【计算机组成原理】第4章 存储器 |
您所在的位置:网站首页 › cache主存和主存辅存相同点在哪 › 【计算机组成原理】第4章 存储器 |
【计算机组成原理】第4章 存储器
|
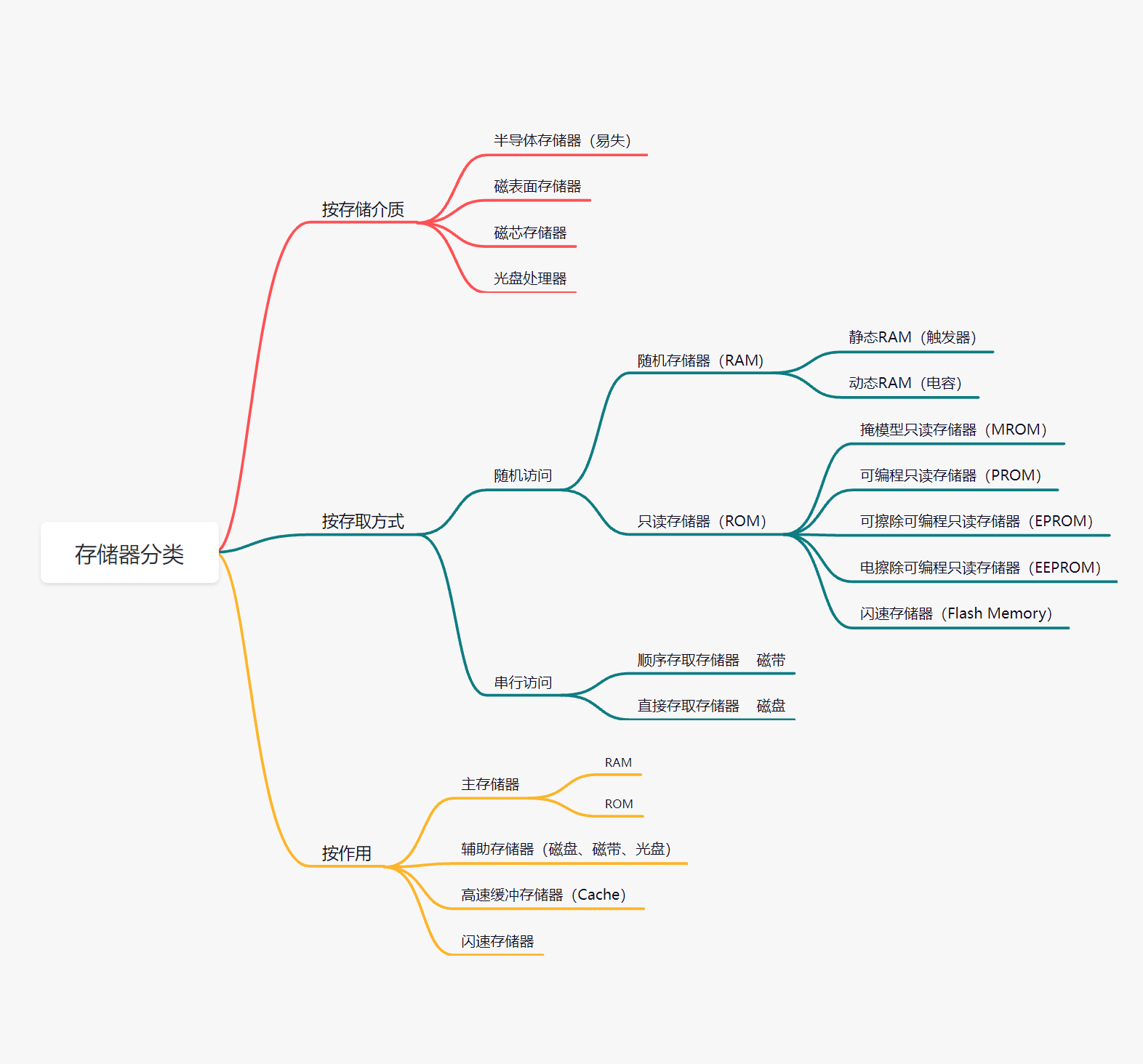
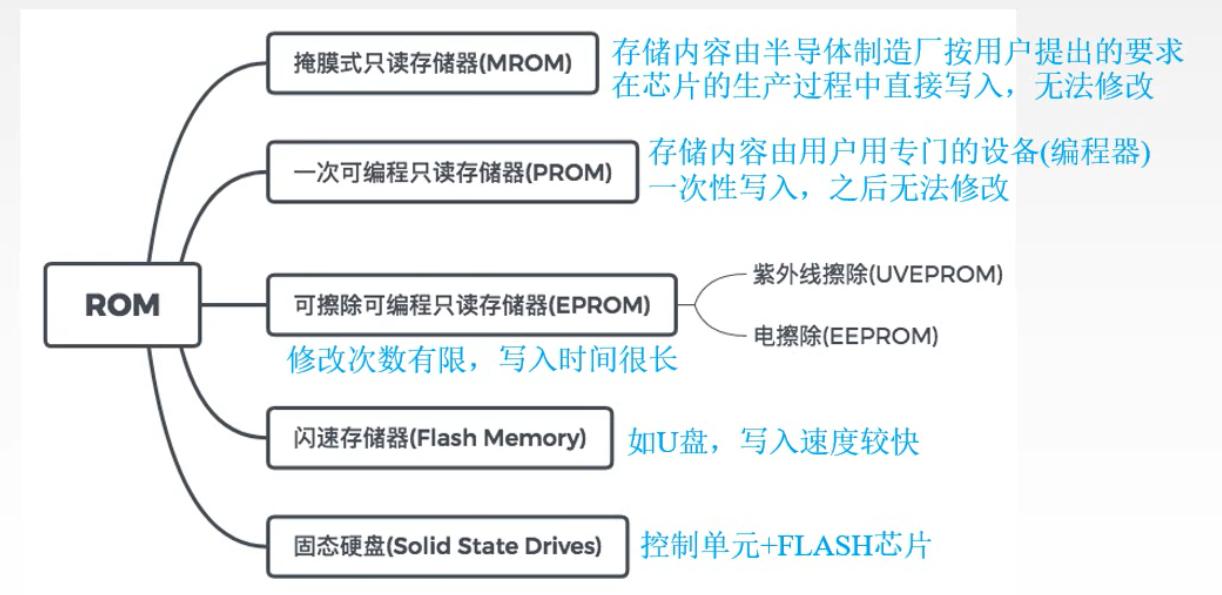
存储器分类
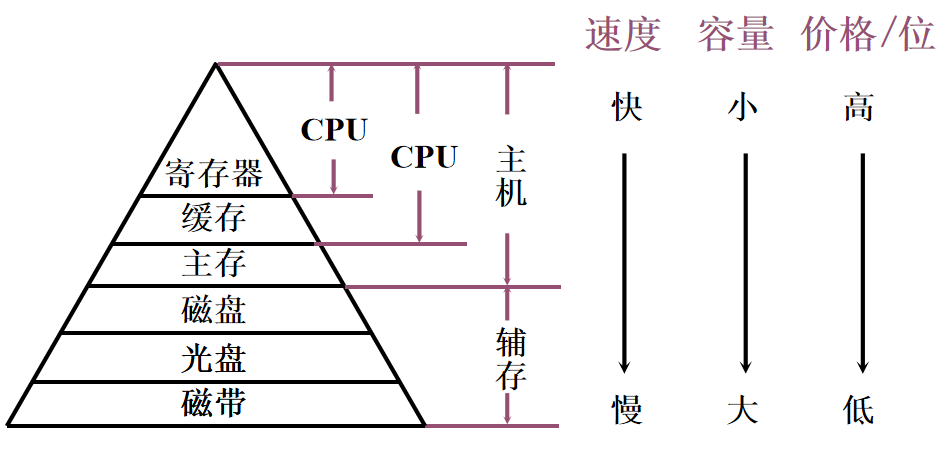
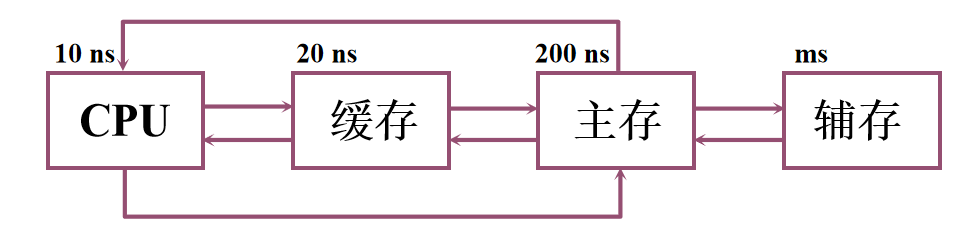
1️⃣ 缓存——主存层次主要解决CPU和主存速度不匹配的问题 2️⃣ 主存——辅存主要解决存储系统的容量问题 3️⃣ 主存——辅存层次发展形成虚拟存储系统。
4️⃣ 需要注意的是,主存和 Cache 之间的数据调动是由硬件自动完成的,对所有程序员均是透明的;而主存和辅存之间的数据调动则是由硬件和操作系统共同完成的,对应用程序员是透明的。 习题
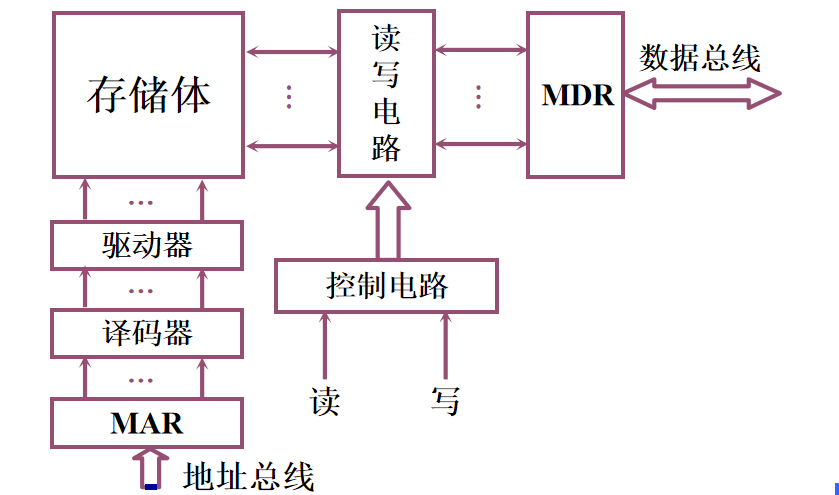
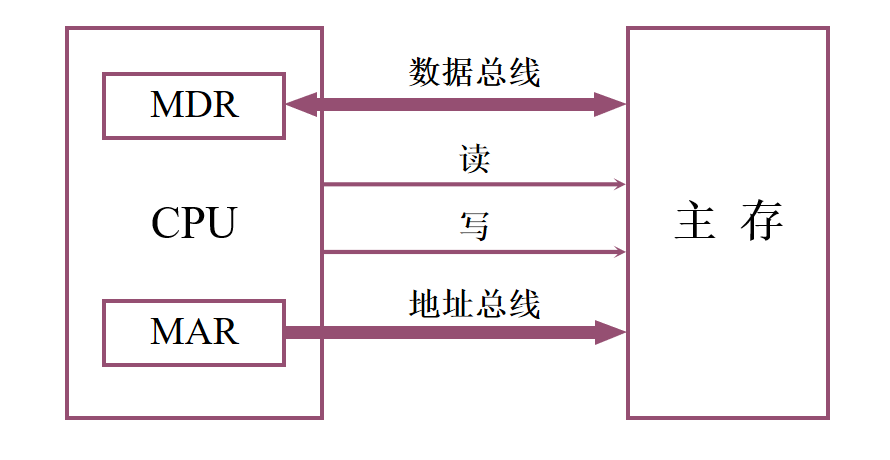
1️⃣ 驱动器、译码器和读写电路在存储芯片中 2️⃣ MAR和MDR在CPU芯片中 3️⃣ 存储芯片和CPU芯片可通过总线连接 主存中存储单元地址的分配
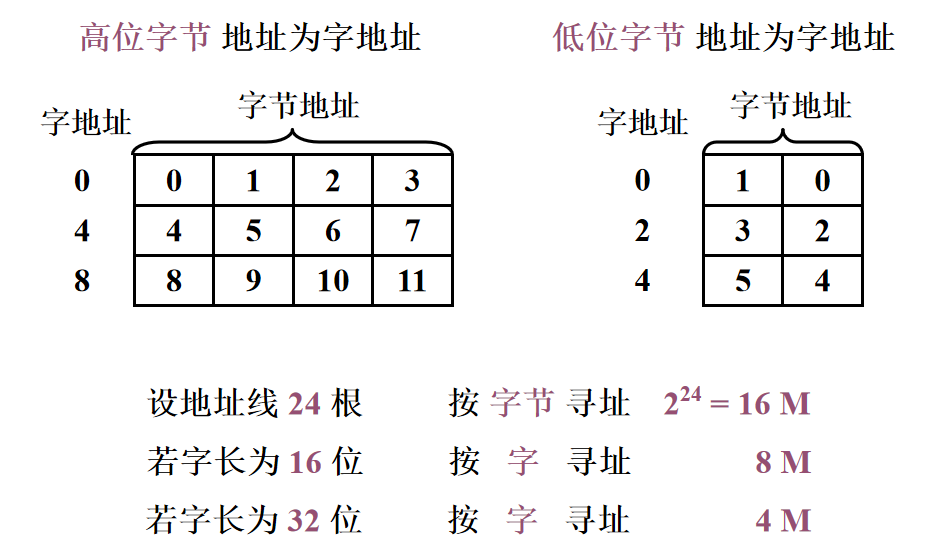
1️⃣ 存储容量:主存存放二进制代码的总位数,存储容量(位)=存储单元个数*存储字长,存储容量(字节)=存储单元个数*存储字长 / 8 2️⃣ 存储速度 存取时间:存储器的访问时间=读出时间+写入时间 存取周期:连续两次独立的存储器操作(读或写)所需的 最小间隔时间3️⃣ 存储器的带宽:单位时间内存储器存取的信息量,每个存储周期可以访问的位(字节)数 / 存储周期 提高存储器带宽的措施 缩短存储周期 增加存储字长 增加存储体 习题
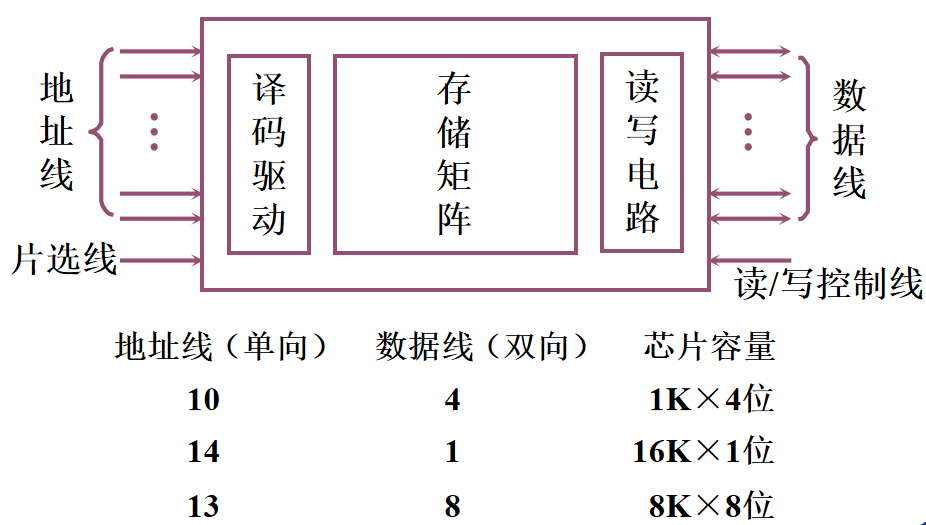
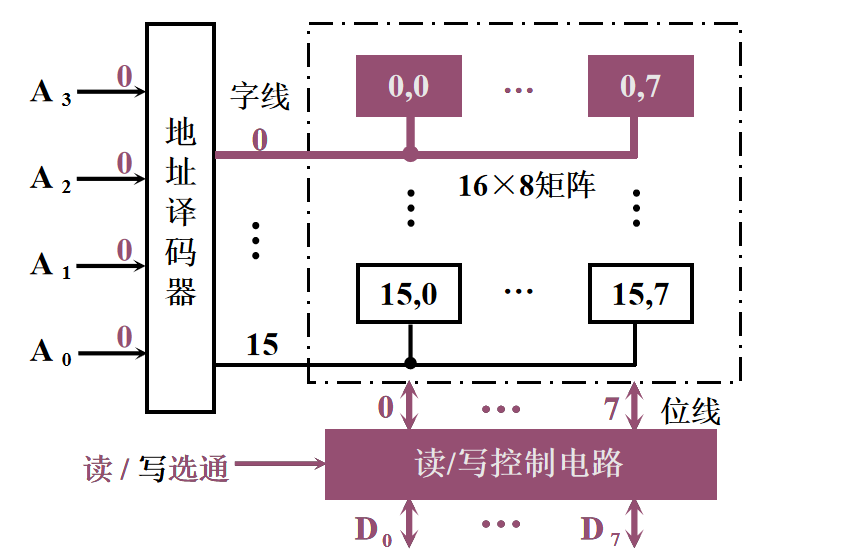
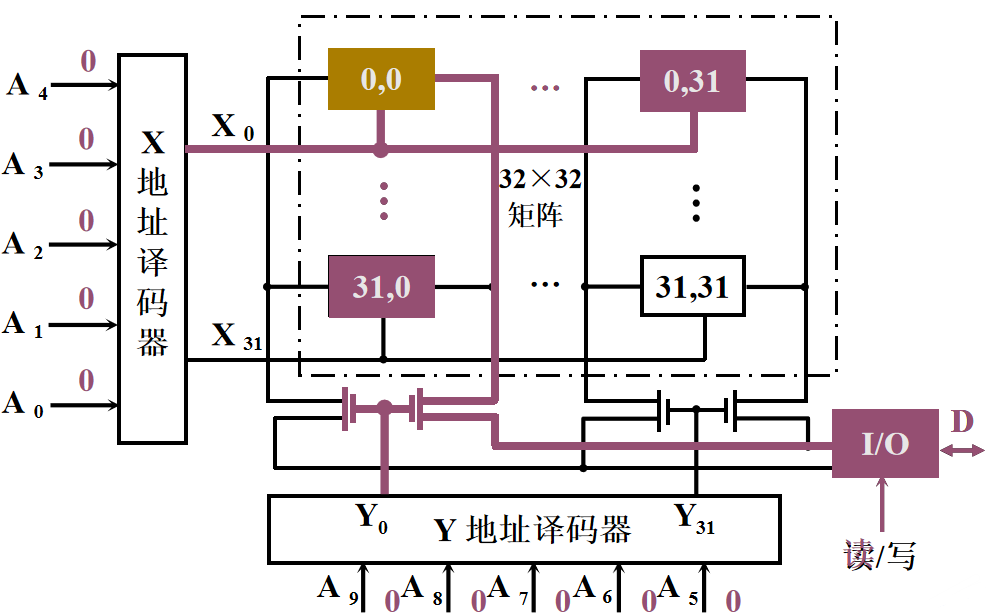
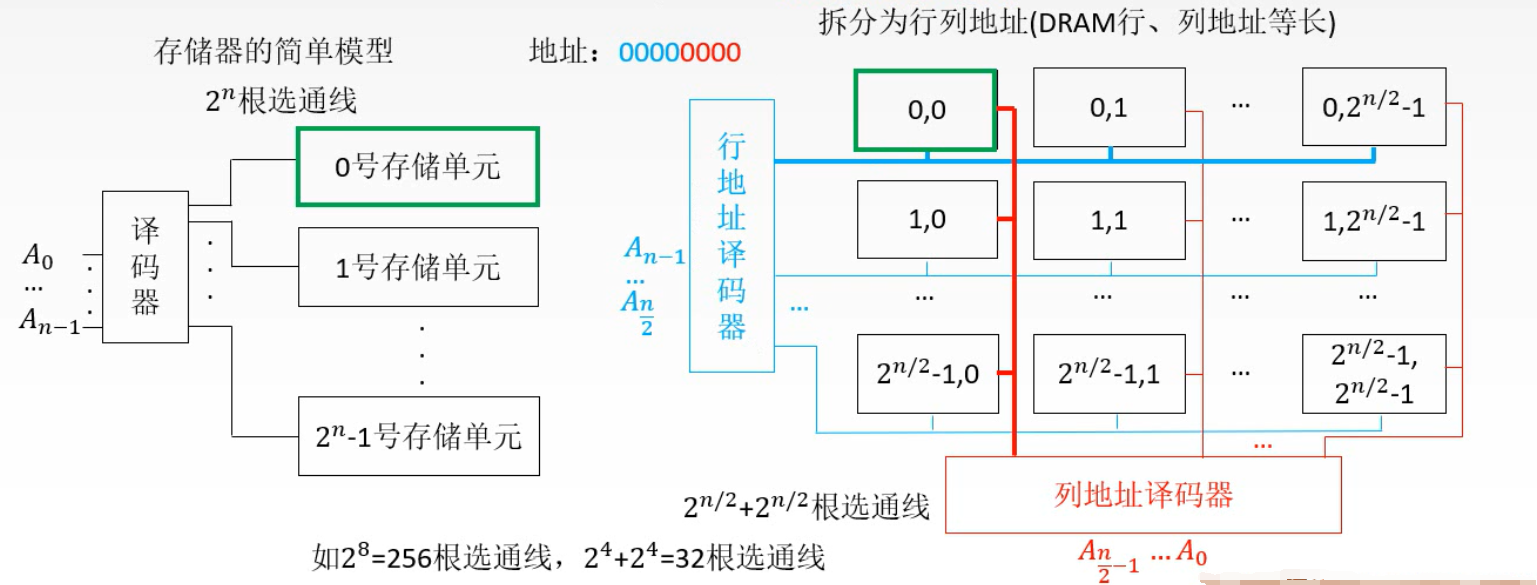
1️⃣ 地址线:单向输入,位数与存储字的个数有关 2️⃣ 数据线:双向的,位数与读/写的数据位数有关 3️⃣ 控制线 读/写控制线:决定芯片进行读/写操作 片选线:选择存储芯片 半导体存储芯片的译码驱动方式🌈 线选法
1️⃣ 特点:一根字选择线(字线),直接选中一个存储单元的各位 2️⃣ 结构简单,只适于容量不大的存储芯片 🌈 重合法
1️⃣ 特点:被选单元是由X、Y两个方向的地址决定的 2️⃣ 适合容量较大的存储芯片 习题
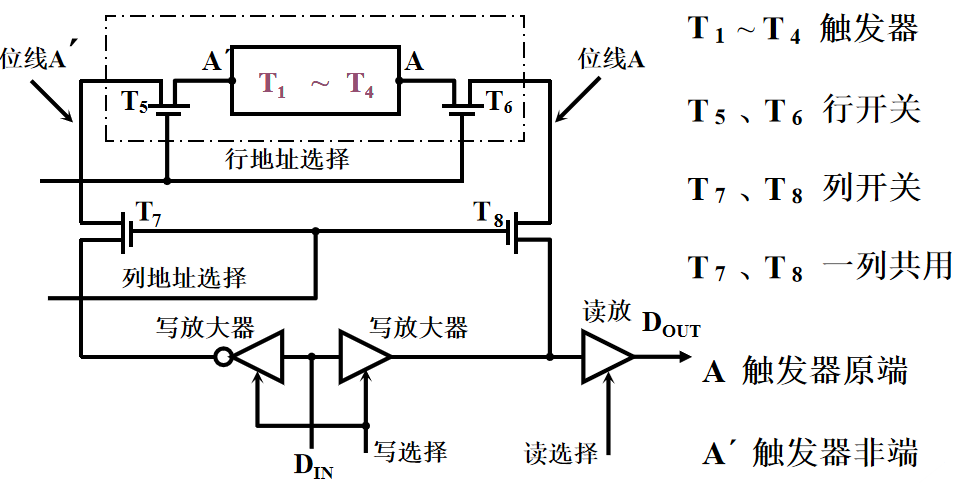
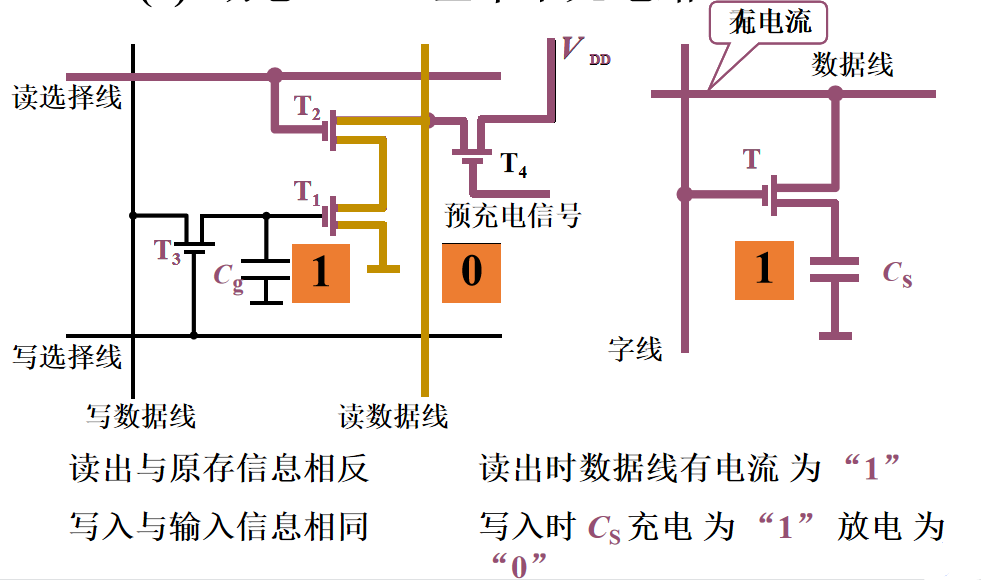
1️⃣ 多久需要刷新一次:刷新周期一般为 2 ms 2️⃣ 每次刷新多少存储单元:以行为单位,每次刷新一行存储单元
————为什么要使用行列地址:减少选通线的数量
3️⃣ 如何刷新:有硬件支持,读出一行的信息后重新写入,占用1个读/写周期 4️⃣ 在什么时候刷新:
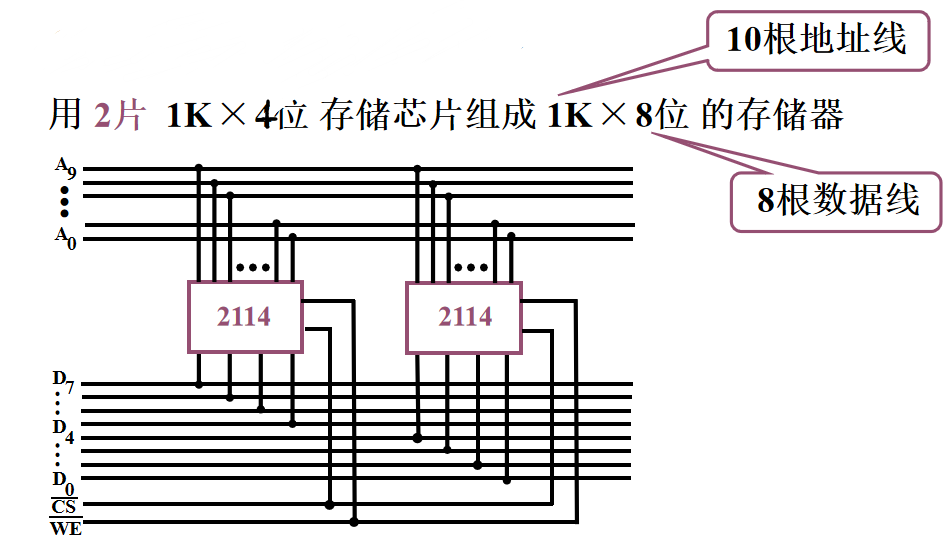
片选线相同,分配数据线
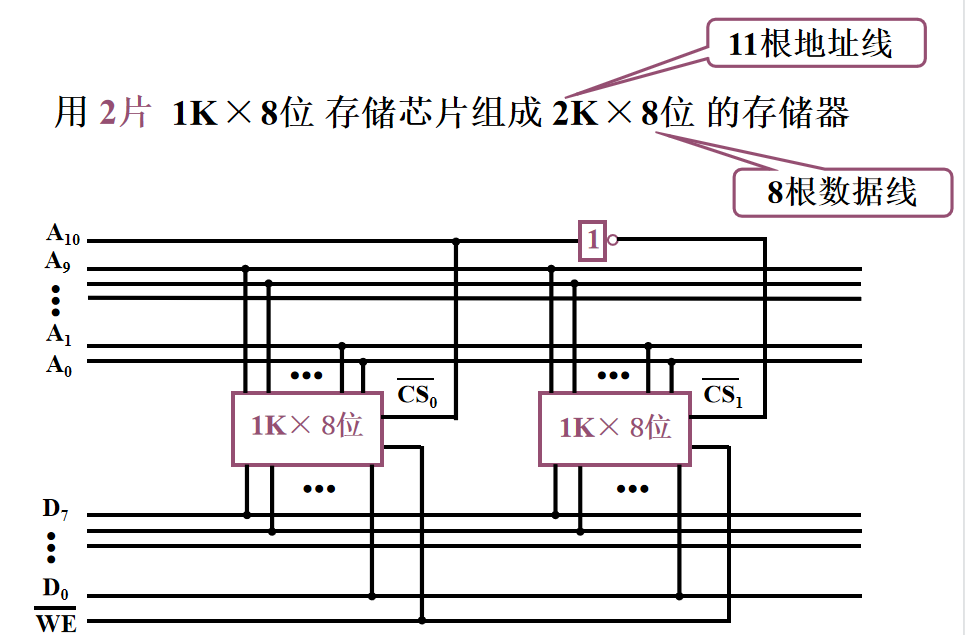
数据线相同,设置片选线
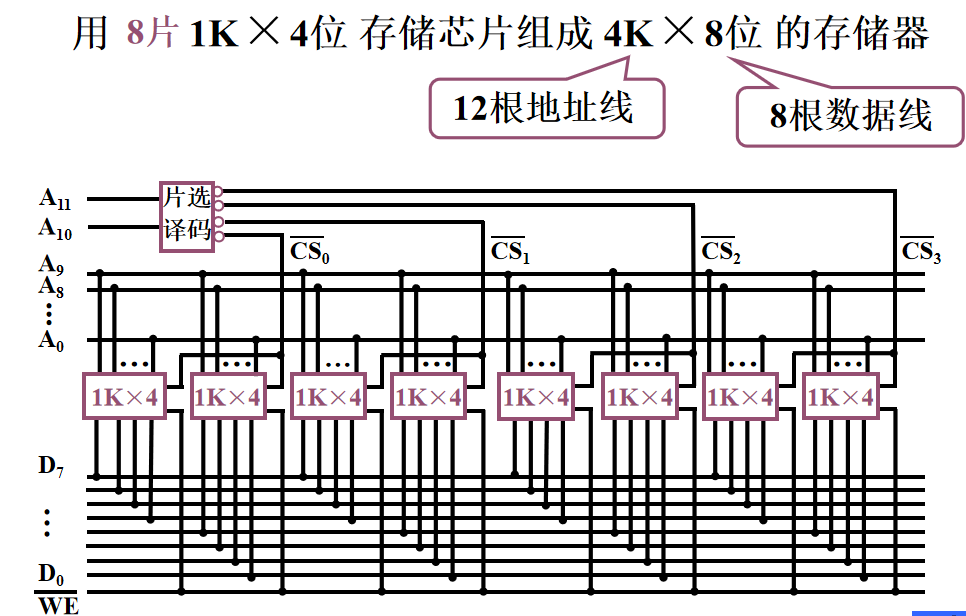
数据线和片选线都要重新考虑
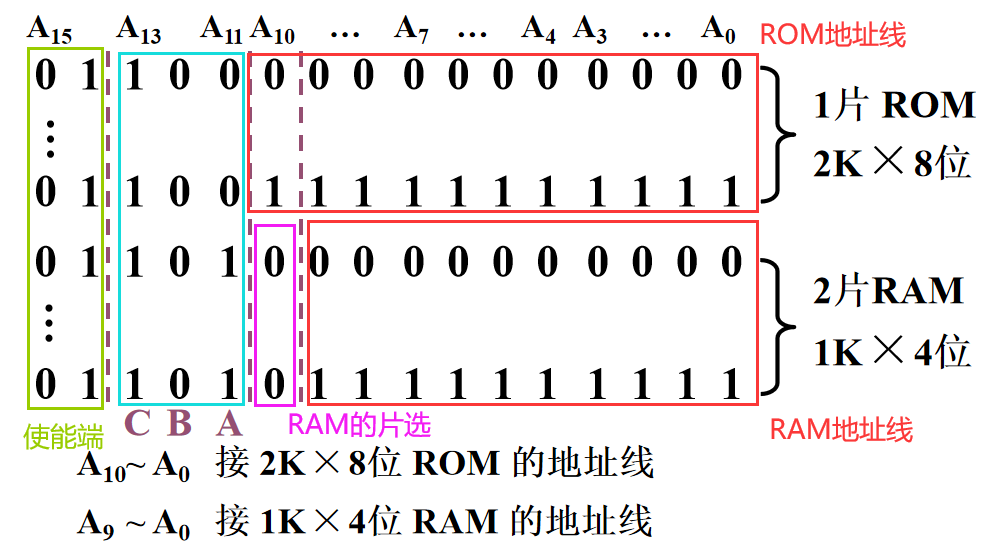
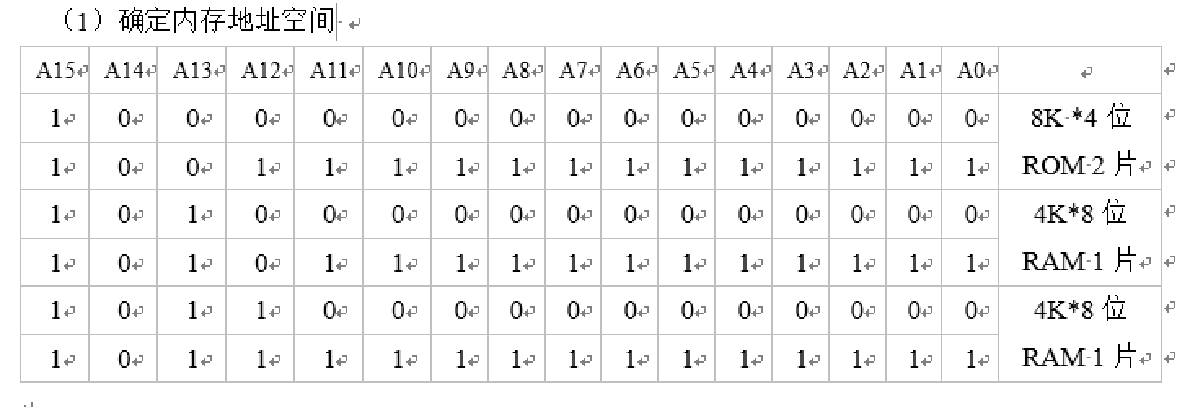
🔔 系统程序区用ROM,用户程序区用RAM 1️⃣ 写出对应的二进制地址码
2️⃣ 确定芯片的数量及类型 由题目知 CPU 数据线8根,则存储器位数应扩展为8位。再根据题目所给的存储芯片 系统程序区选择一片 2 K * 8 位的存储芯片 用户程序区选择两片 1 K * 4 位的存储芯片 3️⃣ 分配地址线
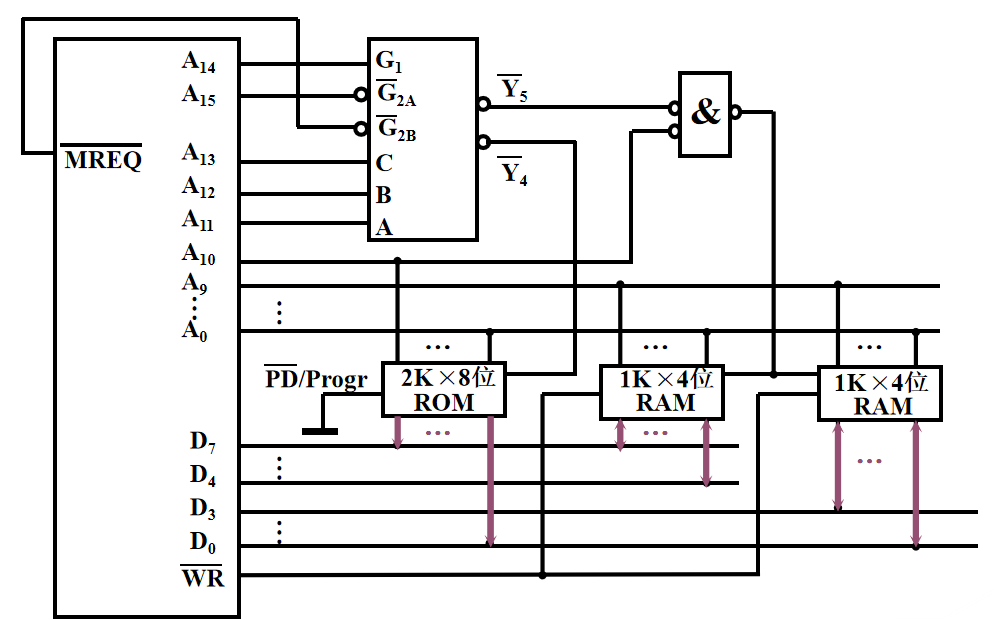
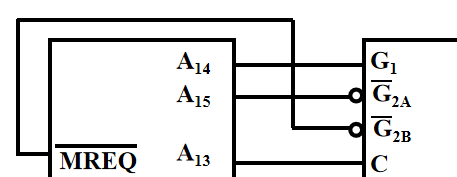
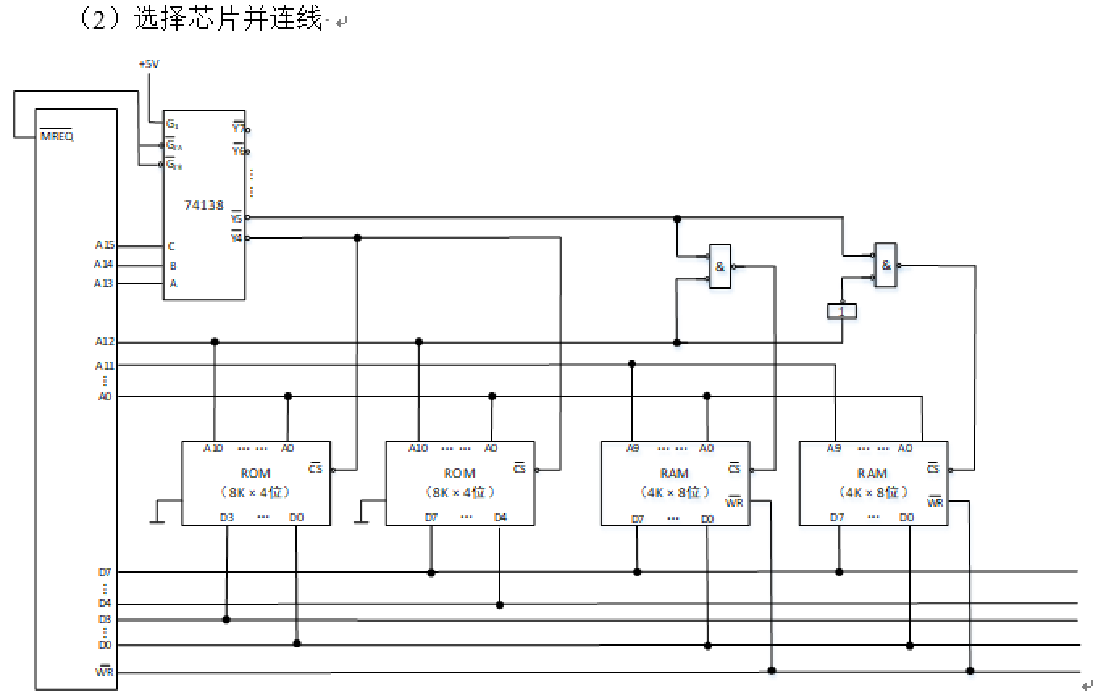
4️⃣ 确定片选信号 RAM 是位拓展,共享片选线,分配数据线 而 ROM 和 RAM 需要考虑片选线的设置 译码器的 Y4 端可以作为 ROM 的片选线端口 译码器的 Y5 端和 RAM 的 A10 地址线可以联合作为 RAM 的片选控制 🔔 有一个默认的原则:不要有任何地址线空着不用!!! 5️⃣ 连接图
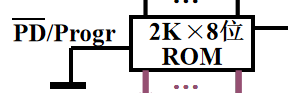
6️⃣ 注意的细节 ROM 要接地
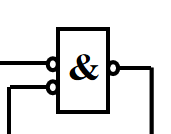
与门都取了非,也就是说输入的数据都为 0 时,输出为 1
RAM 的地址线分配,RAM 要连接读写控制线 WR
使能端只有输入信号为 G1 G2A G2B: 1 0 0 时才工作
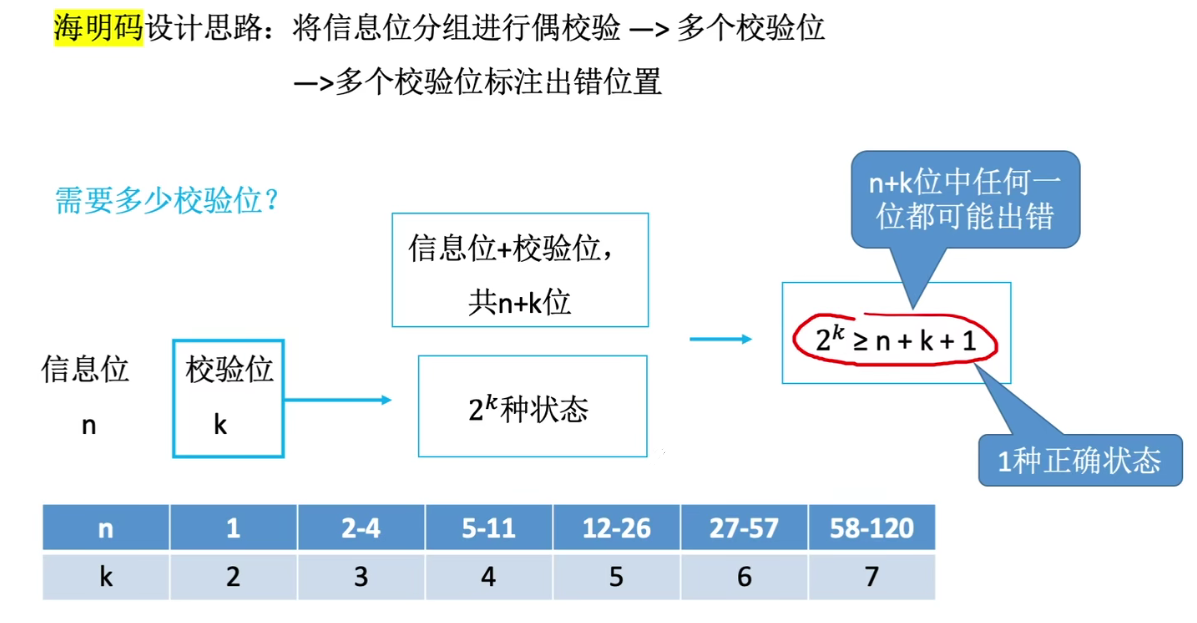
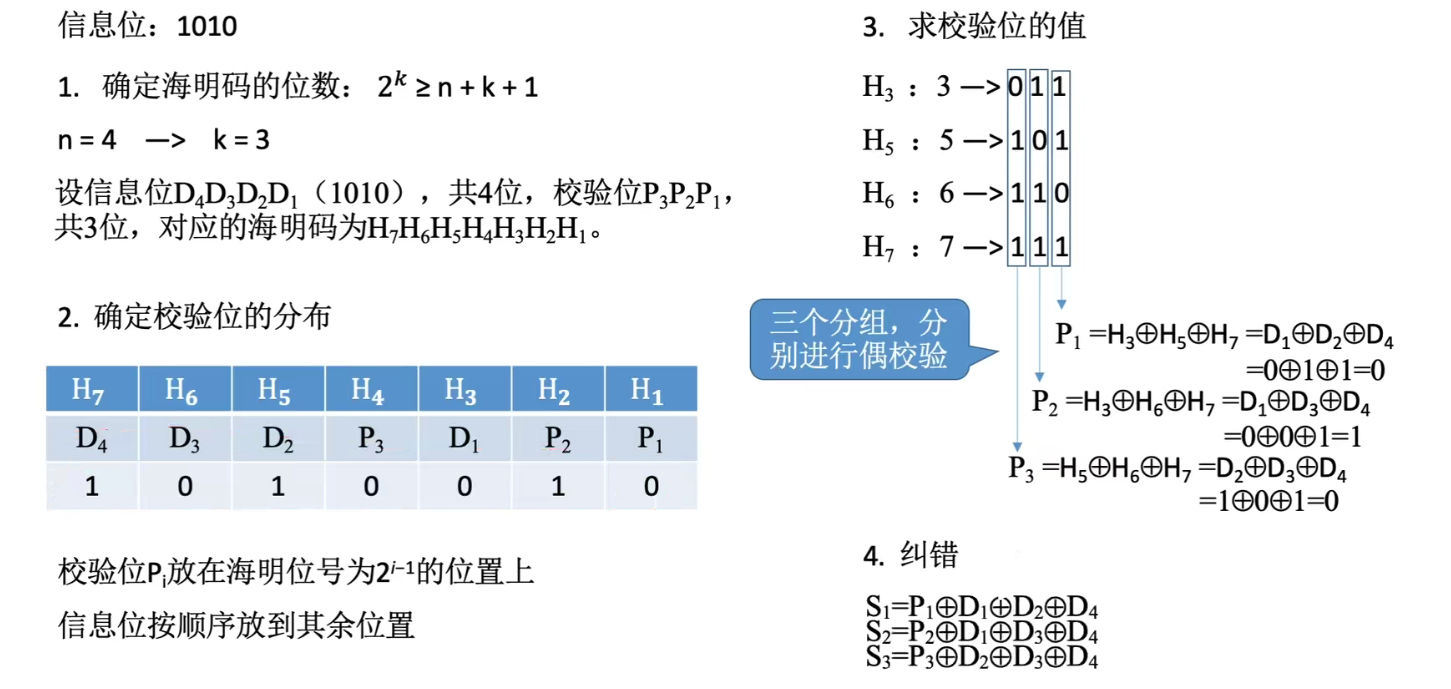
该题与上一个题的区别就是 RAM 是字拓展而不是位拓展,所以数据线相同,片选线要配置,用 A12 作为划分 存储器的校验 海明码
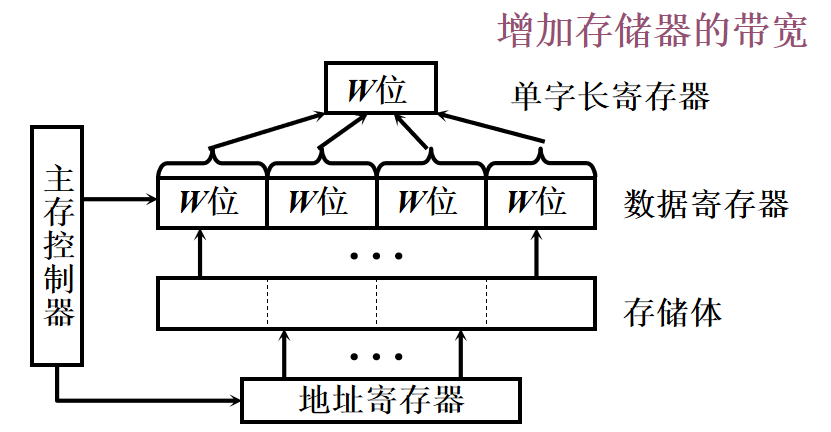
🔔 默认是偶校验,如果题目要求是奇校验,那不论是求海明码还是纠错,每个运算最后都要多异或一个 1 。 提高访存速度的措施采用高速器件 采用层次结构 Cache - 主存 调整主存结构 单体多字系统普通存储器:每行为一个存储单元 🌈 单体多字存储器
每个存储单元存储 m 个字,每个字 w 位,总线宽度为 m 个字。一个存取周期内可以读出 m 个字,也就是 m * w 位的指令或数据,使主存带宽提高到 m 倍 🔔 缺点:指令和数据在主存内必须是连续存放的,一旦遇到转移指令,或者操作数不能连续存放,这种方法的效果就不明显 多体并行系统
高位交叉(顺序存储) 存储体的存储单元通过地址的高位进行分组,高位地址相同的存储单元属于同一个存储体 CPU 有较大概率需要连续访问同一个存储体,效率较低 低位交叉(交叉存储) 存储体的存储单元通过地址的低位进行分组,低位地址相同的存储单元属于同一个存储体 CPU 可以较大概率同时访问多个存储体,效率高,属于流水线方式 可以在不改变每个模块存取周期的前提下,提高存储器的带宽 可以并行工作,如总线宽度为 mw 时,可以同时取出长度为 mw 的数据。等同于高位交叉存储方式的 m 个存储体并行工作 流水线的概念
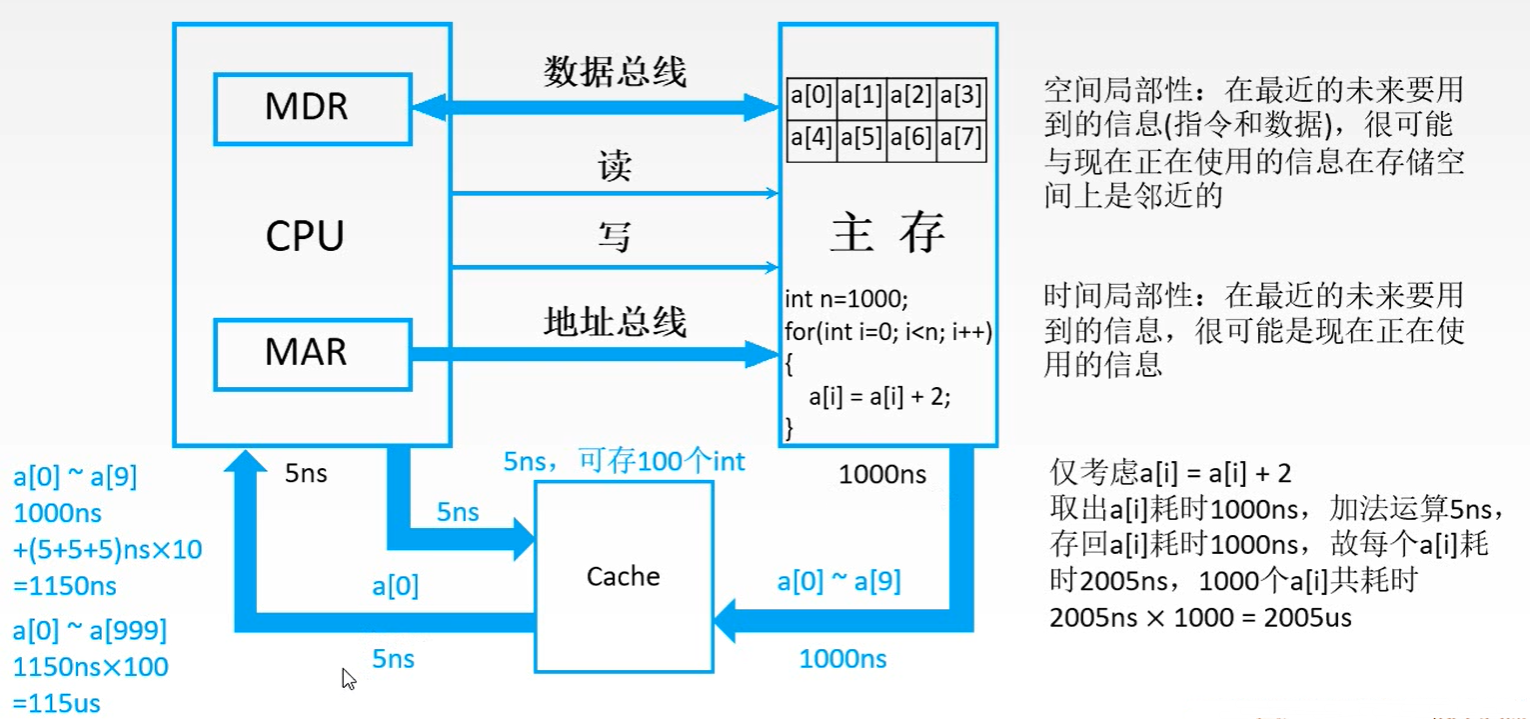
设有 4 个模块组成的四体存储器结构,每个体的存储字长为 32 位,存储周期为 200 ns。假设数据总线宽度为 32 位,总线传输周期为 50 ns,试求顺序存储和交叉存储的存储器带宽。 解:顺序存储和交叉存储连续读出 4 个字的信息量是 32 * 4 = 128 位。 顺序存储器连续读出 4 个字的时间是 200 ns * 4 = 800 ns 交叉存储其连续读出 4 个字的时间是 200 ns + 50 ns * (4 - 1) = 350 ns 顺序存储器的带宽是 128 b / 800 ns = 16 * 10 ^ 7 bps 交叉存储器的带宽是 128 b / 350 ns = 37 * 10 ^ 7 bps 高速缓冲存储器 概述 局部性原理
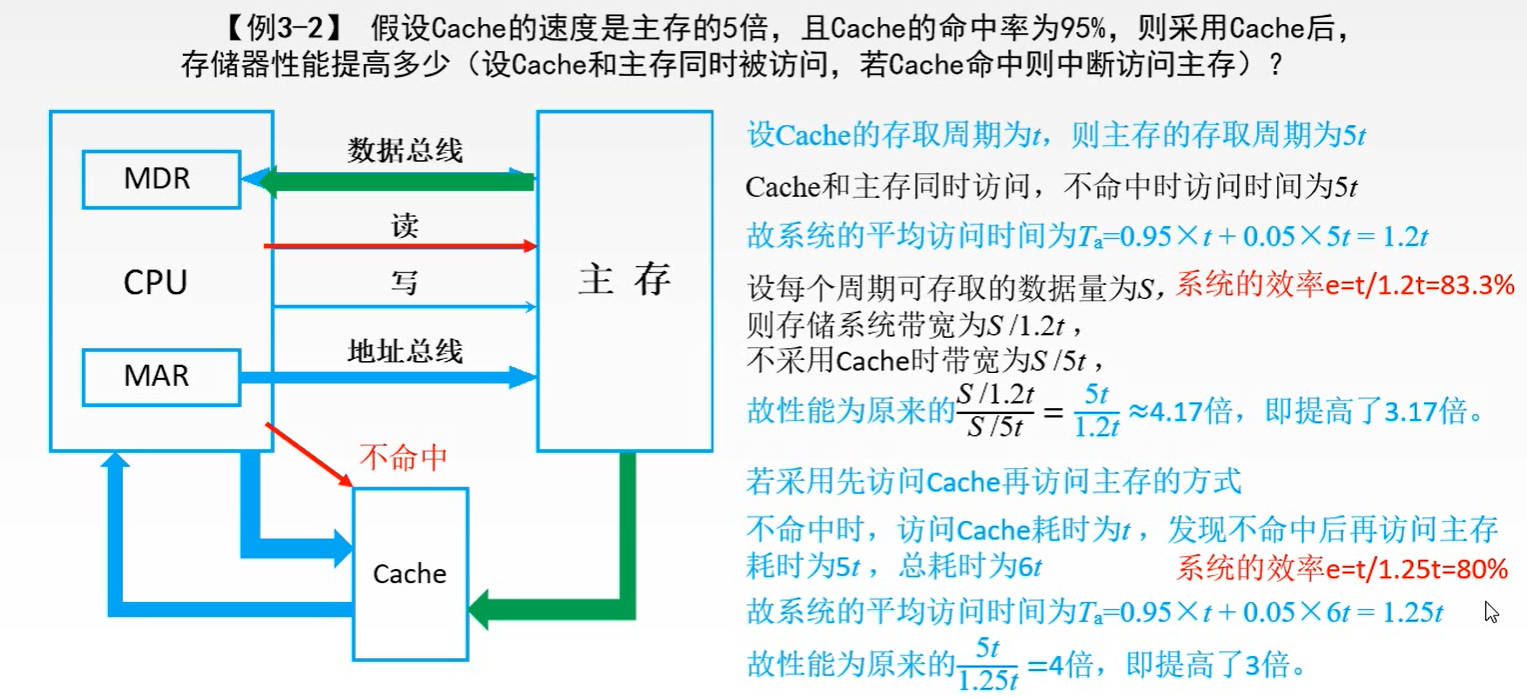
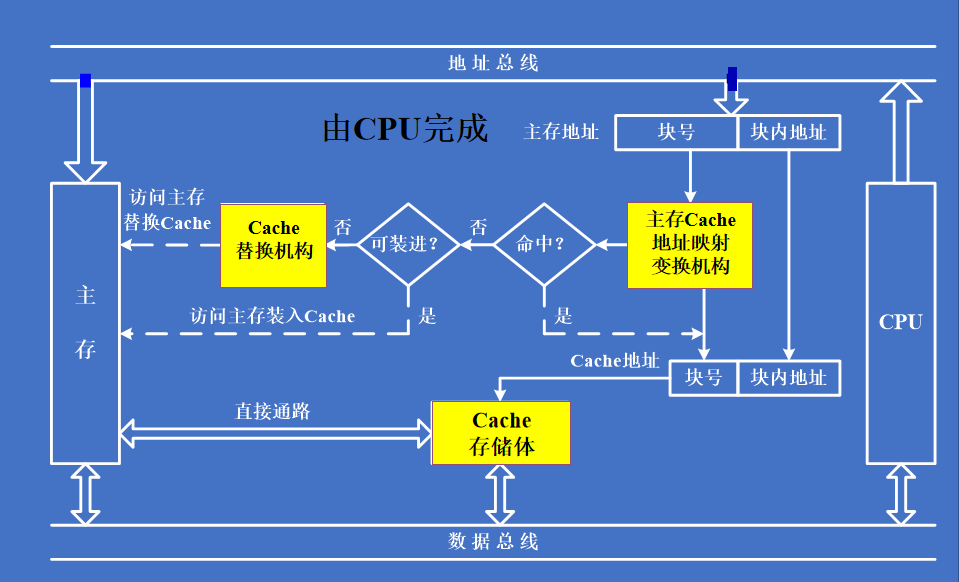
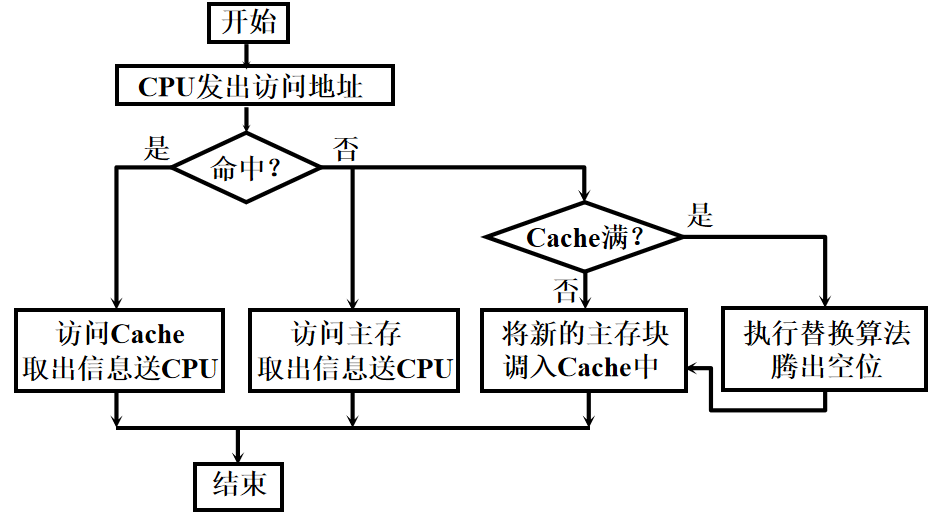
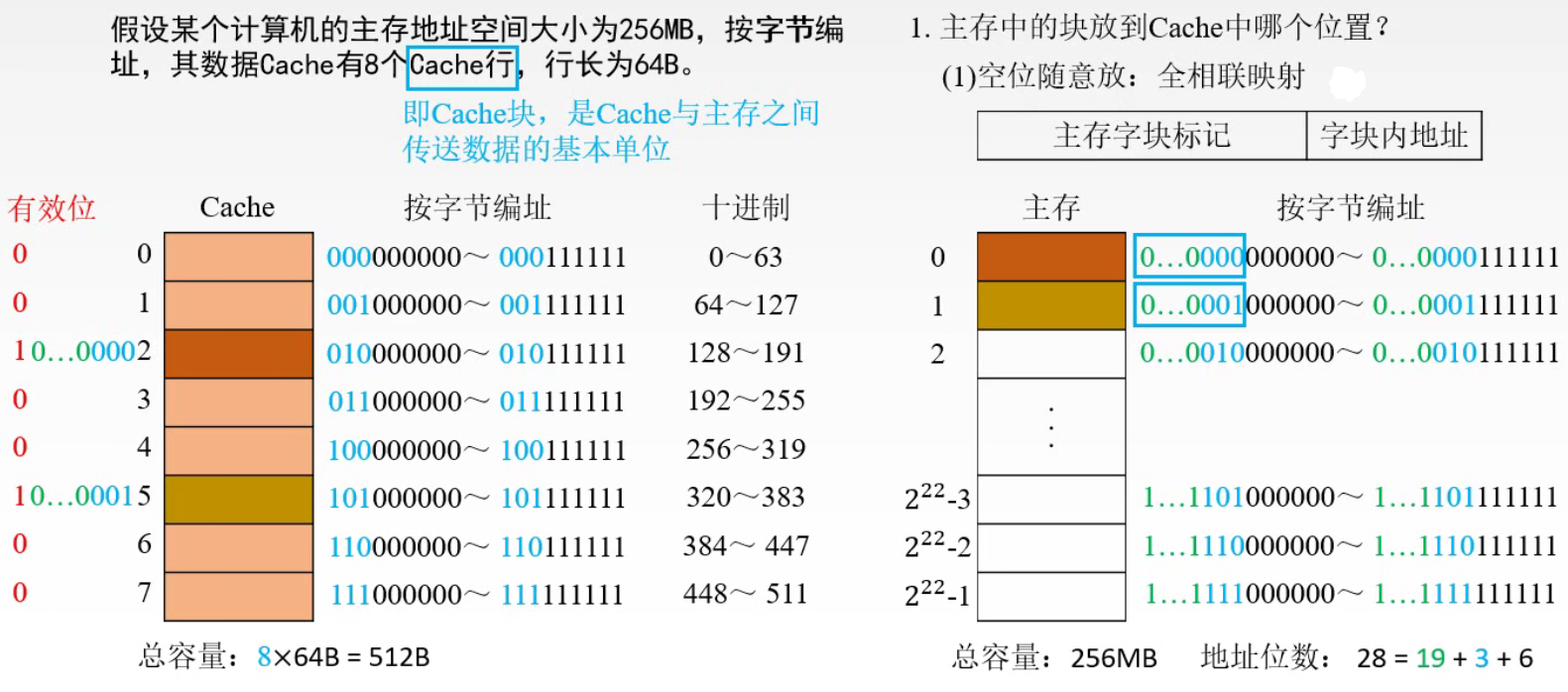
CPU 和主存(DRAM)的速度存在差异,为了避免 CPU 可能存在的“空等”现象 性能分析1️⃣ 命中: 1.主存块调入缓存 2.主存块与缓存块建立了对应关系 3.用标记记录与某缓存块建立了对应关系的主存块号 2️⃣ 未命中: 1.主存块未调入缓存 2.主存块与缓存块未建立对应关系 3️⃣ Cache 的命中率: 1.CPU 欲访问的信息在 Cache 中的 比率 2.命中率 与 Cache 的 容量 与 块长 有关 4️⃣ 主存系统的效率
1.效率 e 与 命中率 有关
🌈 例题
🌈 读
🌈 写
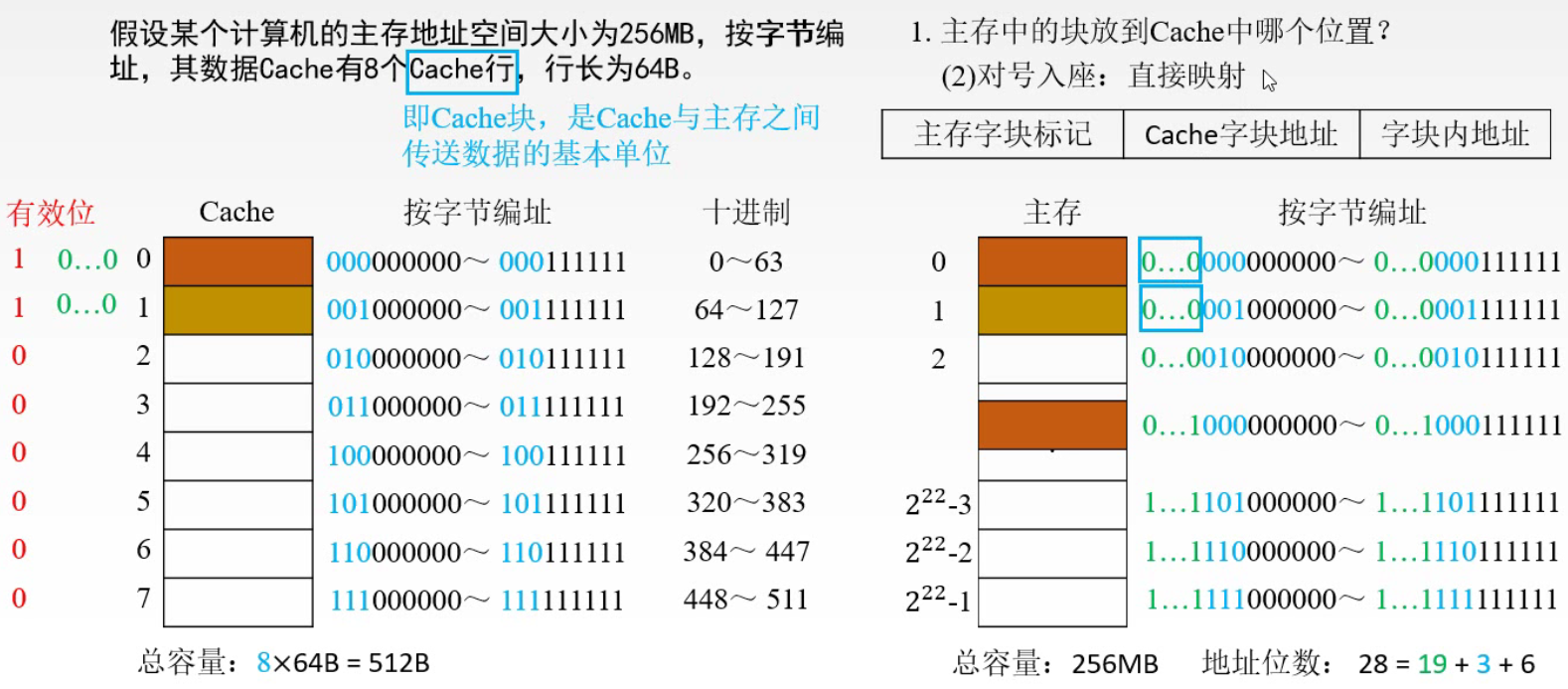
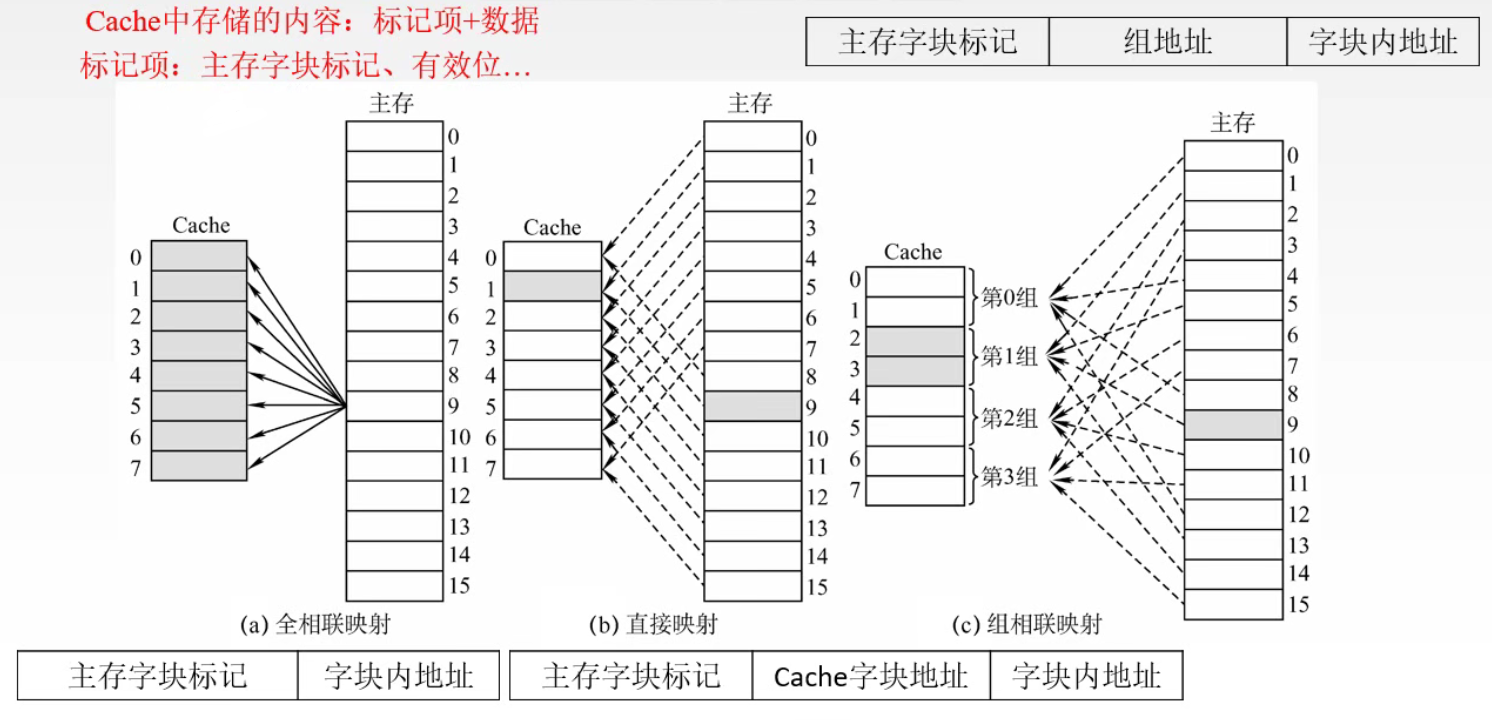
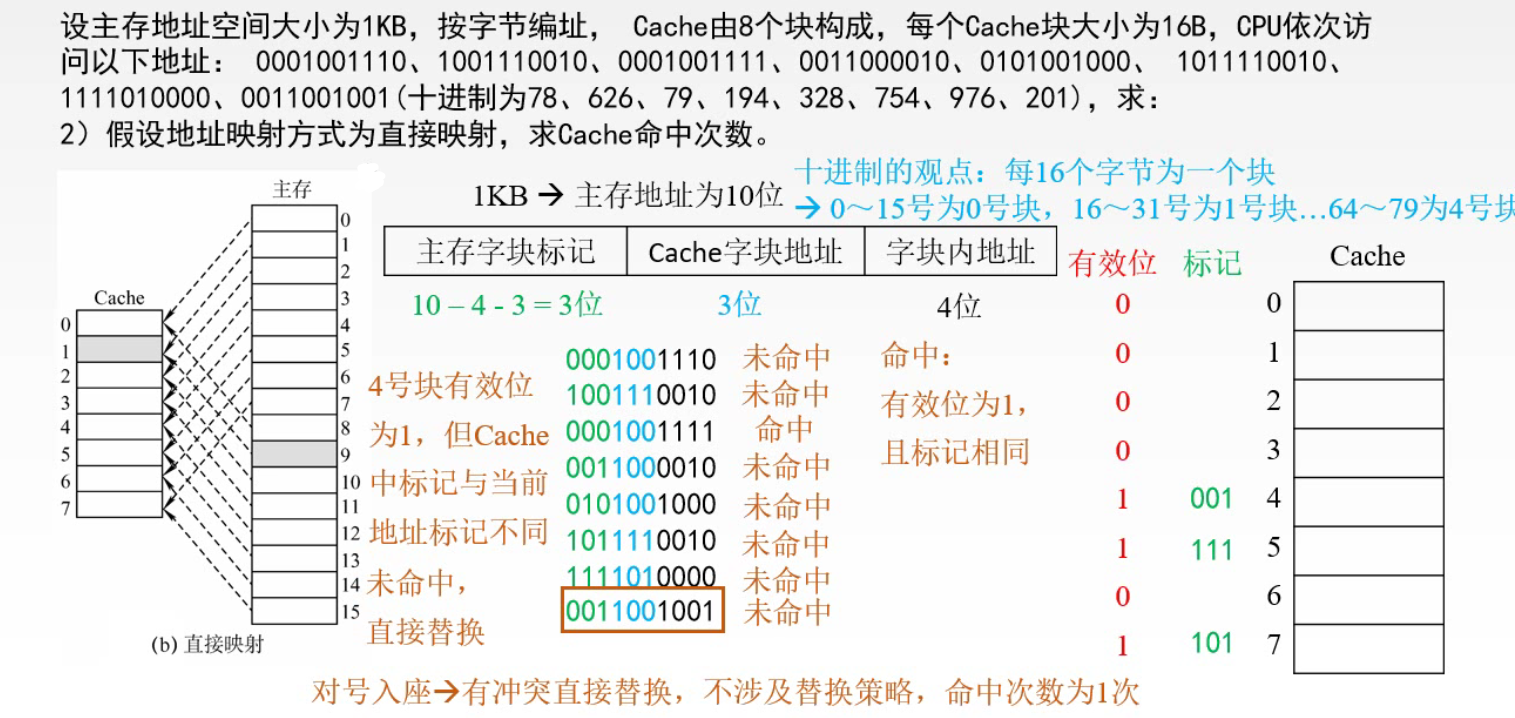
1️⃣ 单一缓存和二级缓存 2️⃣ 统一缓存和分立缓存 Cache – 主存的地址映射 直接映射
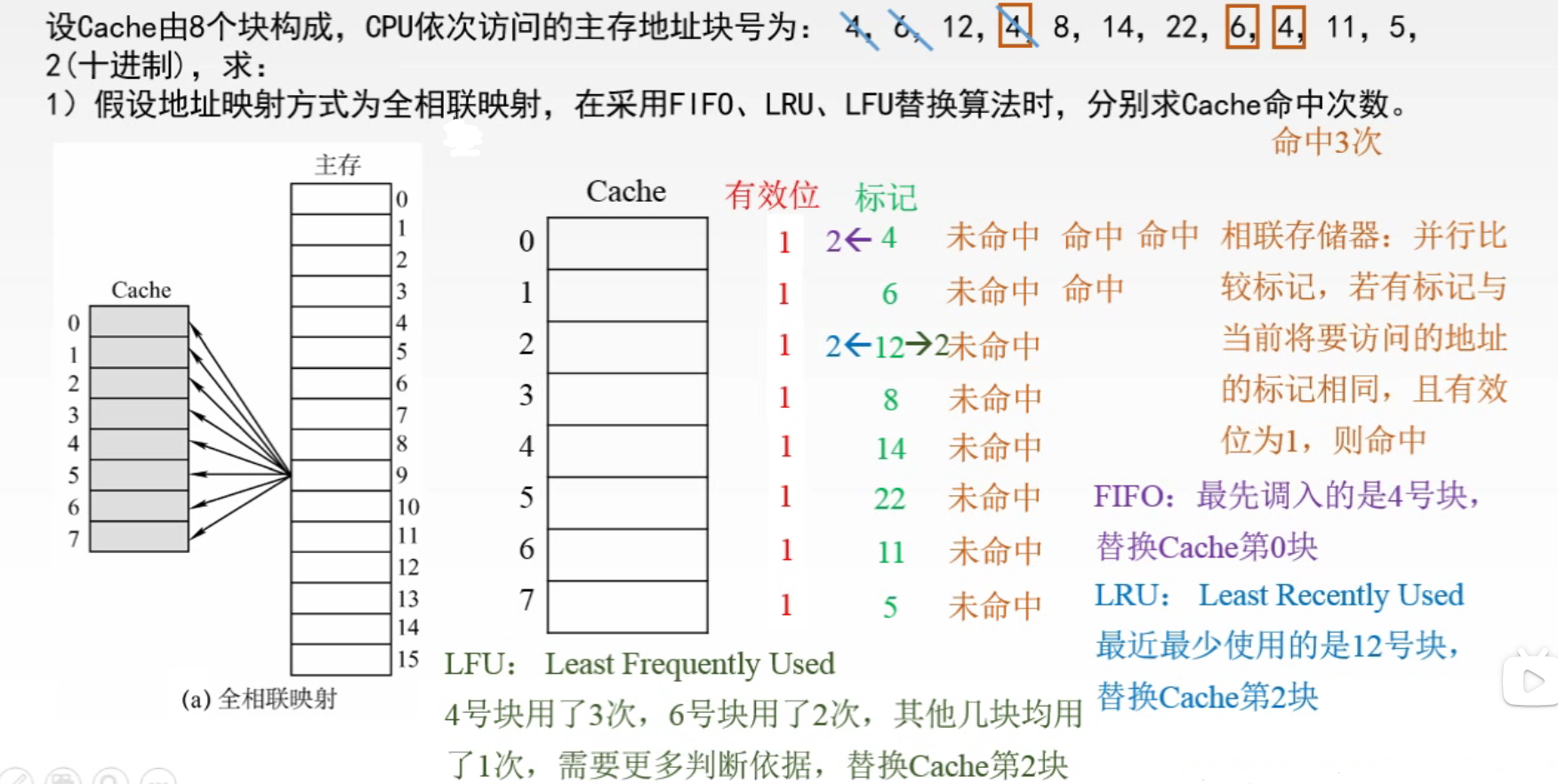
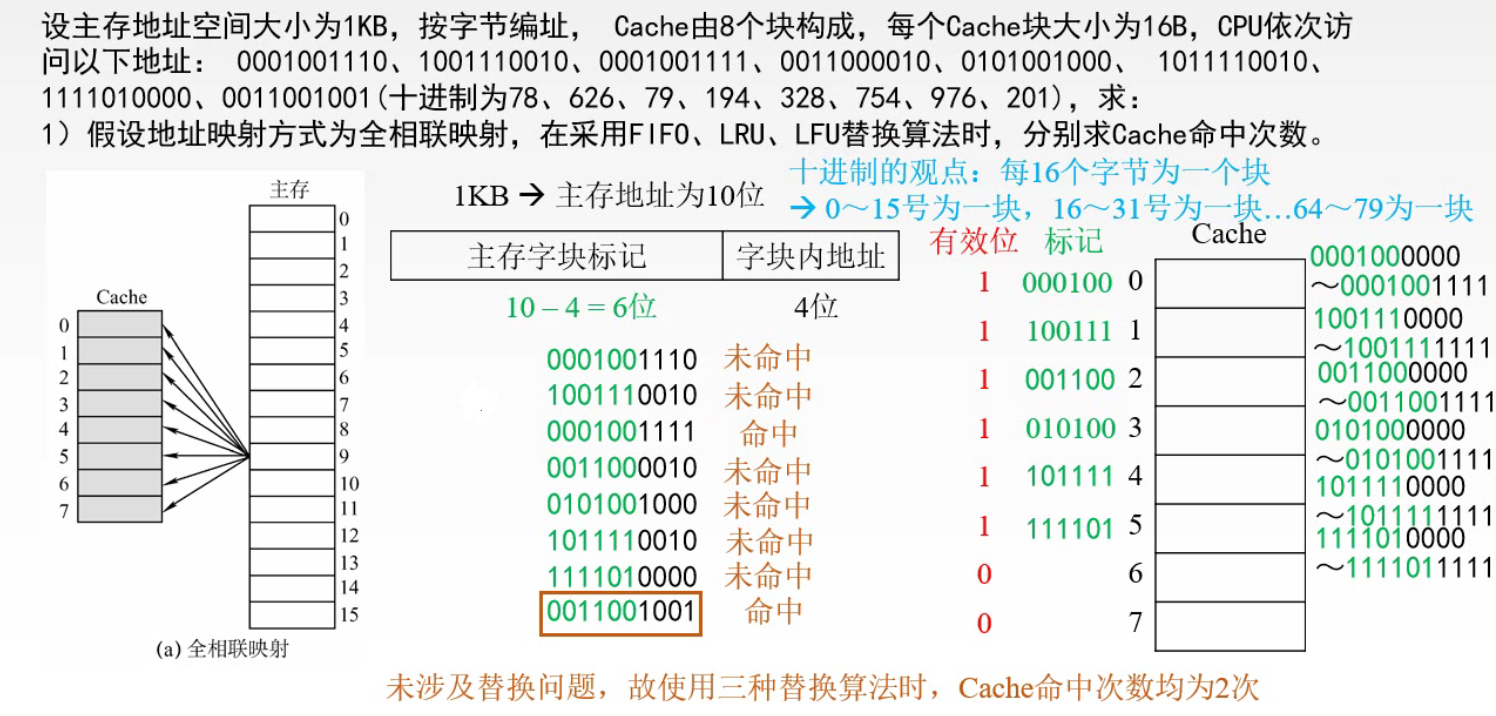
1️⃣ 每个缓存块 i 可以和若干个主存块对应 2️⃣ 每个主存块 j 只能和一个缓存块对应 3️⃣ i = j mod C (C 是 Cache 块总数) 全相联映射主存中的任一块可以映射到缓存中的任一块
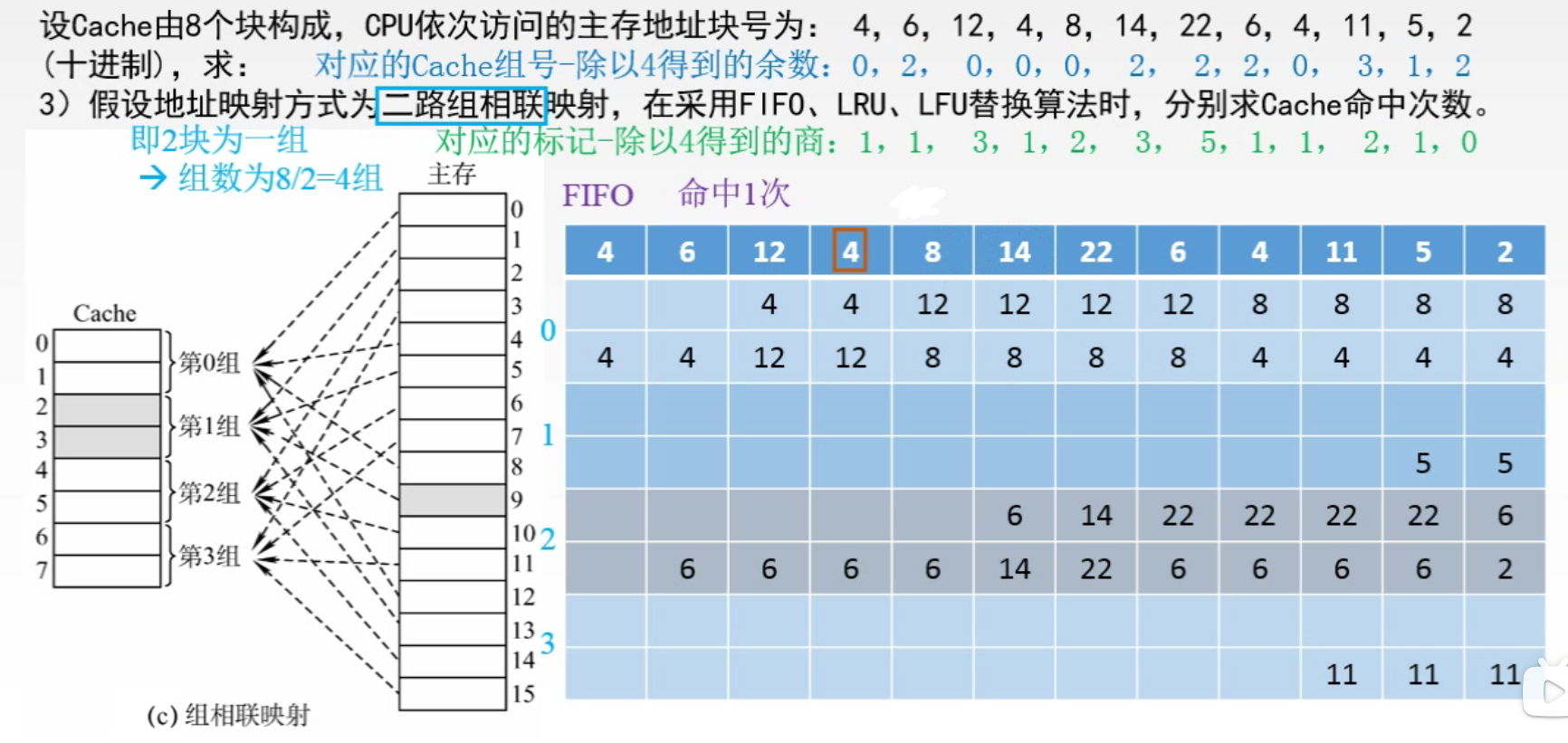
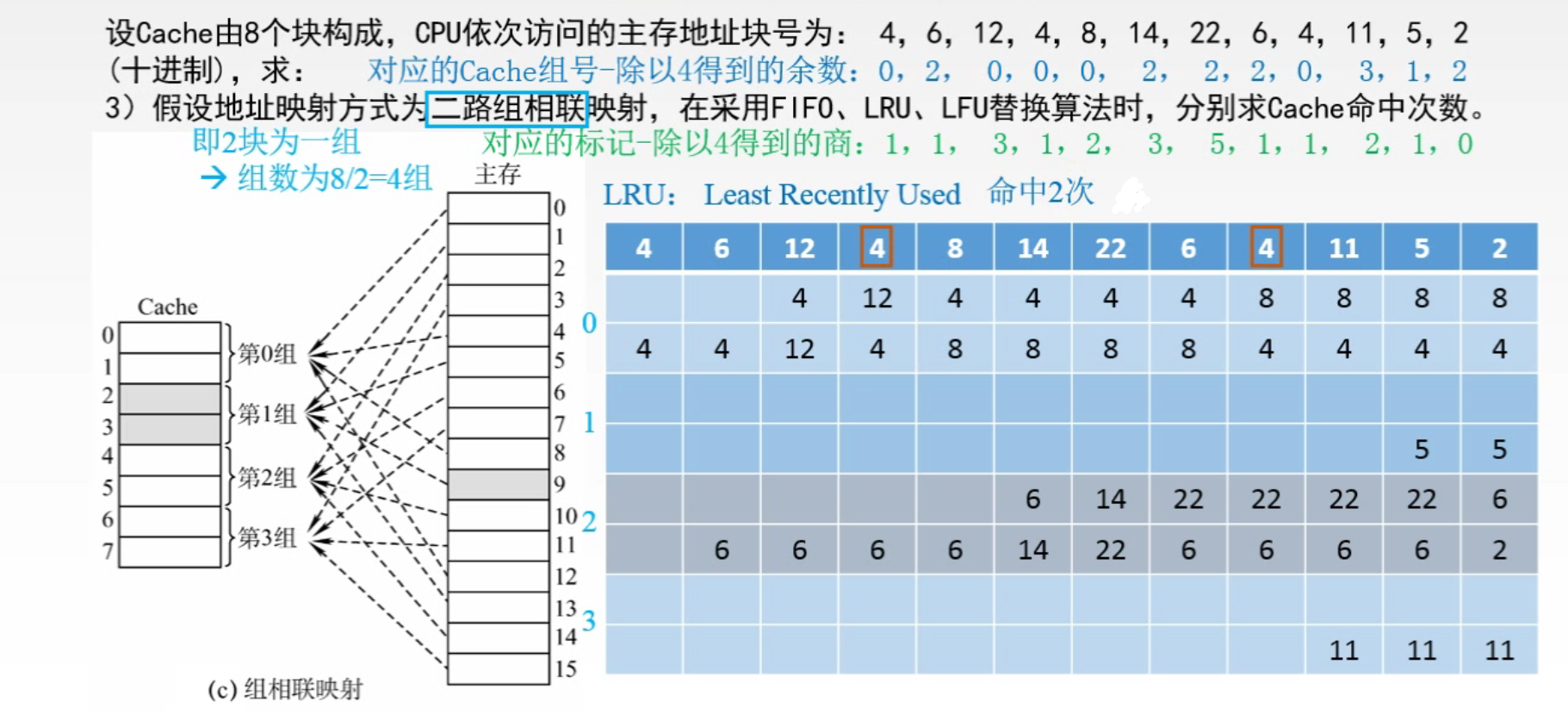
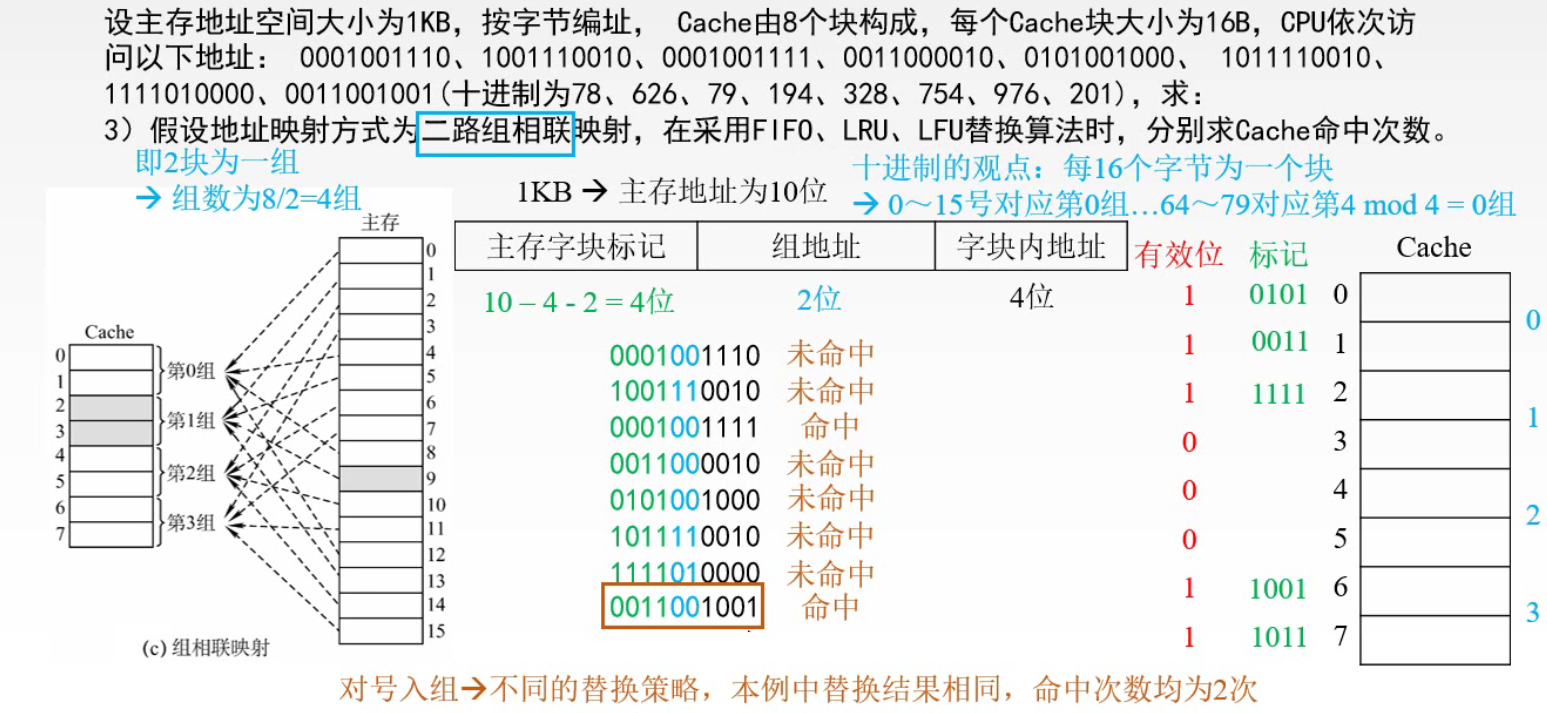
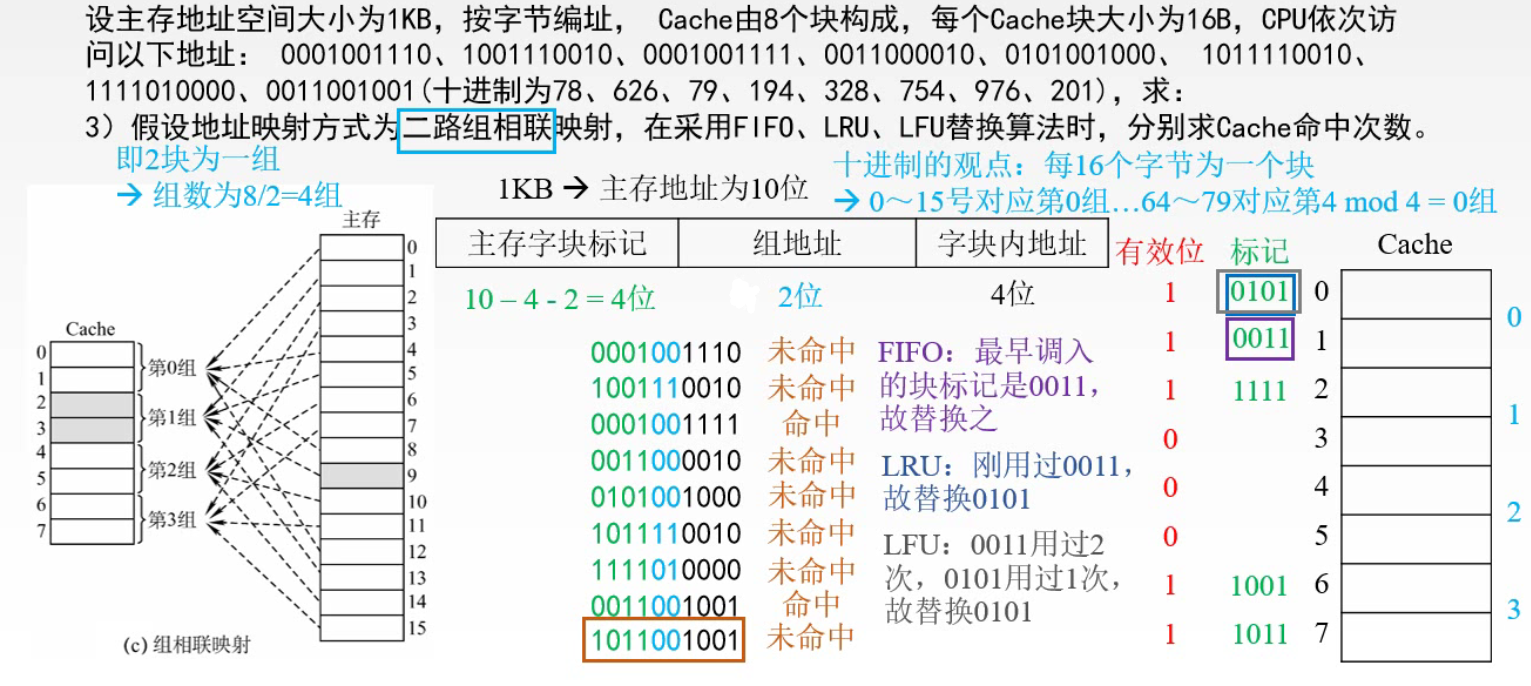
某一主存块 j 按模 Q 映射到 缓存 的第 i 组中的任一块 🔔 n 路组相联:Cache n 个块为一组,即 Q = n 1️⃣ 当 n = 1 时,Cache 分成 1 组,相当于全相联映射 2️⃣ 当 n = Cache 块行数时,Cache 的每个块都是一组。相当于直接映射 三种映射方式的总结
🌈 FIFO:每个组内,就是一个小的队列,组内整体向上移动一个单位,新元素放下面,弹出最上面的元素
🌈 LRU:每个组中,最不常用的放最上,刚刚用到的(命中)的放最下;遇到新的元素且组满,则组内整体向上移动一个单位,新元素放最下,弹出最上面的元素
|


























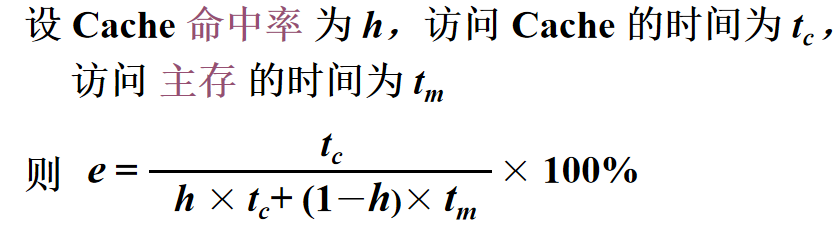




【本文地址】
今日新闻 |
推荐新闻 |