相关性分析 |
您所在的位置:网站首页 › copula模型该怎么做 › 相关性分析 |
相关性分析
|
相关性分析–copula
提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加 例如:第一章 Python 机器学习入门之pandas的使用 提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 相关性分析--copula前言一、copula是什么?二、相关系数1.提出问题2.基于Copula函数的相关性测度2.1.定理 3.模型构建2.读入数据 总结 前言提示:这里可以添加本文要记录的大概内容: 在项目需求运用了线性分析、皮尔逊相关系数、马氏距离等多种分析方法之后,无法得到精确度较高的预测结果,遂学习一下copula模型 提示:以下是本篇文章正文内容,下面案例可供参考 一、copula是什么?形象的说,我们可以把copula函数叫做“连接函数”或“相依函数”,它是把多个随机变量的联合分布与它们各自的边缘分布相连接起来的函数。
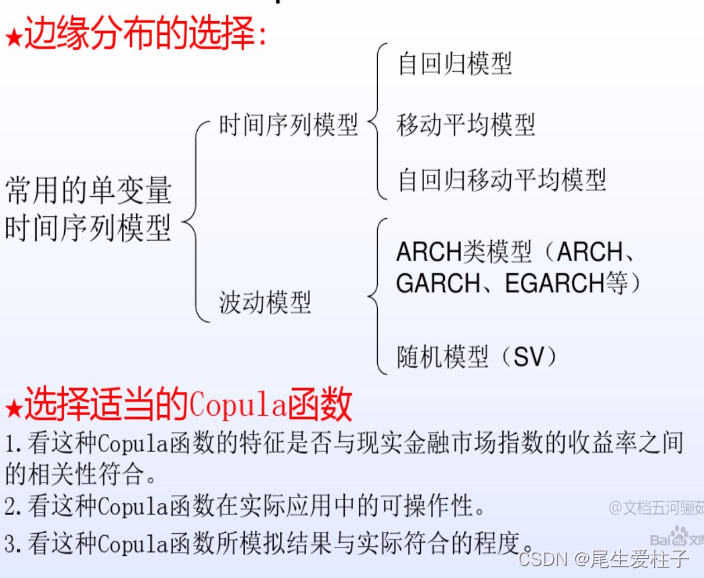
边缘分布:假设有一个和两个变量相关的概率分布:p(x,y),关于其中一个特定变量的边缘分布则为给定其他变量的条件概率分布:P(x) = ∑ y \sum_{y} ∑yP(x,y) = ∑ y \sum_{y} ∑yP(x|y)P(y) 联合分布可以唯一决定边缘分布,但边缘分布不一定能决定联合分布 边缘密度的乘积等于联合密度 二、相关系数 1.提出问题对于两个变量之间的相关性关系,我们可以利用相关系数ρ来度量,但是,我们看下面的问题: 若x~N(0,1),y= x² ,显然x,y关系密切 则cov(x,y) = E(xy)-E(x)E(y)=E( x 3 x^3 x3)-E(x)E( x 2 x^2 x2)=0 当变量间的关系是非线性时,用相关系数来度量其关系是不可靠的,而Copula函数在一定范围内就可以避免这个问题。 2.基于Copula函数的相关性测度 2.1.定理对随机变量 x 1 x_{1} x1, x 2 x_{2} x2,…, x n x_{n} xn做严格的单调增变换,相应的Copula函数不变。 Kendall秩相关系数 τ \tau τSpearman秩相关系数 ρ \rho ρGini关联系数 γ \gamma γ1.Kendall秩相关系数 τ \tau τ:(描述变化趋势)指设有n个统计对象,每个对象有两个属性的系数。将所有统计对象按属性1取值排列,不失一般性,设此时属性2取值的排列是乱序的。设P为两个属性值排列大小关系一致的统计对象对数。则: R=(P-(n*(n-1)/2-P))/(n*(n-1)/2)=(4P/(n*(n-1)))-1 ( x 1 x_1 x1, y 1 y_1 y1)和( x 2 x_2 x2, y 2 y_2 y2)为独立同分布的随机向量 Kendall秩相关系数可以有Copula函数给出: τ \tau τ = 4 ∫ 1 0 \int_1^0 ∫10 ∫ 1 0 \int_1^0 ∫10C(u,v)dC(u,v)-1 2. Spearman秩相关系数 ρ \rho ρ:用来度量两个变量之间联系的强弱,是一种非参数的统计相关性测度,一般用 ρ \rho ρ表示,它所衡量的是两个变量有多大程度可以用单调函数描绘。如果没有重复点,且两个变量单调相关时,Spearman相关系数为+1或者−1 ( x 1 x_1 x1, y 1 y_1 y1)和( x 2 x_2 x2, y 2 y_2 y2), ( x 3 x_3 x3, y 3 y_3 y3)为独立同分的随机向量,由相应的Copula函数来表示如下: ρ \rho ρ = 12 ∫ 1 0 \int_1^0 ∫10 ∫ 1 0 \int_1^0 ∫10uvdC(u,v)-3 = 12 ∫ 1 0 \int_1^0 ∫10 ∫ 1 0 \int_1^0 ∫10C(u,v)dC(u,v)-3 3.Gini关联系数 γ \gamma γ: τ \tau τ和 ρ \rho ρ只考虑了随机变量变化方向的一致性和不一致性,而Gini关联系数则更细致地考虑了随机变量变化顺序的一致性和不一致性。 公式太复杂,暂放 3.模型构建两阶段法: 1、确定边缘分布 2、选取一个适当的Copula函数,以便能很好地描述出随机变量之间的相关结构。 代码如下(示例): data = pd.read_csv( 'https://labfile.oss.aliyuncs.com/courses/1283/adult.data.csv') print(data.head())该处使用的url网络请求的数据。 总结提示:这里对文章进行总结: 例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。 |
 Sklar定理 令F(·,·)为具有边缘分布F(·)的联合分布函数,那么存在一个Copula函数C(·,·),满足
Sklar定理 令F(·,·)为具有边缘分布F(·)的联合分布函数,那么存在一个Copula函数C(·,·),满足 
【本文地址】
今日新闻 |
推荐新闻 |