【python爬虫课程设计】掌上高考 |
您所在的位置:网站首页 › 高考数据库怎么购买 › 【python爬虫课程设计】掌上高考 |
【python爬虫课程设计】掌上高考
|
一、选题的背景 选择此选题是因为掌上高考是一个提供本科院校信息的网站,通过爬取该网站的数据,可以获取到各个本科院校的相关信息,如学校名称、所在地、专业设置等。通过对这些数据进行分析和可视化,可以帮助学生更好地了解各个本科院校的情况,为他们的升学选择提供参考。预期目标是通过数据分析,找出各个本科院校的特点和优势,以及不同地区、不同专业的分布情况,为学生提供更全面、准确的信息。从社会方面来看,这有助于提高学生的就业竞争力;从经济方面来看,这有助于促进教育产业的发展;从技术方面来看,这需要运用爬虫技术和数据分析技术;数据来源主要是掌上高考网站。 二、主题式网络爬虫设计方案 1. 主题式网络爬虫名称:掌上高考高校数据爬取与可视化爬虫 2. 主题式网络爬虫爬取的内容与数据特征分析: - 爬取内容:掌上高考网站上的高校数据,包括高校名称、所在地、类型(综合类、理工类等)、排名、学科门类等信息。 - 数据特征分析:高校数据具有结构化特点,可以通过HTML标签和属性进行定位和提取。同时,由于高校数据的多样性,需要对不同类型的高校进行分类处理 3. 主题式网络爬虫设计方案概述: - 实现思路: (1). 确定目标网站:掌上高考网站。 (2). 分析网页结构:使用浏览器开发者工具查看网页源代码,分析大学数据的HTML标签和属性。 (3). 编写爬虫代码:根据分析结果,使用Python的第三方库编写爬虫代码,实现对高校数据的爬取。 (4). 数据清洗与存储:对爬取到的数据进行清洗和格式化处理,将数据存储到合适的数据结构中,如列表、字典等。 (5). 数据可视化:使用Python的可视化库对高校数据进行可视化展示,如绘制柱状图、折线图等。 - 技术难点: (1). 动态加载:部分网页数据是通过JavaScript动态加载的,需要使用Selenium等工具模拟浏览器操作,获取动态加载的数据。 (2). 反爬机制:目标网站可能采用反爬机制,如设置User-Agent、限制访问频率等,需要使用代理IP、设置请求头等方式绕过反爬策略。 (3). 数据清洗:爬取到的数据可能存在缺失值、异常值等问题,需要进行数据清洗和预处理,确保数据的准确性和完整性。 三、主题页面的结构特征分析 1.主题页面的结构与特征分析:
(1).主题页面包含多个大学的信息、 (2).每个大学的信息包括学校名称、所在地、类型、排名等。 (3).页面中可能存在分页功能,需要翻页获取更多高校信息。 2. Htmls 页面解析
上方导航栏,其内容是学校、专业等内容分类地区选择栏内容区页面部分,用来选择页面 3.节点(标签) 查找方法与遍历方法 - 查找方法:通过调用get_size()函数获取数据总数,然后调用get_university_info()函数进行分页爬取 - 遍历方法:是在get_university_info()函数中,使用for`循环遍历每一页的数据 四、网络爬虫程序设计 Part1: 爬取查学校里面院校库的网页数据并保存为“全国大学数据.csv”文件
Part2: 用访问量排序来查询保存下来的“全国大学数据.csv”文件 1 # 导入所需模块 2 import pandas as pd 3 import plotly as py 4 import numpy as np 5 # 读取数据 6 university = pd.read_csv('data/全国大学数据.csv',encoding='gbk') 7 8 # 对数据进行处理 9 university = university.loc[:,['name','nature_name','province_name','belong', 10 'city_name', 'dual_class_name','f211','f985','level_name' , 11 'type_name','view_month_number','view_total_number', 12 'view_week_number','rank']] 13 c_name = ['大学名称','办学性质','省份','隶属','城市','高校层次', 14 '211院校','985院校','级别','类型','月访问量','总访问量','周访问量','排名'] 15 university.columns = c_name 16 17 # 访问量排序 18 university.sort_values(by='总访问量',ascending=False).head()
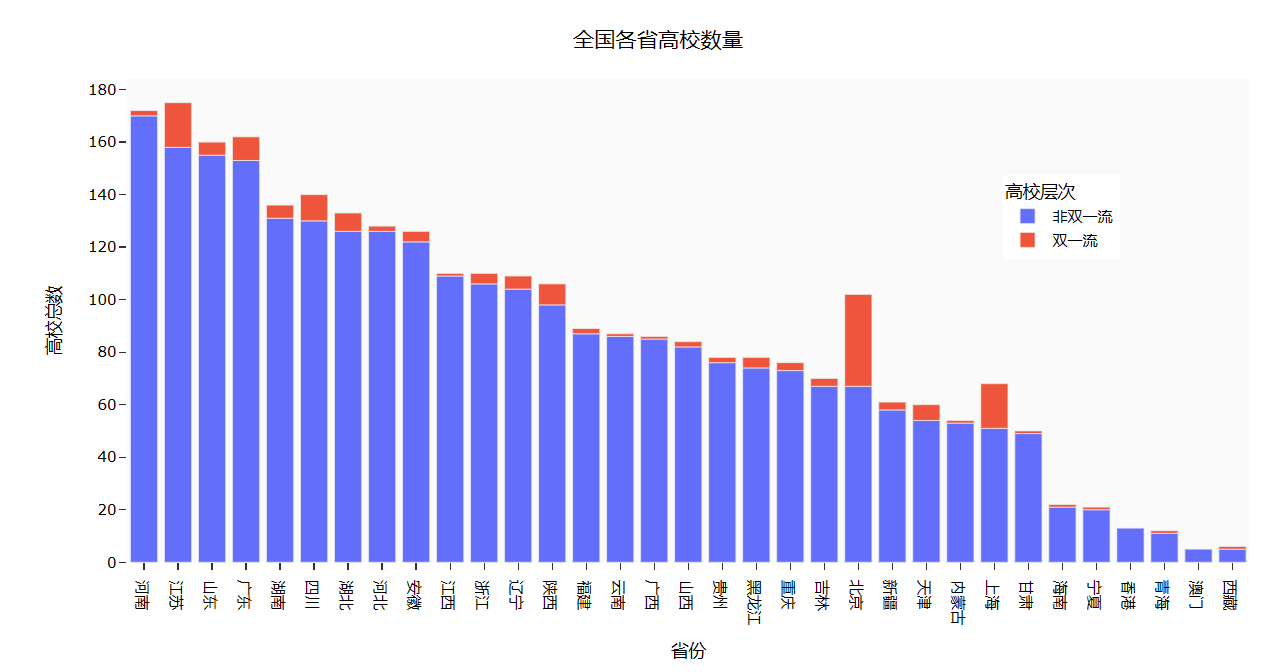
Part3: 用条形图显示全国各省的 “双一流” 和 “非双一流” 高校数量 1 university['高校总数'] = 1 2 university.fillna({'高校层次': '非双一流'},inplace=True) 3 university_by_province = university.pivot_table(index=['省份','高校层次'], 4 values='高校总数',aggfunc='count') 5 university_by_province.reset_index(inplace=True) 6 university_by_province.sort_values(by=['高校总数'],ascending=False,inplace=True) 7 8 #查询全国各省高校数量 9 import plotly.express as px 10 fig = px.bar(university_by_province, 11 x="省份", 12 y="高校总数", 13 color="高校层次") 14 fig.update_layout( 15 title='全国各省高校数量', 16 xaxis_title="省份", 17 yaxis_title="高校总数", 18 template='ggplot2', 19 font=dict( 20 size=12, 21 color="Black", 22 ), 23 margin=dict(l=40, r=20, t=50, b=40), 24 xaxis=dict(showgrid=False), 25 yaxis=dict(showgrid=False), 26 plot_bgcolor="#fafafa", 27 legend=dict(yanchor="top", 28 y=0.8, 29 xanchor="left", 30 x=0.78) 31 ) 32 fig.show()
Part4: 根据 “全国省市区行政区划.xlsx” 文件结合 “全国大学数据.csv” 中的经纬度生成全国高校地理分布图 1 df = pd.read_excel('./data/全国省市区行政区划.xlsx',header=1) 2 # 筛选出层级为2的数据,并选择'全称'、'经度'和'纬度'列 3 df_l = df.query("层级==2").loc[:,['全称','经度','纬度']] 4 df_l = df_l.reset_index(drop=True).rename(columns={'全称':'城市'}) 5 df7 = university.pivot_table('大学名称','城市',aggfunc='count') 6 df7 = df7.merge(df_l,on='城市',how='left') 7 # 按照大学数量降序排序 8 df7.sort_values(by='大学名称',ascending=False) 9 10 import plotly.graph_objects as go 11 import pandas as p 12 df7['text'] = df7['城市'] + '大学总数 ' + (df7['大学名称']).astype(str)+'个' 13 14 # 定义文本、颜色和范围 15 limits = [(0,10),(11,20),(21,50),(51,100),(101,200)] 16 colors = ["royalblue","crimson","lightseagreen","orange","red"] 17 cities = [] 18 scale =.08 19 20 # 创建地理分布图对象 21 fig = go.Figure() 22 23 # 遍历范围,筛选出对应的城市数据,并添加到地理分布图中 24 for i in range(len(limits)): 25 lim = limits[i] 26 df_sub = df7[df7.大学名称.map(lambda x: lim[0] |





【本文地址】
今日新闻 |
推荐新闻 |