Spark 累加器 & 广播变量 |
您所在的位置:网站首页 › java累加求和代码 › Spark 累加器 & 广播变量 |
Spark 累加器 & 广播变量
|
文章目录
Spark 累加器 & 广播变量一、累加器1、累加器说明2、代码示例3、自定义累加器
二、广播变量1、实现原理2、代码示例
Spark 累加器 & 广播变量
一、累加器
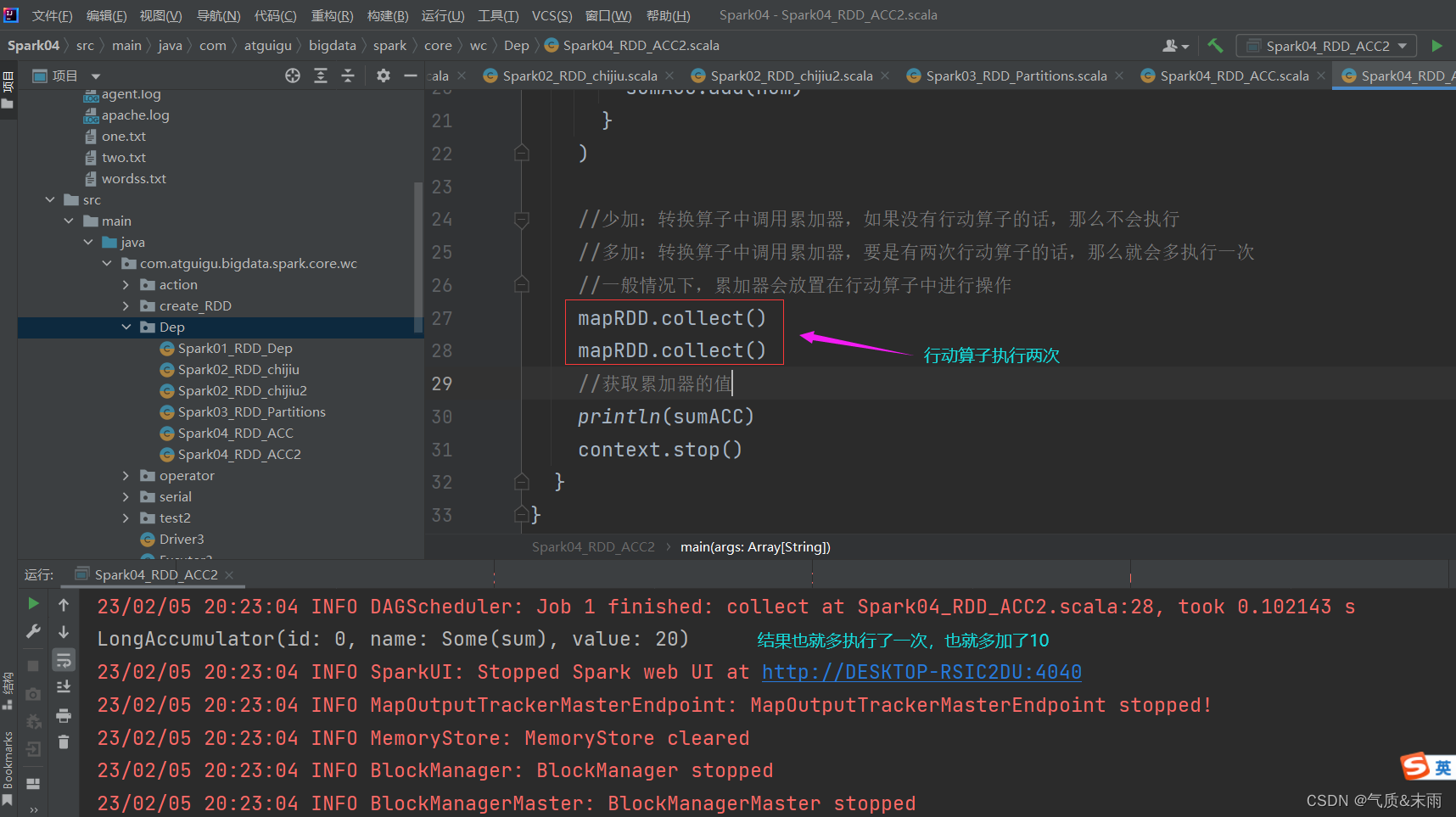
累加器分布式共享只写。 1、累加器说明累加器用把Executor端变量信息聚合到Driver端,在Driver程序中定义的变量,在 Executor 端的每个 Task 都会得到这个变量的一份新的副本,每个 Task 更新这些副本的值后,擦混会 Driver 端进行 merge(合并)。 Spark 是分布式的,可能一个数据源的数据会发送到多个分区,分别进行计算,因为闭包的原因,系统知道要把数据发送过去,但是计算完成后,不知道要再发送回去。 说明:相当于最重要的就是把数据从Driver端发送到多个Executor端进行计算,然后他们计算完之后再发送回来给Driver端进行合并。但是默认情况下是不可以从Excutor端发到Driver端的,所以要用累加器。 2、代码示例使用系统自带的累加器SparkContextlongAccumulator()里面的参数是累加器的名字。 注意:在转换算子中调用累加器,如果没有行动算子的话,那么是不会执行的,比如在map里面调用累加器,然后没有用行动算子,比如collection方法,那么累加器就没有用,所以一般来说累加器是在行动算子里面调用的,用转换算子也行,但是最后的时候用collection算子给打印出来就行了。还有一点特别要注意的,要是行动算子执行了两次的话,那么他要再执行一次,比如collection连续执行了两次,本来结果是10的,结果就变成二十了。 由于系统自带的那三个累加器功能比较简单,所以我们需要自定义累加器,比如我们这里用累加器做wordcount,这里需要几个步骤: 1、首先我们要创建一个累加器对象,这个就是我们自定义的累加器类。 2、SparkContextregister() 方法向Spark注册,里面两个参数,第一个把创建的累加器对象放进去,第二个参数是累加器的名字。 3、在行动算子foreach()里面调用累加器。 4、在我们自定义累加器的时候,要遵循几个原则,继承一个AccumulatorV2类,然后我们要定义累加器输入和输出的泛型,继承的这个类是一个抽象方法,我们要把里面的方法全部重写,具体的我们看下面的代码。 package com.atguigu.bigdata.spark.core.wc.Dep import org.apache.spark.util.AccumulatorV2 import org.apache.spark.{SparkConf, SparkContext} import scala.collection.mutable import scala.util.parsing.json.JSON.headOptionTailToFunList // 用自定义的累加器来做 wordcount //自定义累加器 class Spark04_RDD_ACC3 { } object Spark04_RDD_ACC3{ def main(args: Array[String]): Unit = { val conf = new SparkConf().setMaster("local[*]").setAppName("RDD") val context = new SparkContext(conf) val rdd = context.makeRDD(List("hello","spark","spark","scala")) //累加器:wordcount 因为没有能匹配的类型的累加器,所以我们要自己写一个累加器 //创建累加器对象 val wcAcc = new MyAccumulator //向Spark进行注册 context.register(wcAcc,"wordCountAcc") //把累加器对象放到这里面 rdd.foreach( word => { //数据的累加(使用累加器) wcAcc.add(word) //add是获取输出的,把每一个单词获取到累加器里面 } ) //获取累加器累加的结果 println(wcAcc) context.stop() } /* * 自定义数据累加器: WordCount * 想要自定义累加器要遵循几个原则 * 1、继承AccumulatorV2 定义泛型 * IN:累加器输入的数据类型 * OUT:累加器返回的数据类型 * 2、重写方法 这是一个抽象类,要重写里面的抽象方法 * * */ //我们是要做wordcount,所以输入的是单词也就是key,String类型,最终得到结果是一个集合Map //里面key是String类型,然后单词统记是数字,所以给一个Long class MyAccumulator extends AccumulatorV2[String,mutable.Map[String,Long]] { //创建一个私有的变量集合Map来接收累加器计算完成的结果 private var wcMap = mutable.Map[String,Long]() //判断是否为初始状态 override def isZero: Boolean = { wcMap.isEmpty //如果为空那么就是初始状态了 } //复制一个新的累加器 override def copy(): AccumulatorV2[String, mutable.Map[String, Long]] = { new MyAccumulator //我们直接new一个我们当前的累机器就行了 } //重置累加器,我们重置的目的就是为了清空嘛 override def reset(): Unit = { wcMap.clear() //使用clear 方法进行这个集合 } //获取累加器需要计算的值 override def add(word: String): Unit = { //用getOrELse判断单词在不在这个集合里面,不在默认值就是0 //加的这个1就是当前出现的这一次 val newCut = wcMap.getOrElse(word,0L) + 1 wcMap.update(word,newCut) //用update来进行更新,word是之前的那个次数,newCat是更新后的 } //Driver 合并多个累加器 override def merge(other: AccumulatorV2[String, mutable.Map[String, Long]]): Unit = { val map1 = this.wcMap //我们这里相当于就是两个Map进行合并,这个是第一个 val map2 = other.value map2.foreach{ case (word,count) => { //判断map2里面出现个map1的单词没有,如果没有那么就直接加结果就行 val newCount = map1.getOrElse(word,0L) + count map1.update(word,newCount) } } } //累加器的结果 override def value: mutable.Map[String, Long] = { wcMap //这是上面用来接收到的那个Map集合,这里直接返回就行了 } } } 二、广播变量广播变量分布式共享只读。 1、实现原理广播变量用来高效分发较大的对象。向所有工作节点发送一个较大的只读值,以供一个或多个 Spark 操作使用。比如,如果你的应用需要向所有节点发送一个较大的只读查询表,广播变量用起来都很顺手。在多个并行操作中使用同一个变量,但是 Spark 会为每个任务分别发送。 说明: 闭包数据,都是以 Task 为单位发送的,每个任务中国包含闭包数据,这样会导致,一个Executor中含有大量重复的数据,并且占用大量的内存。 Executor 其实就一个JVM,所以在自动启动时,会自动分配内存,完全可以将任务中的闭包数据放置在 Executor 的内存中,达到共享的目的。 Spark 中的广播变量就可以将闭包的数据保存到 Executor 的内存中。 Spark 中的广播变量 不能够更改:分布式只读变量。 2、代码示例广播变量获取方法:broadcast()里面的参数是数据源 package com.atguigu.bigdata.spark.core.wc.Dep import org.apache.spark.broadcast.Broadcast import org.apache.spark.{SparkConf, SparkContext} import scala.collection.mutable class Spark05_RDD_gb2 { } object Spark05_RDD_gb2{ def main(args: Array[String]): Unit = { val conf = new SparkConf().setMaster("local[*]").setAppName("广播变量") val context = new SparkContext(conf) val rdd1 = context.makeRDD(List(("a", 1), ("b", 2), ("c", 3))) val map = mutable.Map(("a", 4), ("b", 5), ("c", 6)) //封装广播变量 //broadcast()方法,广播变量 val bc: Broadcast[mutable.Map[String, Int]] = context.broadcast(map) rdd1.map{ case (w,c) => { val l:Int = bc.value.getOrElse(w,0) //判断集合2里面有没有这个字母,如果没有就是0 (w,(c,l)) //直接返回这个 } }.collect().foreach(println) context.stop() } } |
【本文地址】
今日新闻 |
推荐新闻 |