深度学习 |
您所在的位置:网站首页 › bp神经网络构建原理图 › 深度学习 |
深度学习
|
目录 一、概念与定义 二、损失函数/代价函数(loss) 三、梯度下降法 二维w与loss: 三维w与loss: 四、常用激活函数 1、softmax激活函数 2、sigmoid激活函数 3、tanh函数 4、softsign函数 sigmoid、tanh、softsign函数对比 5、relu函数 对比tanh和relu激活函数 4个隐藏层tanh激活函数 4个隐藏层relu激活函数 2个隐藏层relu激活函数 五、梯度消失与梯度爆炸 1、梯度消失 2、梯度爆炸 3、解决梯度消失与梯度爆炸 一、概念与定义
正向传播:把样本的特征从输入层进行输入,信号经过各个隐藏层逐层处理后,最后从输出层传出。 反向传播:对于网络的实际输出与期望输出之间的误差,把误差信号从最后一层逐层反传,从而获得各个层的误差学习信号,再根据误差学习信号来修正各个层神经元的权值。 周而复始地进行,权值不断调整的过程,就是神经网学习训练的过程。 二、损失函数/代价函数(loss)损失函数的值越小,说明模型的预测值越接近真实值。 我们可以利用这个函数来优化模型参数。 最常见的损失函数是均方差损失函数(二次损失函数):
梯度下降法是最常用的方法之一。 既然在变量空间的某一点处,函数沿梯度方向具有最大的变化率,那么在优化代价函数的时候,就可以沿着负梯度方向去减小代价函数的值。 梯度下降法优化公式:
首先w移动到了w=3的位置:
当 w 为-3 时,w 所处位置的梯度应该是一个负数,梯度下降法在优化代价函数的时候,是沿着负梯度方向去减小代价函数的值,所以负梯度是一个正数,w 的值应该变大。 w再次移动,到w=2的位置:
当 w 为 2 时,w 所处位置的梯度应该是一个正数,梯度下降法在优化代价函数的时候,是沿着负梯度方向去减小代价函数的值,所以负梯度是一个负数, w 的值应该变小。 我们可以发现不管 w 处于那一个位置,当 w 向着负梯度的方向进行移动时,实际上就是向着可以使 loss 值减小的方向进行移动。只不过 它每一次是移动一步,这个步子的大小会受到学习率和所处位置梯度的大小所影响。 三维w与loss:
在图中随机选取两个 w1 和 w2 的初始值 p1 和 p2,然后从 p1、p2 这两个初始位置,开始使用梯度下降法优化网络参数:  四、常用激活函数
四、常用激活函数
前面介绍的sign函数(符号函数)、purelin函数(线性函数)都不能很好地解决非线性问题。下面介绍神经网络中常用的非线性激活函数:softmax函数、sigmoid函数、tanh函数、softsign函数、relu函数。这些非线性激活函数有助于帮忙解决非线性问题。 1、softmax激活函数将多个神经元的输出,映射到(0,1)区间内。(可以看成概率来理解,从而来进行多分类) 公式:
sigmoid函数也称为逻辑函数,函数公式为:
函数的取值范围是 0-1 之间,当 x 趋向于-∞的时候函数值趋向于 0; 当 x 趋向于+∞的时候函数值趋向于 1。 3、tanh函数tanh函数也称为双曲正切函数。函数公式:
softsign函数公式:
函数的取值范围是-1-1 之间,当 x 趋向于-∞的时候函数值趋向于-1; 当 x 趋向于+∞的时候函数值趋向于 1。 sigmoid、tanh、softsign函数对比
relu函数公式:
可以发现: ReLU 激活函数所描绘出来的边界其实是一条一条的直线构成的,不存在曲线。 模型的拟合效果其实还跟其他一些因素相关,比如说 每一层隐藏层的神经元越多,那么模型的拟合能力也就越强 。 模型训练的周期越多,模型的拟合能力就越强 。 五、梯度消失与梯度爆炸 1、梯度消失梯度消失概念:学习信号随着网络传播逐渐减小。 学习信号从输出层一层一层向前反向传播的时候,每传播一层学习信号就会变小一点,经过多层传播后,学习信号就会接近于 0,从而使得权值∆w调整接近于 0。 ∆w 接近于 0 那就意味着该层的参数不会发生改变,不能进行优化。参数不能优化,那整个网络就不能再进行学习了。 2、梯度爆炸梯度爆炸概念:学习信号随着网络传播逐渐增大。 如果学习信号ReLu表达式:f(x)=max(0,x),当小于0时,f(x)的取值为0;当x>0时,f(x)的取值等于x。
|


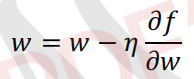




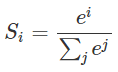


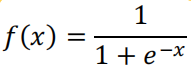

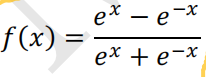

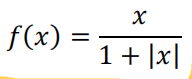


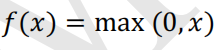







【本文地址】
今日新闻 |
推荐新闻 |