AI芯片架构、分类、关键技术 |
您所在的位置:网站首页 › ai关键技术有哪些 › AI芯片架构、分类、关键技术 |
AI芯片架构、分类、关键技术
|
人工智能芯片目前有两种发展路径:一种是延续传统计算架构,加速硬件计算能力,主要以 3 种类型的芯片为代表,即 GPU、 FPGA、 ASIC,但CPU依旧发挥着不可替代的作用;另一种是颠覆经典的冯·诺依曼计算架构,采用类脑神经结构来提升计算能力,以IBM TrueNorth 芯片为代表。 当前阶段,GPU 配合 CPU 仍然是 AI 芯片的主流,而后随着视觉、语音、深度学习的算法在 FPGA以及 ASIC芯片上的不断优化,此两者也将逐步占有更多的市场份额,从而与GPU达成长期共存的局面。从长远看,人工智能类脑神经芯片是发展的路径和方向。 AI 芯片是人工智能时代的技术核心之一,决定了平台的基础架构和发展生态。
AI 芯片按技术架构分类可分为GPU(Graphics Processing Unit,图形处理单元)、半定制化的 FPGA、全定制化 ASIC和神经拟态芯片等。 各个芯片的特点如下: GPU 通用性强、速度快、效率高,特别适合用在深度学习训练方面,但是性能功耗比较低。 FPGA 具有低能耗、高性能以及可编程等特性,相对于 CPU 与 GPU 有明显的性能或者能耗优势,但对使用者要求高。 ASIC 可以更有针对性地进行硬件层次的优化,从而获得更好的性能、功耗比。但是ASIC 芯片的设计和制造需要大量的资金、较长的研发周期和工程周期,而且深度学习算法仍在快速发展,若深度学习算法发生大的变化,FPGA 能很快改变架构,适应最新的变化,ASIC 类芯片一旦定制则难于进行修改。 1、传统 CPU计算机工业从1960年代早期开始使用CPU这个术语。迄今为止,CPU从形态、设计到实现都已发生了巨大的变化,但是其基本工作原理却一直没有大的改变。 通常 CPU 由控制器和运算器这两个主要部件组成。 传统的 CPU 内部结构图如图所示:
传统CPU内部结构图(ALU计算模块)
从图中我们可以看到:实质上仅单独的ALU模块(逻辑运算单元)是用来完成数据计算的,其他各个模块的存在都是为了保证指令能够一条接一条的有序执行。这种通用性结构对于传统的编程计算模式非常适合,同时可以通过提升CPU主频(提升单位时间内执行指令的条数)来提升计算速度。 但对于深度学习中的并不需要太多的程序指令、 却需要海量数据运算的计算需求, 这种结构就显得有些力不从心。尤其是在功耗限制下, 无法通过无限制的提升 CPU 和内存的工作频率来加快指令执行速度, 这种情况导致 CPU 系统的发展遇到不可逾越的瓶颈。 2、并行加速计算的GPU GPU 作为最早从事并行加速计算的处理器,相比 CPU 速度快, 同时比其他加速器芯片编程灵活简单。 传统的 CPU 之所以不适合人工智能算法的执行,主要原因在于其计算指令遵循串行执行的方式,没能发挥出芯片的全部潜力。与之不同的是, GPU 具有高并行结构,在处理图形数据和复杂算法方面拥有比 CPU 更高的效率。对比 GPU 和 CPU 在结构上的差异, CPU大部分面积为控制器和寄存器,而 GPU 拥有更ALU(逻辑运算单元)用于数据处理,这样的结构适合对密集型数据进行并行处理, CPU 与 GPU 的结构对比如图 所示。
CPU及GPU结构对比图
程序在 GPU系统上的运行速度相较于单核 CPU往往提升几十倍乃至上千倍。随着英伟达、 AMD 等公司不断推进其对 GPU 大规模并行架构的支持,面向通用计算的 GPU(即GPGPU,通用计算图形处理器)已成为加速可并行应用程序的重要手段,GPU 的发展历程可分为 3 个阶段:
第一代GPU(1999年以前),部分功能从CPU分离 , 实现硬件加速 , 以GE(GEOMETRY ENGINE)为代表,只能起到 3D 图像处理的加速作用,不具有软件编程特性。
第二代 GPU(1999-2005 年), 实现进一步的硬件加速和有限的编程性。 1999年,英伟达发布了“专为执行复杂的数学和几何计算的” GeForce256 图像处理芯片,将更多的晶体管用作执行单元, 而不是像 CPU 那样用作复杂的控制单元和缓存,将(TRANSFORM AND LIGHTING) 等功能从 CPU 分离出来,实现了快速变换,这成为 GPU 真正出现的标志。之后几年, GPU 技术快速发展,运算速度迅速超过 CPU。 2001年英伟达和ATI 分别推出的GEFORCE3和RADEON 8500,图形硬件的流水线被定义为流处理器,出现了顶点级可编程性,同时像素级也具有有限的编程性,但 GPU 的整体编程性仍然比较有限。
第三代 GPU(2006年以后), GPU实现方便的编程环境创建, 可以直接编写程序。 2006年英伟达与ATI分别推出了CUDA (Compute United Device Architecture,计算统一设备架构)编程环境和CTM(CLOSE TO THE METAL)编程环境, 使得 GPU 打破图形语言的局限成为真正的并行数据处理超级加速器。
2008年,苹果公司提出一个通用的并行计算编程平台 OPENCL(开放运算语言),与CUDA绑定在英伟达的显卡上不同,OPENCL 和具体的计算设备无关。
GPU芯片的发展阶段
目前, GPU 已经发展到较为成熟的阶段。谷歌、 FACEBOOK、微软、 Twtter和百度等公司都在使用GPU 分析图片、视频和音频文件,以改进搜索和图像标签等应用功能。此外,很多汽车生产商也在使用GPU芯片发展无人驾驶。 不仅如此, GPU也被应用于VR/AR 相关的产业。
但是 GPU也有一定的局限性。 深度学习算法分为训练和推断两部分, GPU 平台在算法训练上非常高效。但在推断中对于单项输入进行处理的时候,并行计算的优势不能完全发挥出来。 3、半定制化的FPGA
FPGA 是在 PAL、 GAL、 CPLD 等可编程器件基础上进一步发展的产物。用户可以通过烧入 FPGA 配置文件来定义这些门电路以及存储器之间的连线。这种烧入不是一次性的,比如用户可以把 FPGA 配置成一个微控制器 MCU,使用完毕后可以编辑配置文件把同一个FPGA 配置成一个音频编解码器。因此, 它既解决了定制电路灵活性的不足,又克服了原有可编程器件门电路数有限的缺点。
FPGA可同时进行数据并行和任务并行计算,在处理特定应用时有更加明显的效率提升。对于某个特定运算,通用 CPU可能需要多个时钟周期,而 FPGA 可以通过编程重组电路,直接生成专用电路,仅消耗少量甚至一次时钟周期就可完成运算。
此外,由于 FPGA的灵活性,很多使用通用处理器或 ASIC难以实现的底层硬件控制操作技术, 利用 FPGA 可以很方便的实现。这个特性为算法的功能实现和优化留出了更大空间。同时FPGA 一次性成本(光刻掩模制作成本)远低于ASIC,在芯片需求还未成规模、深度学习算法暂未稳定, 需要不断迭代改进的情况下,利用 FPGA 芯片具备可重构的特性来实现半定制的人工智能芯片是最佳选择之一。
功耗方面,从体系结构而言, FPGA 也具有天生的优势。传统的冯氏结构中,执行单元(如 CPU 核)执行任意指令,都需要有指令存储器、译码器、各种指令的运算器及分支跳转处理逻辑参与运行, 而FPGA每个逻辑单元的功能在重编程(即烧入)时就已经确定,不需要指令,无需共享内存,从而可以极大的降低单位执行的功耗,提高整体的能耗比。
由于 FPGA 具备灵活快速的特点, 因此在众多领域都有替代ASIC 的趋势。 FPGA 在人工智能领域的应用如图所示。
FPGA 在人工智能领域的应用 4、全定制化的ASIC
目前以深度学习为代表的人工智能计算需求,主要采用GPU、FPGA等已有的适合并行计算的通用芯片来实现加速。在产业应用没有大规模兴起之时,使用这类已有的通用芯片可以避免专门研发定制芯片(ASIC)的高投入和高风险。但是,由于这类通用芯片设计初衷并非专门针对深度学习,因而天然存在性能、 功耗等方面的局限性。随着人工智能应用规模的扩大,这类问题日益突显。
GPU作为图像处理器, 设计初衷是为了应对图像处理中的大规模并行计算。因此,在应用于深度学习算法时,有三个方面的局限性:
第一:应用过程中无法充分发挥并行计算优势。 深度学习包含训练和推断两个计算环节, GPU 在深度学习算法训练上非常高效, 但对于单一输入进行推断的场合, 并行度的优势不能完全发挥。 第二:无法灵活配置硬件结构。 GPU 采用 SIMT 计算模式, 硬件结构相对固定。 目前深度学习算法还未完全稳定,若深度学习算法发生大的变化, GPU 无法像 FPGA 一样可以灵活的配制硬件结构。 第三:运行深度学习算法能效低于FPGA。
尽管 FPGA 倍受看好,甚至新一代百度大脑也是基于 FPGA 平台研发,但其毕竟不是专门为了适用深度学习算法而研发,实际应用中也存在诸多局限:
第一:基本单元的计算能力有限。为了实现可重构特性, FPGA 内部有大量极细粒度的基本单元,但是每个单元的计算能力(主要依靠 LUT 查找表)都远远低于 CPU 和 GPU 中的 ALU 模块。 第二:计算资源占比相对较低。 为实现可重构特性, FPGA 内部大量资源被用于可配置的片上路由与连线。 第三:速度和功耗相对专用定制芯片(ASIC)仍然存在不小差距。 第四,:FPGA 价格较为昂贵。在规模放量的情况下单块 FPGA 的成本要远高于专用定制芯片。
因此,随着人工智能算法和应用技术的日益发展,以及人工智能专用芯片 ASIC产业环境的逐渐成熟, 全定制化人工智能 ASIC也逐步体现出自身的优势,从事此类芯片研发与应用的国内外比较有代表性的公司如图所示。
人工智能专用芯片研发情况一览
ASIC 芯片非常适合人工智能的应用场景。 首先,ASIC的性能提升非常明显。例如英伟达首款专门为深度学习从零开始设计的芯片 Tesla P100 数据处理速度是其 2014 年推出GPU 系列的 12 倍。谷歌为机器学习定制的芯片 TPU 将硬件性能提升至相当于当前芯片按摩尔定律发展 7 年后的水平。正如 CPU 改变了当年庞大的计算机一样,人工智能 ASIC 芯片也将大幅改变如今 AI 硬件设备的面貌。如大名鼎鼎的 AlphaGo 使用了约 170 个图形处理器(GPU)和 1200 个中央处理器(CPU),这些设备需要占用一个机房,还要配备大功率的空调,以及多名专家进行系统维护。而如果全部使用专用芯片,极大可能只需要一个普通收纳盒大小的空间,,且功耗也会大幅降低。
第二,下游需求促进人工智能芯片专用化。从服务器,计算机到无人驾驶汽车、无人机再到智能家居的各类家电,至少数十倍于智能手机体量的设备需要引入感知交互能力和人工智能计算能力。而出于对实时性的要求以及训练数据隐私等考虑,这些应用不可能完全依赖云端,必须要有本地的软硬件基础平台支撑,这将带来海量的人工智能芯片需要。
目前人工智能专用芯片的发展方向包括:主要基于 FPGA 的半定制、针对深度学习算法的全定制和类脑计算芯片 3 个方向。
在芯片需求还未形成规模、深度学习算法暂未稳定,AI 芯片本身需要不断迭代改进的情况下,利用具备可重构特性的 FPGA 芯片来实现半定制的人工智能芯片是最佳选择之一。这类芯片中的杰出代表是国内初创公司深鉴科技,该公司设计了“深度学习处理单元”(Deep Processing Unit,DPU)的芯片,希望以 ASIC 级别的功耗达到优于 GPU 的性能,其第一批产品就是基于 FPGA 平台开发研制出来的。这种半定制芯片虽然依托于 FPGA 平台,但是抽象出了指令集与编译器,可以快速开发、快速迭代,与专用的 FPGA 加速器产品相比,也具有非常明显的优势。
深度学习算法稳定后,AI 芯片可采用 ASIC 设计方法进行全定制,使性能、功耗和面积等指标面向深度学习算法做到最优。 5、类脑芯片
类脑芯片不采用经典的冯·诺依曼架构, 而是基于神经形态架构设计,以IBM Truenorth为代表。 IBM 研究人员将存储单元作为突触、计算单元作为神经元、传输单元作为轴突搭建了神经芯片的原型。
目前, Truenorth用三星 28nm功耗工艺技术,由 54亿个晶体管组成的芯片构成的片上网络有4096个神经突触核心,实时作业功耗仅为70mW。由于神经突触要求权重可变且要有记忆功能, IBM采用与CMOS工艺兼容的相变非易失存储器(PCM)的技术实验性的实现了新型突触,加快了商业化进程。
来源:清华2018人工智能芯片研究报告 报告:关注公众号,菜单回复“2018AI芯片报告”获取完整报告 二、Why GPU可以用于加速人工智能或者机器学习的计算速度(并行计算能力) 其实GPU计算比CPU并不是“效果好”,而是“速度快”。 计算就是计算,数学上都是一样的,1+1用什么算都是2,CPU算神经网络也是可以的,算出来的神经网络放到实际应用中效果也很好,只不过速度会很慢罢了。 GPU的起源 GPU全称叫做graphics processing unit,图形处理器,顾名思义就是处理图形的。 电脑显示器上显示的图像,在显示在显示器上之前,要经过一些列处理,这个过程有个专有的名词叫“渲染”。以前的计算机上没有GPU,渲染就是CPU负责的。渲染是个什么操作呢,其实就是做了一系列图形的计算,但这些计算往往非常耗时,占用了CPU的一大部分时间。而CPU还要处理计算机器许多其他任务。因此就专门针对图形处理的这些操作设计了一种处理器,也就是GPU。这样CPU就可以从繁重的图形计算中解脱出来。 由于GPU是专门为了渲染设计的,那么他也就只能做渲染的那些事情。 渲染这个过程具体来说就是几何点位置和颜色的计算,这两者的计算在数学上都是用四维向量和变换矩阵的乘法,因此GPU也就被设计为专门适合做类似运算的专用处理器了。为什么说专用呢,因为很多事情他做不了。 CPU通用性强,但是专用领域性能低。工程就是折衷,这项强了,别的就弱了。再后来游戏、3D设计对渲染的要求越来越高,GPU的性能越做越强。论纯理论计算性能,要比CPU高出几十上百倍。 人们就想了,既然GPU这么强,那用GPU做计算是不是相比CPU速度能大大提升呢?于是就有了GPGPU(general purpose GPU,通用计算GPU)这个概念。但我们前面提到了,GPU是专门为了图像渲染设计的,他只适用于那些操作。但幸运的是有些操作和GPU本职能做的那些东西非常像,那就可以通过GPU提高速度,比如深度学习。 深度学习中一类成功应用的技术叫做卷积神经网络CNN,这种网络数学上就是许多卷积运算和矩阵运算的组合,而卷积运算通过一定的数学手段也可以通过矩阵运算完成。这些操作和GPU本来能做的那些图形点的矩阵运算是一样的。因此深度学习就可以非常恰当地用GPU进行加速了。 以前GPGPU(通用GPU)概念不是很火热,GPU设计出来就是为了图形渲染。想要利用GPU辅助计算,就要完全遵循GPU的硬件架构。而现在GPGPU越来越流行,厂家在设计和生产GPU的时候也会照顾到计算领域的需求了。比如今年英伟达发布M40和P100的时候,都在说”针对深度学习设计“,当然其实这里面炒概念的成分更大了,但至少可以看出厂家越来越多地看重通用GUGPU计算了。 二、GPGPU与GPU的区别 GPU的产生是为了解决图形渲染效率的问题,但随着技术进步,GPU越来越强大,尤其是shader出现之后(这个允许我们在GPU上编程),GPU能做的事越来越多,不再局限于图形领域,也就有人动手将其能力扩展到其他计算密集的领域,这就是GP(General Purpose)GPU。 三、为什么快 比如说你用美图xx软件,给一张图片加上模糊效果的时候,CPU会这么做: 但是有一些聪明的读者会发现,每个窗口在处理图片的过程中,都是独立的,相互没有关系的。那么同时用几个滤镜窗口来处理是不是更快一些? 于是我们有了GPU, 一般的GPU都有几百个核心,意味着,我们可以同时有好几百个滤镜窗口来处理这张图片。 三、人工智能常见算法简介 人工智能的三大基石—算法、数据和计算能力,算法作为其中之一,是非常重要的,那么人工智能都会涉及哪些算法呢?不同算法适用于哪些场景呢? 一、按照模型训练方式不同可以分为监督学习(Supervised Learning),无监督学习(Unsupervised Learning)、半监督学习(Semi-supervised Learning)和强化学习(Reinforcement Learning)四大类。 常见的监督学习算法包含以下几类:(1)人工神经网络(Artificial Neural Network)类:反向传播(Backpropagation)、波尔兹曼机(Boltzmann Machine)、卷积神经网络(Convolutional Neural Network)、Hopfield网络(hopfield Network)、多层感知器(Multilyer Perceptron)、径向基函数网络(Radial Basis Function Network,RBFN)、受限波尔兹曼机(Restricted Boltzmann Machine)、回归神经网络(Recurrent Neural Network,RNN)、自组织映射(Self-organizing Map,SOM)、尖峰神经网络(Spiking Neural Network)等。(2)贝叶斯类(Bayesin):朴素贝叶斯(Naive Bayes)、高斯贝叶斯(Gaussian Naive Bayes)、多项朴素贝叶斯(Multinomial Naive Bayes)、平均-依赖性评估(Averaged One-Dependence Estimators,AODE)贝叶斯信念网络(Bayesian Belief Network,BBN)、贝叶斯网络(Bayesian Network,BN)等。(3)决策树(Decision Tree)类:分类和回归树(Classification and Regression Tree,CART)、迭代Dichotomiser3(Iterative Dichotomiser 3, ID3),C4.5算法(C4.5 Algorithm)、C5.0算法(C5.0 Algorithm)、卡方自动交互检测(Chi-squared Automatic Interaction Detection,CHAID)、决策残端(Decision Stump)、ID3算法(ID3 Algorithm)、随机森林(Random Forest)、SLIQ(Supervised Learning in Quest)等。(4)线性分类器(Linear Classifier)类:Fisher的线性判别(Fisher’s Linear Discriminant)线性回归(Linear Regression)、逻辑回归(Logistic Regression)、多项逻辑回归(Multionmial Logistic Regression)、朴素贝叶斯分类器(Naive Bayes Classifier)、感知(Perception)、支持向量机(Support Vector Machine)等。 常见的无监督学习类算法包括:(1) 人工神经网络(Artificial Neural Network)类:生成对抗网络(Generative Adversarial Networks,GAN),前馈神经网络(Feedforward Neural Network)、逻辑学习机(Logic Learning Machine)、自组织映射(Self-organizing Map)等。(2) 关联规则学习(Association Rule Learning)类:先验算法(Apriori Algorithm)、Eclat算法(Eclat Algorithm)、FP-Growth算法等。(3)分层聚类算法(Hierarchical Clustering):单连锁聚类(Single-linkage Clustering),概念聚类(Conceptual Clustering)等。(4)聚类分析(Cluster analysis):BIRCH算法、DBSCAN算法,期望最大化(Expectation-maximization,EM)、模糊聚类(Fuzzy Clustering)、K-means算法、K均值聚类(K-means Clustering)、K-medians聚类、均值漂移算法(Mean-shift)、OPTICS算法等。(5)异常检测(Anomaly detection)类:K最邻近(K-nearest Neighbor,KNN)算法,局部异常因子算法(Local Outlier Factor,LOF)等。 常见的半监督学习类算法包含:生成模型(Generative Models)、低密度分离(Low-density Separation)、基于图形的方法(Graph-based Methods)、联合训练(Co-training)等。 常见的强化学习类算法包含:Q学习(Q-learning)、状态-行动-奖励-状态-行动(State-Action-Reward-State-Action,SARSA)、DQN(Deep Q Network)、策略梯度算法(Policy Gradients)、基于模型强化学习(Model Based RL)、时序差分学习(Temporal Different Learning)等。 常见的深度学习类算法包含:深度信念网络(Deep Belief Machines)、深度卷积神经网络(Deep Convolutional Neural Networks)、深度递归神经网络(Deep Recurrent Neural Network)、分层时间记忆(Hierarchical Temporal Memory,HTM)、深度波尔兹曼机(Deep Boltzmann Machine,DBM)、栈式自动编码器(Stacked Autoencoder)、生成对抗网络(Generative Adversarial Networks)等。 二、按照解决任务的不同来分类,粗略可以分为二分类算法(Two-class Classification)、多分类算法(Multi-class Classification)、回归算法(Regression)、聚类算法(Clustering)和异常检测(Anomaly Detection)五种。1.二分类(Two-class Classification)(1)二分类支持向量机(Two-class SVM):适用于数据特征较多、线性模型的场景。(2)二分类平均感知器(Two-class Average Perceptron):适用于训练时间短、线性模型的场景。(3)二分类逻辑回归(Two-class Logistic Regression):适用于训练时间短、线性模型的场景。(4)二分类贝叶斯点机(Two-class Bayes Point Machine):适用于训练时间短、线性模型的场景。(5)二分类决策森林(Two-class Decision Forest):适用于训练时间短、精准的场景。(6)二分类提升决策树(Two-class Boosted Decision Tree):适用于训练时间短、精准度高、内存占用量大的场景(7)二分类决策丛林(Two-class Decision Jungle):适用于训练时间短、精确度高、内存占用量小的场景。(8)二分类局部深度支持向量机(Two-class Locally Deep SVM):适用于数据特征较多的场景。(9)二分类神经网络(Two-class Neural Network):适用于精准度高、训练时间较长的场景。 解决多分类问题通常适用三种解决方案:第一种,从数据集和适用方法入手,利用二分类器解决多分类问题;第二种,直接使用具备多分类能力的多分类器;第三种,将二分类器改进成为多分类器今儿解决多分类问题。常用的算法:(1)多分类逻辑回归(Multiclass Logistic Regression):适用训练时间短、线性模型的场景。(2)多分类神经网络(Multiclass Neural Network):适用于精准度高、训练时间较长的场景。(3)多分类决策森林(Multiclass Decision Forest):适用于精准度高,训练时间短的场景。(4)多分类决策丛林(Multiclass Decision Jungle):适用于精准度高,内存占用较小的场景。(5)“一对多”多分类(One-vs-all Multiclass):取决于二分类器效果。 回归回归问题通常被用来预测具体的数值而非分类。除了返回的结果不同,其他方法与分类问题类似。我们将定量输出,或者连续变量预测称为回归;将定性输出,或者离散变量预测称为分类。长巾的算法有:(1)排序回归(Ordinal Regression):适用于对数据进行分类排序的场景。(2)泊松回归(Poission Regression):适用于预测事件次数的场景。(3)快速森林分位数回归(Fast Forest Quantile Regression):适用于预测分布的场景。(4)线性回归(Linear Regression):适用于训练时间短、线性模型的场景。(5)贝叶斯线性回归(Bayesian Linear Regression):适用于线性模型,训练数据量较少的场景。(6)神经网络回归(Neural Network Regression):适用于精准度高、训练时间较长的场景。(7)决策森林回归(Decision Forest Regression):适用于精准度高、训练时间短的场景。(8)提升决策树回归(Boosted Decision Tree Regression):适用于精确度高、训练时间短、内存占用较大的场景。 聚类聚类的目标是发现数据的潜在规律和结构。聚类通常被用做描述和衡量不同数据源间的相似性,并把数据源分类到不同的簇中。(1)层次聚类(Hierarchical Clustering):适用于训练时间短、大数据量的场景。(2)K-means算法:适用于精准度高、训练时间短的场景。(3)模糊聚类FCM算法(Fuzzy C-means,FCM):适用于精确度高、训练时间短的场景。(4)SOM神经网络(Self-organizing Feature Map,SOM):适用于运行时间较长的场景。异常检测异常检测是指对数据中存在的不正常或非典型的分体进行检测和标志,有时也称为偏差检测。异常检测看起来和监督学习问题非常相似,都是分类问题。都是对样本的标签进行预测和判断,但是实际上两者的区别非常大,因为异常检测中的正样本(异常点)非常小。常用的算法有:(1)一分类支持向量机(One-class SVM):适用于数据特征较多的场景。(2)基于PCA的异常检测(PCA-based Anomaly Detection):适用于训练时间短的场景。 常见的迁移学习类算法包含:归纳式迁移学习(Inductive Transfer Learning) 、直推式迁移学习(Transductive Transfer Learning)、无监督式迁移学习(Unsupervised Transfer Learning)、传递式迁移学习(Transitive Transfer Learning)等。 算法的适用场景:需要考虑的因素有:(1)数据量的大小、数据质量和数据本身的特点(2)机器学习要解决的具体业务场景中问题的本质是什么?(3)可以接受的计算时间是什么?(4)算法精度要求有多高? 有了算法,有了被训练的数据(经过预处理过的数据),那么多次训练(考验计算能力的时候到了)后,经过模型评估和算法人员调参后,会获得训练模型。当新的数据输入后,那么我们的训练模型就会给出结果。业务要求的最基础的功能就算实现了。 互联网产品自动化运维是趋势,因为互联网需要快速响应的特性,决定了我们对问题要快速响应、快速修复。人工智能产品也不例外。AI + 自动化运维是如何工作的呢? 根据一些 feature 进行分类,每个节点提一个问题,通过判断,将数据分为两类,再继续提问。这些问题是根据已有数据学习出来的,再投入新数据的时候,就可以根据这棵树上的问题,将数据划分到合适的叶子上。
视频 在源数据中随机选取数据,组成几个子集
S 矩阵是源数据,有 1-N 条数据,A B C 是feature,最后一列C是类别
由 S 随机生成 M 个子矩阵
这 M 个子集得到 M 个决策树 将新数据投入到这 M 个树中,得到 M 个分类结果,计数看预测成哪一类的数目最多,就将此类别作为最后的预测结果
视频 当预测目标是概率这样的,值域需要满足大于等于0,小于等于1的,这个时候单纯的线性模型是做不到的,因为在定义域不在某个范围之内时,值域也超出了规定区间。
所以此时需要这样的形状的模型会比较好
那么怎么得到这样的模型呢? 这个模型需要满足两个条件 大于等于0,小于等于1大于等于0 的模型可以选择 绝对值,平方值,这里用 指数函数,一定大于0小于等于1 用除法,分子是自己,分母是自身加上1,那一定是小于1的了
再做一下变形,就得到了 logistic regression 模型
通过源数据计算可以得到相应的系数了
最后得到 logistic 的图形
视频 support vector machine 要将两类分开,想要得到一个超平面,最优的超平面是到两类的 margin 达到最大,margin就是超平面与离它最近一点的距离,如下图,Z2>Z1,所以绿色的超平面比较好
将这个超平面表示成一个线性方程,在线上方的一类,都大于等于1,另一类小于等于-1
点到面的距离根据图中的公式计算
所以得到 total margin 的表达式如下,目标是最大化这个 margin,就需要最小化分母,于是变成了一个优化问题
举个栗子,三个点,找到最优的超平面,定义了 weight vector=(2,3)-(1,1)
得到 weight vector 为(a,2a),将两个点代入方程,代入(2,3)另其值=1,代入(1,1)另其值=-1,求解出 a 和 截矩 w0 的值,进而得到超平面的表达式。
a 求出来后,代入(a,2a)得到的就是 support vector a 和 w0 代入超平面的方程就是 support vector machine 5. 朴素贝叶斯视频 举个在 NLP 的应用 给一段文字,返回情感分类,这段文字的态度是positive,还是negative
为了解决这个问题,可以只看其中的一些单词
这段文字,将仅由一些单词和它们的计数代表
原始问题是:给你一句话,它属于哪一类 通过 bayes rules 变成一个比较简单容易求得的问题
问题变成,这一类中这句话出现的概率是多少,当然,别忘了公式里的另外两个概率 栗子:单词 love 在 positive 的情况下出现的概率是 0.1,在 negative 的情况下出现的概率是 0.001
视频 k nearest neighbours 给一个新的数据时,离它最近的 k 个点中,哪个类别多,这个数据就属于哪一类 栗子:要区分 猫 和 狗,通过 claws 和 sound 两个feature来判断的话,圆形和三角形是已知分类的了,那么这个 star 代表的是哪一类呢
k=3时,这三条线链接的点就是最近的三个点,那么圆形多一些,所以这个star就是属于猫
视频 想要将一组数据,分为三类,粉色数值大,黄色数值小最开心先初始化,这里面选了最简单的 3,2,1 作为各类的初始值剩下的数据里,每个都与三个初始值计算距离,然后归类到离它最近的初始值所在类别
分好类后,计算每一类的平均值,作为新一轮的中心点
几轮之后,分组不再变化了,就可以停止了
视频 adaboost 是 bosting 的方法之一 bosting就是把若干个分类效果并不好的分类器综合起来考虑,会得到一个效果比较好的分类器。 下图,左右两个决策树,单个看是效果不怎么好的,但是把同样的数据投入进去,把两个结果加起来考虑,就会增加可信度
adaboost 的栗子,手写识别中,在画板上可以抓取到很多 features,例如 始点的方向,始点和终点的距离等等
training 的时候,会得到每个 feature 的 weight,例如 2 和 3 的开头部分很像,这个 feature 对分类起到的作用很小,它的权重也就会较小
而这个 alpha 角 就具有很强的识别性,这个 feature 的权重就会较大,最后的预测结果是综合考虑这些 feature 的结果
视频 Neural Networks 适合一个input可能落入至少两个类别里 NN 由若干层神经元,和它们之间的联系组成第一层是 input 层,最后一层是 output 层 在 hidden 层 和 output 层都有自己的 classifier
input 输入到网络中,被激活,计算的分数被传递到下一层,激活后面的神经层,最后output 层的节点上的分数代表属于各类的分数,下图例子得到分类结果为 class 1 同样的 input 被传输到不同的节点上,之所以会得到不同的结果是因为各自节点有不同的weights 和 bias 这也就是 forward propagation
视频 Markov Chains 由 state 和 transitions 组成 栗子,根据这一句话 ‘the quick brown fox jumps over the lazy dog’,要得到 markov chain 步骤,先给每一个单词设定成一个状态,然后计算状态间转换的概率
这是一句话计算出来的概率,当你用大量文本去做统计的时候,会得到更大的状态转移矩阵,例如 the 后面可以连接的单词,及相应的概率
生活中,键盘输入法的备选结果也是一样的原理,模型会更高级
原文出自:https://www.imooc.com/article/32691
|
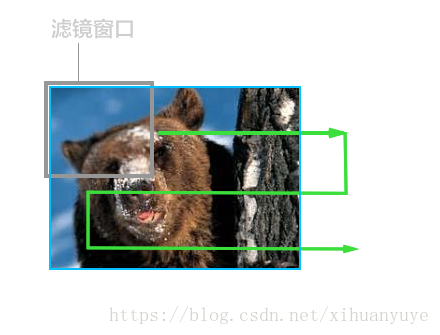 使用一个模糊滤镜算子的小窗口,从图片的左上角开始处理,并从左往右,再从左往右进行游走处理,直到整个图片被处理完成。因为CPU只有一个或者少数几个核,所以执行这种运算的时候,只能老老实实从头遍历到最后。
使用一个模糊滤镜算子的小窗口,从图片的左上角开始处理,并从左往右,再从左往右进行游走处理,直到整个图片被处理完成。因为CPU只有一个或者少数几个核,所以执行这种运算的时候,只能老老实实从头遍历到最后。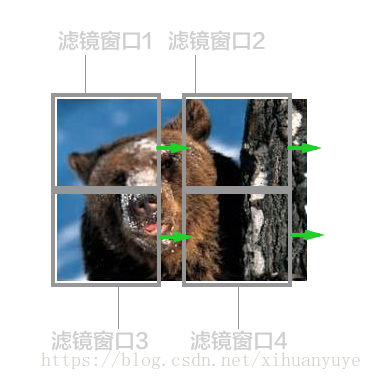 所以说,GPU起初的设计目标就是为了处理这种图形图像的渲染工作,而这种工作的特性就是可以分布式、每个处理单元之间较为独立,没有太多的关联。而一部分机器学习算法,比如遗传算法,神经网络等,也具有这种分布式及局部独立的特性(e.g.比如说一条神经网络中的链路跟另一条链路之间是同时进行计算,而且相互之间没有依赖的),这种情况下可以采用大量小核心同时运算的方式来加快运算速度。
所以说,GPU起初的设计目标就是为了处理这种图形图像的渲染工作,而这种工作的特性就是可以分布式、每个处理单元之间较为独立,没有太多的关联。而一部分机器学习算法,比如遗传算法,神经网络等,也具有这种分布式及局部独立的特性(e.g.比如说一条神经网络中的链路跟另一条链路之间是同时进行计算,而且相互之间没有依赖的),这种情况下可以采用大量小核心同时运算的方式来加快运算速度。






































【本文地址】
今日新闻 |
推荐新闻 |