深度学习 |
您所在的位置:网站首页 › 鸢尾花种类识别 › 深度学习 |
深度学习
|
iris数据集介绍
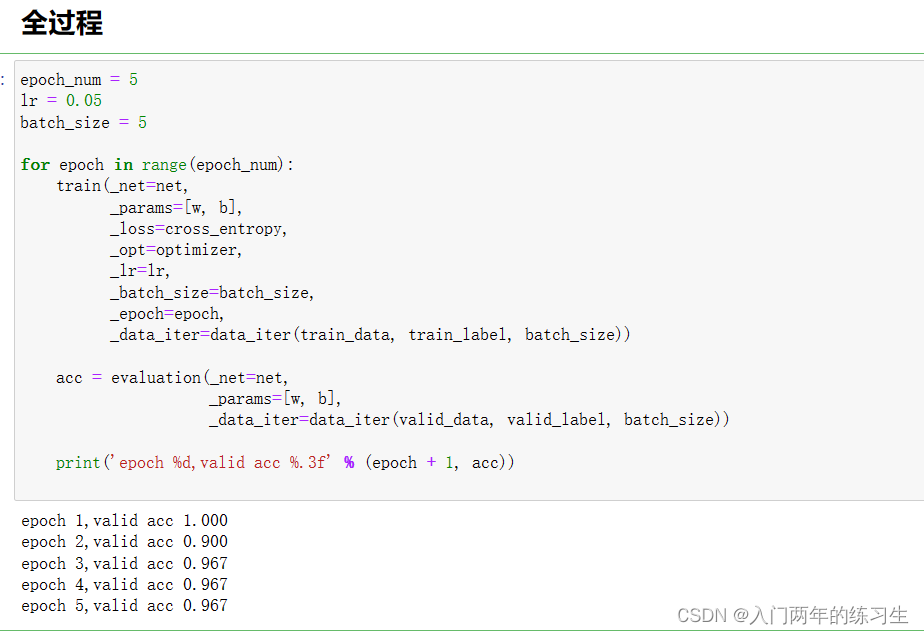
由统计学家和植物学家Ronald Fisher在1936年收集并发布。该数据集中包含了150个样本,其中每个样本代表了一朵鸢尾花(iris flower),并且包含了四个特征(sepal length(花萼长度)、sepal width(花萼宽度)、petal length(花瓣长度)和petal width(花瓣宽度))以及对应的类别标签(iris setosa、iris versicolor和iris virginica)。 样本数量:150条类别数量:3类每类样本:50条特征维度:4 读取数据集 import numpy as np import torch def load_iris(filename): data = np.load(filename) features = data['data'] labels = data['label'] return torch.tensor(features, dtype=torch.float64), torch.tensor(labels, dtype=torch.int64) train_data, train_label = load_iris(r"../../Dataset/iris/iris_train.npz") valid_data, valid_label = load_iris(r"../../Dataset/iris/iris_valid.npz") print(train_data.shape, train_label.shape, valid_data.shape, valid_label.shape,) input_dim = train_data.shape[1] output_dim = int(train_label.max().numpy()) + 1 print(input_dim, output_dim) import random def data_iter(feature, label, _batch_size): num_samples = len(label) index_list = list(range(num_samples)) random.shuffle(index_list) for i in range(0, num_samples, _batch_size): batch_index = index_list[i: min(i + _batch_size, num_samples)] batch_features = torch.index_select(feature, dim=0, index=torch.LongTensor(batch_index)) batch_labels = torch.index_select(label, dim=0, index=torch.LongTensor(batch_index)) yield batch_features, batch_labels for x, y in data_iter(train_data, train_label, 2): print(x, y) break在Iris数据集中,标签的取值为0、1、2,因此最大值为2。为了将标签用于多分类问题,需要将其转换为one-hot编码,输出维度为3。 网络模型采用最基础的softmax网络 def net(_input, _w, _b): output = torch.mm(_input, _w) + _b exp = torch.exp(output) exp_sum = torch.sum(exp, dim=1, keepdim=True) output = exp / exp_sum return output w = torch.normal(0, .01, [input_dim, output_dim], requires_grad=True, dtype=torch.float64) b = torch.normal(0, .01, [1, output_dim], requires_grad=True, dtype=torch.float64) with torch.no_grad(): random_input = torch.normal(0, .01, [10, 4], dtype=torch.float64) output = net(random_input, w, b) print(output.shape) 定义损失函数 def cross_entropy(y_pred, y): pred_value = torch.gather(y_pred, 1, y.view(-1, 1)) _loss = -torch.log(pred_value) return _loss.sum()一个交叉熵损失函数,用于度量模型输出与真实标签之间的差异。 定义优化器 def optimizer(params, _lr, _batch_size): with torch.no_grad(): for param in params: param -= _lr * param.grad / _batch_size param.grad.zero_()定义一个梯度下降优化器,用于更新模型的参数。 训练评估 epoch_num = 5 lr = 0.05 batch_size = 5 for epoch in range(epoch_num): train(_net=net, _params=[w, b], _loss=cross_entropy, _opt=optimizer, _lr=lr, _batch_size=batch_size, _epoch=epoch, _data_iter=data_iter(train_data, train_label, batch_size)) acc = evaluation(_net=net, _params=[w, b], _data_iter=data_iter(valid_data, valid_label, batch_size)) print('epoch %d,valid acc %.3f' % (epoch + 1, acc))结果图: 鸢尾花数据集下载免费 |
【本文地址】