C语言可执行程序到底怎样生成? |
您所在的位置:网站首页 › c语言程序实现过程与生成文件后缀是什么 › C语言可执行程序到底怎样生成? |
C语言可执行程序到底怎样生成?
|
目录 程序的翻译环境 NO1.VS编译器工具 NO2.VS链接器工具 NO3.链接库是什么? 编译 预处理 编译 汇编 链接 符号表 编译阶段符号汇总 汇编生成符号表 链接合并段表和符号表 程序的执行环境 C语言的程序到底是怎样生成的呢?又怎样去执行呢?我们来探索。本篇是讲解编译环境。 在ANSI C(标准C语言)的任何一种实现中,存在两个不同的环境。第一种是翻译环境,在这个环境中源代码.c被转换为可执行的机器指令.exe,第二种是执行环境,它用于实际执行代码。 test.c----->test.i------->test.s----->test.obj----->test.exe
程序的翻译环境同时又分为两个阶段 编译 和 链接
理解图:
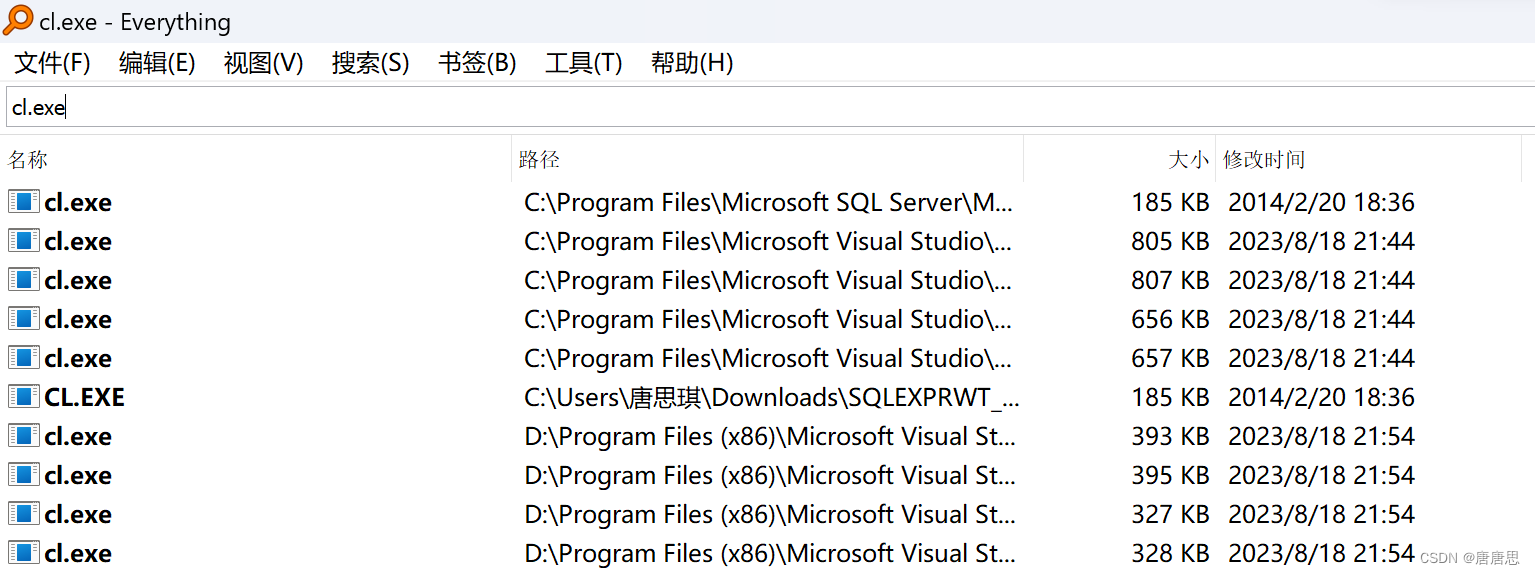
以我们的VS编译器为例子。编译和链接依赖的是什么工具呢? NO1.VS编译器工具 那在我们的VS2022集成开发环境下,VS依赖就是cl.exe这个工具去实现编译这项功能。在windows环境下,生成相应的目标文件test.obj在Linux环境下,生成的目标文件是test.o
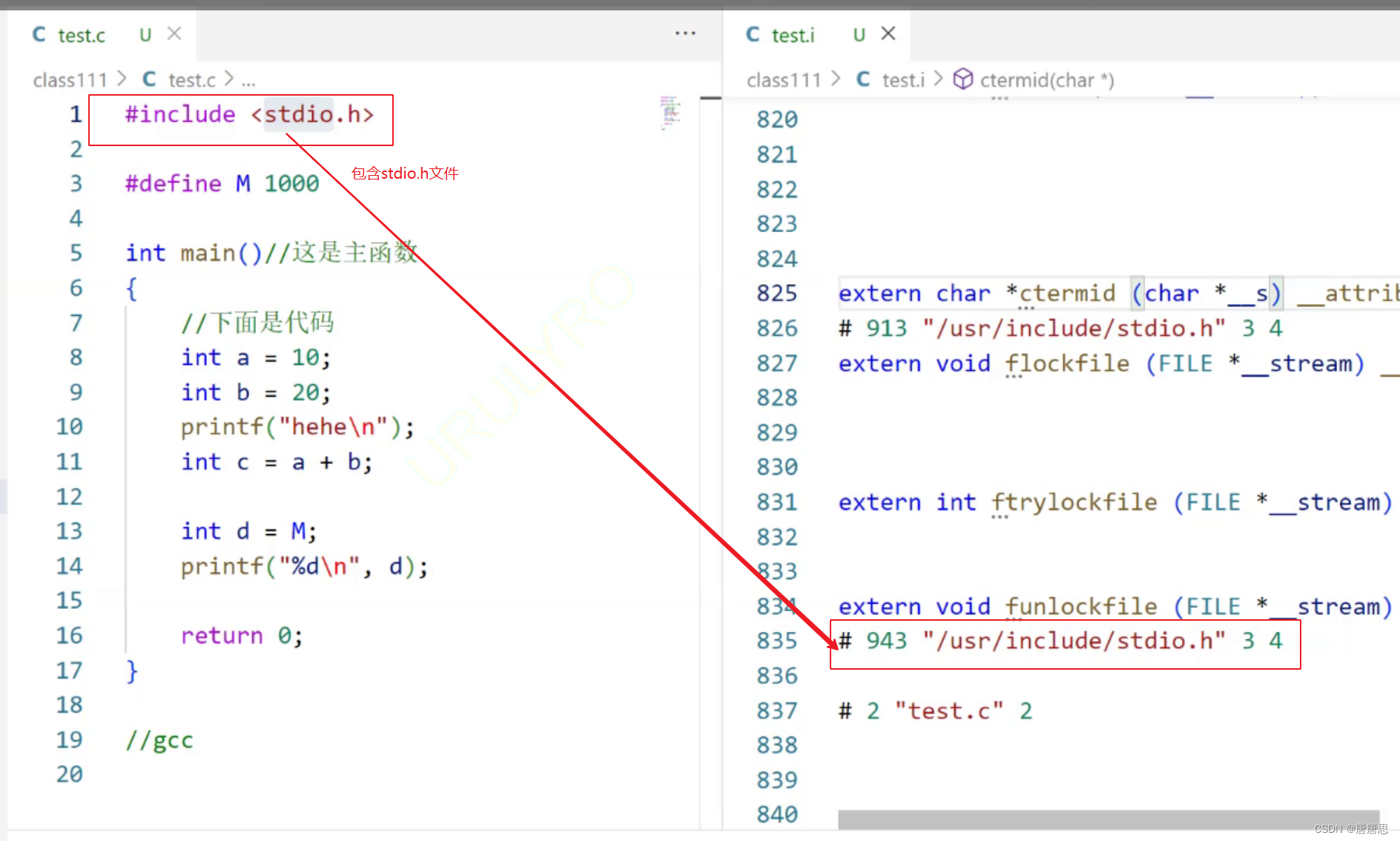
其实编译本身也分为几个阶段:预编译(预处理) 编译 汇编 这三个阶段。我们接下来分别探索一下这三个阶段分别干了什么事情。我们整个过程都在 : Linux环境下,使用gcc编译器去验证整个过程。test.c------->test.i--------->test.s----->test.o(test.obj) 具体要用到的指令: 预处理 选项 gcc -E test.c -o test.i 预处理完成之后就停下来,预处理之后产生的结果都放在test.i文件中。编译 选项 gcc -S test.c 编译完成之后就停下来,结果保存在test.s中。汇编 gcc -c test.c 汇编完成之后就停下来,结果保存在test.o中。 预处理我们想要展示一个预处理的效果,那我们希望预处理之后这个代码就不会往后继续执行了。这里我们要用到一个gcc的指令: -E test.c / test.c -E(预处理之后test.c代码不会往后继续执行) 在我们VS验证之后我们发现我们预处理的文件名为test.i 所以这里在Linux环境下,我们使用gcc指令:-o test.i (把test.c预处理完之后的文件命名为test.i,如果没有指定就直接打印在屏幕上了)
在观察了test.c和test.i两个文件差异我们发现预处理对源代码做了一些文本操作处理的。 注释的替换(删除)。注释被替换成一个空格头文件的包含#include< >#define符号的替换#include和#define这种都是 预处理指令。所有的预处理指令都在预处理阶段处理的。在我们的下篇博客我们也会详细去讲到预处理这个阶段的知识点。 注释的删除
头文件的包含
来到我们的编译阶段,我们想要展示一个编译的效果,那我们希望编译之后这个代码就不会往后继续执行了。这里我们要用到一个gcc的指令: -S test.i / test.i -S(编译之后test.i代码不会往后继续执行) 同时我们也可以使用gcc指令:-o test.s (把test.i编译完之后的文件命名为test.s,如果没有指定也会生成test.s)
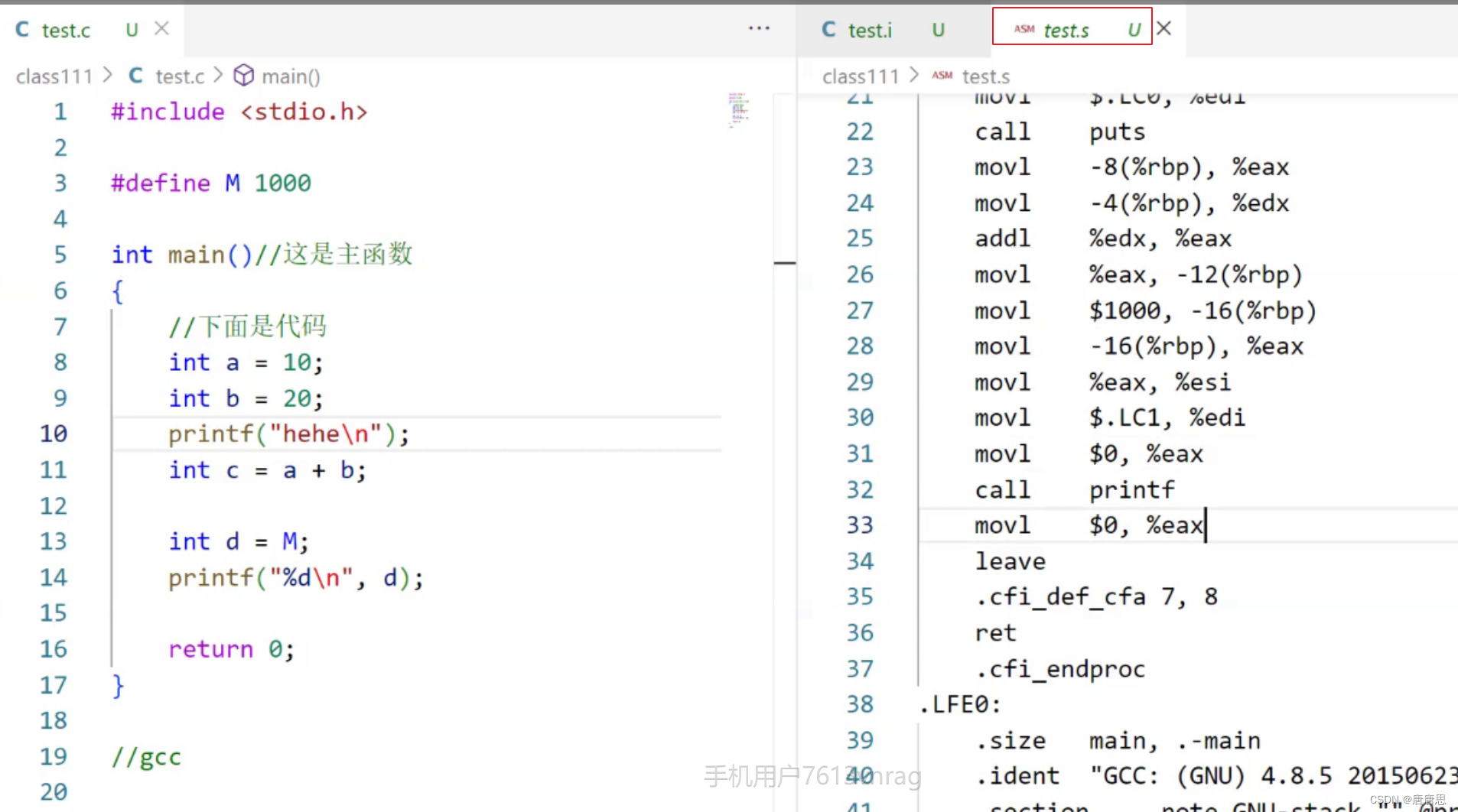
我们发现test.s里面放置的都是汇编代码。 其实编译的过程就是:把C语言代码翻译成了汇编代码。这个过程是非常非常复杂的。简单来说,编译这个过程包含: 语法分析词法分析语义分析符号汇总 汇编到这里,汇编语言依旧不能被我们计算机读懂,汇编语言必须经过汇编器转化成二进制指令,才能被计算机读懂。 我们想要展示一个汇编的效果,那我们希望汇编之后这个代码就不会往后继续执行了。这里我们要用到一个gcc的指令: -c test.s / test.s -c(汇编之后test.s代码不会往后执行) 同时我们也可以使用gcc指令:-o test.o(test.obj) (把test.s汇编完之后的文件命名为test.o,如果没有指定也会生成test.o)
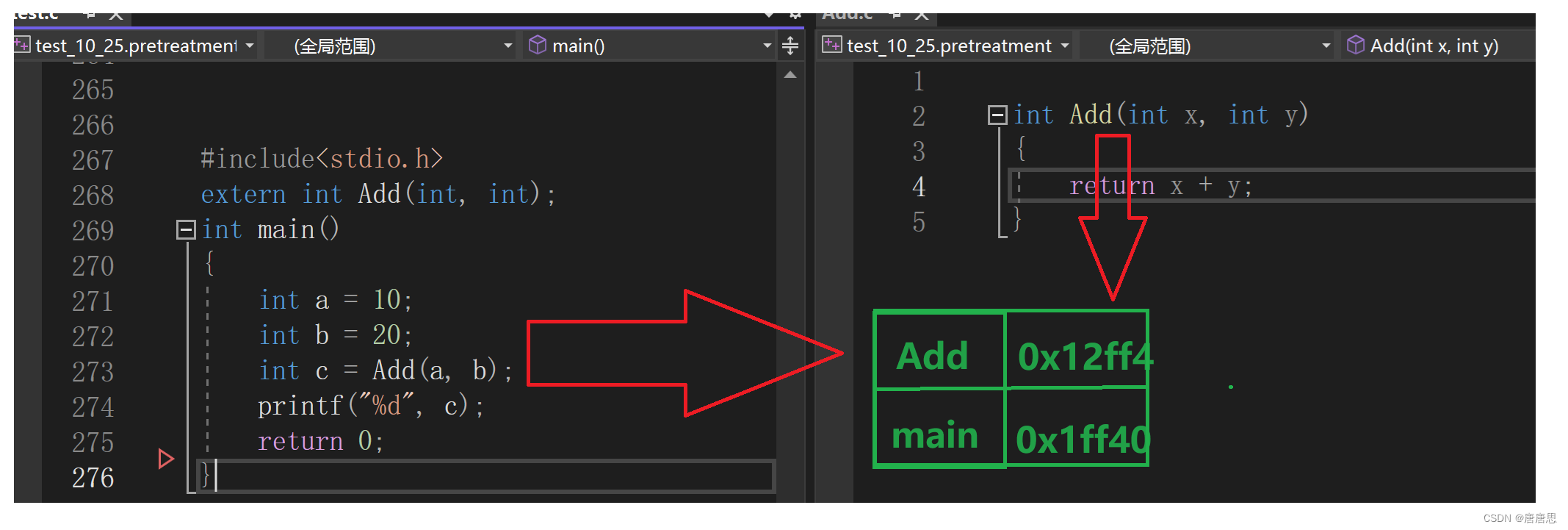
我们发现test.o里面放置的都是二进制信息代码。 其实汇编的过程就是:把汇编代码翻译成二进制指令(目标文件)。到此为止,计算机看得懂了。 生成符号表 链接现在我们的目标文件test.obj 在gcc指令下:gcc test.o(test.obj) -o test.c(test.exe) (把test.o链接完之后的文件命名为test.c,如果没有指定也会生成test.c(其实就是test.exe可执行程序) 上面在学习编译/汇编/链接这几个阶段,我们发现他们有一个公共的点。 在编译里有:符号汇总。在汇编里面有:生成符号表。在链接里面有:合并段表和符号表的合并和重定位。这些功能的实现应用在多文件的工程的项目里。
那编译器是如何处理这种多文件的定义和声明的呢?下面我们来深入学习一下。 编译阶段符号汇总当每个源文件经过编译器都会发生符号汇总。一般都是全局变量汇总,局部变量一般不会汇总。 为什么只有全局变量才会汇总,因为只有全局变量才会跨文件使用。所以一般只会汇总全局变量 在符号表汇总的时候,编译器会为每个文件的全局变量分配地址。
此刻这个阶段每个.o目标文件都有自己的符号表。 汇编生成符号表像上面的test.o和add.o文件都有自己的符号表。我们需要知道的是: 在gcc编译器下,生成的目标和二进制的可执行文件都是按照 elf 这种文件的形式组织。elf 会把目标文件分成不同的段,每个段来存放不同的数据。因为格式都是 elf 所以分段的格式都是一样。
接下来,把相同段的目标文件的数据进行锁定和合并成二进制的可执行文件。
合并完段表,我们就要进行符号表的合并和重新定位。
当编译器在编译阶段想要去查找的时候,都是去符号表里面根据地址查找。 错误当我们在执行程序的时候,经常发生这样的错误。❌❌
【VIM学习资料】 简明 Vim 练级攻略 | 酷 壳 - CoolShell 【给程序员的VIM速查卡】 https://coolshell.cn/articles/5479.html ✔✔✔✔✔最后,感谢大家的阅读,若有错误和不足,欢迎指正!我想说:最近有很多小伙伴和我交流说学不懂,告诉大家,一定要有耐性哦,乖乖敲代码,留给自己足够的时间与耐性。慢慢悟,学着学着自然就会了 希望大家都有好好学习,好好敲代码。好好生活哦 代码------→【gitee:唐棣棣 (TSQXG) - Gitee.com】 联系------→【邮箱:[email protected]】 |










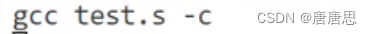








 【推荐书籍】《程序员的自我修养》
【推荐书籍】《程序员的自我修养》 【本文地址】
今日新闻 |
推荐新闻 |