常见数据结构及应用场景 |
您所在的位置:网站首页 › c语言使用方法及使用场景有哪些 › 常见数据结构及应用场景 |
常见数据结构及应用场景
|
目录
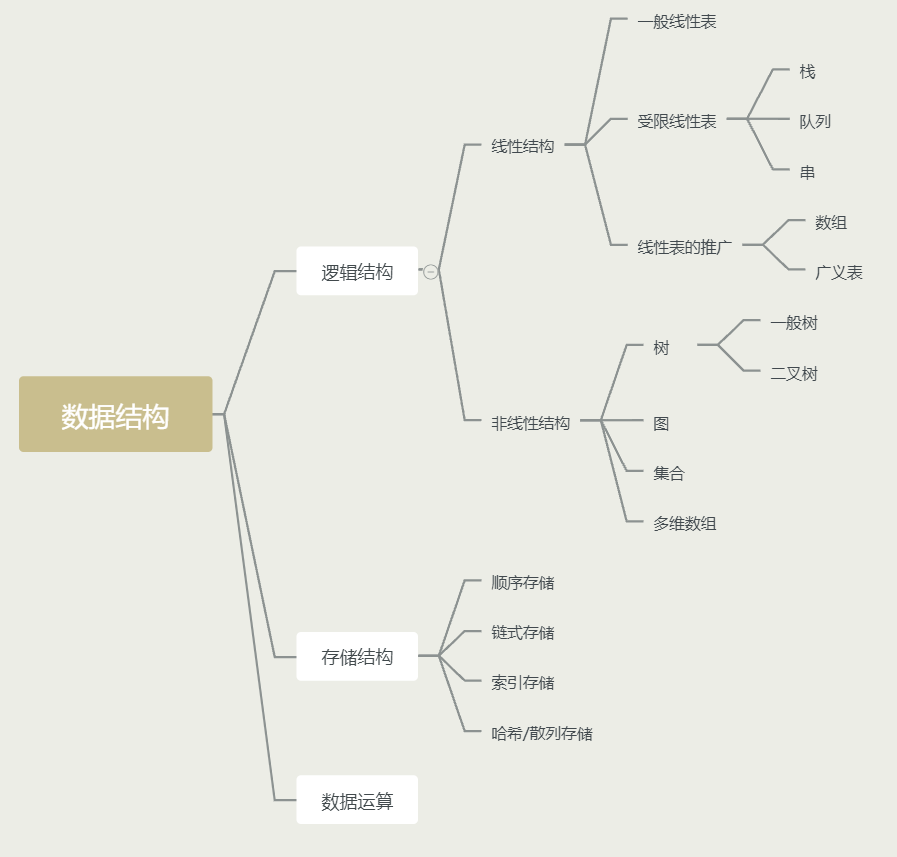
什么是数据结构?1、数据的逻辑结构2、数据的物理结构3、数据存储结构
线性结构与非线性结构1、线性结构2、非线性结构
常用数据结构一、数组( Array)二、链表( Linked List)1、单链表2、双链表3、循环链表4、静态链表应用场景:数组与链表的区别
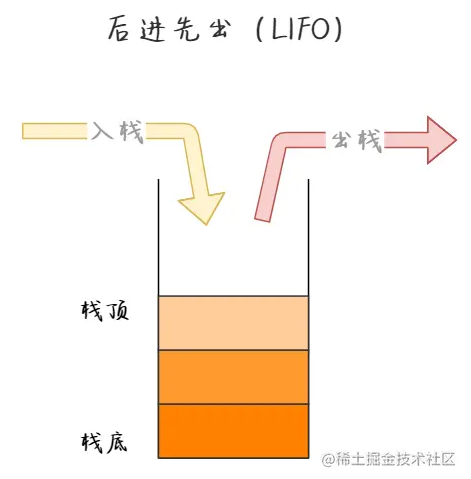
三、栈( Stack)应用场景:
四、队列( Queue)应用场景:
五、树( Tree)六、图( Graph)1、邻接矩阵2、邻接表3、十字链表4、邻接多重表
七、散列表( Hash)1、什么是散列表?2、散列表的存储3、哈希表在集合里的应用应用场景:
八、堆( Heap)
参考资料
什么是数据结构?
数据结构是计算机存储、组织数据的方式。 数据结构是指相互之间存在一种或多种特定关系的数据元素的集合。 指反映数据元素之间的逻辑关系的数据结构,其中的逻辑关系是指数据元素之间的前后间关系,而与他们在计算机中的存储位置无关。逻辑结构包括: 集合:数据结构中的元素之间除了“同属一个集合” 的相互关系外,别无其他关系;线性结构:数据结构中的元素存在一对一的相互关系;树形结构:数据结构中的元素存在一对多的相互关系;图形结构:数据结构中的元素存在多对多的相互关系。 2、数据的物理结构指数据的逻辑结构在计算机存储空间的存放形式。 数据的物理结构是数据结构在计算机中的表示(又称映像),它包括数据元素的机内表示 和 关系的机内表示。 由于具体实现的方法有顺序、链接、索引、散列等多种,所以,一种数据结构可表示成一种或多种存储结构。 数据元素的机内表示(映像方法): 用二进制位(bit)的位串表示数据元素。通常称这种位串为节点(node)。 当数据元素有若干个数据项组成时,位串中与各个数据项对应的子位串称为数据域(data field)。 因此,节点是数据元素的机内表示(或机内映像)。 关系的机内表示(映像方法):数据元素之间的关系的机内表示可以分为顺序映像和非顺序映像。 常用两种存储结构:顺序存储结构和链式存储结构。 顺序映像借助元素在存储器中的相对位置来表示数据元素之间的逻辑关系。 非顺序映像借助指示元素存储位置的指针(pointer)来表示数据元素之间的逻辑关系。 3、数据存储结构数据的逻辑结构在计算机存储空间中的存放形式称为数据的物理结构(也称为存储结构)。 一般来说,一种数据结构的逻辑结构根据需要可以表示成多种存储结构,常用的存储结构有顺序存储、链式存储、索引存储和哈希存储等。 数据的顺序存储结构的特点是:借助元素在存储器中的相对位置来表示数据元素之间的逻辑关系; 非顺序存储的特点是:借助指示元素存储地址的指针表示数据元素之间的逻辑关系。 线性结构与非线性结构一般来说,按照数据的逻辑结构对其进行简单的分类,包括线性结构和非线性结构两类。 1、线性结构 是一个有序数据元素的集合有且仅有一个开始结点和一个终端结点,且所有结点都最多只有一个直接前驱和一个直接后继。常用的线性结构有:数组(顺序表),线性表,栈,队列,双队列,串。
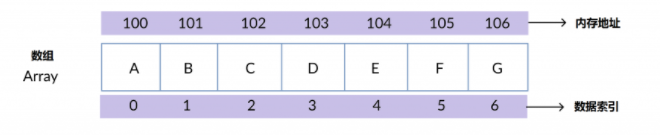
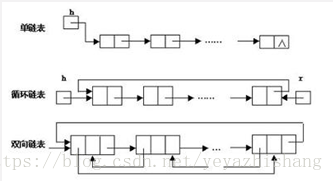
常见的非线性结构有:二维数组,多维数组,广义表,树(二叉树等),图。 广义表(Lists,又称列表)是线性表的推广,其本质上非线性结构! 常用数据结构 一、数组( Array)有序排列的同类数据元素的集合称为数组。 若将有限个类型相同的变量的集合命名,那么这个名称为数组名。 组成数组的各个变量称为数组的分量,也称为数组的元素,有时也称为下标变量。 用于区分数组的各个元素的数字编号称为下标。 链表是物理存储单元上非连续的、非顺序的存储结构。 数据元素的逻辑顺序是通过链表的指针地址实现。 每个元素包含两个结点,一个是存储元素的数据域 (内存空间),另一个是指向下一个结点地址的指针域。 根据指针的指向,链表能形成不同的结构,例如单链表,双向链表,循环链表等。
 应用场景:
操作系统管道通信并发容器:阻塞队列、并发队列。“生产者 - 消费者”、“发布 - 订阅”模型。优先级队列:最大/小堆方法解决 topK 问题。树相关:层序遍历、高度。图相关:广度优先遍历。
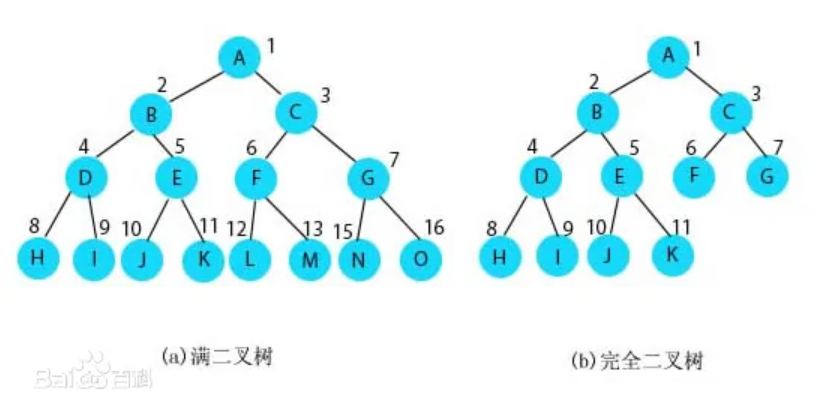
五、树( Tree)
应用场景:
操作系统管道通信并发容器:阻塞队列、并发队列。“生产者 - 消费者”、“发布 - 订阅”模型。优先级队列:最大/小堆方法解决 topK 问题。树相关:层序遍历、高度。图相关:广度优先遍历。
五、树( Tree)
树是一种数据结构,它是由 n(n≥1) 个有限节点组成一个具有层次关系的集合。 树的特点: 每个节点有零个或多个子节点;没有父节点的节点称为根节点;每一个非根节点有且只有一个父节点;除了根节点外,每个子节点可以分为多个不相交的子树
散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。 也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。 给定表M,存在函数 f(key),对任意给定的关键字值 key,代入函数后若能得到包含该关键字的记录在表中的地址,则称表M为哈希(Hash)表,函数 f(key) 为哈希(Hash) 函数。 2、散列表的存储记录的存储位置=f(key) 散列表就是把 key 通过一个固定的算法函数(哈希函数),转换成一个整型数字。 然后就将该数字对数组长度进行取余,取余结果就当作数组的下标。 将 value 存储在以该数字为下标的数组空间里。 这种存储空间可以充分利用数组的查找优势来查找元素,所以查找的速度很快。 3、哈希表在集合里的应用哈希表在应用中也是比较常见的,就如 Java 中有些集合类就是借鉴了哈希原理构造的,例如 HashMap,HashTable 等,利用 hash表的优势,对于集合的查找元素时非常方便的。 然而,因为哈希表是基于数组衍生的数据结构,在添加删除元素方面是比较慢的,所以很多时候需要用到一种数组链表来做,也就是拉链法。 拉链法是数组结合链表的一种结构,较早前的 HashMap 底层的存储就是采用这种结构,直到 jdk1.8 之后才换成了数组加红黑树的结构,其示例图如下: 我们根据元素的一些特征把元素分配到不同的链表中去,也是根据这些特征,找到正确的链表,再从链表中找出这个元素。 哈希表的应用场景很多,当然也有很多问题要考虑,比如哈希冲突的问题,如果处理的不好会浪费大量的时间,导致应用崩溃。 应用场景:哈希表适用于那种查找性能要求高,数据元素之间无逻辑关系要求的情况。 哈希表和位图的结合——布隆过滤器 可作用于网页URL的去重,垃圾邮件的判别,集合重复元素的判别,查询加速(比如基于key-value的存储系统)等 校验安装文件的完整性 在软件部署的时候,计算软件包当前的哈希值是否与预设值相等,防止软件包被篡改或被替换。Linux提供了基于 sha 算法的命令,用于计算文件的哈希值 sha256sum fileName 存储和校验用户口令 用户口令不能用明文存储,更进一步,如果系统不知道用户口令明文,那就更好了,而哈希算法就可以做到既不知道用户明文,又可以校验用户口令。详见《基于哈希算法的web账户口令存储方法》,http://www.cnblogs.com/todsong/archive/2012/04/22/2465178.html 校验重复提交的消息 用户可能因为误操作重复提交数据,而这些数据会对系统产生影响,若要拒绝这些消息,最好的方法就是在每次提交时,计算消息的哈希值,当发现疑似重复提交的时候,做消息哈希值的对比。这是一个 CPU 密集型的操作,如果系统的 CPU 负载比较低,可以考虑使用。至于如何在代码中使用哈希算法,这里就不描述了,Java、C++都有现成的算法库可用。 作为数据库乐观锁的条件 数据库中,最常用的乐观锁方法是在表中增加额外的一列,用于记录一行数据的版本值,通常是一个计数或是时间戳。但是,一张已经存在大量数据的表需要增加额外的版本列,似乎不太可行,也不太方便,此时可以通过哈希计算出虚拟的版本列,用于乐观锁定控制。Oracle数据库提供了哈希算法的存储过程,输入某几个列数据的字符连接,输出该条记录的哈希值,通过比较该值判断数据是否被修改。下面是摘自《Oracle 9i&10g 编程艺术》的例子 作为数据库表分区的分区条件 如果难以按照某一个列对数据库表做分区,表中的数据又没有太多的业务逻辑,那么通过哈希函数强行分区是个不错的选择。详见《Oracle分区表,哈希分区的新建与增加》,http://www.cnblogs.com/todsong/archive/2012/08/26/2657158.htm 八、堆( Heap) 参考资料[1] 数据结构:八大数据结构分类: https://blog.csdn.net/yeyazhishang/article/details/82353846 [2] 数据结构:https://juejin.cn/post/6916804072485945358 [3] 408数据结构: https://www.processon.com/view/6103b75a0e3e7423a334a3c5?fromnew=1 [4] 数据结构与算法: https://www.processon.com/view/5cc266d7e4b08b66b9bb9579?fromnew=1 [5] 数据结构:八大数据结构分类: https://blog.csdn.net/yeyazhishang/article/details/82353846 [6] 散列表原理与应用场景:https://blog.csdn.net/qq_39038793/article/details/103210889 |
 其中静态链表是数组模拟的链式结构,数组存储下表跳转信息,建立链接逻辑。
其中静态链表是数组模拟的链式结构,数组存储下表跳转信息,建立链接逻辑。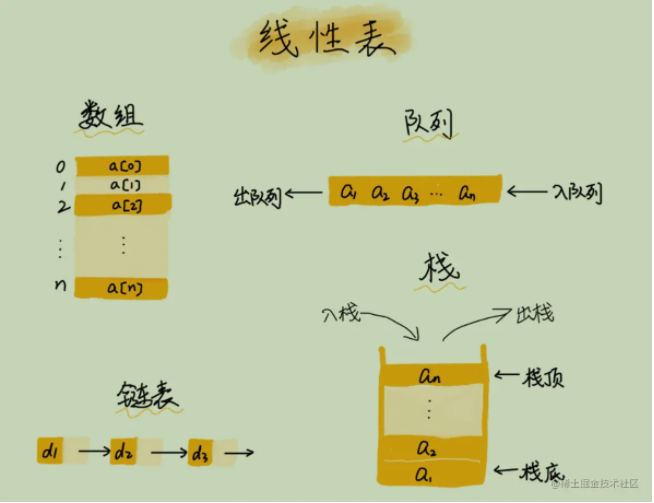
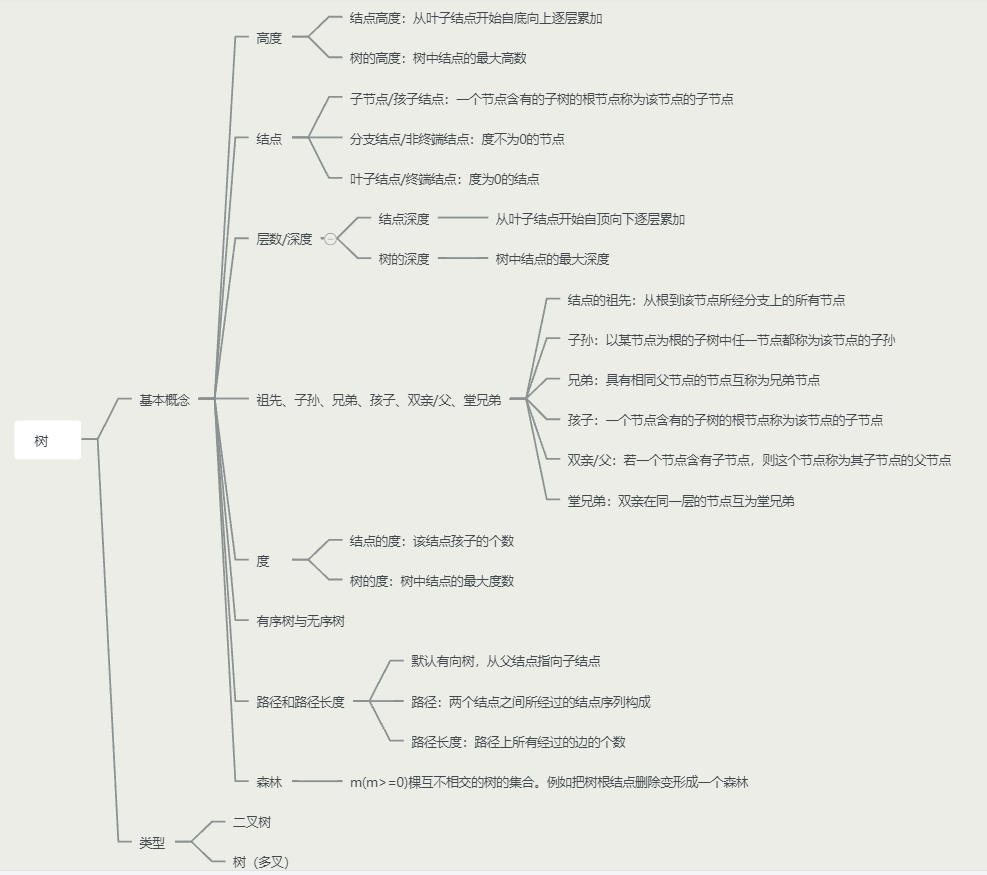 思维导图未完待补充…
思维导图未完待补充…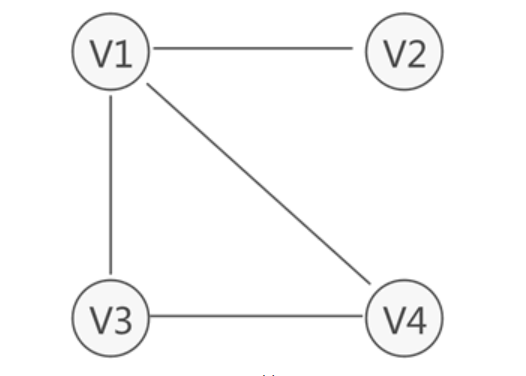 数据结构中的一个图是用G = (V, E)集合来表示的, V(vertex)是顶点集合, E(edge)是边集合。 图的相关概念如下图所示。
数据结构中的一个图是用G = (V, E)集合来表示的, V(vertex)是顶点集合, E(edge)是边集合。 图的相关概念如下图所示。 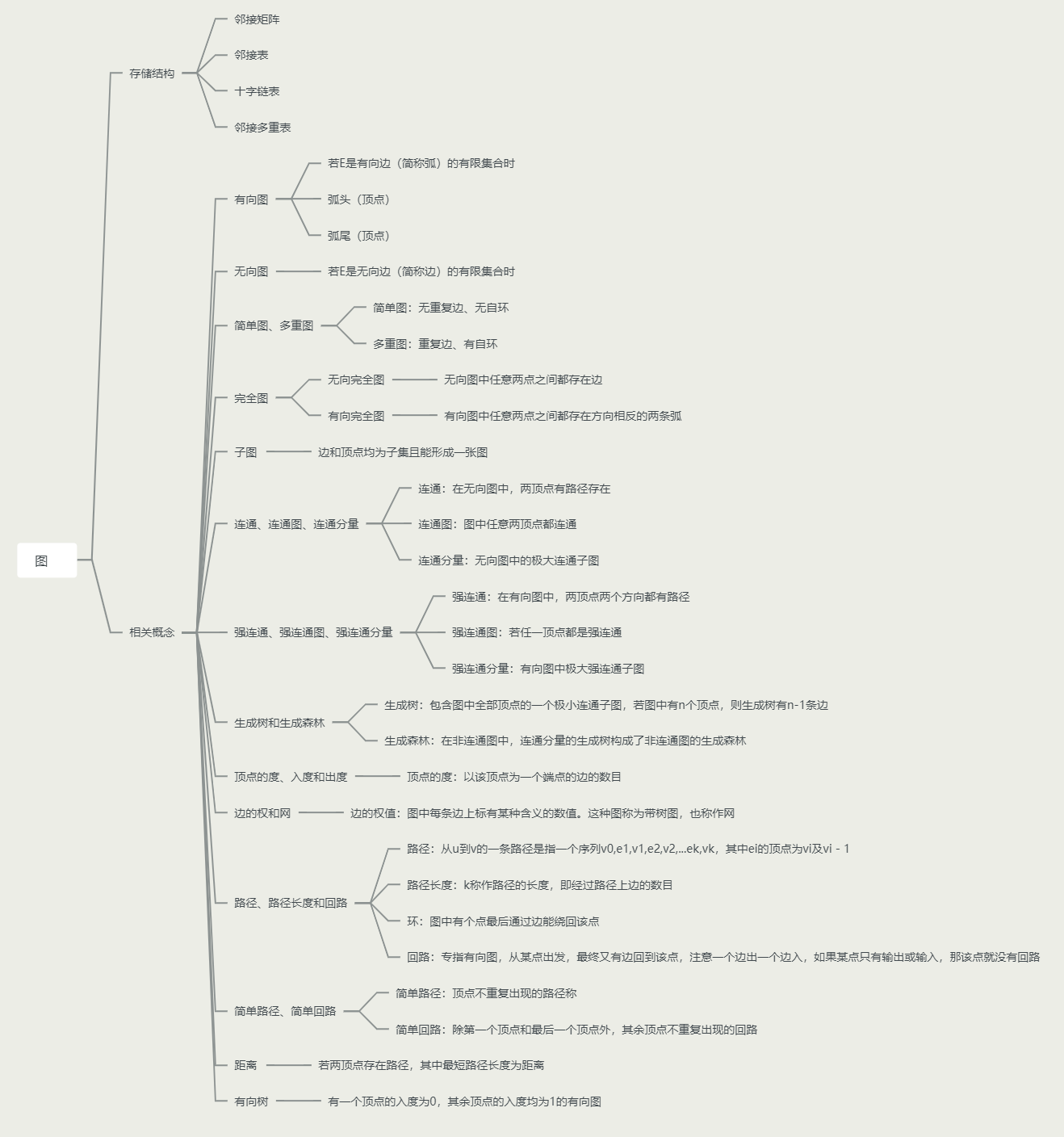 图的相关概念(附图):https://blog.csdn.net/shuiyixin/article/details/83692474
图的相关概念(附图):https://blog.csdn.net/shuiyixin/article/details/83692474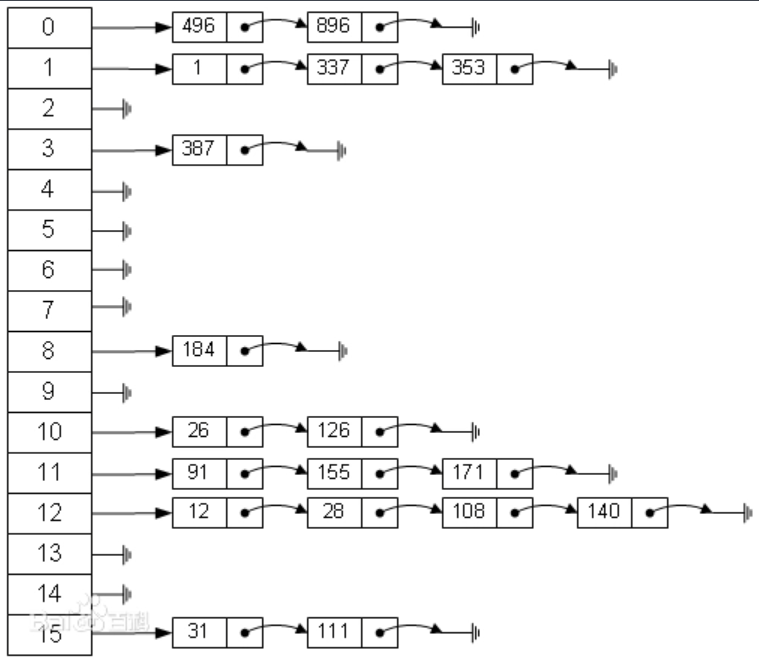 从图中可以看出,左边很明显是个数组,数组的每个成员包括一个指针,指向一个链表的头。当然这个链表可能为空,也可能元素很多。
从图中可以看出,左边很明显是个数组,数组的每个成员包括一个指针,指向一个链表的头。当然这个链表可能为空,也可能元素很多。【本文地址】
今日新闻 |
推荐新闻 |