python 隐马尔可夫模型的中文分词和词性分类实验 hmm |
您所在的位置:网站首页 › Cookie的词性 › python 隐马尔可夫模型的中文分词和词性分类实验 hmm |
python 隐马尔可夫模型的中文分词和词性分类实验 hmm
|
目录 一、研究背景及意义 1.1 研究背景和研究意义 1.2 研究内容简要介绍 二、中文分词实验 2.1中文分词介绍 2.1.1分词的难点 2.1.2分词的方法 2.2隐马尔可夫模型介绍 2.2.1马尔科夫过程 2.2.2隐马尔科夫模型基本假设 2.2.2 隐马尔可夫模型的描述 2.2.3 隐马尔可夫模型的主要问题 2.3隐马尔可夫模型用于中文分词 2.3.1用于中文分词的HMM模型的描述 2.3.2用于分词的HMM的参数学习 2.3.3用于分词的HMM的预测 2.4实际实验 2.4.1训练语料库 2.4.2参数估计 实际代码 2.4.3预测 实际代码 2.4.4预测效果 实际代码 2.4.4不足 三、词性标注实验 3.1词性标注介绍 3.1.1词性标注列表(PKU标注) 3.1.2词性标注的难点 3.2 隐马尔可夫模型用于词性标注 3.2.1用于词性标注的HMM模型的描述 3.3.2用于词性标注的HMM的参数学习 3.3.3用于词性标注的HMM的预测 3.4实际实验 3.4.1训练语料库 3.4.2参数估计 实际代码 2.4.3预测 实际代码 总结 参考资料 一、研究背景及意义 1.1 研究背景和研究意义 在中文里面,词是最小的能够独立活动的有意义的语言成分,分词和词性标注都是中文自然语言处理的基础工作,能够后续如句法分析带来很大的便利性。 1.2 研究内容简要介绍第一章是中文分词实验,先讲了中文分词是什么、中文分词的常用方法、中文分词的难点,再介绍隐马尔可夫模型并描述隐马尔可夫模型运用到中文分词的原理,接下来是实际操作与遇到的问题 第二章是词性标注实验,先介绍词性标注与词性标注的难点,然后介绍隐马尔可夫模型如何应用到词性标注,最后是实际操作。 第三章总结实验,并做出展望。 二、中文分词实验 2.1中文分词介绍中文文本,从形式上看是由汉字、标点符号等组成的一个字符串。由字组成词,再组成句子、文章等。那么分词,就是按照一定的规则把字符串重新组合成词序列的过程。 在中文里面,词是最小的能够独立活动的有意义的语言成分;英文中单词以空格作为自然分界,虽然也有短语划分的问题。但中文词没有一个形式上的分界,相对而言难度大了许多,分词作为中文自然语言处理的基础工作,质量的好坏对后面的工作影响很大。 2.1.1分词的难点(1)歧义消解问题 输入待切分句子: 提高人民生活水平 可以切分输出 : 提高/人民/生活/水平 或者切分输出: 提/高人/民生/活水/平 可以看到,明显第二个输出为歧义切分。 (2)未登录词识别 未登录词指的是在已有的词典中,或者训练语料里面没有出现过的词,分为实体名词,专有名词及新词。 2.1.2分词的方法(1)基于字典、词库匹配的分词机械分词算法,将待分的字符串与一个充分大的机器词典中的词条进行匹配。实际应用中,将机械分词作为初分手段,再利用其他方法提高准确率。 (2)基于词频统计的分词统计分词,是一种全切分方法。切分出待分语句中所有的词,基于训练语料词表中每个词出现的频率,运用统计模型和决策算法决定最优的切分结果。 (3)基于知识理解的分词主要基于句法、语法分析,并结合语义分析,通过对上下文内容所提供信息的分析对词进行定界。这类方法试图让机器具有人类的理解能力,需要使用大量的语言知识和信息,目前还处在试验阶段。 本文采用的就是第二种分词方法,即利用隐马尔可夫模型来进行中文分词。 2.2隐马尔可夫模型介绍 2.2.1马尔科夫过程一个系统有N各状态,
如果系统在t时刻的状态只与其在时间t-1的状态相关,则该系统构成一个离散的一阶markov链(马尔科夫过程):
如果仅仅考虑独立于时间t的随机过程 在Markov Model中,每一个状态代表一个可观察的事件。然而在Hidden Markov Model中观察到的事件是状态的随机函数,其中状态转移过程是隐蔽的,并且可观察的事件的随机过程是隐蔽的状态转换过程的随机函数。 HMM模型建立在三条重要的假设基础之上。对于一个随机事件,观察序列为
(1)齐次马尔科夫性,即一阶Markov过程 (2)不动性假设:即状态与具体的时间无关 (3)观测独立性假设:输出仅与当前状态相关, HMM可以通过以下描述:
评估问题:即给定观测序列 O=O1,O2,O3…Ot和模型参数λ=(A,B,pi),怎样有效计算这一观测序列出现的概率,使用Forward-backward算法 解码问题:对于给定模型和观察值序列,求可能性最大的状态序列,使用viterbi算法。 学习问题:对于给定的一个观察值序列O,调整参数,使得观察值出现的概率最大,使用极大似然估计的方法估计参数、Baum-Welch或EM算法。 2.3隐马尔可夫模型用于中文分词 2.3.1用于中文分词的HMM模型的描述(1)观测序列:把每一个待分的句子,都视为一个观测序列,如:我喜欢星期天喝牛奶,就是一个长度8的观测序列 (2)状态序列:每一个观测序列,都对应着相同长度的状态序列。这里将汉字按SBME进行标注,分别代表single(单独成词的字)、begin(一个词语开始字)、middle(一个词语中间的字)、end(一个词语结束的字), 如:观测序列:我喜欢星期天喝牛奶 状态序列:SBEBMESBE (3)初始概率分布:SBME各自作为句首状态的概率。 我们可以查看jieba的hmm分词方法中的初始概率分布,对应 jiaba/finalseg/prob_start.py文件,如下
(4)状态转移矩阵:SBME之间两两转移的概率,我们可以对应查看jieba/finalseg/prob_trans.py文件,如下:
(5)观测发射矩阵:其元素含义为,当状态为SBME时。观察到各个汉字的概率,对应jieba/finalseg/prob_emit.py文件,如下:
比如P[‘B’][‘\u4e00’]代表的含义就是’B’状态下观测的字为’\u4e00’(对应的汉字为’一’)的概率对数P[‘B’][‘\u4e00’] = -3.6544978750449433。 2.3.2用于分词的HMM的参数学习1)有监督学习:监督学习的隐状态是已知的,训练样本是已经分好词的文本。通过使用训练数据,我们可以处理得到观测序列和对应的隐状态。然后计算相应的频数值,以简单的计数来近似其初始概率分布、状态转移矩阵和观测发射矩阵。 2)无监督学习:无监督学习的隐状态是未知的,训练样本是原始文本。我们需要使用EM算法,迭代更新求使得MSE最大的初始概率分布、状态转移矩阵和观测发射矩阵。 2.3.3用于分词的HMM的预测输入未分词的句子,使用维特比算法,即可得到由SBME组成的隐状态序列。 2.4实际实验有监督的HMM分词准确率要比无监督的高,所以这里就只实现有监督的HMM分词。 2.4.1训练语料库语料库来自国际中文自动分词评测(SIGHAN)2015年的公开数据[1],选取其中PKU整理的人民日报语料文件pku_training,打开后其数据格式如下:
上图中每一条都是已经分好词的句子,根据字的位置和所在词语的位置可以判断出每一个字的SBME状态。 2.4.2参数估计1)初始概率分布:统计所有训练样本中分别以状态S、B、M、E为初始状态的样本的数量,之后分别除以训练词语总数,就可以得到初始概率分布。 实验训练得到的初始概率分布如下,其中,middle和end作为字符序列初始状态的概率为零,符合常识,另外两项begin的概率大于single的概率,同jieba的prob_start相似。
2)状态转移概率分布:统计所有样本中,从状态S转移到B的出现次数,再除以S出现的总次数,便得到由S转移到B的转移概率,其他同理。 实验训练得到的转移概率如下,其中,B-B,B-S,M-B,M-S,E-M,E-E,S-M,S-E都为0,符合常理,其他转移概率之间的比率也与jieba库的相似。
3)观测发射概率矩阵:统计训练数据中,状态为j并观测为k的频数,除以训练数据中状态j出现的次数,其他同理。 截取部分结果如下图,下面的字作为single出现的概率挺小,我推测”凋”、”痴”、” 瞟”等都只出现了一次。
把观测序列即一句未分词的话、初始分布、转移概率矩阵和观测发射矩阵带入维特比算法的函数,即得使得观测序列发生概率最大的隐状态序列,然后按隐状态序列即可对观测序列进行分词,一则试验如下:
1.原计划:将训练数据,将pku_test每一行的未分词句子、初始分布、转移概率矩阵和观测发射矩阵维特比算法,得到隐状态序列,再取出pku_test_gold中分好词的句子的隐状态序列,计算实际隐状态序列和预测隐状态序列的匹配程度。 2. 遇到问题:对所有预测数据进行批量预测时,许多句子一行太长或者专有名词太多导致所有可能状态都为0,所以就预测不出其隐状态序列,为了观测序列太长导致的无法预测,我写了许多if和for来把判断句子长度,并把序列用“,”和“。”把句子划开,写的程序中for和if太多,程序过繁杂,导致由pku_test经维特比算法得到的预测隐状态序列与从pku_test_gold中得到的实际隐状态序列最终长度相差200,并且经过尝试,无法消除。 3. 替代方法:为了解决长度不一致的问题,我放弃使用pku_test_gold数据集,转而使我的HMM模型与jieba的分词比较,对每一个观测序列,在用HMM模型维特比算法预测一遍后,紧接着用jieba分一遍词,并取出SBME,这个妥协折中的方法成功了。 4. 预测效果 下表是jieba分词与自制HMM分词的混淆矩阵,四列表示四个结巴分词分出的BEMS,四行表示四个自制HMM分词分出的BEMS,如第二行第三列表示,有757个字在jieba分词中被分为E而在自制HMM模型中被分为M。从混淆矩阵中抓取重点信息:大多数在jieba分词中被分为B的在自制HMM模型中也被分为了B,大多数在jieba分词中被分为E的在自制HMM模型中也被分为了E,大多数在jieba分词中被分为S的在自制HMM模型中也被分为了S,然而大部分在jieba分词中被分为M的字,却更多地在HMM模型中被分为B和M,直观感觉是自制HMM分词的分词效果还是比较正常。
下表以jieba分词结果为正确结果,来计算自制HMM分词的精确率、召回率、精确率和召回率的调和平均值,可以看出除了M的召回率比较低为0.14外,其他的比率值都不差,自制HMM的分词效果较良。
2.4.4不足 1. 对长句字的分词能力不够,只能先将长句字按句号、分号和逗号分隔,然后再对短句子分词。 2. 除此之外,在测试集中还有一些句子,即使按1.中的方法分割为小句子,也会因为所有隐状态序列组合都为0而无法分词,在测试集分词时,只好跳过这些句子,下面罗列这些句子:
上列无法分词的句子可以分为四种情况,第一种,罗列专业词汇:句子1)罗列法律词语、句子5)罗列体育名词;第二种,罗列人名地名店铺名,如句子3)和句子4);第三种:罗列带有特殊符号的词语,如句子6)罗列带有书名号的节目;第四种:专有名词太长又没有收录到发射矩阵中,如句子2)。 上述四种情况即对应着自制HMM模型的不足和待改进之处。第一,应该增加对专业词汇的收录;第二,想办法识别姓名和地点名,可以从结构入手,如姓名总是2-3个字并且有常见的姓氏,地点名则可能带有‘**镇’、‘**村’的提示;第三、增强对类如书名号的符号识别;第四、增加长词汇的收录,并且优先考虑分为长词汇。 三、词性标注实验 3.1词性标注介绍词性(part-of-speech)是词汇基本的语法属性。词性标注(part-of-speech tagging),又称为词类标注或者简称标注,是指为分词结果中的每个单词标注一个正确的词性的程序,也即确定每个词是名词、动词、形容词或者其他词性的过程。词性标注是很多NLP任务的预处理步骤,如句法分析,经过词性标注后的文本会带来很大的便利性,但也不是不可或缺的步骤。 3.1.1词性标注列表(PKU标注)
(1)观测序列:把每一个分好词的句子,都视为一个观测序列,如:我/喜欢/星期天/喝/牛奶,就是一个长度5的观测序列 (2)状态序列:每一个观测序列,都对应着相同长度的状态序列。状态序列由对应序列每一个词语的词性组成。 如:观测序列:我/喜欢/星期天/喝/牛奶 状态序列:r[代词] v[动词] t[时间词] v[动词] n[名词] (3)初始概率分布:各个词性各自作为句首状态的概率。 我们可以查看jieba的hmm词性标注方法中的初始概率分布,对应 jiaba/posseg/prob_start.py文件,如下,可以看出jieba中的词性标注方法将分词和词性标注同时考虑,隐状态为SBME和不同词性的组合。
(4)状态转移矩阵:不同状态之间两两转移的概率,我们可以对应查看jieba/ posseg /prob_trans.py文件,如下:
(5)观测发射矩阵:其元素含义为,当状态不同时时。观察到各个汉字的概率,对应jieba/finalseg/prob_emit.py文件,如下:
与中文分词一样,我们选择正确率更高的有监督学习,有监督学习的隐状态是已知的,训练样本是已经标注好词语的文本。通过使用训练数据,我们可以处理得到观测序列和对应的隐状态。然后计算相应的频数值,以简单的计数来近似其初始概率分布、状态转移矩阵和观测发射矩阵。 3.3.3用于词性标注的HMM的预测输入已分词未标注词性的句子,使用维特比算法,即可得到由词性组成的隐状态序列。 3.4实际实验在上一个分词实验中,我们生成的针对训练集中所有字符的发射矩阵,参数估计后,我们可以将参数和新观测序列输入维特比算法即可得到隐状态序列,这种方法参数学习时间较长,参数可以重复用于预测。 当我们的训练语料库特别大,预测次数不多时,为了减少参数学习时间,我们可以先输入预测序列,然后只记录和预测序列元素的发射矩阵,下面的 3.4.1训练语料库训练语料库由PKU整理,编自人民日报,文件为19980101.txt,在每一个词语的后面标注了词性,打开后其数据格式如下:
1)初始概率分布:统计所有训练样本中分别以44个不同词性为序列初始状态的样本的数量,之后分别除以训练词语总数,就可以得到初始概率分布。 实验训练得到词性状态有以下44种:
这44种词性的初始概率如下(都不为零,只是为了展示四舍五入),
初始概率分别按顺序对应词性,其中第11个词性n,即名词有0.21的概率作为序列的初始状态,和常识是相符的。 2)状态转移概率分布:统计所有样本中,从状态S转移到B的出现次数,再除以S出现的总次数,便得到由S转移到B的转移概率,其他同理。 实验训练得到的转移概率如下,44*44的矩阵不便展示,就只截取了一部分。
由一行,人名转移至人名的频率为0.4549,人名转移至动词的频率为0.1114,这似乎有违常识,一般的新闻稿罗列人名的频率没有那么高,追寻原因,打开训练语料库寻找人名”nr”标注的词语,如下
原来是因为分词时将名和姓分隔开,都贴了人名标签,所以就有一半的人名后面跟的还是人名了。 3)观测发射概率矩阵: 上文中提到,观测发射概率矩阵是根据输入的测试序列而定的,现在举例输入句子:[边疆的 人们 在 春天 种 玉米] ,则得到了发射矩阵如下:
解释上矩阵:状态为n名词而出现观测’人们’的频率为0.002;状态为t时间词而出现观测’春天’的频率为0.001;无论词性为什么,出现观测’边疆的’和’玉米’的频率都十分小;状态为q量词而出现观测’种’的频率为0.022,状态为q量词而出现观测’种’的频率为0.022,其他同理。 在上面的发射状态矩阵中,大部分元素的值都为0,但并不是真实值为0,而是为了展示在论文上保留了三位小数,四舍五入后为0。事实上,为了追求词性标注效果,我会人为地用一个很小的数来代替转移概率矩阵和观测发射矩阵中为0的元素,因为一旦某一个元素为0,那么整条路径的发生概率就会为0,举一个例子,当测试集出现了语料库中未收录的词时,其所有路径的概率都会因其观测发射概率等于0而为0,这时,我们就选不出最大的概率,但是如果我们用一个很小的数来代替其观测发射矩阵中的0,我们就可以用根据这个句子中的其他词,还有转移概率矩阵的规则来选那个发生概率最大的路径了,这在自然语言处理中称为平滑处理,我在程序中使用了拉普拉斯平滑。除了能识别未登录词的,平滑处理还一定地解决了汉语的一词多词性、词性活用的问题,因为训练语料库中可能就没有收录不常用词性,但测试集中可能会出现。 实际代码 ----------------------------词性标注代码------------------------------- import numpy as np def cal_hmm_matrix(observation): word_pos_file = open('C:/Users/91333/Documents/semester6/VS code/VScode Python/hmm中文分词/语料库收集/ChineseDic.txt','r', encoding='utf-8').readlines() # 得到所有标签 tags_num = {} for line in word_pos_file: word_tags = line.strip().split(',')[1:] for tag in word_tags: if tag not in tags_num.keys(): tags_num[tag] = 0 tags_list = list(tags_num.keys()) # 转移矩阵、发射矩阵 transaction_matrix = np.zeros((len(tags_list), len(tags_list)), dtype=float) emission_matrix = np.zeros((len(tags_list), len(observation)), dtype=float) word_file = open('C:/Users/91333/Documents/semester6/VS code/VScode Python/hmm中文分词/语料库收集/pku_training_type.txt','r', encoding='utf-8').readlines() # 计算转移矩阵和发射矩阵 for line in word_file: if line.strip() != '': word_pos_list = line.strip().split(' ') for i in range(1, len(word_pos_list)): tag = word_pos_list[i].split('/')[1] pre_tag = word_pos_list[i - 1].split('/')[1] try: transaction_matrix[tags_list.index(pre_tag)][tags_list.index(tag)] += 1 tags_num[tag] += 1 except ValueError: if ']' in tag: tag = tag.split(']')[0] else: pre_tag = tag.split(']')[0] transaction_matrix[tags_list.index(pre_tag)][tags_list.index(tag)] += 1 tags_num[tag] += 1 for o in observation: if ' ' + o in line: pos_tag = line.strip().split(o)[1].split(' ')[0].strip('/') if ']' in pos_tag: pos_tag = pos_tag.split(']')[0] emission_matrix[tags_list.index(pos_tag)][observation.index(o)] += 1 for row in range(transaction_matrix.shape[0]): n = np.sum(transaction_matrix[row]) # 平滑处理 transaction_matrix[row] += 1e-16 transaction_matrix[row] /= n + 1 for row in range(emission_matrix.shape[0]): emission_matrix[row] += 1e-16 emission_matrix[row] /= tags_num[tags_list[row]] + 1 times_sum = sum(tags_num.values()) for item in tags_num.keys(): tags_num[item] = tags_num[item] / times_sum return tags_list, list(tags_num.values()), transaction_matrix, emission_matrix2.4.3预测 把观测序列即一句已分词未标注的句子、初始分布、转移概率矩阵和观测发射矩阵带入维特比算法的函数,即得使得观测序列发生概率最大的隐状态序列,一则试验如下:
预测结果是正确的,再试验一次,
预测效果的衡量同理自制HMM分词程序,由于自制HMM词性标注程序每预测一个句子都要扫描一遍训练集得出与输入句子序列相对应的发射矩阵,如果在测试集上衡量效果,程序计算量太大,故省去。 实际代码 def viterbi(obs_len, states_len, init_p, trans_p, emit_p): """ :param obs_len: 观测序列长度 int :param states_len: 隐含序列长度 int :param init_p:初始概率 list :param trans_p:转移概率矩阵 np.ndarray :param emit_p:发射概率矩阵 np.ndarray :return:最佳路径 np.ndarray """ # max_p每一列为当前观测序列不同隐状态的最大概率 max_p = np.zeros((states_len, obs_len)) # path每一行存储上max_p对应列的路径 path = np.zeros((states_len, obs_len)) # 初始化max_p第1个观测节点不同隐状态的最大概率并初始化path从各个隐状态出发 for i in range(states_len): max_p[i][0] = init_p[i] * emit_p[i][0] path[i][0] = i # 遍历第1项后的每一个观测序列,计算其不同隐状态的最大概率 for obs_index in range(1, obs_len): new_path = np.zeros((states_len, obs_len)) # 遍历其每一个隐状态 for hid_index in range(states_len): # 根据公式计算累计概率,得到该隐状态的最大概率 max_prob = -1 pre_state_index = 0 for i in range(states_len): each_prob = max_p[i][obs_index - 1] * trans_p[i][hid_index] * emit_p[hid_index][obs_index] if each_prob > max_prob: max_prob = each_prob pre_state_index = i # 记录最大概率及路径 max_p[hid_index][obs_index] = max_prob for m in range(obs_index): # "继承"取到最大概率的隐状态之前的路径(从之前的path中取出某条路径) new_path[hid_index][m] = path[pre_state_index][m] new_path[hid_index][obs_index] = hid_index # 更新路径 path = new_path # 返回最大概率的路径 max_prob = -1 last_state_index = 0 for hid_index in range(states_len): if max_p[hid_index][obs_len - 1] > max_prob: max_prob = max_p[hid_index][obs_len - 1] last_state_index = hid_index return path[last_state_index] def state_to_show(obs,hid,result): tag_line = '' for k in range(len(result)): tag_line += obs[k] + hid[int(result[k])] + ' ' return tag_line obs = ['边疆的/', '人们/', '在/', '春天/','种/',"玉米/"] hid, init_p, trans_p, emit_p = cal_hmm_matrix(obs) result = viterbi(len(obs), len(hid), init_p, trans_p, emit_p) state_to_show(obs,hid,result) obs1 = ['我/', '和/', '妹妹/', '昨天/','唱/',"歌曲/"] hid1, init_p1, trans_p1, emit_p1 = cal_hmm_matrix(obs1) result1 = viterbi(len(obs1), len(hid1), init_p1, trans_p1, emit_p1) state_to_show(obs1,hid1,result1) 总结本次实验的不足有很多,所以还有较多的改进空间,下面分条展示本文的不足。 语料库旧且不全面。两则实验的语料库都来自1998年,和现在的用语习惯已有区别;语料库只收录了人民日报1个月的文章评论,训练集样本不够多;人民日报是官方书面语言,训练出的模型不很适用与民间口语的分词与词性分类。往后的分词训练应该寻找更新更全面的语料库,或者根据不同情境寻找相应的语料库。如4.4中指出的,不管中文分词还是词性分类,单纯的HMM模型都不够灵巧,往后应该加一些技巧,如对增强对书名号的敏感,使得模型能够甄别多种情况。对于长的专有名词的处理还是一个有待解决的问题,比如,[大连/ns 市委/n 宣传部/n]nt,可以分为3个词也可以是一个整体,何时应该分为3个词,何时该做为一个整体?在本实验中,都暂且将长专有名词分开。 参考资料 宗成庆.《统计自然语言处理》.清华大学出版社.201352nlp.HMM系列文章. http://www.52nlp.cn/hmm%E7%9B%B8%E5%85%B3%E6%96%87%E7%AB%A0%E7%B4%A2%E5%BC%95. 2015Nonlinear Time Series Theory, Methods, and Applications with R Examples. Randal Douc, Eric Moulines, David Stoffer .CRC Press. 2013不愿透露姓名的广外男子 .基于特定语料库生成HMM转移概率分布和发射概率分布用于词性标注 Python https://blog.csdn.net/Chase1998/article/details/84192005. 2018[1] http://sighan.cs.uchicago.edu/bakeoff2005/
|

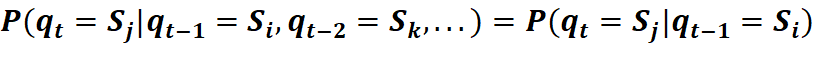























【本文地址】
今日新闻 |
推荐新闻 |