性能爆表 |
您所在的位置:网站首页 › CNKI查询卡 › 性能爆表 |
性能爆表
|
文章目录
1 基本概念2 数据结构3 设计原则4 python针对influxdb的操作6 附-性能测试报告6.1 被测环境6.2 写入测试6.3 查询测试
首先声明我是InfluxDB的粉丝
1 基本概念
InfluxDB 是用Go语言编写的一个开源分布式时序、事件和指标数据库,无需外部依赖。专业处理时序数据的数据库,传统上的软件架构不论是什么类型的数据都用Mysql存储,一个Mysql走遍天下的感觉,伴随数据量的增大,数据种类的多样性,涌现出大量的专业型数据库: 处理关系数据的数据库:Mysql,pgsql,sql server缓存数据库:memchach键值对数据库:redis文档数据库:mongoDB时序数据库:influxdbinfluxdb 有两个版本,社区版和企业版,社区版不能部署集群。 2 数据结构InfluxDB是一个时间序列数据库,因此一切的根源就是——时间 示例数据: name: census -———————————— time butterflies honeybees location scientist 2020-08-18T00:00:00Z 12 23 1 langstroth 2020-08-18T00:00:00Z 1 30 1 perpetua 2020-08-18T00:06:00Z 11 28 1 langstroth 2020-08-18T00:06:00Z 3 28 1 perpetua 2020-08-18T05:54:00Z 2 11 2 langstroth 2020-08-18T06:00:00Z 1 10 2 langstroth 2020-08-18T06:06:00Z 8 23 2 perpetua 2020-08-18T06:12:00Z 7 22 2 perpetua其中census是measurement 等同于关系数据库中的表名 butterflies和honeybees是field key,location和scientist是tag key。 time列在InfluxDB中所有的数据都有这一列。time存时间戳,这个时间戳以RFC3339格式展示了与特定数据相关联的UTC日期和时间。 butterflies列 & honeybees列接下来两个列叫作butterflies和honeybees,称为fields。fields由field key和field value组成。field key(butterflies和honeybees)都是字符串,他们存储元数据;field key butterflies告诉我们蝴蝶的计数从12到7;field key honeybees告诉我们蜜蜂的计数从23变到22。 field value就是你的数据,它们可以是字符串、浮点数、整数、布尔值,因为InfluxDB是时间序列数据库,所以field value总是和时间戳相关联。 在示例中,field value如下: 12 23 1 30 11 28 3 28 2 11 1 10 8 23 7 22在上面的数据中,每组field key和field value的集合组成了field set,在示例数据中,有八个field set: butterflies = 12 honeybees = 23 butterflies = 1 honeybees = 30 butterflies = 11 honeybees = 28 butterflies = 3 honeybees = 28 butterflies = 2 honeybees = 11 butterflies = 1 honeybees = 10 butterflies = 8 honeybees = 23 butterflies = 7 honeybees = 22field是InfluxDB数据结构所必需的一部分——在InfluxDB中不能没有field。还要注意,field是没有索引的。如果使用field value作为过滤条件来查询,则必须扫描其他条件匹配后的所有值。因此,这些查询相对于tag上的查询(下文会介绍tag的查询)性能会低很多。 一般来说,字段不应包含常用来查询的元数据。 location和scientist列样本数据中的最后两列(location和scientist)就是tag。 tag由tag key和tag value组成。tag key和tag value都作为字符串存储,并记录在元数据中。示例数据中的tag key是location和scientist。 location有两个tag value:1和2。scientist还有两个tag value:langstroth和perpetua。 在上面的数据中,tag set是不同的每组tag key和tag value的集合,示例数据里有四个tag set(笛卡尔积): location = 1, scientist = langstroth location = 2, scientist = langstroth location = 1, scientist = perpetua location = 2, scientist = perpetuatag不是必需的字段,但是在你的数据中使用tag总是大有裨益,因为不同于field, tag是索引起来的。这意味着对tag的查询更快,tag是存储常用元数据的最佳选择。 measurementmeasurement作为tag,fields和time列的容器,measurement的名字是存储在相关fields数据的描述。 measurement的名字是字符串,对于一些SQL用户,measurement在概念上类似于表。样本数据中唯一的测量是census。 名称census告诉我们,fields值记录了butterflies和honeybees的数量,而不是不是它们的大小,方向或某种幸福指数。 单个measurement可以有不同的retention policy。 retention policy描述了InfluxDB保存数据的时间(DURATION)以及这些存储在集群中数据的副本数量(REPLICATION)。 在样本数据中,measurement census中的所有内容都属于autogen的retention policy。 InfluxDB自动创建该存储策略; 它具有无限的持续时间和复制因子设置为1。 series在InfluxDB中,series是共同retention policy,measurement和tag set的集合。 以上数据由四个series组成: 示例数据有以下四个series 任意series编号 retention policy measurement tag set series 1 autogen census location = 1,scientist = langstroth series 2 autogen census location = 2,scientist = langstroth series 3 autogen census location = 1,scientist = perpetua series 4 autogen census location = 2,scientist = perpetua理解series对于设计数据schema以及对于处理InfluxDB里面的数据都是很有必要的。 ponitpoint就是具有相同timestamp的相同series的field集合。例如,这就是一个point: name: census ----------------- time butterflies honeybees location scientist 2015-08-18T00:00:00Z 1 30 1 perpetua例子里的series的retention policy为autogen,measurement为census,tag set为location = 1, scientist = perpetua。point的timestamp为2015-08-18T00:00:00Z。 3 设计原则如果你说你的大部分的查询集中在字段honeybees和butterflies上: SELECT * FROM "census" WHERE "butterflies" = 1 SELECT * FROM "census" WHERE "honeybees" = 23因为field是没有索引的,在第一个查询里面InfluxDB会扫描所有的butterflies的值,第二个查询会扫描所有honeybees的值。这样会使请求时间很长,特别在规模很大时。为了优化你的查询,你应该重新设计你的数据结果,把field(butterflies和honeybees)改为tag,而将tag(location和scientist)改为field。 4 python针对influxdb的操作 from influxdb import influxDBClient conn_db=InfluxDBClient('localhost','8086','username','password','db_name') 1、显示已存在的所有数据库 使用get_list_database函数, print conn_db.get_list_database() #显示所有数据库名称 2、创建新数据库 使用create_database函数,示例如下: conn_db.create_database('testdb') #创建数据库 3、删除数据库 使用drop_database函数,示例如下: conn_db.drop_database('testdb') #删除数据库 表操作 influxDBClient中要指定连接的数据库 1、显示指定数据库中已存在的表,可以通过influxql语句实现,示例如下: result = conn_db.query("show measurements") #显示数据库中的表 print("Result: {0}".format(result)) 2、创建新表并添加数据 influxDB没有提供单独的建表语句,可以通过并添加数据的方式建表,示例如下: json_body = [ { "measurement": "students", "tags": { "stuid": "s123" }, #"time": "2017-03-12T22:00:00Z", "fields": { "score": 89 } } ] conn_db.write_points(json_body) #写入数据,同时创建表 3、删除表 可以通过influxql语句实现,示例如下: conn_db.query('drop measurement students') #删除表 4、查询: 可以通过influxql语句实现,示例如下: result = conn_db.query('select * from students;') print("Result: {0}".format(result)) 5、更新 tags和timestamp相同时数据会覆盖操作,相当于influxDB的更新操作 6、删除 使用influxql语句实现,delete语法,示例如下" client.query('delete from students;') #删除数据 # 5 小结 上述涵盖的所有内容都存储在数据库(database)中——示例数据位于数据库test_database中。 InfluxDB数据库与传统的关系数据库类似,并作为users,retention policy,continuous以及point的逻辑上的容器. 数据库可以有多个users,retention policy,continuous和measurement。 InfluxDB是一个无模式数据库,意味着可以随时添加新的measurement,tag和field。 它旨在使时间序列数据的工作变得非常棒。 6 附-性能测试报告 6.1 被测环境 硬件 CPU 内存 带宽 版本号 4核 16G 1Gbit/s Ubuntu 4.8.4-2ubuntu1~14.04.3 软件Docker下安装的influxDB 端口8086 从github上找的influxdata公司提供的两款测试工具 influx-stress 用于写入测试 influxdb-comparisons用于查询测试 6.2 写入测试
|

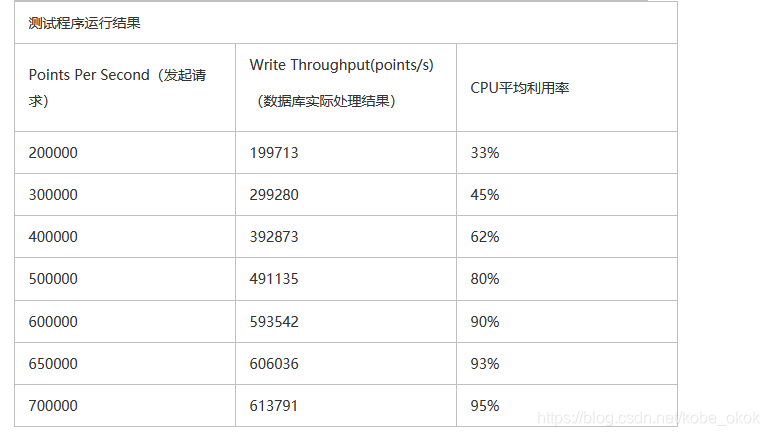 测试结论:最大的吞吐量为每秒写入60万条数据。这之后,每秒发送的points再多,吞吐量也不会增加,同时CPU利用率已达90%。
测试结论:最大的吞吐量为每秒写入60万条数据。这之后,每秒发送的points再多,吞吐量也不会增加,同时CPU利用率已达90%。
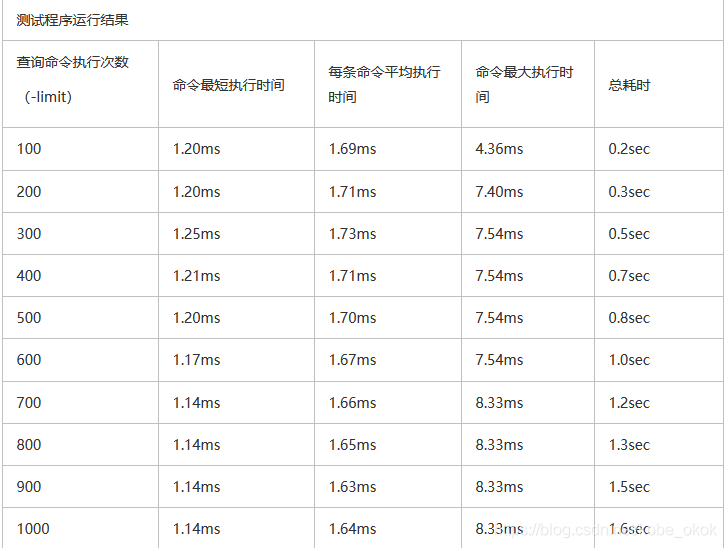 测试结论:因为该工具最大只能测到读取1000条数据,所以没有继续加大压力测试。查询操作的消耗时间因为受到被查询表的数据量和查询语句的复杂性影响,所以在influxDate官方给出的被查表和查询语句下,算出来是平均每秒执行600次查询。
测试结论:因为该工具最大只能测到读取1000条数据,所以没有继续加大压力测试。查询操作的消耗时间因为受到被查询表的数据量和查询语句的复杂性影响,所以在influxDate官方给出的被查表和查询语句下,算出来是平均每秒执行600次查询。【本文地址】
今日新闻 |
推荐新闻 |