Appstore评分数据python实战 |
您所在的位置:网站首页 › appstore评分标准 › Appstore评分数据python实战 |
Appstore评分数据python实战
|
Appstore数据集中的主要字段: id:APP的编号id track_name:App名称 size_bytes:App的大小(单位:byte) price:价格(单位:美元) rating_count_tot:该App所有版本的用户评分数量 rating_count_ver:该App当前版本的用户评分数量 primae_genre:App类别 user_rating:该App所有版本的用户评分 user_rating_ver:该App当前版本的用户评分 sup_devices:支持的ios设备数量 ipadSc_urls:App提供的截屏展示数量 lang:支持的语言数量 要分析的业务问题: 1,免费或者收费的APP集中在哪些类别? 2,免费和收费的app在不同评分区间的分布情况如何? 3,app的大小和用户评分是否有关系? 打开python,开始敲代码 首先导入要用到的模块和打开数据集 import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns get_ipython().run_line_magic('matplotlib', 'inline') df=pd.read_csv(r'applestore.csv') #打开数据了解数据总体概括 df.head() #读取前5行的数据
size_bytes为App大小,单位为byte。为了计算方便,将其转化为MB单位。 df['size_mb']=df['size_bytes']/(1024*1024)根据price价格新增标签,将app分为0(免费)和1(付费) df['paid']=df['price'].apply(lambda x:1 if x>0 else 0)然后用head()查看处理后的数据表情况 到这里,初步完成数据清洗和数据转换。 然后开始进行分析。 根据类别对App进行分组 #value_counts()只能对应series,不能对于整个dataframe进行操作 df.prime_genre.value_counts()
|


 开始数据预处理 Unnamed: 0 为自动生成的记录ID,为无关变量,删除
开始数据预处理 Unnamed: 0 为自动生成的记录ID,为无关变量,删除
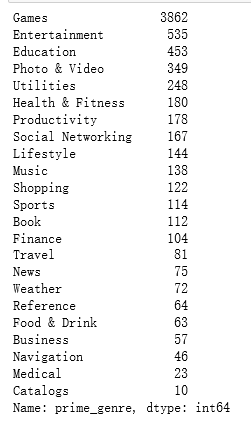 运行可知,Game类别中的App数量最多 然后根据价格对App进行分组
运行可知,Game类别中的App数量最多 然后根据价格对App进行分组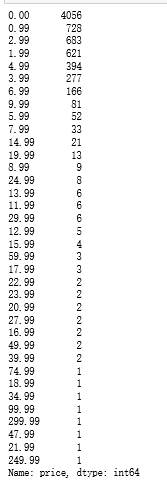 运行可知,免费的App数量最多。为了计算方便,取价格在0到49.99的记录进行接下来的分析。
运行可知,免费的App数量最多。为了计算方便,取价格在0到49.99的记录进行接下来的分析。【本文地址】
今日新闻 |
推荐新闻 |