centos7 安装hadoop 3.1.3集群 |
您所在的位置:网站首页 › centos7hadoop安装教程 › centos7 安装hadoop 3.1.3集群 |
centos7 安装hadoop 3.1.3集群
|
1、下载hadoop 3.1.3,设置hadoop环境变量
官网下载地址:https://archive.apache.org/dist/hadoop/common/hadoop-3.1.3/hadoop-3.1.3.tar.gz
将下载的tar包解压到/usr/local/目录下,解压后的文件具体如下:
[root@vm01 tmp]# ll /usr/local/hadoop-3.1.3/
total 180
drwxr-xr-x. 2 1000 1000 183 Sep 12 2019 bin
drwxr-xr-x. 3 1000 1000 20 Sep 11 2019 etc
drwxr-xr-x. 2 1000 1000 106 Sep 12 2019 include
drwxr-xr-x. 3 1000 1000 20 Sep 12 2019 lib
drwxr-xr-x. 4 1000 1000 288 Sep 12 2019 libexec
-rw-rw-r--. 1 1000 1000 147145 Sep 4 2019 LICENSE.txt
drwxr-xr-x. 2 root root 4096 Aug 15 10:25 logs
-rw-rw-r--. 1 1000 1000 21867 Sep 4 2019 NOTICE.txt
-rw-rw-r--. 1 1000 1000 1366 Sep 4 2019 README.txt
drwxr-xr-x. 3 1000 1000 4096 Aug 15 10:24 sbin
drwxr-xr-x. 4 1000 1000 31 Sep 12 2019 share
在/etc/profile中添加hadoop环境变量
#HADOOP
export HADOOP_HOME=/usr/local/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
创建hadoop所需目录
sudo mkdir -p /data/hadoop/name #NameNode数据存放目录
sudo mkdir -p /data/hadoop/secondary # SecondaryNameNode数据存放目录
sudo mkdir -p /data/hadoop/data # DataNode数据存放目录
sudo mkdir -p /data/hadoop/tmp # 临时数据存放目录
2、修改3台机器的基础配置、环境安装
hadoop是java编写的,所以机器需要安装java环境,centos7安装jdk1.8此处不再赘述。
修改主机名,添加主机名至hosts文件中
hostnamectl set-hostname xxx
[root@vm01 ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.168.238 vm01
192.168.168.237 vm02
192.168.168.236 vm03
我的三台主机分别修改主机名为:vm01、vm02、vm03
设置ssh免密登录
生成秘钥(公钥和私钥),一路回车
ssh-keygen -t rsa
进入.ssh目录下,重命名生成的公钥
cd ~/.ssh
cp id_rsa.pub authorized_keys
将重命名的authorized_keys分发到其他主机,并将id_rsa.pub追加至authorized_keys中
scp authorized_keys root@vm02:/root/.ssh/
vm02主机执行追加
cat id_rsa.pub >> authorized_keys
以上操作分别在每个主机上执行。
3、修改hadoop配置文件
修改.sbin/start-dfs.sh 和.sbin/stop-dfs.sh,添加以下启动用户配置: HDFS_DATANODE_USER=root HADOOP_SECURE_DN_USER=root HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root 修改./sbin/start-yarn.sh 和./sbin/stop-yarn.sh,添加以下启动用户配置: YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=root YARN_NODEMANAGER_USER=root hadoop所有的配置文件都在etc/hadoop/目录下 修改core-site.xml fs.default.name hdfs://vm01:9000 默认的HDFS端口,用于NameNode与DataNode之间到的通讯,IP为NameNode的地址 hadoop.tmp.dir /data/hadoop/data/ 存放hadoop文件系统依赖的基本配置,很多路径都依赖它 修改hdfs-site.xml配置文件 dfs.replication 3 副本数,HDFS存储时的备份数量 dfs.namenode.name.dir /data/hadoop/name namenode临时文件所存放的目录 dfs.datanode.data.dir /data/hadoop/data datanode临时文件所存放的目录 dfs.namenode.http-address vm01:9870 hdfs web 地址 修改yarn-site.xml配置文件 yarn.nodemanager.aux-services mapreduce_shuffle nomenodeManager获取数据的方式是shuffle yarn.resourcemanager.hostname vm01 指定Yarn的老大(ResourceManager)的地址 yarn.nodemanager.env-whitelist JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ 容器可能会覆盖的环境变量,而不是使用NodeManager的默认值 修改mapred-site.xml配置文件 mapreduce.framework.name yarn 告诉hadoop以后MR(Map/Reduce)运行在YARN上 mapreduce.admin.user.env HADOOP_MAPRED_HOME=$HADOOP_HOME 可以设置AM【AppMaster】端的环境变量,如果上面缺少配置,可能会造成mapreduce失败 yarn.app.mapreduce.am.env HADOOP_MAPRED_HOME=$HADOOP_HOME 可以设置AM【AppMaster】端的环境变量,如果上面缺少配置,可能会造成mapreduce失败 修改从节点主机配置文件workers,添加从节点 vm02 vm03 4、配置分发至其他主机 以上配置均是在master节点修改的,由于每个服务器都装了hadoop,现将其配置信息分发给其余两个slave节点即可: rsync -av /usr/local/hadoop-3.1.3/etc/hadoop/* vm02:/usr/local/hadoop-3.1.3/etc/hadoop/ rsync -av /usr/local/hadoop-3.1.3/etc/hadoop/* vm03:/usr/local/hadoop-3.1.3/etc/hadoop/ 5、对namenode进行格式化 hdfs namenode -format # 只需要在 master 执行即可 6、启动hadoop集群 ./sbin/start-all.sh 启动日志: Starting namenodes on [vm01] Last login: Sun Aug 15 11:29:22 EDT 2021 on pts/0 Starting datanodes Last login: Sun Aug 15 11:29:38 EDT 2021 on pts/0 Starting secondary namenodes [vm01] Last login: Sun Aug 15 11:29:40 EDT 2021 on pts/0 Starting resourcemanager Last login: Sun Aug 15 11:29:45 EDT 2021 on pts/0 Starting nodemanagers Last login: Sun Aug 15 11:29:50 EDT 2021 on pts/0 使用jps查看进程 vm01: [root@vm01 hadoop-3.1.3]# jps 11764 ResourceManager 11253 NameNode 11518 SecondaryNameNode 12094 Jps vm02: [root@vm02 hadoop-3.1.3]# jps 4288 NodeManager 4400 Jps 4179 DataNode vm03: 4025 NodeManager 4137 Jps 3917 DataNode 在浏览器输入:9870进入hdfs web: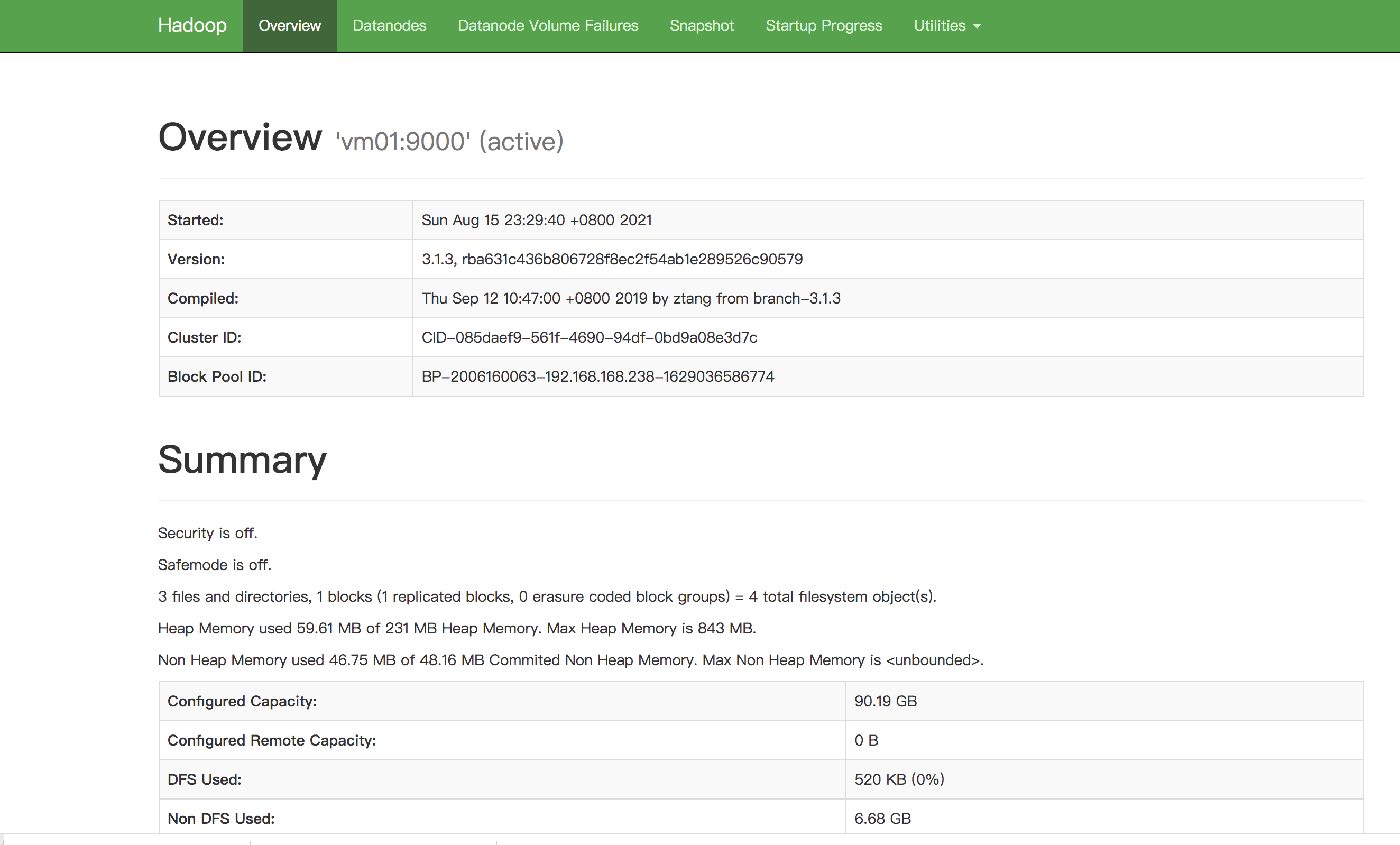 7、在hadoop web进行文件操作验证是否可用
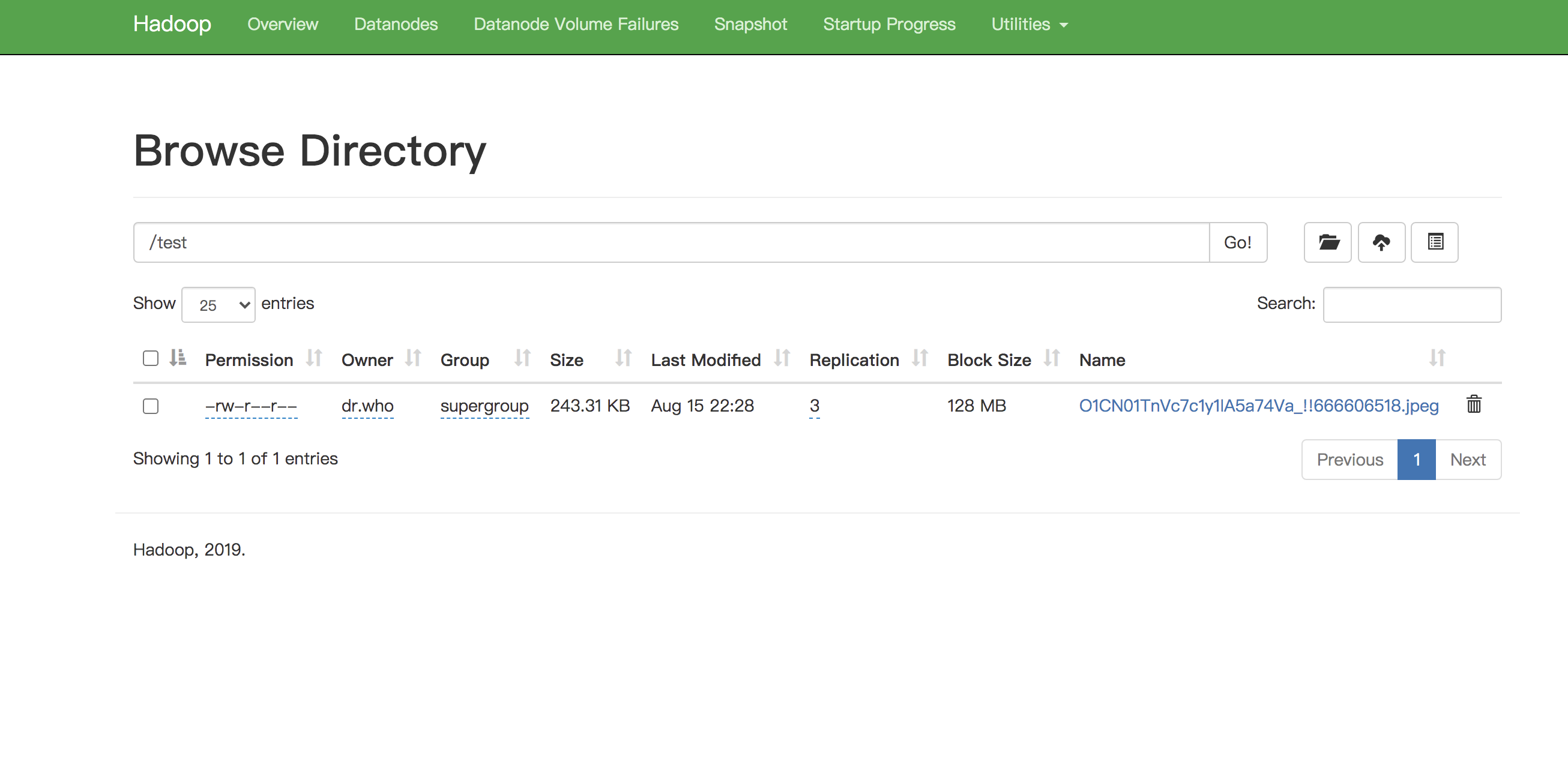
通过web管理端成功创建文件夹和上传文件
7、在hadoop web进行文件操作验证是否可用
通过web管理端成功创建文件夹和上传文件
Tags:centos hadoop 转载:感谢您对高晓波个人博客网站平台的认可,以及对我们原创作品以及文章的青睐,非常欢迎各位朋友分享到个人站长或者朋友圈,但转载请说明文章出处“来源高晓波个人博客”。https://www.gaoxiaobo.com/web/server/172.html 很赞哦! () 上一篇:pve添加阿里云源---U盘安装Proxmox VE(七) 下一篇:Centos7 安装Jenkins--Jenkins使用(一) |
【本文地址】
今日新闻 |
推荐新闻 |