深度学习 |
您所在的位置:网站首页 › Reward翻译 › 深度学习 |
深度学习
|
目录1. 强化学习2. 马尔科夫链3. Q值和V值
1. 强化学习
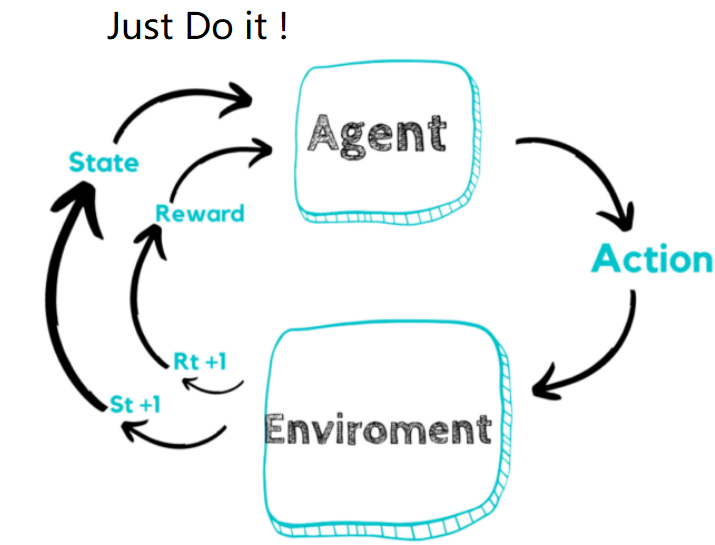
首先我们需要明确,强化学习的任务是什么? 这用大白话说:就是我们希望用强化学习的方式,使智能体获得独立自主地完成某种任务的能力。 智能体学习和工作的地方,我们就称为环境。 注意!所谓独立自主,就是智能体一旦启动,就不需要人指挥了。 state action reward
有兴趣的可以参看:https://openai.com/index/emergent-tool-use/ A(action)动作 动作其实不用解释,就是智能体做出的具体行为。 例如扫地机器人会移动,吸尘,甚至喷水。无人驾驶汽车能够移动,加速,刹车,转弯等。 动作空间就是该智能体能够做出的动作数量。 举个例子:智能体身处十字路口。那么我们的方向就有4个。也就是说,我们能做的动作,就是4个。我们称我们能做的动作的集合,称为动作空间 π R(reward)奖励 当我们在某个状态下,完成动作。环境就会给我们反馈,告诉我们这个动作的效果如何。这种效果的数值表达,就是奖励。 其实这里的reward翻译为“反馈”可能更合适一点。因为反馈并不是完全正面的,也有负面。当奖励可以是正数,表示鼓励当前的行为;如果是负数负数,表示惩罚这种行为。当然也可以是0。 而奖励值的大小,表示鼓励的和惩罚的力度不同。 奖励在强化学习中,起到了很关键的作用,我们会以奖励作为引导,让智能体学习做能获得最多奖励的动作。 例如:我需要训练机器人打乒乓球。机器人每次赢球,都可以加分;输球,就减分。这分数就表现了机器人的动作好坏。如果机器人希望获得更多的分数,就需要想办法赢球。 又例如:无人驾驶汽车如果成功到达目标地点,那么可以获得奖励;但如果闯红灯,那么就会被扣除大量的奖励作为惩罚。如果无人驾驶汽车希望获得更多的分数,那么就必须在遵守交通规则的情况下,成功到达目标地点。 注意,奖励的设定是主观的,也就是说我们为了智能体更好地学习工作,自己定的。所以大家可以看到,很多时候我们会对奖励进行一定的修正,这也是加速智能体学习的方法之一。 state 是环境的状态,输入给智能体agent, 对于智能体来说是它看到的,所以也叫做observation 2. 马尔科夫链
1.智能体在环境中,观察到状态(S); 2.状态(S)被输入到智能体,智能体经过计算,选择动作(A); 3.动作(A)使环境进入另外一个状态(S),并返回奖励(R)给智能体。 4.智能体根据返回,调整自己的策略。 重复以上步骤,一步一步创造马尔科夫链。 所以你看,强化学习跟教孩子是一个道理: 孩子做了好事,必须给奖励;孩子做错事了,必须惩罚。就这么简单! 两个不确定性: 第一个,是“选择”的过程。智能体“选择”会影响到下一个状态。比如state/observation一样,agent对于action的选择也可能不同,这种不同动作之间的选择,我们称为智能体的策略。策略我们一般用Π表示。我们的任务就是找到一个策略,能够获得最多的奖励。 第二个不确定性,是环境的随机性,这是智能体无法控制的,比如action一样但反馈回来新的state/observation或reward也可能有所不同。但马尔科夫链允许我们有不确定性的存在。 所以,这种不确定性来自两个方面:1.智能体的行动选择(策略)。2.环境的不确定性。 3. Q值和V值当智能体从一个状态S,选择动作A,会进入另外一个状态S';同时,也会给智能体奖励R。 奖励既有正,也有负。正代表我们鼓励智能体在这个状态下继续这么做;负得话代表我们并不希望智能体这么做。 在强化学习中,我们会用奖励R作为智能体学习的引导,期望智能体获得尽可能多的奖励。 并不能单纯通过R来衡量一个动作的好坏。我们必须用长远的眼光来看待问题。我们要把未来的奖励也计算到当前状态下,再进行决策。 所以我们在做决策的时候,需要把眼光放远点,把未来的价值换到当前,才能做出选择。 评估动作的价值,我们称为Q值: 它代表了智能体选择这个动作后,一直到最终状态奖励总和的期望; 对action的评估 所以能指引agent采取哪种action 评估状态的价值,我们称为V值: 它代表了智能体在这个状态下,一直到最终状态的奖励总和的期望。 对state的评估, 所以能指引agent尽量让环境进入哪种state,让自身处于哪种state更有利。 假设现在需要求某状态S的V值,那么我们可以这样:
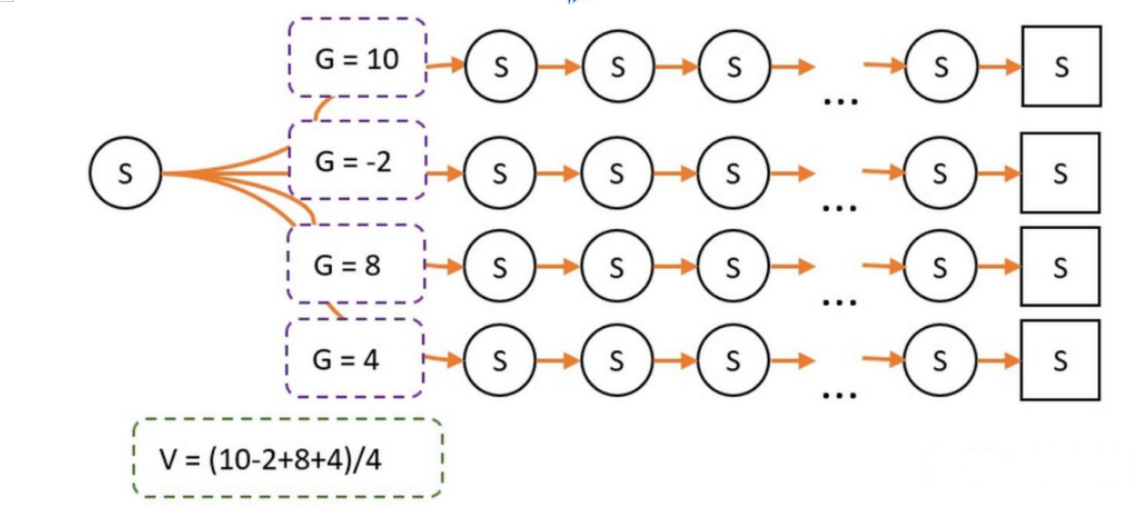
V值是会根据不同的策略有所变化的 假设策略 采用平均策略[A1:50%,A2:50%],根据用影分身(如果是学霸直接求期望),那么我们可以求得V值为15
改变策略[A1:60%,A2:40%],那么我们可以求得V值为14,变少了!
Q值和V值的概念是一致的,都是衡量在马可洛夫树上某一个节点的价值。只不过V值衡量的是状态节点的价值,而Q值衡量的是动作节点的价值。 现在我们需要计算,某个状态S0下的一个动作A的Q值: 1.我们就可以从A这个节点出发,使用影分身之术; 2.每个影分身走到最终状态,并记录所获得的奖励; 3.求取所有影分身获得奖励的平均值,这个平均值就是我们需要求的Q值。 与V值不同,Q值和策略并没有直接相关,而与环境的状态转移概率相关,而环境的状态转移概率是不变的。 总结一下,从以上的定义, 我们可以知道Q值和V值的意义相通的: 1.都是马可洛夫树上的节点; 2.价值评价的方式是一样的: 从当前节点出发 - 一直走到最终节点 - 所有的奖励的期望值Monte Carlo Sampling(1947) 大量的重复试验的方法就叫做Monte Carlo Sampling(1947) 1.我们把智能体放到环境的任意状态; 2.从这个状态开始按照策略进行选择动作,并进入新的状态。 3.重复步骤2,直到最终状态; 4.我们从最终状态开始向前回溯:计算每个状态的G值。 5.重复1-4多次,然后平均每个状态的G值,这就是我们需要求的V值。
1.G的意义:在某个路径上,状态S到最终状态的总收获。 2.V和G的关系:V是G的平均数。 |
 有三个重要的元素:S,A,R。我们分别来看一下,他们代表的是什么。然后大家就会明白,为什么马尔科夫链是一个很好很常用的模型。
有三个重要的元素:S,A,R。我们分别来看一下,他们代表的是什么。然后大家就会明白,为什么马尔科夫链是一个很好很常用的模型。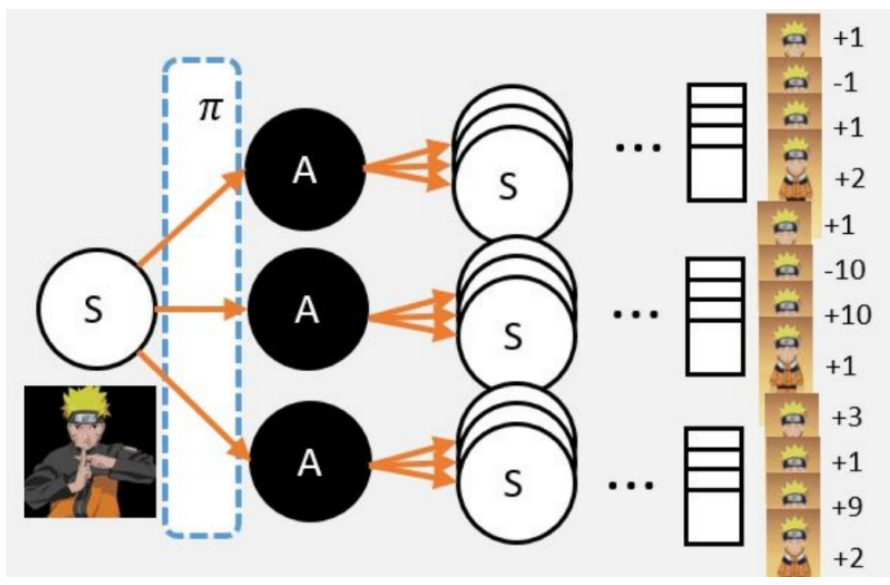 1.我们从S点出发,并影分身出若干个自己;
2.每个分身按照当前的策略 选择行为;
3.每个分身一直走到最终状态,并计算一路上获得的所有奖励总和;
4.我们计算每个影分身获得的平均值,这个平均值就是我们要求的V值。
从某个状态,按照策略,走到最终状态很多很多次;最终获得奖励总和的平均值,就是V值。
1.我们从S点出发,并影分身出若干个自己;
2.每个分身按照当前的策略 选择行为;
3.每个分身一直走到最终状态,并计算一路上获得的所有奖励总和;
4.我们计算每个影分身获得的平均值,这个平均值就是我们要求的V值。
从某个状态,按照策略,走到最终状态很多很多次;最终获得奖励总和的平均值,就是V值。

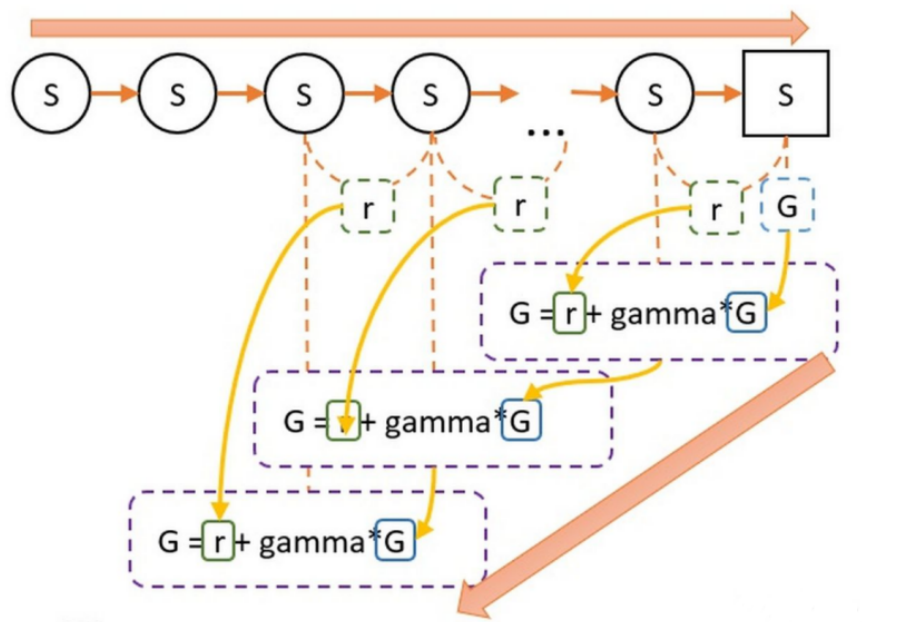 第一步,我们根据策略往前走,一直走到最后,期间我们什么都不用算,还需要记录每一个状态转移,我们获得多少奖励r即可。
第二步,我们从终点往前走,一边走一边计算G值。G值等于上一个状态的G值(记作G'),乘以一定的折扣(gamma),再加上r。
第一步,我们根据策略往前走,一直走到最后,期间我们什么都不用算,还需要记录每一个状态转移,我们获得多少奖励r即可。
第二步,我们从终点往前走,一边走一边计算G值。G值等于上一个状态的G值(记作G'),乘以一定的折扣(gamma),再加上r。
【本文地址】