Python:雷达图的实现 |
您所在的位置:网站首页 › Python雷达图绘制步骤 › Python:雷达图的实现 |
Python:雷达图的实现
|
雷达图
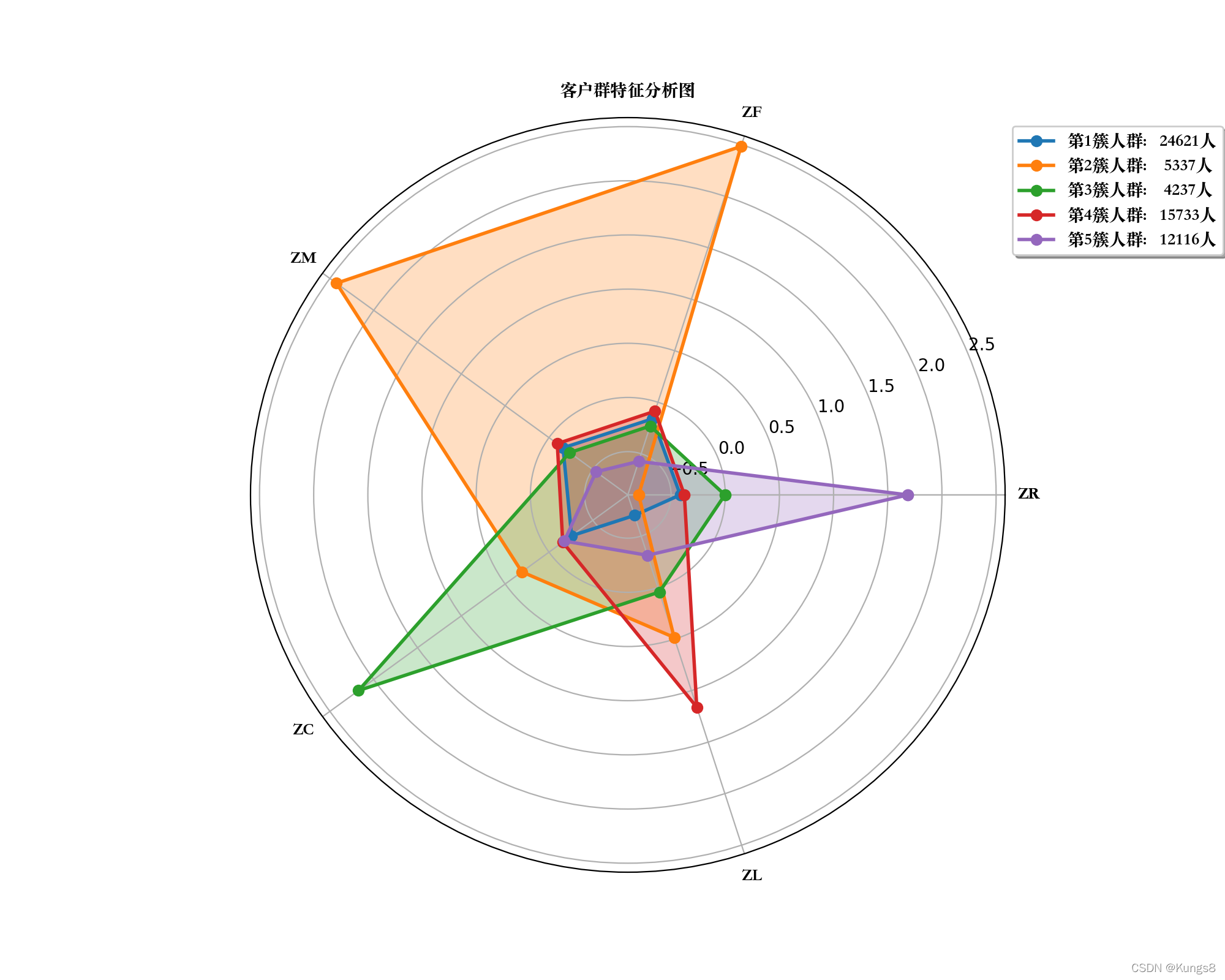
雷达图在数据挖掘项目中多用于企业分析或者价值分析的环节可视化。雷达图分析法是一种系统分析的有效方法,它是从项目中自身建立的多方面分析企业的经营成果。并将这些方面的有关数据用比率表示出来,填写到一张能表示各自比率关系的等比例图形上,再用彩笔连接各自比率的结点后,恰似一张雷达图表。从图上可以看出企业经营状况的全貌,一目了然地找出了企业经营上的优势和弱势。 分析方法就各指标来看,当指标值处于标准线以内时,说明该指标低于平均水平,需要加以改进;若接近最小圆圈或处于其内,说明此指标处于极差状态,是企业需要注意的问题,应重点加以分析改进;若处于标准线外侧,说明该指标处于理想状态,是企业的优势,应采取保持措施。 雷达图的分析方法是:如果企业的比率位于标准线以内,则说明企业比率值低于同行业的平均水平,应认真分析原因,提出改进方向;如果企业的比率值接近或低于小圆,则说明企业经营处于非常危险的境地,急需推出改革措施以扭转局面;如果企业的比率值超过了中圆或标准线,甚至接近大圆,则表明企业经营的优势所在,用予以巩固和发扬。如果把雷达图应用于创新战略的评估,就演变成为戴布拉图。实际上戴布拉图与雷达图的绘制与分析方法完全相同,但是,戴布拉图是用企业内部管理责任:协作过程、业绩度量、教育与开发、分布式学习网络和智能市场定位,以及外部关系:知识产品/服务协作市场准入、市场形象活动、领导才能和通信技术等两个基本方面10个具体因素来替代经营雷达图的5个因素。 制作方法雷达图的绘制方法是:先画3个同心圆,把圆分为5个区域(每个区为72度),分别代表企业的收益性、生产性、流动性、安全性和成长性。同心圆中最小的圆代表同行业平均水平的1/2值或最差的情况;中心圆代表同行业的平均水平或特定比较对象的水平,称为标准线(区);大圆表示同行业平均水平的1.5倍或最佳状态。在5个区域内,以圆心为起点,以放射线的形式画出相应的经营比率线。然后,在相应的比率线上标出本企业决算期的各种经营比率。将本企业的各种比率值用线联结起来后,就形成了一个不规则闭环图。他清楚地表示出本企业的经营态势,并把这种经营态势与标准线相比,就可以清楚地看出本企业的成绩和差距。 python雷达图Demo(完整) import matplotlib.pyplot as plt import numpy as np import pandas as pd from sklearn.cluster import KMeans # 中文字体显示设置 from matplotlib import font_manager my_font = font_manager.FontProperties(fname="/System/Library/Fonts/Supplemental/Songti.ttc") # 导入数据 datafile = "./air_data.csv" data = pd.read_csv(datafile, encoding="utf-8")# 读取原始数据,指定utf-8编码 # 数据清洗 data = data[data['SUM_YR_1'].notnull()&data['SUM_YR_2'].notnull()] #票价非空值才保留 #只保留票价非零的,或者平均折扣率与总飞行公里数同时为0的记录。 index1 = data['SUM_YR_1'] != 0 index2 = data['SUM_YR_2'] != 0 index3 = (data['SEG_KM_SUM'] == 0) & (data['avg_discount'] == 0) #该规则是“与” data = data[index1 | index2 | index3] #该规则是“或” # 属性规约 filter_data = data[["LOAD_TIME","FFP_DATE","LAST_TO_END","FLIGHT_COUNT", "SEG_KM_SUM", "avg_discount"]] # 标准化标准差 L=pd.to_datetime(filter_data['LOAD_TIME'])-pd.to_datetime(filter_data['FFP_DATE']) needzs=filter_data[["LAST_TO_END","FLIGHT_COUNT", "SEG_KM_SUM", "avg_discount"]] needzs['L']=L.astype(np.int64)/(60*60*24*10**9) data = (needzs-needzs.mean(axis=0))/(needzs.std(axis = 0)) #标准化变换 data.columns = ['ZR','ZF','ZM','ZC','ZL'] #表头重命名 # k-means 聚类算法 from sklearn.cluster import KMeans k = 5 kmodel = KMeans(n_clusters = k) #n_jobs是并行数 kmodel.fit(data) #训练模型 kmodel.cluster_centers_ #查看聚类中心 kmodel.labels_ #查看各样本对应的类别 r1 = pd.Series(kmodel.labels_).value_counts() #统计各个类别的数目 r2 = pd.DataFrame(kmodel.cluster_centers_) #找出聚类中心 # 所有簇中心坐标值中最大值和最小值 max = r2.values.max() min = r2.values.min() r = pd.concat([r2, r1], axis = 1) #横向连接(0是纵向),得到聚类中心对应的类别下的数目 r.columns = list(data.columns) + [u'类别数目'] #重命名表头 # r = pd.DataFrame(kmodel.cluster_centers_, columns=data.columns) # 绘图 fig=plt.figure(figsize=(10, 8)) ax = fig.add_subplot(111, polar=True) center_num = r.values feature = ["ZR", "ZF", "ZM", "ZC", "ZL"] N =len(feature) lab = [] # 图例标签名 for i, v in enumerate(center_num): # 设置雷达图的角度,用于平分切开一个圆面 angles=np.linspace(0, 2*np.pi, N, endpoint=False) # 为了使雷达图一圈封闭起来,需要下面的步骤 center = np.concatenate((v[:-1],[v[0]])) angles=np.concatenate((angles,[angles[0]])) # 绘制折线图 ax.plot(angles, center, 'o-', linewidth=2, label = "第%d簇人群,%d人"% (i+1,v[-1])) # 填充颜色 ax.fill(angles, center, alpha=0.25) # 添加每个特征的标签 ax.set_thetagrids(angles * 180/np.pi, feature + [feature[0]], fontsize=15, font_properties=my_font) # 设置雷达图的范围 ax.set_ylim(min-0.1, max+0.1) # 添加标题 plt.title('客户群特征分析图', fontsize=20, font_properties=my_font) # 添加网格线 ax.grid(True) lab.append("第{}簇人群: {:>7}人".format(i+1, int(v[-1]))) # 设置图例 plt.legend(lab, loc='upper right', bbox_to_anchor=(1.3,1.0),ncol=1,fancybox=True,shadow=True, prop=my_font) plt.savefig("./07_航空公司客户群特征分布图.jpg") # 保存图片到本地 plt.show() # 显示图形效果展示 |
【本文地址】
今日新闻 |
推荐新闻 |