神经网络ANN算法 |
您所在的位置:网站首页 › 鸢尾花分类python算法可视化 › 神经网络ANN算法 |
神经网络ANN算法
|
个人对神经网络的理解
神经网络算法,是一个黑匣子,当你传入一些数据,并告诉它最终要达到的目标,整个神经网络就开始学习。但是,我们很难知道里面究竟发生了什么,也没有数学来严格推导和证明 黑匣子这玩意不可控啊! 人脑人在刚出生的时候有 2000 亿的脑细胞,且细胞不会再生,当然你也不用担心会用完,100岁衰减都还有27亿。神经元包含了轴突和树突,树突负责接收信号、轴突负责发送信号。人的大脑是很好记忆、逻辑、运算、推理的设备。 假设有一个最简单的神经系统 构成:一层输入单元和一层输出单元,我们根据已知数据去预测y值,且y值符合以下方程。 我们加入隐藏层后,我们的模型就可以处理非线性模型。 难度很大!!! 因为网络结构可以无限拓展,要知道什么样的结构才符合我们的问题需要做大量的试验 第二步:初始化模型权重模型中的每一个连接都会有一个权重,在初始化的时候可以都随机给予一个值。 第三步:就是根据输入数据和权重来预测结果引入误差来衡量predict与true数据的偏差。 最开始的参数都是随机设置的,所以获得的结果肯定与真实的结果差距比较大,所以在这里要计算一个误差,误差反映了预测结果和真实结果的差距有多大。 第四步:模型要调节权重我们要设置学习率,这个学习率是针对误差的,每次获得误差后,连接上的权重都会按照误差的这个比率来进行调整,从而期望在下次计算时获得一个较小的误差。 经过若干次循环这个过程,我们可以选择达到一个比较低的损失值的时候停止并输出模型,也可以选择一个确定的循环轮次来结束。 注:关于激活函数激活函数相当于神经元的激活需要电信号累加到一定的水平,这个神经元才会被激活。 我们在神经网络中,在上层节点的输出和下层节点的输入中间加入一个激活函数,来实现。 那没有激活函数会怎么样? 如果没有激活函数,那不管有多少层网络,神经元之间也仍然是线性关系,就像没有隐藏层的时候一样,加入了非线性函数作为激活函数,这样深层次的网络就可以去拟合任意类型的函数了。常见的激活函数有 ReLU、tanh、Sigmoid 等,在不同的场景下可能需要不同的激活函数。 算法优缺点 优点它可以像搭积木一样不断的扩展到模型的边界 而对于内部具体的运行不需要加以太多的干涉。通过不同的搭建手段,神经网络几乎可以去模拟任何算法的结果,只要数据量够多,构建的模型够完善,最终都会有一个很好的结果。 缺点前文说过,它是一个黑匣子,可解释性不高 你告诉它数据,然后它告诉你结果,至于为什么会这样,它不做任何解释。所以在很多对解释性要求比较高的场景,比如信用评级、金融风控等情况下没办法使用 其次,非常消耗资源,包括数据、网络节点、硬件设备、时间、人力物力财力等等。 实践案例这里使用鸢尾花案例 from sklearn import datasets # 加载数据集 import numpy as np # 数据处理工具 from sklearn.neural_network import MLPClassifier # 导入神经网络 np.random.seed(0) # 保证每次数据唯一性 iris=datasets.load_iris() iris_x=iris.data # 属性 iris_y=iris.target # 标签 indices = np.random.permutation(len(iris_x)) # 随机产生一个序列,或是返回一个排列范围,为拆分数据做准备 iris_x_train = iris_x[indices[:-10]] iris_y_train = iris_y[indices[:-10]] iris_x_test = iris_x[indices[-10:]] iris_y_test = iris_y[indices[-10:]]需要注意的是我们设置的参数,其中有一个比较重要的是 hidden_layer_sizes,它用来设置隐藏层大小,长度就是隐藏层的数量。在第一次,我们设置的是 [5,2] 这个数组,这样我们的网络有两层隐藏层,第一层有 5 个神经元,第二层有 2 个神经元。 #slover 是权重优化策略; activation 表示选择的激活函数,这里没有设置,默认是 relu;alpha 是惩罚参数;hidden_layer_sizes 是隐藏层大小,长度就是隐藏层的数量,每一个大小就是设置每层隐藏层的神经元数量;random_state 是初始化所使用的随机项; clf = MLPClassifier(solver='lbfgs', alpha=1e-5, hidden_layer_sizes=(5, 2), random_state=1) clf.fit(iris_x_train,iris_y_train) #拟合 iris_y_predict = clf.predict(iris_x_test) score=clf.score(iris_x_test,iris_y_test,sample_weight=None) print('iris_y_predict = ') print(iris_y_predict) print('iris_y_test = ') print(iris_y_test) print('Accuracy:',score) print('layers nums :',clf.n_layers_)参数说明 1. hidden_layer_sizes :例如hidden_layer_sizes=(50, 50),表示有两层隐藏层,第一层隐藏层有50个神经元,第二层也有50个神经元。 2. activation :激活函数,{‘identity’, ‘logistic’, ‘tanh’, ‘relu’}, 默认relu - identity:f(x) = x - logistic:其实就是sigmod,f(x) = 1 / (1 + exp(-x)). - tanh:f(x) = tanh(x). - relu:f(x) = max(0, x) 3. solver: {‘lbfgs’, ‘sgd’, ‘adam’}, 默认adam,用来优化权重 - lbfgs:quasi-Newton方法的优化器 - sgd:随机梯度下降 - adam: Kingma, Diederik, and Jimmy Ba提出的机遇随机梯度的优化器 注意:默认solver ‘adam’在相对较大的数据集上效果比较好(几千个样本或者更多),对小数据集来说,lbfgs收敛更快效果也更好。 4. alpha :float,可选的,默认0.0001,正则化项参数 5. batch_size : int , 可选的,默认’auto’,随机优化的minibatches的大小batch_size=min(200,n_samples),如果solver是’lbfgs’,分类器将不使用minibatch 6. learning_rate :学习率,用于权重更新,只有当solver为’sgd’时使用,{‘constant’,’invscaling’, ‘adaptive’},默认constant - ‘constant’: 有’learning_rate_init’给定的恒定学习率 - ‘incscaling’:随着时间t使用’power_t’的逆标度指数不断降低学习率learning_rate_ ,effective_learning_rate = learning_rate_init / pow(t, power_t) - ‘adaptive’:只要训练损耗在下降,就保持学习率为’learning_rate_init’不变,当连续两次不能降低训练损耗或验证分数停止升高至少tol时,将当前学习率除以5. 7. power_t: double, 可选, default 0.5,只有solver=’sgd’时使用,是逆扩展学习率的指数.当learning_rate=’invscaling’,用来更新有效学习率。 8. max_iter: int,可选,默认200,最大迭代次数。 9. random_state:int 或RandomState,可选,默认None,随机数生成器的状态或种子。 10. shuffle: bool,可选,默认True,只有当solver=’sgd’或者‘adam’时使用,判断是否在每次迭代时对样本进行清洗。 11. tol:float, 可选,默认1e-4,优化的容忍度 12. learning_rate_int:double,可选,默认0.001,初始学习率,控制更新权重的补偿,只有当solver=’sgd’ 或’adam’时使用。 14. verbose : bool, 可选, 默认False,是否将过程打印到stdout 15. warm_start : bool, 可选, 默认False,当设置成True,使用之前的解决方法作为初始拟合,否则释放之前的解决方法。 16. momentum : float, 默认 0.9,动量梯度下降更新,设置的范围应该0.0-1.0. 只有solver=’sgd’时使用. 17. nesterovs_momentum : boolean, 默认True, Whether to use Nesterov’s momentum. 只有solver=’sgd’并且momentum > 0使用. 18. early_stopping : bool, 默认False,只有solver=’sgd’或者’adam’时有效,判断当验证效果不再改善的时候是否终止训练,当为True时,自动选出10%的训练数据用于验证并在两步连续迭代改善,低于tol时终止训练。 19. validation_fraction : float, 可选, 默认 0.1,用作早期停止验证的预留训练数据集的比例,早0-1之间,只当early_stopping=True有用 20. beta_1 : float, 可选, 默认0.9,只有solver=’adam’时使用,估计一阶矩向量的指数衰减速率,[0,1)之间 21. beta_2 : float, 可选, 默认0.999,只有solver=’adam’时使用估计二阶矩向量的指数衰减速率[0,1)之间 22. epsilon : float, 可选, 默认1e-8,只有solver=’adam’时使用数值稳定值。 模型结果 iris_y_predict = [0 0 0 0 0 0 0 0 0 0] iris_y_test = [1 1 1 0 0 0 2 1 2 0] Accuracy: 0.4 layers nums : 4再看结果,这里需要注意一下,在第一次输出的时候,可以看到准确率只有40%,是不是让人大跌眼镜? 咋办呢???在第二次输出的时候,对于代码其他部分没有做任何调整,只是对 hidden_layer_sizes 进行了修改,改成了三个隐藏层,每个隐藏层有 10 个神经元,这个时候神奇的事情发生了,我们的准确率已经提升到了 90%。 合理的当一个调包侠和调参侠!!!来吧展示 # 将 hidden_layer_sizes=(10,10,10) iris_y_predict = [1 2 1 0 0 0 2 1 2 0] iris_y_test = [1 1 1 0 0 0 2 1 2 0] Accuracy: 0.9 layers nums : 5百度实验室【传送门】 |
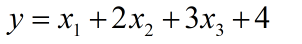 4个输入神经元,1个输入神经元,如图所示它的结构 这个模型的目的就是去寻找从输入单元到输出单元这条线上的权重,来根据数据拟合结果,这就是一个最简单的人工神经网络模型 ANN(Artificial Neural Network)。
4个输入神经元,1个输入神经元,如图所示它的结构 这个模型的目的就是去寻找从输入单元到输出单元这条线上的权重,来根据数据拟合结果,这就是一个最简单的人工神经网络模型 ANN(Artificial Neural Network)。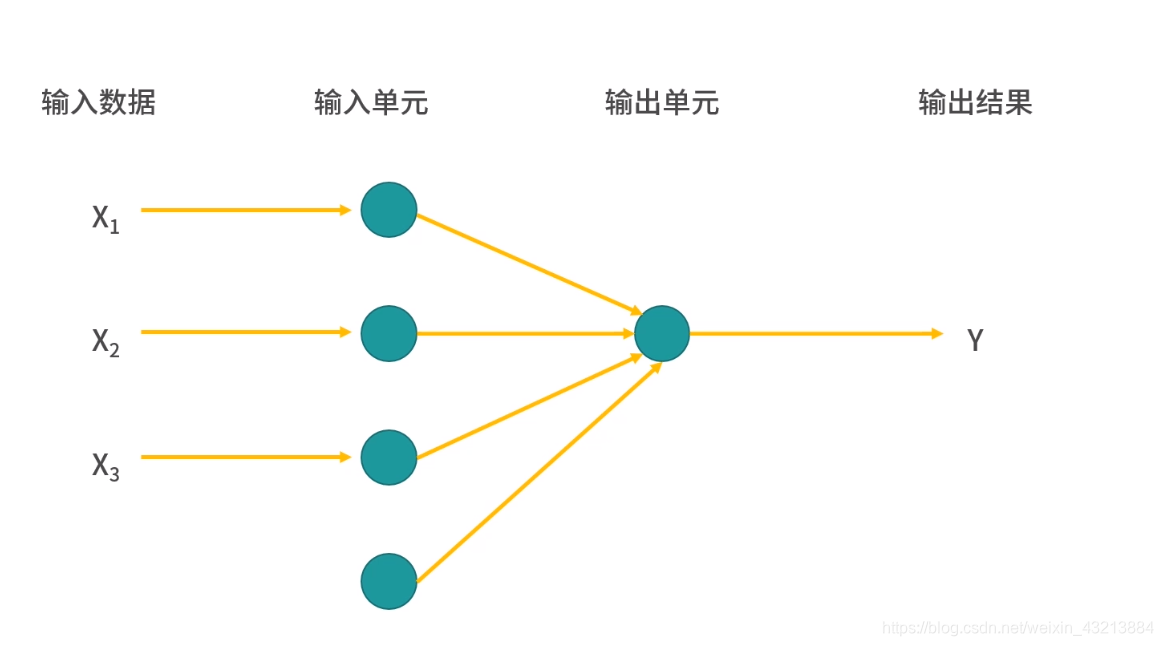
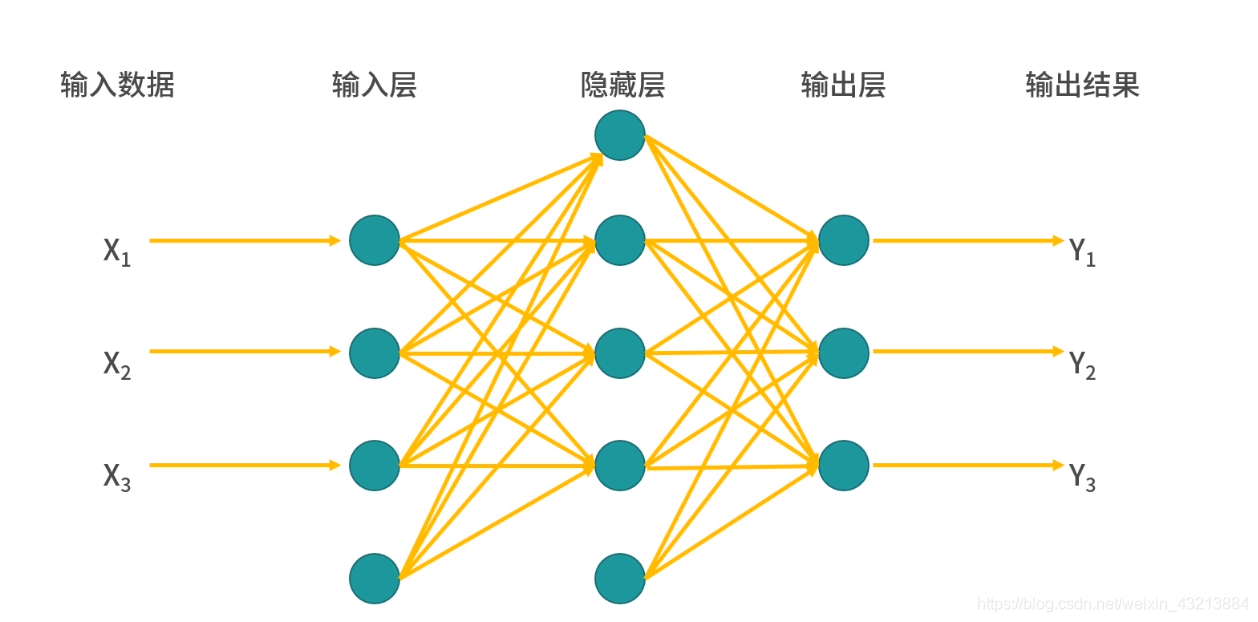
【本文地址】
今日新闻 |
推荐新闻 |