Python的字典/字典多层(2层/3层)嵌套操作 |
您所在的位置:网站首页 › Python字典的应用操作 › Python的字典/字典多层(2层/3层)嵌套操作 |
Python的字典/字典多层(2层/3层)嵌套操作
|
字典(Dictionary)用“{}”标识,有索引(key)和它对应的值(value)组成,是除列表(list)以外,Python中最灵活的内置数据结构类型,以k-v数据类型行程键-值对。 其他关于字典操作的,可以参考这里:Python数据系列(二)- 字典Dict:Python的“大胃王”,实在好用 可存储任意类型的对象,如字符串、数字、元组等其他容器模型。 我们在日常的数据处理中,遇到数据字典的情况大多数是数据存在层级结构的时候,包含关系,或者从属关系。在操作中就要分为两种情况: 使用(解析)字典:操作是从外层字典,逐步的进去内层字典创建(保存)字典:先构建内层字典,再外层字典包含内层字典字典的使用,使得数据的处理方便了很多,尤其是针对无序的数组,先保存为字典,在最后对无序的整理为有序的,再统一处理,从整理上把握大局。 与此同时,对于算法与后端之间的交互,一般也都是采用字典的格式进行传递的,以json文件的存储结果最为常见。所以,学好字典,事半功倍。 尤其是在你有一堆各色各异的属性,和对应的值需要存储的时候,字典的作用就非常的明显了,比如下面这种情况:(记录学生信息的字典) students_info = { 'lily':{ 'height':175, 'weight':50, 'father': gao hanyu, 'mother': guo meili, 'english score':102, }, 'shasha':{ 'height':170, 'weight':40, 'father': guo li, 'mother': da meili, 'english score':98, } }这里面就会涉及一个问题,就是再创建和不断的添加信息阶段,需要不断的更新这个字典。下面给出了一个方法,当然肯定还有其他的方式,但遵从的一个原则如下: 先取出字典中原来对应位置的值,或者是整个字典,作为临时变量;对临时变量进行修改,把需要补充,或者删除的部分给操作了;再将改好的临时变量,赋值给原字典,这样就完成了一次字典的更新。这种思路不仅仅适用于字典内元素的更改,对于列表等等内元素的更改,依旧适用。 一、采用2层嵌套字典dict的项目实操一层字典格式是比较常见的,也是字典使用的一个基本形式,形式如下: dict_tmp={'key1':value1, 'key2':value2, 'key3':value3,}那假如,我们的数据层级比较的复杂,班级下面有年级,年级下面还有几十个学生,学生下面还有姓名和性别,那这个时候就可以使用多层嵌套的形式,存储数据了,案例如下: dict_tmp={'key1':{'class1': 1, 'class2':2 }, 'key2':{'class3': 3, 'class4':4 }, 'key3':{'class5': 5, 'class6':6 }, }我第一次想要储存一系列的信息的时候,比如姓名、年龄、身高、体重等等信息。当时还不知道使用字典,愚蠢的使用了字符串,比如:姓名#年龄#身高#体重,的方式,搞了一大串。尽管最后也达到了这个目的,但是很臃肿,不是很好记录。 下面就以一个真实的案例,来实操下。看文件,其中以“_”进行分割的第一个字符是名字,又发现有些文件中又存在名字和日期的组合形式。 这里就是要把某一个人,无论有没有日期,都做统一的处理,究竟该如何处理,这个需要自己在项目中而异了。
这里直接实操代码,内有注释,应该能看懂 from xpinyin import Pinyin from itertools import groupby def rename_docum(): raw_path="F:\\data" p=Pinyin() dict_information_one_patient = {} # 最外层的字典-------------------------重点 for (path, dirs, files) in os.walk(raw_path): for filename in files: name=filename.split("_")[0] print(name) dict_inform_image = {} # 内层字典,与外层字典行成嵌套字典形式-------重点 ss = [''.join(list(g)) for k, g in groupby(name, key=lambda x: x.isdigit())] if ss[0].lower() in list_name: # 由于name中提取的字符是大写,list_name的元素都是小写,所以先转化一致 try: name_index=list_name.index(ss[0].lower()) last_test_time = ss[1] # ss[0]是名称,ss[1]是时间 print(name_index) print(last_test_time) print(list_time[name_index]) # 这里就是先确定ss[0]在list_name中的index,然后在list_time # 中找到与之相对应位置的时间,传给内层字典 # 创建内层字典啦-------------------------重点 dict_inform_image[name] = list_time[name_index] """ 字典形式保存all patient信息, 判断ss[0]是否是dict_information_one_patient的key 如果不在,则将dict_inform_image作为value,ss[0]作为key加入字典内 若是已经存在了,则把存在信息先拿出来,在与新的信息进行合并,最后替换旧的信息-------------------------重点 """ if ss[0] not in dict_information_one_patient: dict_information_one_patient[ss[0]] = dict_inform_image else: x = dict_information_one_patient[ss[0]] # 拿到该病人字典中已经存在的信息 y = dict_inform_image # 新的信息 new_x = dict(x, **y) # 合并dict dict_information_one_patient[ss[0]] = new_x except: print(name) continue print(dict_information_one_patient) np.savetxt("./dict_patient.txt", np.reshape(dict_information_one_patient, -1), delimiter=',', fmt='%5s')上面的处理比较的复杂,但是你不必为怎么得到要保存到字典内的key和value操心,重点关注与如何将字典内的value值保存到字典内,以及如何判断该key是否已经在电脑内了,如何合并俩value,然后嵌套字典,这块都用--------进行了标注。 保存这块字典2层嵌套时候,目的是: 保持字典的key不变对应的value改变,不断的将新加进来的数据,进行更新保存的文件结果,如下面截图这样(太小可点击图像,放大查看)
上面就是保存后的结果,不太好看,经过sublime text整理后,如下清晰所示
最后,总结下记录这个嵌套字典的作用。在某些数据处理中,存在这种局部处理和全局处理的情况。 而最终的数据呈现又需要采用全局的方式从整体上进行分析,此时就可以采用这种嵌套式字典的形式,先暂时的将满足该大key的value进行保存。 其中大value下又存在小key和小value的情况,可以在最后统一对所有满足大key的value进行处理。拥有全局观。也可以采用一下的方式进行字典的嵌套,如下: { oneClassMate['three class'] = { "xiaohong":{ "sex":'female', 'age':'18', 'like':'apple' }, "lily":{ "sex":'female', 'age':'16', 'like':'apple' }, "Tom":{ "sex":'male', 'age':'19', 'like':'noddle' } }, oneClassMate['four class'] = { "Mical":{ "sex":'female', 'age':'18', 'like':'apple' }, "ethon":{ "sex":'female', 'age':'16', 'like':'apple' }, "ajun":{ "sex":'male', 'age':'19', 'like':'noddle' } } }这种也是常用的数据形式,这块把字典叠到一起的操作,就比较的简单了。只是说我的key对应的value不是一个实数,而是一个字典 二、python读取txt格式文件来创建一个存储字典法1:
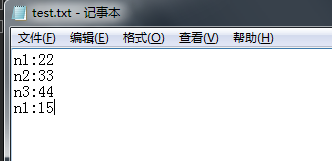
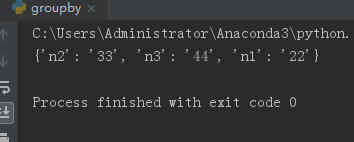
法2: def main(path): dict_data = {} with open(path, 'r') as f: for kv in [d.strip().split(':') for d in f]: dict_data[kv[0]] = kv[1] print(dict_data) if __name__=='__main__': txtpath="D:\\test.txt" main(txtpath)
两张之间是有一定的差别的,第一种方法,会检查是否存在了key,存在就不在存进去了;第二种方法不管,有就存,然后替代 三、关于字典dict的一些其他常用操作 #!/usr/bin/env python # -*- coding:utf-8 -*- id={'123':'ab','456':'cd'} #添加字典元素 id['789']='ef' #删除 del id['123'] #更改 id['456']='ookk' print(id) #遍历字典 for key,value in id.items(): print(key) print(value) print('\n') #遍历字典的键 for key in id.keys(): print(key) #等价于上 for key in id: print(key) print(type(id.keys())) #对key,value进行排序输出 for key in sorted(id.keys()): print(key) for value in sorted(id.values()): print(value) print("\n") #遍历字典的值 for value in id.values(): print(value) print("\n") #去重set集合 for value in set(id.values()): print(value) print("\n") #字典列表 id1={'id':'123','name':'bf'} id2={'id':'234','name':'ef'} ids=[id1,id2] print(ids) print('\n') #字典嵌套,适用于多个结构相同的字典保存 usernames={ 'bfss':{ 'name':'ss', 'tel':'134' }, 'ssff':{ 'name':'dd', 'tel':'187' } } print(usernames)更多的字典相关操作,可以参考这里:Python数据系列(二)- 字典Dictionary:Python的“大胃王” |




【本文地址】
今日新闻 |
推荐新闻 |