Python 汽车之家 全系车型参数(包含历史停售车型) 最全 |
您所在的位置:网站首页 › 龙华行政划分 › Python 汽车之家 全系车型参数(包含历史停售车型) 最全 |
Python 汽车之家 全系车型参数(包含历史停售车型) 最全
|
本文仅供学习交流使用,如侵立删!联系方式及demo下载见文末 **** 汽车之家2021 全系车型参数(包含历史停售车型) **** 2021.10.21更新 增加参数:电动扰流板、无框设计车门、隐藏电动门把手、自动驾驶芯片、芯片总算力... **** 2021.8.12更新 最新官网数据(共57380款车型数据) **** 2021.7.8更新 最新官网数据(新增或修改共1098款车型数据)
**** 打包成了采集器,需要的自行下载。
**** 2021.5.17更新 更新最新官网数据:新增821款车型参数及图片
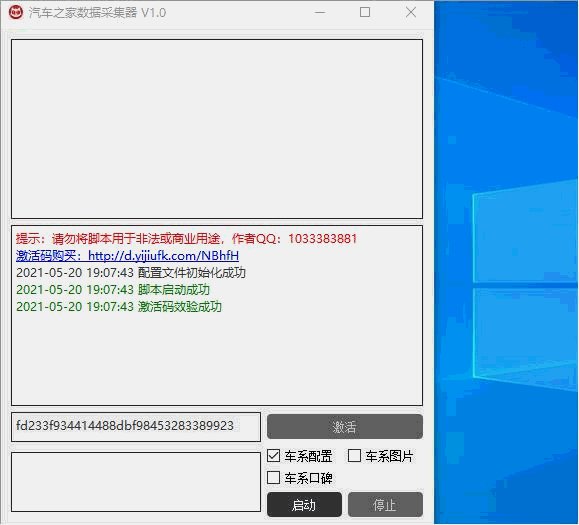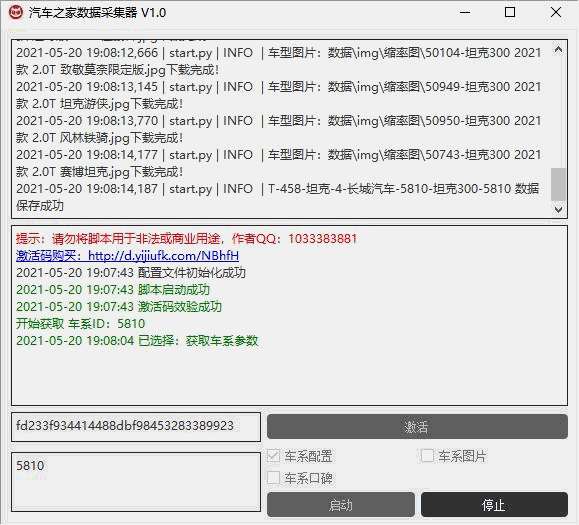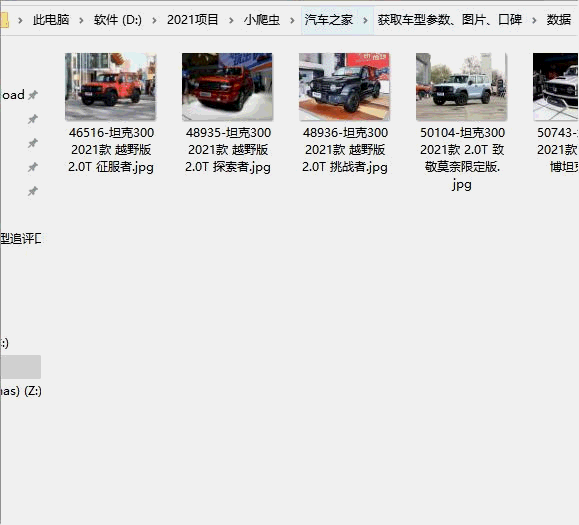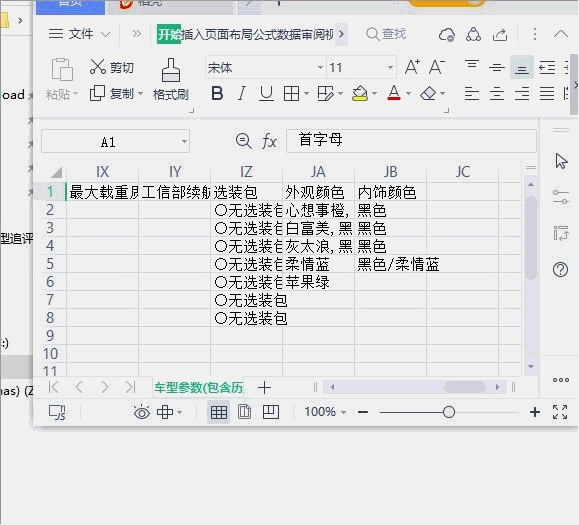
**** 2021.4.14更新 最新官网数据 更改解析,保存更多参数 增加:logo、车型图片
**** 2021.3.7更新最新数据 **** 2021.1.29更新全系车辆十年保值率数据
**** 2021.1.17更新汽车之家全系车型图片:576149张原图(50.5G)**** 2021.1.8更新增加:品牌LOGO **** 2021.1.6更新更新:最新2021官网数据 **** 2020.5.9更新**增加:选装包、外观颜色、内饰颜色参数 修复:多行数据存储不完整问题**
****** 2020.4.15更新更新最新官网数据 ****** 2020.3.22更新**新增:途虎养车 车型、保养 数据 ****** 2020.1.9更新增加:品牌首字母,品牌ID,品牌名称,车系ID,车系名称,车型ID,车型名称 字段数据 **************** 2019.12.25更新很多网友留言说需要车标logo,果断满足需求 1. 车标logo页面 只需要车标logo和品牌参数,从移动端页面直接获取比较方便 https://car.m.autohome.com.cn/ 2.解析车标图片url和品牌名称 response = requests.get("https://car.m.autohome.com.cn/")response.encoding = 'UTF-8'html = etree.HTML(response.text)items = html.xpath('//*[@class="item"]')for item in items: logo_url = item.xpath('./img/@data-src') if not logo_url: continue text = item.xpath('./span')[0].text downLoadImage(text, logo_url[0])3.根据url下载图片 def downLoadImage(fileName, downLoadUrl): r = requests.get(downLoadUrl) fileName = fileName + ".jpg" print("正在下载 " + fileName) with open("img/" + fileName, 'wb') as f: f.write(r.content)4.运行结果 ************** 2019.12.17更新**闲来无事研究了一下*车之家页面class 字体混淆**
效果: **** 2019.10.12更新有人反馈数据不全刚抽出时间看了一下,原来之前只取了在售车型没有获取停售的车型数据,本次更新后数据为国内在售(停售)全系车型数据包含历史数据 **** 2019.9.29更新闲来无事把脚本更新了一下用selenium,获取了全系全车型详细参数,主要这次包含了停售车型数据,所有历史车型数据 **** 所有车型数据
ps:当然也可通过解析网页 xpath提取,或通过接口,获取方式有很多种,此文主要需要seriesId 车型ID 这一项数据 为获取车型价格做准备 顾用此方法。
价格接口需要两个参数:dealerId 经销商ID 和 seriesId 车型ID
经销商接口需要两个参数:seriesId 车型ID 和 cityId 区域代码 def get_price(self, dealerId, seriesId): """获取价格""" url = ‘删除线格式 ’ # 根据经销商ID 和 车型ID 获取车型价格 response = self._parse_url(url) # 无数据跳过 if not response.json()['result']['list']: print('暂无经销商信息') return # 获取经销商信息 主要取经销商ID 用来获取价格 contents = response.json()['result']['list'] for con in contents: # 汽车型号 SpecName = con['SpecName'] # 指导价 OriginalPrice = con['OriginalPrice'] # 参考价 Price = con['Price'] print('{}数据请求中'.format(SpecName)) yield SpecName, OriginalPrice, Price
**** 数据DEMO链接:https://pan.baidu.com/s/1aQMR_2ix_ANK7DkujxaAwg 提取码:cmwi **** 本文仅供学习交流使用,如侵立删! **** |













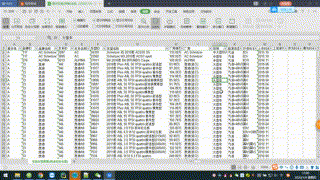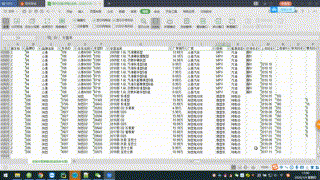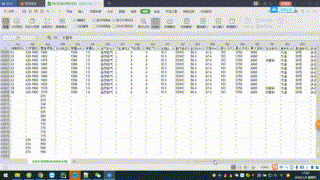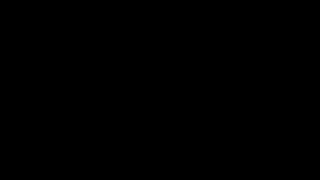
 思路:
思路: 途中碰到问题:
途中碰到问题:

 分析发现所有车型数据在一个js文件中:
分析发现所有车型数据在一个js文件中:




【本文地址】
今日新闻 |
推荐新闻 |