-to-end的方式,SimCLR用了更多的数据增量方式,而且提出在编码器后加一个projector,可以让效果大大编号。同时google的TPU可以把batch size调到8192,这是SimCLR普通人玩不起的。。。 memory bank会把整个数据集的特征都存到内存中,但是更新每次只能更新q的梯度,每次从memory bank里随机抽样一些key并且更新,但是这样的话大的bank里key不够一致。 因此MoCo主要两个contribution:1. Momentum解决memory bank不一致的问题,而且每次要给一个大的动量,实验测比如m=0.999;2. 用一个大的dictionary,通过一个动态queue来实现dictionary 另外MoCo在对下游任务做微调时,learning rate居然到30。。。如果和有监督的样本空间差别非常大 MoCo选择instance discrimination(个体判别,判断两张图是不是同一个东西)作为pretext tasks(代理任务,还有其他代理任务例如CPC【contrastive predictive coding,预测性对比学习,通过上下文信息来预测未来】和CMC【contrastive multiview coding,通过不同视角来进行对比,例如图片上色】),使用InfoNCE(Noise Contrastrive Estimation,两类,数据和噪声分两类;但是等到了InfoNCE就不止两类了,变成多类了,就这么点区别。注意NCE是要对噪声进行采样的,但是从形式上看和cross entropy loss区别只是一个是类别个数,另外一个是负样本个数)作为Loss Function。 这个视频讲解比较好 MoCo 论文逐段精读 - 知乎 截图贴一下MoCo V1的伪代码:
1. 在末端用了非线性映射
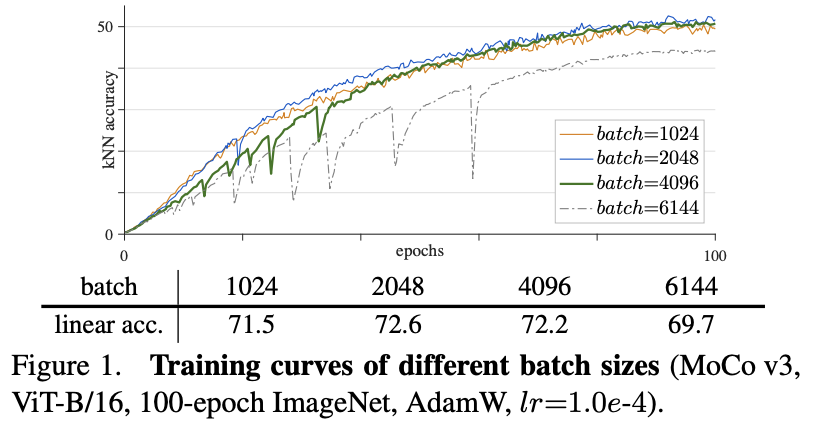
2. 改进为扩充了一种数据增强方式,SimCLR 使用了模糊增强,于是 MoCo v2 也将此加入了增强集 3. 文章还采用了余弦学习率表(cosine learning rate schedule) MoCo V31. 换了vit,如果把vit的patch embedding层给冻住,训练的稳定性会提升 2. MoCo v3采用了同一batch中的case作为key,取代之前版本中使用的memory queue。实验发现在batch size(4096)足够大的时候,两者的差异就很小。在MoCo V1的时候,负样本的字典大小是65536,等到了MoCo V3的时候作者发现构造又大又一致的字典其实也没必要达到65536(在MoCo v1里也有这个消融实验,MoCo V1大了效果更好),有4096效果就够了,因此在MoCo V3的时候就把那个作为保持一致性的queue给扔了,直接用同一个batch中的cases做负样本就可以。
3. MoCo V3采用了对称性的loss 截图贴一下MoCo V3的伪代码:
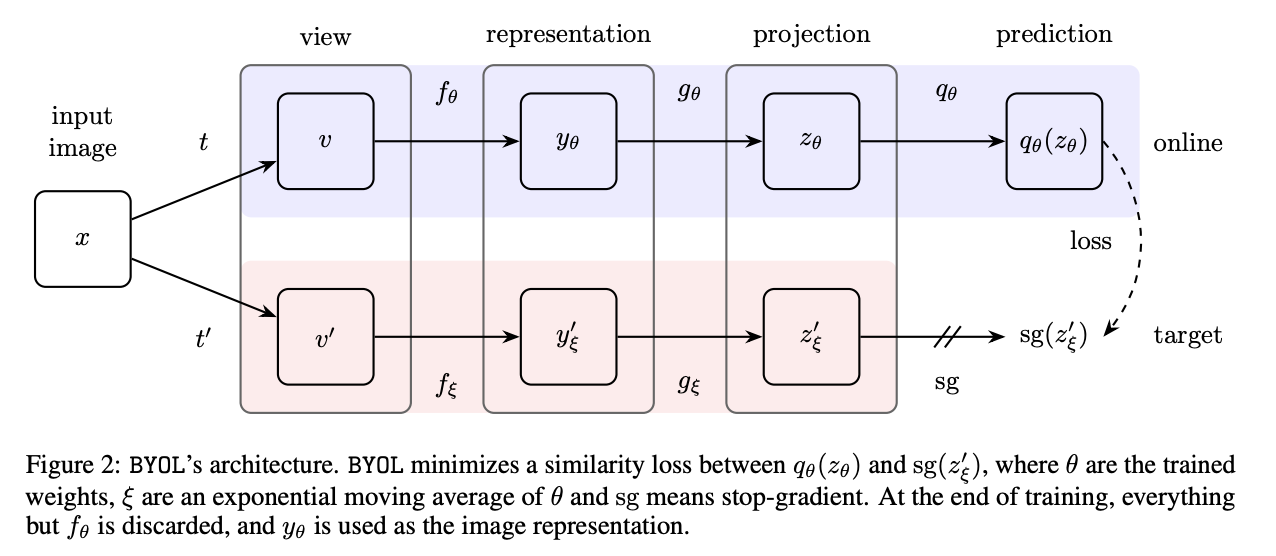
MoCo V1中就使用了Shuffling BN的操作。BN大部分的时候是在当前GPU上算的,使用BN的时候BN的running mean和runnning variance很容易让模型找到正确的解。Shuffling BN就是算之前先把样本顺序打乱,送到多卡上,算完再合在一起 SimCLR(A Simple Framework for Contrastive Learning of Visual Representations)SimCLR本质上也是一种end-to-end的方式,SimCLR用了更多的数据增量方式,而且提出在编码器后加一个projector,可以让效果大大变好。同时google的TPU可以把batch size调到8192,这是SimCLR普通人玩不起的。。。 SimCLRV2(Big Self-Supervised models are strong semi-supervised learners)3个改进: 1. 更大的Resnet 2. MLP更深 3. 用了MoCo的momentum Encoder 对比式自监督图片,没有负样本,MSE loss预测 BYOL(Bootstrap Your Own Latent ) 和SimCLR相比在projection后面又加了一个prediction层,通过自己一个视角的特征去预测另外一个视角的特征。用的loss不同于InfoNCE,而是过了prediction后直接得到两个向量开始算了MSE
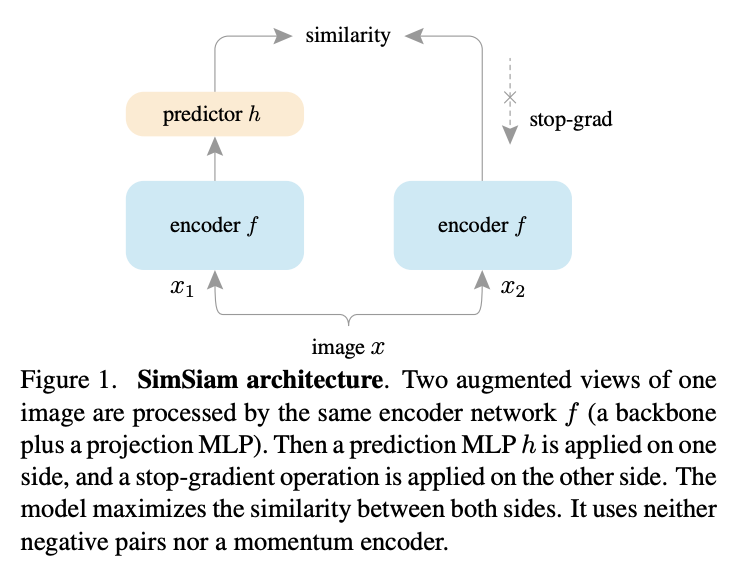
没用负样本,怎么就没坍塌呢?博客Understanding self-supervised and contrastive learning with "Bootstrap Your Own Latent" (BYOL)认为是BN是BYOL的核心,因为BYOL的MLP里有BN。但在BYOL works even without batch statistics中作者实验了下即使SimCLR v2没有BN也不行。 SiaSiam(Exploring Simple Siamese Representation Learning)作者把BYOL抽象了这样一个简单结构,认为BYOL没坍塌的主要原因就是有了stop-grad操作,导致模型更新是劈成两份交替进行的,是一种EM算法。。。
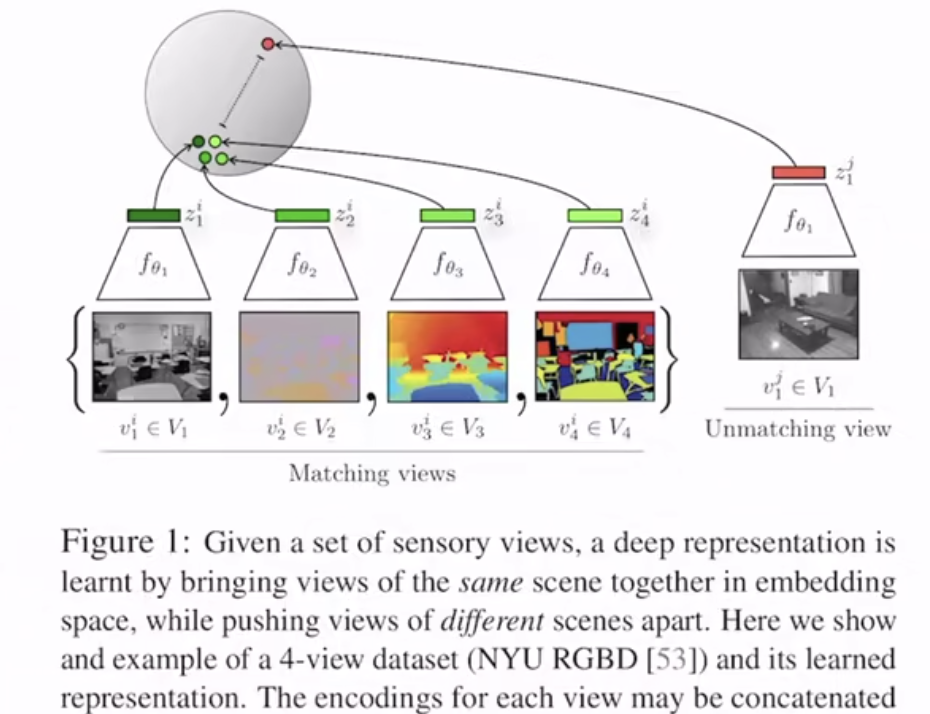
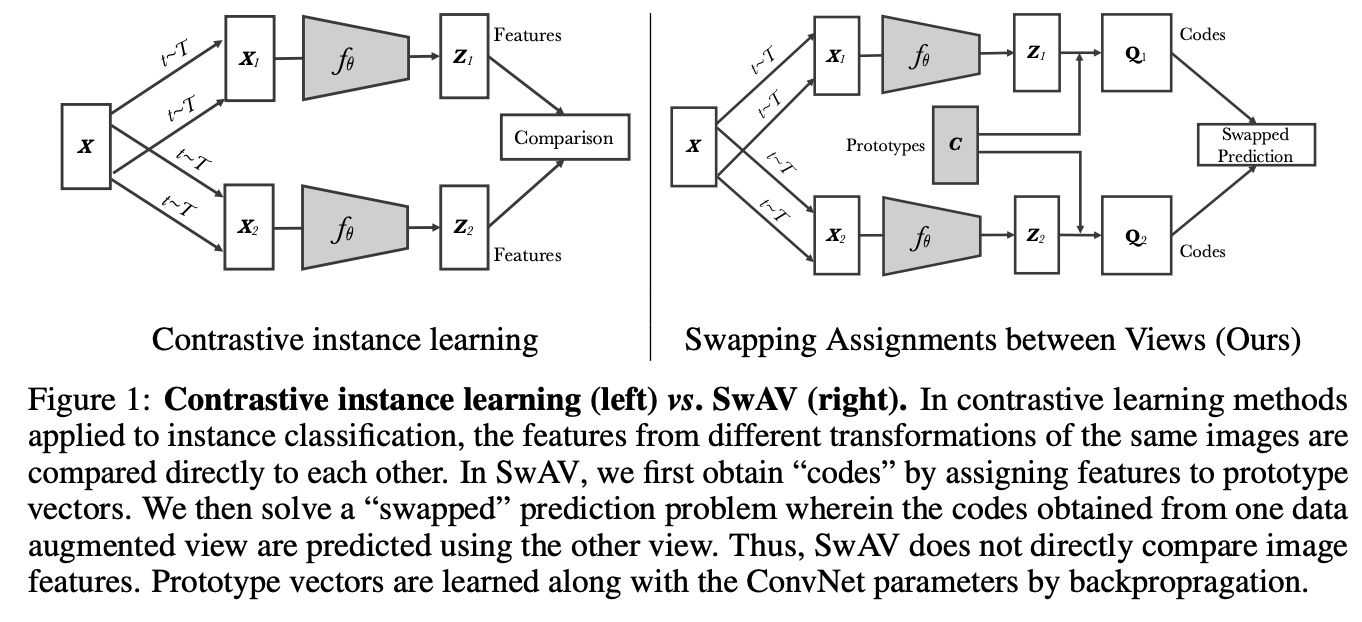
相似的物体聚类在聚类中心,3000个聚类中心相对于几万个负样本小了很多,而且聚类有明确的语义含义,而且负样本不容易采样错,Unsupervised Learning of Visual Features by Contrasting Cluster Assignments
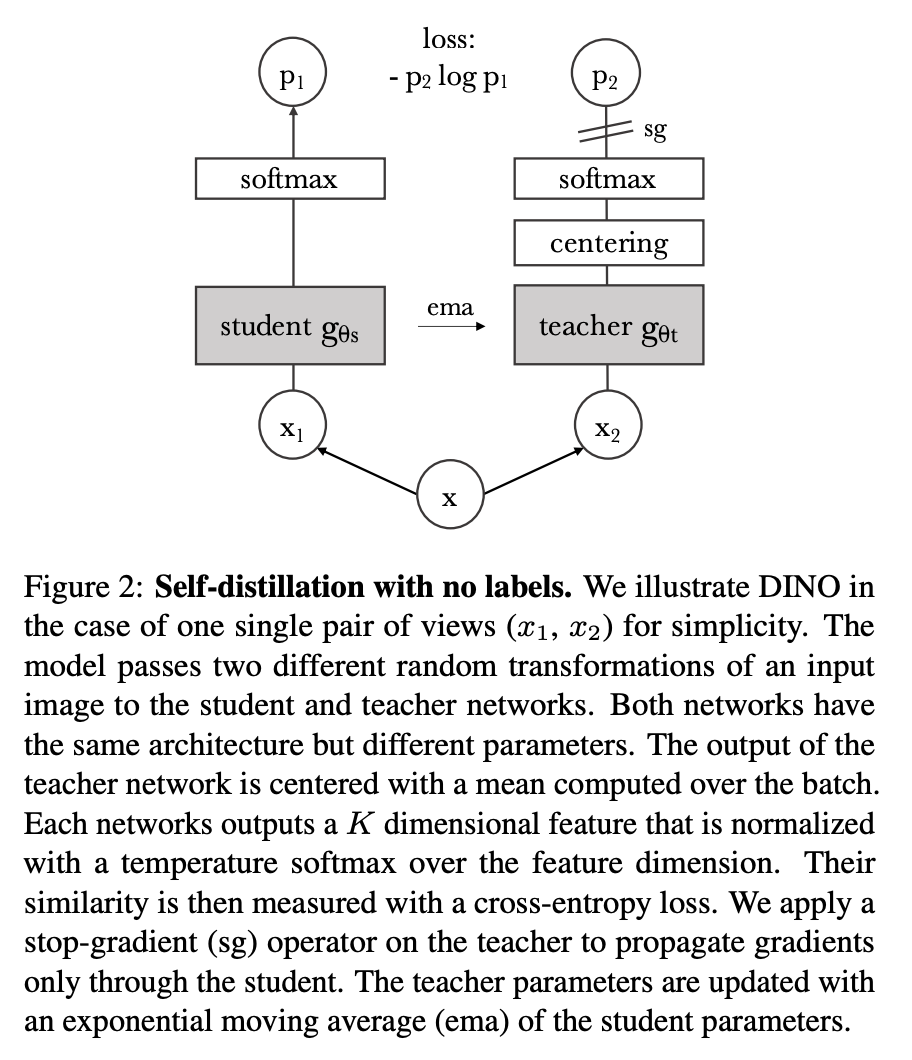
整体结构和BYOL很像,有一个centering这样一个操作,DiNo产生的分割效果很好
由于在DINO的基础上引入了MLM, 因此只能用ViT架构. 原文中使用的是随机波动的mask ratio, 采用的是blockwise mask. 在复现过程中, follow MAE的random mask, mask ratio=0.75也可以大致复现. 总体而言IBOT的idea是DiNo和Beit组合, 由一个distillation loss和一个MIM loss组成: Distillation loss约束teacher网络和student网络的cross-view [CLS] token的一致性MIM Loss则是recover masked token: 用teacher network提取un masked image feature作为target, 而student network提取maksed image feature并尝试recover被mask掉的部分. DiNoV2来自DINOv2: Learning Robust Visual Features without Supervision,摘自原文We learn our features with a discriminative self-supervised method that can be seen as a combination of DINO and iBOT losses with the centering of SwAV。简单点理解就是,这种自监督方法是由多个损失函数组成的,包括 DINO(Transformers之间的局部信息最大化),iBOT(特征之间的相似度最小化)和 SwAV(样本中心化)。同时,添加了一个正则项,以使特征在特征空间中更加均匀地分布。此外,DINOv2 中还进行了一个短暂的高分辨率训练阶段,以进一步提高特征的鲁棒性。 Image-level objective这个方法被称为图像级目标,是一种用于学习特征的判别式自监督方法。其基本思想是将来自同一图像不同裁剪的视图作为正样本,将来自不同图像的视图作为负样本,使用交叉熵损失函数来衡量这些视图之间的相似性和差异性,从而训练一个学生网络。另外,我们使用指数移动平均方法构建一个教师网络,其参数是过去迭代的加权平均值,以减少训练中的波动。最终,我们使用这两个网络的类令牌特征作为特征表示。 Patch-level objective这个方法是另一种用于学习特征的自监督方法,称为 Patch 级目标。在这种方法中,作者将输入的一些 Patch 随机地遮盖掉,只将未被遮盖的 Patch 提供给教师网络,然后使用交叉熵损失函数来衡量学生和教师网络在每个被遮盖的 Patch 上的特征表示的相似性和差异性,从而训练学生网络。同时,我们可以将 Patch 级别的损失与图像级别的损失相结合,以便在训练过程中兼顾整体和局部特征。 Untying head weights between both objectives此方法是针对前两个方法的实验发现进行的改进。在前两个方法中,图像级别和Patch级别的损失函数都共享了一个网络的参数(权重)。但是经过实验观察发现,当两个级别的损失函数共享同样的参数时,模型在Patch级别会欠拟合,在图像级别会过拟合。因此,我们可以考虑将这些参数(权重)解绑,使得模型在两个级别都能够更好地学习特征表示。这个方法的优化目标是在两个级别都得到最佳的结果。 Sinkhorn-Knopp centering这个方法是对 DINO 和 iBot 两种方法中的一些步骤进行改进。在原来的方法中,教师模型中的 softmax-centering 步骤在某些情况下可能导致不稳定性,因此本文采用了 Sinkhorn-Knopp(SK)批量归一化方法来代替。这个方法的核心思想是通过正则化来使学生和教师网络在特征表示上更加接近。在这个方法中,作者使用了 3 次 Sinkhorn-Knopp 算法迭代来实现归一化。对于学生网络,则仍然使用 softmax 归一化。通过这个方法,我们可以更好地训练学生模型,并获得更好的性能。 # Sinkhorn-Knopp centering # scores: batch scores with dim=K def sinkhorn(scores, eps=0.05, niters=3): Q = exp(scores / eps).T Q /= sum(Q) K, B = Q.shape u, r, c = zeros(K), ones(K) / K, ones(B) / B for _ in range(niters): u = sum(Q, dim=1) Q *= (r / u).unsqueeze(1) Q *= (c / sum(Q, dim=0)).unsqueeze(0) return (Q / sum(Q, dim=0, keepdim=True)).T KoLeo regularizerKoLeo regularizer 是一种正则化方法,它通过计算特征向量之间的差异来确保它们在批次内均匀分布。具体来说,它使用了一种名为 Kozachenko-Leonenko 差分熵估计的技术,这是一种估计随机样本密度的方法。在计算这个正则化器之前,特征向量会被进行“2-范数归一化”(将每个向量的所有元素平方和开根号并除以该和),以确保它们具有相同的长度。这个正则化器的作用是减少特征向量之间的差异,从而使它们在整个批次内均匀分布。 这一步主要是涉及在预训练的最后一段时间内,将图像的分辨率提高到 518×518 ,便在下游任务中更好地处理像素级别的信息,例如分割或检测任务。高分辨率的图像通常需要更多的计算资源和存储空间,因此只在预训练的最后阶段使用这种方法,以减少时间和资源成本。 部分摘自https://zhuanlan.zhihu.com/p/623274167 生成式自监督 MAE (Masked Autoencoders Are Scalable Vision Learners)来自Masked Autoencoders Are Scalable Vision Learners,Our loss function computes the mean squared error (MSE) between the reconstructed and original images in the pixel space. 几个关键点: 需要Encoder和Decoder,encoder负责抽取高维表示,decoder则负责细粒度还原比较大的mask比例,甚至达到了75% Beit图像块和 ViT 原文所描述的并无二致,而对于重建目标,BEiT 并没有使用原始的像素,而是通过一个 “image tokenizer” 进行离散化,遵循的是 dVAE 的思路,在 BEiT 预训练之前,先构建 “tokenizer” 和 “decoder” 进行 dVAE 的训练,并构建视觉词汇表。在 BEiT 中是直接采用 Zero-shot text-to-image generation 文章开源的代码进行训练。 对于预训练的主干网络,则是标准的 ViT,每个图像块会被线性投射为对应的 embedding 向量,同时再加上标准的可学习的绝对位置编码。而与之不同的是,BEiT 采用了 Blockwise Masking 的方式,对大约 40% 的图像块进行了掩码操作,而预训练的目标便是期望能够正确预测掩码图像块的视觉标记,从而获得可以提取图像特征向量的编码器。部分摘自https://zhuanlan.zhihu.com/p/475952825 SimMIM/MaskFeatSimMIM:A Simple Framework for Masked Image Modeling Masked Feature Prediction for Self-Supervised Visual Pre-Training 这两篇在结构上十分相似,差距仅在最终的回归目标上 SimMIM 结合了 BEiT 和 MAE 两者的特点,相比 BEiT 不再需要额外的 Tokenizer,相比 MAE 不再需要额外的 decoder 而是仅用一层线性层对图像的 masked patch 进行重建,此外还提供了 SwinV1 和 SwinV2 的实验结果 MaskFeat 与 SimMIM 的结构相同,但在预训练过程中不再使用原始图像的 RGB 值作为回归目标,而是改用图像或视频的Histogram of Oriented Gradients(HOG)特征,相比直接回归 RGB 能涨点 |




【本文地址】