机器学习预测2022年考研成绩、考研分数线 |
您所在的位置:网站首页 › 查看历史考研成绩的网站有哪些 › 机器学习预测2022年考研成绩、考研分数线 |
机器学习预测2022年考研成绩、考研分数线
|
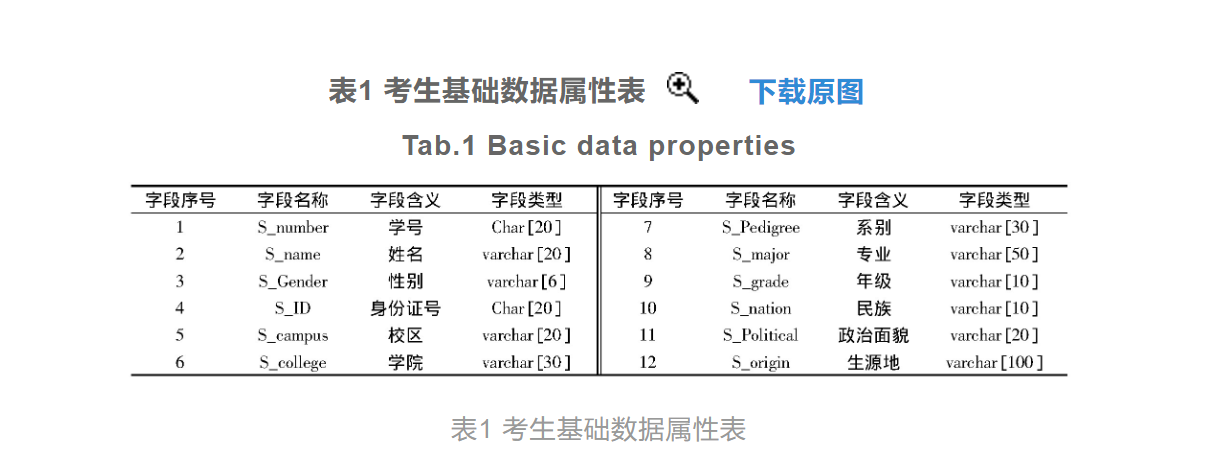
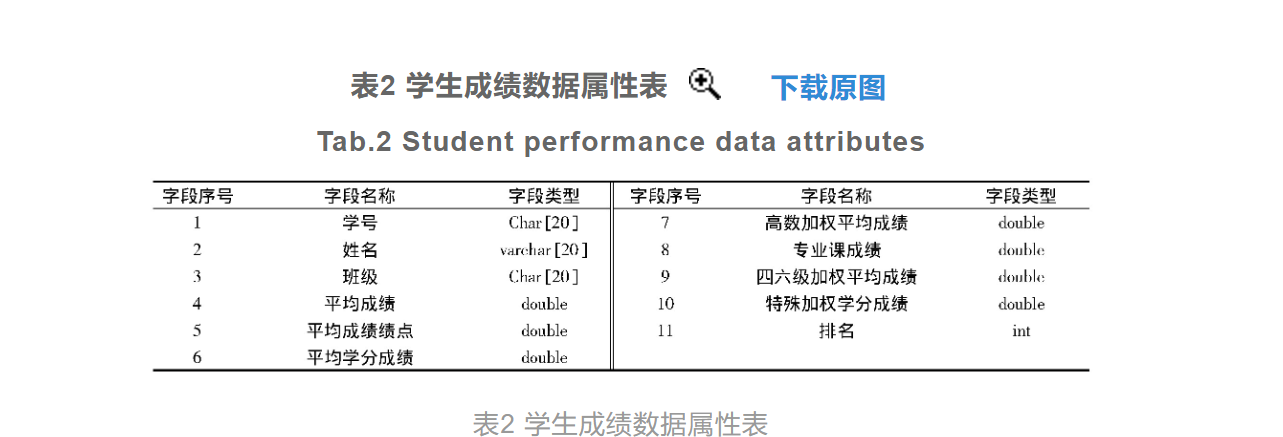
大作业2:利用机器学习算法,实现:2022年考研成绩预测。 要求: 1.预测一下2022年考研各门课程的分数线。 2.样本数据的获得与收集,自己提供。 3.使用学过的机器学习算法, 4.编写程序代码 5.训练模型 6.模型测试 Logistic 考研成绩预测 佳俊提醒你:200多人,都抄重了 点击[此处]查看有趣的鼠标点击CSS样式 总览针对传统考研成绩变量预测方法的变量关联性低,导致预测结果存在较大误差的问题,提出基于Logistic算法的考研成绩变量预测方法。收集并处理历年考研成绩数据和学生成绩数据,作为成绩变量预测的初始数据。设置考研成绩的预测变量,建立Logistic回归分类算法模型,通过该模型的运算提高考研成绩变量之间的关联性。综合历年考研成绩数据的发展规律以及变量的影响因素分析结果,得出考研成绩变量的预测结果。通过对比实验分析得出结论:基于Logistic算法的考研成绩变量预测方法的预测误差率较低,预测准确性较高。 引导从历年研究生考试的报名情况看,报考硕士研究生的学生人数持续增加,2018年我国研究生报名人数为238万人,2019年为290万人,比上一年增加52万人,中国研究生教育已经进入了新的历史发展阶段。考研成绩的预测可以预估考生的考试成绩,并为考研的下一个程序阶段做准备。由于考研成绩与多个成绩变量有关,因此为了保证考研成绩结果的预测精度,需要提出一种高精度考研成绩变量预测方法。教育部在2012年发布了考研成绩的相关报告,对考研成绩统计工作产生了深远的影响。但对考研成绩数据的预测和研究工作起步较晚,相关研究文献较少。目前对考研成绩变量预测方法的研究成果主要包括多变量GM(1,N)灰色模型成绩预测方法、正交核最小二乘法成绩预测方法和权重分配组合模型成绩预测方法等。然而在成绩变量预测问题的研究上仍存在缺陷有待改进,例如仅凭学生的单一成绩数据对考研成绩进行预测、历史数据的获取来源过于单一等。为解决上述传统方法存在的问题,在前人研究已取得重大成果的基础上进一步探索,笔者提出了基于Logistic算法的考研成绩变量预测方法,该方法主要立足于Logistic算法,即回归分类模型,与传统的分析手段不同,其将考研成绩变量的诸多影响因素按照不同的逻辑层次进行划分,凸显出不同层次影响因素的主次效应,得出更加精准的考研成绩变量预测结果。 考研成绩变量预测方法设计考研成绩变量预测方法在设计过程中引入了Logistic算法,并以该算法的运行原理为基础构建对应的回归分类模型。以某学生的历史学习数据以及历年考研的成绩数据作为初始数据,通过模型的运算得出考研成绩变量的变化规律,结合考研成绩变量的影响因素得出最终的成绩变量预测结果,并实现该预测方法的设计目的。 收集历年考研成绩数据历年考研成绩数据的采集是为了获取研究所需的学生基础信息数据以及历史成绩数据,其中学生的基础信息数据包括学生的学号、年龄和性别等,由于信息系统中学生信息的精确度较低,不能满足技术要求,因此运用python工具编写一个网络爬虫程序,通过学生的身份证号在相关平台上进行历史数据信息的抓取,并从抓取到的文件中对此次研究中需要使用的信息数据进行解析,最终获取到可以满足成绩变量预测方法研究要求的学生历史信息数据。经过历年考研成绩数据的收集,得出的考研学生基础数据的部分采集结果如表1所示。
初始考研成绩与学生成绩数据中出现的缺失和不一致的数据十分普遍,低质量的成绩数据会干扰变量的预测效果。为了去除初始成绩数据中的干扰因素,产生更加准确的考研成绩变量预测结果,需要预处理初始数据,数据预处理的内容主要包括数据清洗、数据变换和数据规约3部分[5]。首先在初始数据中搜索离群点数据、缺失数据和异常数据,针对不同的异常类型采取不处理、删除记录以及数据插补3种处理方式。数据变换是对数据进行的一系列规范化的操作,主要包括简单函数变换、数据标准化变换、连续属性离散化处理等变换方式。结合预测方法的设计需求,保证预测结果数据的标准化,在初始数据的预处理过程中选择数据标准化处理方式,定义W为初始成绩数据集,利用
以预处理完成的初始数据为基础,结合数据内容分析结果与数据特征提取结果,设置考研成绩预测变量[8]。在本次预测方法中设置的考研成绩变量分别为平均成绩绩点、高数加权平均成绩、专业课成绩和四六级加权平均成绩,其中平均成绩绩点是评估考研成绩的一项重要指标,该变量的计算公式如下: 其中GPA为平均成绩绩点,fi和gi分别为课程学分和课程绩点,gi的计算表达式为 其中F为学生的实际考研科目总分数。加权平均成绩是学生每门考研成绩与其权值比例的乘积计算出的平均成绩,其计算表达式为其中Fi为加权科目分数,WA为单科考研的加权平均成绩。通过式(5)的计算可得出高数、政治以及英语四六级的加权成绩计算结果。而专业课成绩可以通过数据调取直接得出,为提高数据的参考价值,可以计算专业课的平均值代替某一次专业课的实际成绩。 构建Logistic回归分类算法模型Logistic回归分类算法模型的构建是用于描述分类响应变量与解释变量之间的关系,在本研究中也就是历史考研成绩、学生平时成绩与考研成绩之间的变量关系。定义模型中的响应变量为Y,且该变量只有0和1两种取值结果,假设Y依赖于p个自变量,记为Xi,则在自变量的作用下Y取值为0或1的概率可表示为
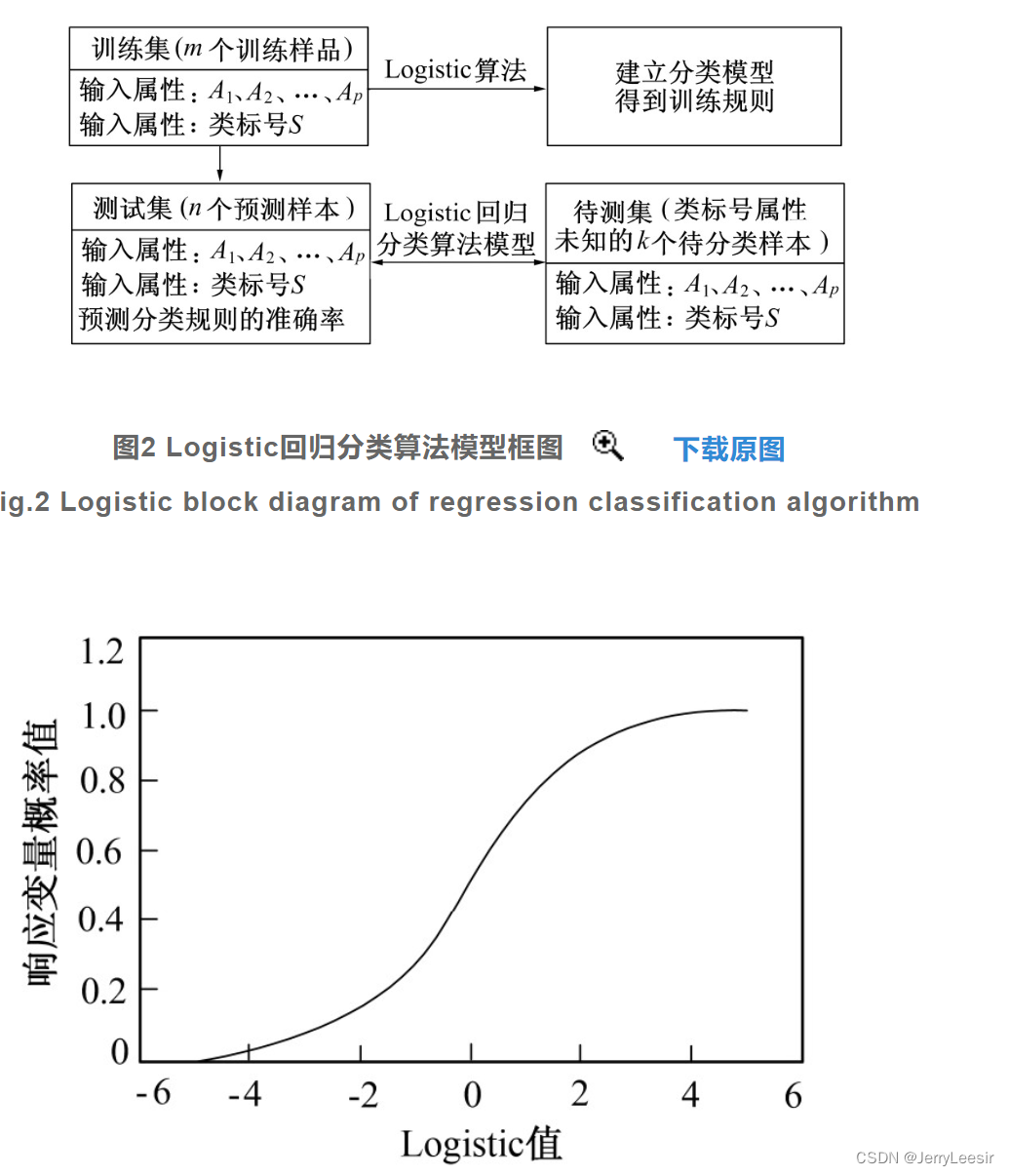
式(6)为Logistic回归分类算法模型的一般形式,其中βi为模型的回归系数,当i的取值为0时,β0为常数项,得出的Logistic回归分类算法模型建立结果如图2所示。
判断一个变量是否能对相应变量提供显著的附加解释信息,若满足则将该变量选入Logistic回归分类算法模型当中,否则剔除该变量。通过模型变量的筛选,得出模型对应的Logistic回归分类函数如图3所示。
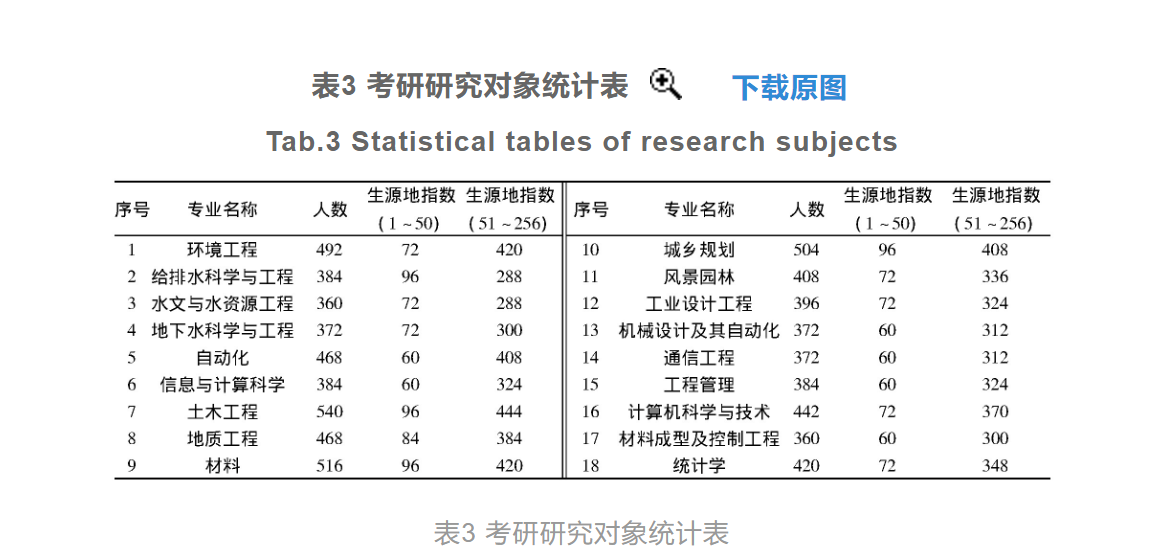
从图3中可以看出,Logistic函数的值域为[0,1],保证了模型概率估计的合理性。受到自变量变化的影响,响应变量的概率值也发生了变化。则将影响考研成绩变量的影响因素作为模型的输入值代入模型中,模型的输出值即为成绩变量回归分类的结果。 对比实验分析 考研研究对象以全国256个地级及以上城市的1 195所本科高等学院获得各个城市本科高校生作为此次实验的研究对象。选择的研究对象为具有考研意愿的大四学生,由于生源地对考生的成绩存在着一定的影响,因此在选择考研研究对象时,需要将考生的生源地信息一同存储到主测环境中,作为实验的自变量之一。通过对学生数据的筛选最终确定实验研究对象共7 642人,具体的研究对象统计情况如表3所示。
针对选择的实验研究样本,调取每个考生在校期间的成绩,需要调取的成绩包括四六级成绩、英语成绩、高数成绩、政治成绩和专业课成绩,并在主测环境中生成对应的初始数据,如图4所示。
对比设计基于Logistic算法的考研成绩变量预测方法与现有预测方法之间的预测误差,凸显设计的考研成绩变量预测方法的应用价值。为了保证实验结果的可信度,在实验中分别设置传统的考研成绩变量预测方法和文献[5]中的基于正交核最小二乘法的成绩预测方法作为此次实验的两个对比方法,其中传统的预测方法是通过分析历年考研成绩变量的变化趋势,得出对应的变化规律,从而得出预测结果。而文献[5]中的预测方法,在传统预测方法的基础上应用了正交核最小二乘法,通过该技术方法的应用,分析历史考研成绩数据与成绩变量之间的关系,得出最终的成绩预测结果。分别将3种预测方法导入到相同的实验环境中,并连接初始样本数据,保证预测方法可以实时调用样本数据。设置考研成绩变量的实际预测数据,其中部分考研成绩变量的数据设置情况如表4所示。
将3种方法的预测结果与设置的数据做对比,可以得出有关考研成绩变量预测误差的实验结果,其中设计的考研成绩变量的预测输出结果如图5所示。
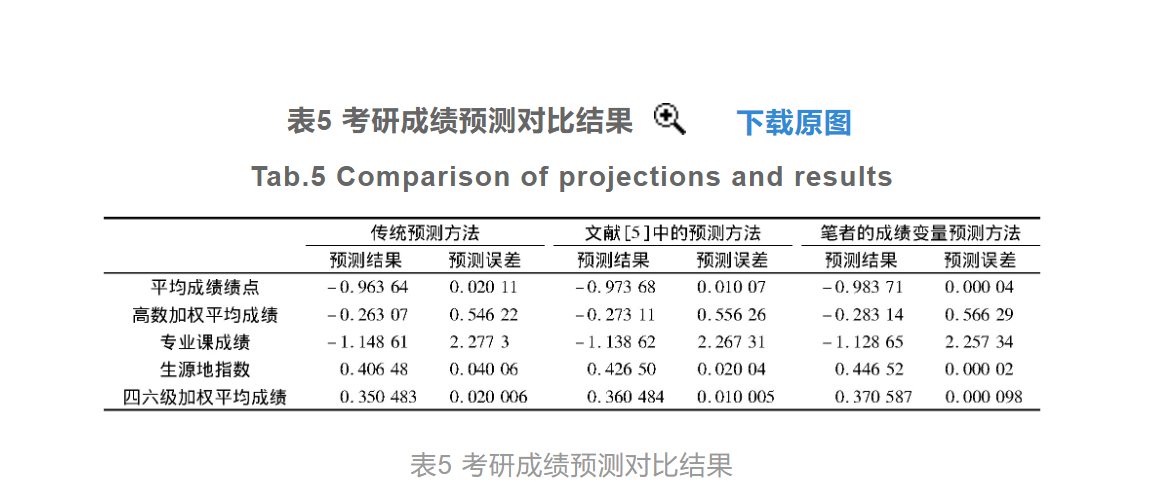
从表5可以看出,在实验样本1中应用传统的成绩变量预测方法,得出的平均预测误差约为0.58,而应用文献[5]中提出的以及本设计的成绩变量预测方法,对应的平均预测误差分别为0.57和0.56。使用相同的测试方法得出本次实验中7 642个样本的平均预测误差,通过对比传统预测方法和文献[5]中预测方法的平均预测误差分别为0.65和0.62,而笔者预测方法的平均预测误差为0.54,由此可见设计预测方法的预测准确性更高。其原因是所设计预测方法综合所有考研成绩的影响因素,并将其作为Logistic回归分类算法的自变量导入到构建的模型中,得出对应的响应变量,即考研成绩变量的概率测算结果,在一定程度上,有助于提高预测结果准确性。 结语大学生毕业去向的选择不仅对大学生自身非常重要,同时也是国家、社会、高校十分关注的问题。考研首先要符合国家标准,其次按照考研进度,分别完成与学校联系、报名、初试、调剂、复试、复试调剂以及录取等程序。考研成绩是决定大学生能顺利拿到研究生学位的重要决定因素,考研成绩按照不同的报考专业,对应的计算方式不同,考研的必考科目包括专业课、英语、数学和政治,此外,其他专业课均为招生自主命题、阅卷。考研成绩变量的预测可以在一定程度上影响考生的实际成绩,通过Logistic算法的应用解决了变量单一的问题,从实验结果看能有效地提升对考研成绩变量预测的准确度,因此设计的基于Logistic算法的考研成绩变量预测方法可以推广使用。 佳俊提醒你:本篇文章,不适用2022年5月份的Python大作业,参考就好! 参考代码由于作者未开源代码,你可以参考下面的Logistic回归代码,去复现本文代码! colicLogRegres.py # -*- coding:UTF-8 -*- from sklearn.linear_model import LogisticRegression import numpy as np import random """ 函数说明:sigmoid函数 Parameters: inX - 数据 Returns: sigmoid函数 Author: Jack Cui Blog: http://blog.csdn.net/c406495762 Zhihu: https://www.zhihu.com/people/Jack--Cui/ Modify: 2017-09-05 """ def sigmoid(inX): return 1.0 / (1 + np.exp(-inX)) """ 函数说明:改进的随机梯度上升算法 Parameters: dataMatrix - 数据数组 classLabels - 数据标签 numIter - 迭代次数 Returns: weights - 求得的回归系数数组(最优参数) Author: Jack Cui Blog: http://blog.csdn.net/c406495762 Zhihu: https://www.zhihu.com/people/Jack--Cui/ Modify: 2017-09-05 """ def stocGradAscent1(dataMatrix, classLabels, numIter=150): m, n = np.shape(dataMatrix) # 返回dataMatrix的大小。m为行数,n为列数。 weights = np.ones(n) # 参数初始化 #存储每次更新的回归系数 for j in range(numIter): dataIndex = list(range(m)) for i in range(m): alpha = 4 / (1.0 + j + i) + 0.01 # 降低alpha的大小,每次减小1/(j+i)。 randIndex = int(random.uniform(0, len(dataIndex))) # 随机选取样本 h = sigmoid(sum(dataMatrix[randIndex] * weights)) # 选择随机选取的一个样本,计算h error = classLabels[randIndex] - h # 计算误差 weights = weights + alpha * error * dataMatrix[randIndex] # 更新回归系数 del (dataIndex[randIndex]) # 删除已经使用的样本 return weights # 返回 """ 函数说明:梯度上升算法 Parameters: dataMatIn - 数据集 classLabels - 数据标签 Returns: weights.getA() - 求得的权重数组(最优参数) Author: Jack Cui Blog: http://blog.csdn.net/c406495762 Zhihu: https://www.zhihu.com/people/Jack--Cui/ Modify: 2017-08-28 """ def gradAscent(dataMatIn, classLabels): dataMatrix = np.mat(dataMatIn) # 转换成numpy的mat labelMat = np.mat(classLabels).transpose() # 转换成numpy的mat,并进行转置 m, n = np.shape(dataMatrix) # 返回dataMatrix的大小。m为行数,n为列数。 alpha = 0.01 # 移动步长,也就是学习速率,控制更新的幅度。 maxCycles = 500 # 最大迭代次数 weights = np.ones((n, 1)) for k in range(maxCycles): h = sigmoid(dataMatrix * weights) # 梯度上升矢量化公式 error = labelMat - h weights = weights + alpha * dataMatrix.transpose() * error return weights.getA() # 将矩阵转换为数组,并返回 """ 函数说明:使用Python写的Logistic分类器做预测 Parameters: 无 Returns: 无 Author: Jack Cui Blog: http://blog.csdn.net/c406495762 Zhihu: https://www.zhihu.com/people/Jack--Cui/ Modify: 2017-09-05 """ def colicTest(): frTrain = open('horseColicTraining.txt') # 打开训练集 frTest = open('horseColicTest.txt') # 打开测试集 trainingSet = [] trainingLabels = [] for line in frTrain.readlines(): currLine = line.strip().split('\t') lineArr = [] for i in range(len(currLine) - 1): lineArr.append(float(currLine[i])) trainingSet.append(lineArr) trainingLabels.append(float(currLine[-1])) trainWeights = stocGradAscent1(np.array(trainingSet), trainingLabels, 500) # 使用改进的随即上升梯度训练 errorCount = 0 numTestVec = 0.0 for line in frTest.readlines(): numTestVec += 1.0 currLine = line.strip().split('\t') lineArr = [] for i in range(len(currLine) - 1): lineArr.append(float(currLine[i])) if int(classifyVector(np.array(lineArr), trainWeights)) != int(currLine[-1]): errorCount += 1 errorRate = (float(errorCount) / numTestVec) * 100 # 错误率计算 print("测试集错误率为: %.2f%%" % errorRate) """ 函数说明:分类函数 Parameters: inX - 特征向量 weights - 回归系数 Returns: 分类结果 Author: Jack Cui Blog: http://blog.csdn.net/c406495762 Zhihu: https://www.zhihu.com/people/Jack--Cui/ Modify: 2017-09-05 """ def classifyVector(inX, weights): prob = sigmoid(sum(inX * weights)) if prob > 0.5: return 1.0 else: return 0.0 """ 函数说明:使用Sklearn构建Logistic回归分类器 Parameters: 无 Returns: 无 Author: Jack Cui Blog: http://blog.csdn.net/c406495762 Zhihu: https://www.zhihu.com/people/Jack--Cui/ Modify: 2017-09-05 """ def colicSklearn(): frTrain = open('horseColicTraining.txt') # 打开训练集 frTest = open('horseColicTest.txt') # 打开测试集 trainingSet = [] trainingLabels = [] testSet = [] testLabels = [] for line in frTrain.readlines(): currLine = line.strip().split('\t') lineArr = [] for i in range(len(currLine) - 1): lineArr.append(float(currLine[i])) trainingSet.append(lineArr) trainingLabels.append(float(currLine[-1])) for line in frTest.readlines(): currLine = line.strip().split('\t') lineArr = [] for i in range(len(currLine) - 1): lineArr.append(float(currLine[i])) testSet.append(lineArr) testLabels.append(float(currLine[-1])) classifier = LogisticRegression(solver='sag', max_iter=5000).fit(trainingSet, trainingLabels) test_accurcy = classifier.score(testSet, testLabels) * 100 print('正确率:%f%%' % test_accurcy) if __name__ == '__main__': colicSklearn()LogRegres.py # -*- coding:UTF-8 -*- import matplotlib.pyplot as plt import numpy as np import types """ 函数说明:梯度上升算法测试函数 求函数f(x) = -x^2 + 4x的极大值 Parameters: 无 Returns: 无 Author: Jack Cui Blog: http://blog.csdn.net/c406495762 Zhihu: https://www.zhihu.com/people/Jack--Cui/ Modify: 2017-08-28 """ def Gradient_Ascent_test(): def f_prime(x_old): # f(x)的导数 return -2 * x_old + 4 x_old = -1 # 初始值,给一个小于x_new的值 x_new = 0 # 梯度上升算法初始值,即从(0,0)开始 alpha = 0.01 # 步长,也就是学习速率,控制更新的幅度 presision = 0.00000001 # 精度,也就是更新阈值 while abs(x_new - x_old) > presision: x_old = x_new x_new = x_old + alpha * f_prime(x_old) # 上面提到的公式 print(x_new) # 打印最终求解的极值近似值 """ 函数说明:加载数据 Parameters: 无 Returns: dataMat - 数据列表 labelMat - 标签列表 Author: Jack Cui Blog: http://blog.csdn.net/c406495762 Zhihu: https://www.zhihu.com/people/Jack--Cui/ Modify: 2017-08-28 """ def loadDataSet(): dataMat = [] # 创建数据列表 labelMat = [] # 创建标签列表 fr = open('testSet.txt') # 打开文件 for line in fr.readlines(): # 逐行读取 lineArr = line.strip().split() # 去回车,放入列表 dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])]) # 添加数据 labelMat.append(int(lineArr[2])) # 添加标签 fr.close() # 关闭文件 return dataMat, labelMat # 返回 """ 函数说明:sigmoid函数 Parameters: inX - 数据 Returns: sigmoid函数 Author: Jack Cui Blog: http://blog.csdn.net/c406495762 Zhihu: https://www.zhihu.com/people/Jack--Cui/ Modify: 2017-08-28 """ def sigmoid(inX): return 1.0 / (1 + np.exp(-inX)) """ 函数说明:梯度上升算法 Parameters: dataMatIn - 数据集 classLabels - 数据标签 Returns: weights.getA() - 求得的权重数组(最优参数) Author: Jack Cui Blog: http://blog.csdn.net/c406495762 Zhihu: https://www.zhihu.com/people/Jack--Cui/ Modify: 2017-08-28 """ def gradAscent(dataMatIn, classLabels): dataMatrix = np.mat(dataMatIn) # 转换成numpy的mat labelMat = np.mat(classLabels).transpose() # 转换成numpy的mat,并进行转置 m, n = np.shape(dataMatrix) # 返回dataMatrix的大小。m为行数,n为列数。 alpha = 0.001 # 移动步长,也就是学习速率,控制更新的幅度。 maxCycles = 500 # 最大迭代次数 weights = np.ones((n, 1)) for k in range(maxCycles): h = sigmoid(dataMatrix * weights) # 梯度上升矢量化公式 error = labelMat - h weights = weights + alpha * dataMatrix.transpose() * error return weights.getA() # 将矩阵转换为数组,返回权重数组 """ 函数说明:绘制数据集 Parameters: 无 Returns: 无 Author: Jack Cui Blog: http://blog.csdn.net/c406495762 Zhihu: https://www.zhihu.com/people/Jack--Cui/ Modify: 2017-08-30 """ def plotDataSet(): dataMat, labelMat = loadDataSet() # 加载数据集 dataArr = np.array(dataMat) # 转换成numpy的array数组 n = np.shape(dataMat)[0] # 数据个数 xcord1 = [] ycord1 = [] # 正样本 xcord2 = [] ycord2 = [] # 负样本 for i in range(n): # 根据数据集标签进行分类 if int(labelMat[i]) == 1: xcord1.append(dataArr[i, 1]) ycord1.append(dataArr[i, 2]) # 1为正样本 else: xcord2.append(dataArr[i, 1]) ycord2.append(dataArr[i, 2]) # 0为负样本 fig = plt.figure() ax = fig.add_subplot(111) # 添加subplot ax.scatter(xcord1, ycord1, s=20, c='red', marker='s', alpha=.5) # 绘制正样本 ax.scatter(xcord2, ycord2, s=20, c='green', alpha=.5) # 绘制负样本 plt.title('DataSet') # 绘制title plt.xlabel('X1') plt.ylabel('X2') # 绘制label plt.show() # 显示 """ 函数说明:绘制数据集 Parameters: weights - 权重参数数组 Returns: 无 Author: Jack Cui Blog: http://blog.csdn.net/c406495762 Zhihu: https://www.zhihu.com/people/Jack--Cui/ Modify: 2017-08-30 """ def plotBestFit(weights): dataMat, labelMat = loadDataSet() # 加载数据集 dataArr = np.array(dataMat) # 转换成numpy的array数组 n = np.shape(dataMat)[0] # 数据个数 xcord1 = [] ycord1 = [] # 正样本 xcord2 = [] ycord2 = [] # 负样本 for i in range(n): # 根据数据集标签进行分类 if int(labelMat[i]) == 1: xcord1.append(dataArr[i, 1]) ycord1.append(dataArr[i, 2]) # 1为正样本 else: xcord2.append(dataArr[i, 1]) ycord2.append(dataArr[i, 2]) # 0为负样本 fig = plt.figure() ax = fig.add_subplot(111) # 添加subplot ax.scatter(xcord1, ycord1, s=20, c='red', marker='s', alpha=.5) # 绘制正样本 ax.scatter(xcord2, ycord2, s=20, c='green', alpha=.5) # 绘制负样本 x = np.arange(-3.0, 3.0, 0.1) y = (-weights[0] - weights[1] * x) / weights[2] ax.plot(x, y) plt.title('BestFit') # 绘制title plt.xlabel('X1') plt.ylabel('X2') # 绘制label plt.show() if __name__ == '__main__': dataMat, labelMat = loadDataSet() plotDataSet() weights = gradAscent(dataMat, labelMat) plotBestFit(weights)LogRegres-gj.py # -*- coding:UTF-8 -*- from matplotlib.font_manager import FontProperties import matplotlib.pyplot as plt import numpy as np import random """ 函数说明:加载数据 Parameters: 无 Returns: dataMat - 数据列表 labelMat - 标签列表 Author: Jack Cui Blog: http://blog.csdn.net/c406495762 Zhihu: https://www.zhihu.com/people/Jack--Cui/ Modify: 2017-08-28 """ def loadDataSet(): dataMat = [] # 创建数据列表 labelMat = [] # 创建标签列表 fr = open('testSet.txt') # 打开文件 for line in fr.readlines(): # 逐行读取 lineArr = line.strip().split() # 去回车,放入列表 dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])]) # 添加数据 labelMat.append(int(lineArr[2])) # 添加标签 fr.close() # 关闭文件 return dataMat, labelMat # 返回 """ 函数说明:sigmoid函数 Parameters: inX - 数据 Returns: sigmoid函数 Author: Jack Cui Blog: http://blog.csdn.net/c406495762 Zhihu: https://www.zhihu.com/people/Jack--Cui/ Modify: 2017-08-28 """ def sigmoid(inX): return 1.0 / (1 + np.exp(-inX)) """ 函数说明:梯度上升算法 Parameters: dataMatIn - 数据集 classLabels - 数据标签 Returns: weights.getA() - 求得的权重数组(最优参数) weights_array - 每次更新的回归系数 Author: Jack Cui Blog: http://blog.csdn.net/c406495762 Zhihu: https://www.zhihu.com/people/Jack--Cui/ Modify: 2017-08-28 """ # 全批量梯度上升法-每次全部使用样本计算,计算量非常大 def gradAscent(dataMatIn, classLabels): dataMatrix = np.mat(dataMatIn) # 转换成numpy的mat labelMat = np.mat(classLabels).transpose() # 转换成numpy的mat,并进行转置 m, n = np.shape(dataMatrix) # 返回dataMatrix的大小。m为行数,n为列数。 alpha = 0.01 # 移动步长,也就是学习速率,控制更新的幅度。 maxCycles = 500 # 最大迭代次数 weights = np.ones((n, 1)) weights_array = np.array([]) for k in range(maxCycles): h = sigmoid(dataMatrix * weights) # 梯度上升矢量化公式 error = labelMat - h weights = weights + alpha * dataMatrix.transpose() * error weights_array = np.append(weights_array, weights) weights_array = weights_array.reshape(maxCycles, n) return weights.getA(), weights_array # 将矩阵转换为数组,并返回 """ 函数说明:改进的随机梯度上升算法 Parameters: dataMatrix - 数据数组 classLabels - 数据标签 numIter - 迭代次数 Returns: weights - 求得的回归系数数组(最优参数) weights_array - 每次更新的回归系数 Author: Jack Cui Blog: http://blog.csdn.net/c406495762 Zhihu: https://www.zhihu.com/people/Jack--Cui/ Modify: 2017-08-31 """ # 随机梯度上升法-每次随机取一个不同的样本进行更新回归系数 def stocGradAscent1(dataMatrix, classLabels, numIter=150): m, n = np.shape(dataMatrix) # 返回dataMatrix的大小。m为行数,n为列数。 weights = np.ones(n) # 参数初始化 weights_array = np.array([]) # 存储每次更新的回归系数 for j in range(numIter): dataIndex = list(range(m)) for i in range(m): alpha = 4 / (1.0 + j + i) + 0.01 # 降低alpha的大小,每次减小1/(j+i)。 randIndex = int(random.uniform(0, len(dataIndex))) # 随机选取样本 h = sigmoid(sum(dataMatrix[randIndex] * weights)) # 选择随机选取的一个样本,计算h error = classLabels[randIndex] - h # 计算误差 weights = weights + alpha * error * dataMatrix[randIndex] # 更新回归系数 weights_array = np.append(weights_array, weights, axis=0) # 添加回归系数到数组中 del (dataIndex[randIndex]) # 删除已经使用的样本 weights_array = weights_array.reshape(numIter * m, n) # 改变维度 return weights, weights_array # 返回 """ 函数说明:绘制数据集 Parameters: weights - 权重参数数组 Returns: 无 Author: Jack Cui Blog: http://blog.csdn.net/c406495762 Zhihu: https://www.zhihu.com/people/Jack--Cui/ Modify: 2017-08-30 """ def plotBestFit(weights): dataMat, labelMat = loadDataSet() # 加载数据集 dataArr = np.array(dataMat) # 转换成numpy的array数组 n = np.shape(dataMat)[0] # 数据个数 xcord1 = [] ycord1 = [] # 正样本 xcord2 = [] ycord2 = [] # 负样本 for i in range(n): # 根据数据集标签进行分类 if int(labelMat[i]) == 1: xcord1.append(dataArr[i, 1]) ycord1.append(dataArr[i, 2]) # 1为正样本 else: xcord2.append(dataArr[i, 1]) ycord2.append(dataArr[i, 2]) # 0为负样本 fig = plt.figure() ax = fig.add_subplot(111) # 添加subplot ax.scatter(xcord1, ycord1, s=20, c='red', marker='s', alpha=.5) # 绘制正样本 ax.scatter(xcord2, ycord2, s=20, c='green', alpha=.5) # 绘制负样本 x = np.arange(-3.0, 3.0, 0.1) y = (-weights[0] - weights[1] * x) / weights[2] ax.plot(x, y) plt.title('BestFit') # 绘制title plt.xlabel('X1') plt.ylabel('X2') # 绘制label plt.show() """ 函数说明:绘制回归系数与迭代次数的关系 Parameters: weights_array1 - 回归系数数组1 weights_array2 - 回归系数数组2 Returns: 无 Author: Jack Cui Blog: http://blog.csdn.net/c406495762 Zhihu: https://www.zhihu.com/people/Jack--Cui/ Modify: 2017-08-30 """ def plotWeights(weights_array1, weights_array2): # 设置汉字格式 font = FontProperties(fname=r"c:\windows\fonts\simsun.ttc", size=14) # 将fig画布分隔成1行1列,不共享x轴和y轴,fig画布的大小为(13,8) # 当nrow=3,nclos=2时,代表fig画布被分为六个区域,axs[0][0]表示第一行第一列 fig, axs = plt.subplots(nrows=3, ncols=2, sharex=False, sharey=False, figsize=(20, 10)) x1 = np.arange(0, len(weights_array1), 1) # 绘制w0与迭代次数的关系 axs[0][0].plot(x1, weights_array1[:, 0]) axs0_title_text = axs[0][0].set_title(u'改进的随机梯度上升算法:回归系数与迭代次数关系', FontProperties=font) axs0_ylabel_text = axs[0][0].set_ylabel(u'W0', FontProperties=font) plt.setp(axs0_title_text, size=20, weight='bold', color='black') plt.setp(axs0_ylabel_text, size=20, weight='bold', color='black') # 绘制w1与迭代次数的关系 axs[1][0].plot(x1, weights_array1[:, 1]) axs1_ylabel_text = axs[1][0].set_ylabel(u'W1', FontProperties=font) plt.setp(axs1_ylabel_text, size=20, weight='bold', color='black') # 绘制w2与迭代次数的关系 axs[2][0].plot(x1, weights_array1[:, 2]) axs2_xlabel_text = axs[2][0].set_xlabel(u'迭代次数', FontProperties=font) axs2_ylabel_text = axs[2][0].set_ylabel(u'W1', FontProperties=font) plt.setp(axs2_xlabel_text, size=20, weight='bold', color='black') plt.setp(axs2_ylabel_text, size=20, weight='bold', color='black') x2 = np.arange(0, len(weights_array2), 1) # 绘制w0与迭代次数的关系 axs[0][1].plot(x2, weights_array2[:, 0]) axs0_title_text = axs[0][1].set_title(u'梯度上升算法:回归系数与迭代次数关系', FontProperties=font) axs0_ylabel_text = axs[0][1].set_ylabel(u'W0', FontProperties=font) plt.setp(axs0_title_text, size=20, weight='bold', color='black') plt.setp(axs0_ylabel_text, size=20, weight='bold', color='black') # 绘制w1与迭代次数的关系 axs[1][1].plot(x2, weights_array2[:, 1]) axs1_ylabel_text = axs[1][1].set_ylabel(u'W1', FontProperties=font) plt.setp(axs1_ylabel_text, size=20, weight='bold', color='black') # 绘制w2与迭代次数的关系 axs[2][1].plot(x2, weights_array2[:, 2]) axs2_xlabel_text = axs[2][1].set_xlabel(u'迭代次数', FontProperties=font) axs2_ylabel_text = axs[2][1].set_ylabel(u'W1', FontProperties=font) plt.setp(axs2_xlabel_text, size=20, weight='bold', color='black') plt.setp(axs2_ylabel_text, size=20, weight='bold', color='black') plt.show() if __name__ == '__main__': dataMat, labelMat = loadDataSet() weights1, weights_array1 = stocGradAscent1(np.array(dataMat), labelMat) weights2, weights_array2 = gradAscent(dataMat, labelMat) plotWeights(weights_array1, weights_array2) |
 学生的历史成绩数据方面,从教务部门获得该学院所有专业多个学年的成绩排名数据,去除与此次研究无明显关联的字段属性,得出学生历史成绩数据属性结果,如表2所示
学生的历史成绩数据方面,从教务部门获得该学院所有专业多个学年的成绩排名数据,去除与此次研究无明显关联的字段属性,得出学生历史成绩数据属性结果,如表2所示
 除了上述学生对象的历史成绩数据外,还需要对历年的考研平均数据进行收集与统计,并以采集整理完成的结果作为考研成绩变量预测的初始数据。
除了上述学生对象的历史成绩数据外,还需要对历年的考研平均数据进行收集与统计,并以采集整理完成的结果作为考研成绩变量预测的初始数据。 实现对数据的标准差标准化变换。其中W'和珚W分别为初始数据的标准化处理结果以及初始属性值的均值,σ为初始属性值的标准差[6]。为降低均值和标准差受离群点的影响,用初始数据集中的中位数替换均值数据,并用平均绝对偏差取代标准差,得出数据标准化变化处理的修正表达式为
实现对数据的标准差标准化变换。其中W'和珚W分别为初始数据的标准化处理结果以及初始属性值的均值,σ为初始属性值的标准差[6]。为降低均值和标准差受离群点的影响,用初始数据集中的中位数替换均值数据,并用平均绝对偏差取代标准差,得出数据标准化变化处理的修正表达式为
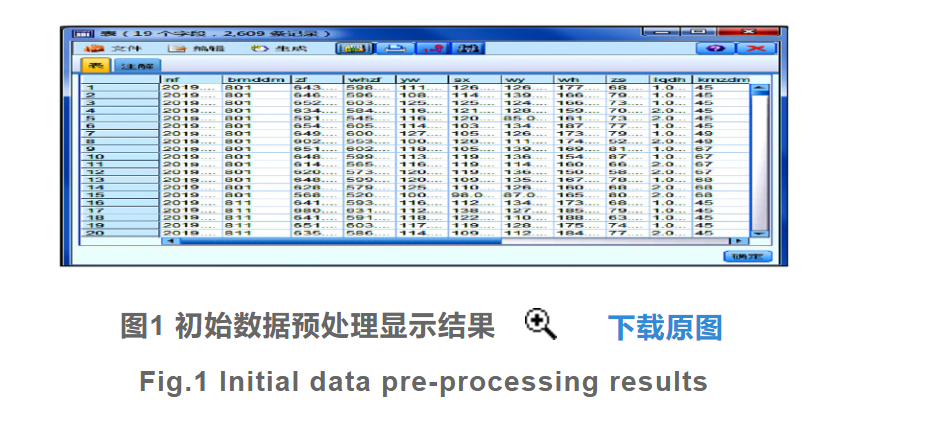
 其中M为初始数据集中的平均值或中位数,n为初始数据集中数据的数量[7]。最后从属性规约和数值规约两个方面实现对初始数据集的规约处理,并得出预处理完成的考研成绩初始数据表,如图1所示
其中M为初始数据集中的平均值或中位数,n为初始数据集中数据的数量[7]。最后从属性规约和数值规约两个方面实现对初始数据集的规约处理,并得出预处理完成的考研成绩初始数据表,如图1所示
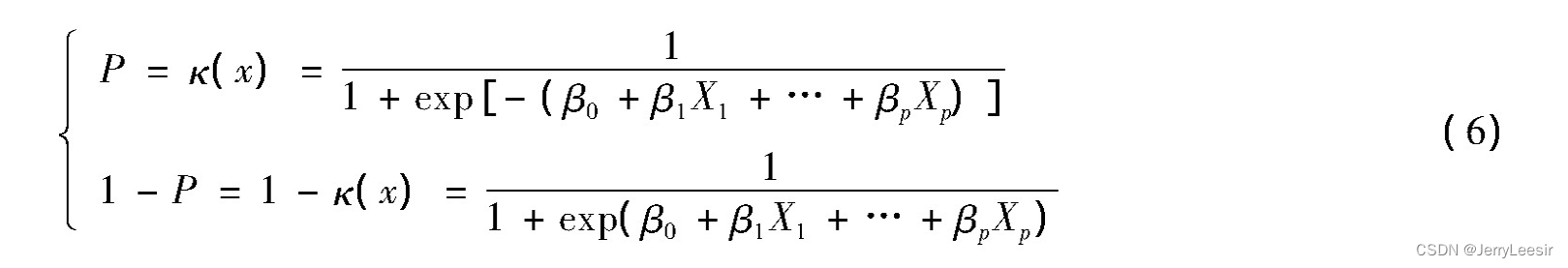
 除了研究对象的平时成绩外,还需要调取不同生源地近5年不同专业的考研成绩,包括考研的平均成绩以及考研的分数线等。按照相同的方式导入到实验环境中,并生成对应的数据库表。
除了研究对象的平时成绩外,还需要调取不同生源地近5年不同专业的考研成绩,包括考研的平均成绩以及考研的分数线等。按照相同的方式导入到实验环境中,并生成对应的数据库表。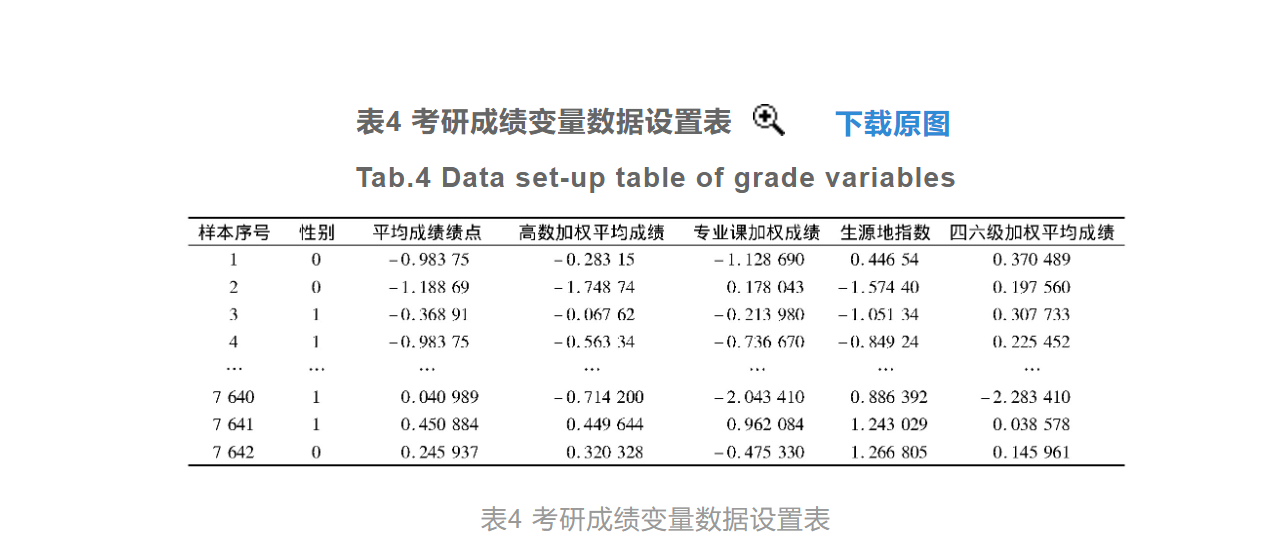
【本文地址】
今日新闻 |
推荐新闻 |