拓端tecdat |
您所在的位置:网站首页 › copula模型用什么软件 › 拓端tecdat |
拓端tecdat
|
原文链接:http://tecdat.cn/?p=25804
原文出处:拓端数据部落公众号
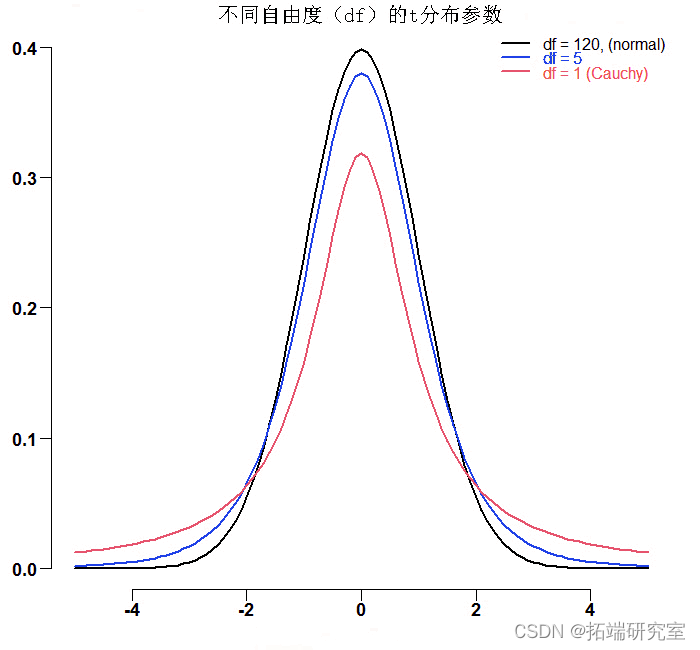
这篇文章是关于 copulas 和重尾的。在全球金融危机之前,许多投资者是多元化的。 看看下面这张熟悉的图:
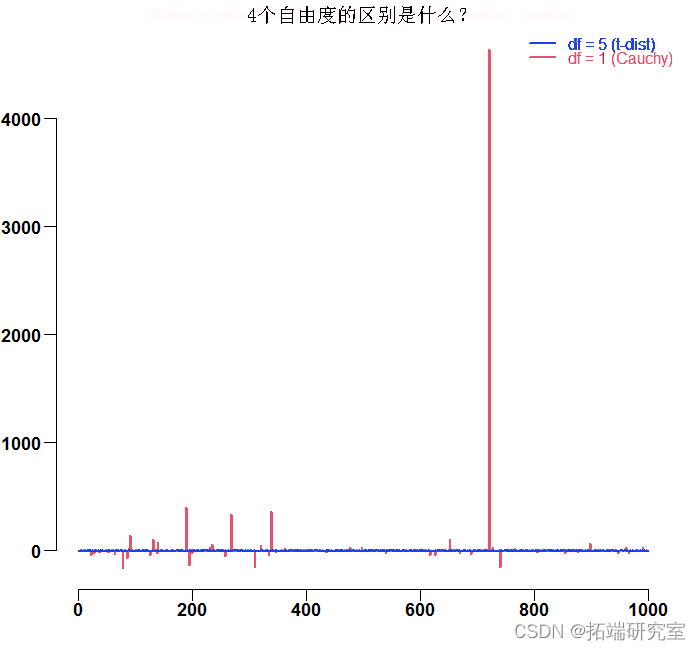
黑线是近似正态的。红线代表Cauchy分布,它是具有一个自由度的T分布的一个特殊情况。也许是因为Cauchy和t分布混在一起。我们总是可以计算出经验方差。请看下图。这是对1自由度的t分布(红色的Cauchy分布)和5自由度的t分布(蓝色)的模拟结果。
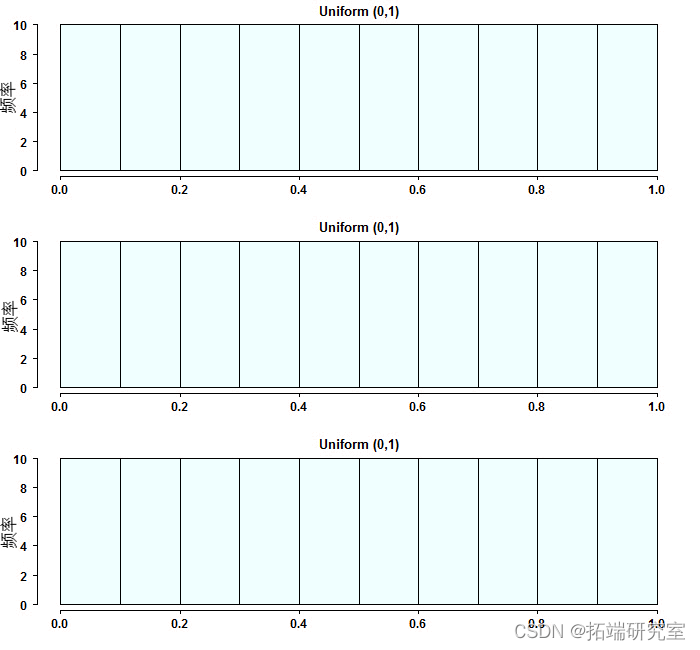
为了比较不同的尾部行为,我们有我们所谓的尾部指数。简而言之,在几乎任何分布中,某个阈值之后的观测值(比如说最差的5%的情况下的观测值)都是渐进式的帕累托分布。 其中x_m是截止点,α将决定尾巴的形状。α也被称为尾部指数。 现在大家都知道,金融收益呈现出厚尾。这使得保持投资组合为左尾事件做好准备变得更加重要,因为在那个区域,由于相关性的增加,你会同时受到所有资产的影响(正如金融危机所证明的那样)。在这个讨论中,copulas发挥了重要的作用。copulas的概念是相当巧妙的。copula这个词起源于拉丁语,它的意思是捆绑。当我们有两个(或更多)资产类别的收益,我们可以假设或模拟它们的分布。做完这些之后,我们可以把它们 "粘贴 "在一起,只对相关部分进行建模,而不考虑我们最初对它们各自分布的建模方式。怎么做? 我们从英国统计学家 Ronald Fisher 开始,他在 1925 年证明了一个非常有用的性质,即任何连续随机变量的累积分布函数都是均匀分布的。形式上,对于任何随机变量 X,如果我们表示
现在让我们对金融和消费必需品之间的相关结构进行建模。从拉取数据开始: da0 = (getSymbols(sym[1]) for (i in 1:l){ da0 = getSymbols w |
 您可以通过这种方式转换任何连续分布。现在,将两个变换后的随机数表示为
您可以通过这种方式转换任何连续分布。现在,将两个变换后的随机数表示为 【本文地址】
今日新闻 |
推荐新闻 |