【Python从入门到进阶】43.验证码识别工具结合requests的使用 |
您所在的位置:网站首页 › 验证码里面有字符的怎么输入 › 【Python从入门到进阶】43.验证码识别工具结合requests的使用 |
【Python从入门到进阶】43.验证码识别工具结合requests的使用
|
接上篇《42、使用requests的Cookie登录古诗文网站》 上一篇我们介绍了如何利用requests的Cookie登录古诗文网。本篇我们来学习如何使用验证码识别工具进行登录验证的自动识别。 一、图片验证码识别过程及手段上一篇我们通过requests的session方法,带着原网页登录后的Cookie进入个人中心,访问到了登录后的界面数据。但是,我们在登录的过程中,对于验证码的识别,是先下载相关图片然后人工输入进行校验的,有没有能够通过程序自动识别验证码的手段呢?答案是肯定有。 1、验证码识别过程图片验证码是目前最常用的一种,想要对验证码进行精准识别,至少要经过三个过程,分别为图片清理、字符切分、字符识别。 (1)图片清理图片清理是为接下来的机器学习或模板匹配阶段做准备的,指通过灰度化、二值化、干扰点清理等过程,得到比较干净的图片数据,如以下样例: 该阶段对前期预处理后的图片进行切割处理,定位和分离出整幅图片中的每个孤立的字符主体部分。主要采用X轴和Y轴投影的方法,即统计对应坐标上黑色像素点的个数。例如下面的字符图片: 通过处理、切分后的图片,已经可以清晰的辨别要识别的字符,此时我们需要使用OCR识别等手段,进行字符的识别。具体详见第2节的介绍。 2、验证码识别手段常见的图片验证码有以下几种识别手段: (1)OCR识别
需要建立字符模板库,进行字符匹配。该方法需要针对目标网站收集大量的验证码;然后根据上一章节的方法,进行图片清理;最后按照固定的长宽值切分出字符模板图,保存文件名带上对应字符的标记,例如: 以上验证码识别都依赖于字符切分,切分的好坏几乎直接决定识别的准确程度。而对于有字符粘连的图片,往往识别率就会低很多。目前验证码识别最先进的是谷歌在识别“街景”图像中门牌号码中使用的一套的算法。该算法将定位、分割和识别等几个步骤统一起来,采用一种“深度卷积神经网络”(deep convolutional neural network)方法进行识别,准确率可以达到99%以上。 目前市面上已经有很多商用的验证码识别软件和工具,为了提高我们的编程效率,我们没有必要亲自去实现验证码的整个识别过程,直接调用相关的程序包即可。 本篇我们介绍的验证码识别工具为“超级鹰”的验证码识别平台(官网http://www.chaojiying.com/): 这里我们按照这段代码进行图片识别即可。里面需要我们输入超级鹰的账号和密码,以及一个软件ID。软件ID的获取方式如下: 首先我们回到超级鹰的用户中心,拉倒最下面,点击左下角的“软件ID”菜单,然后点击生成一个软件ID: 我们把上一章节的古诗文代码,编写一个V2.0版本,将其中的验证码手工输入的部分,修改为使用超级鹰识别代码进行识别的方法: # _*_ coding : utf-8 _*_ # @Time : 2023-11-19 15:59 # @Author : 光仔December # @File : requests_cookie登录古诗文网 # @Project : Python基础 import requests import chaojiying # 古诗文网登录页面的URL地址 url = 'https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36' } # 获取网络源代码 response = requests.get(url=url, headers=headers) content = response.text # 使用BeautifulSoup来解析网页源码,获取__VIEWSTATE和__VIEWSTATEGENERATOR参数 from bs4 import BeautifulSoup soup = BeautifulSoup(content, 'lxml') # 获取__VIEWSTATE VIEWSTATE = soup.select('#__VIEWSTATE')[0].attrs.get('value') print('VIEWSTATE: ', VIEWSTATE) # 获取__VIEWSTATEGENERATOR VIEWSTATEGENERATOR = soup.select('#__VIEWSTATEGENERATOR')[0].attrs.get('value') print('VIEWSTATEGENERATOR: ', VIEWSTATEGENERATOR) # 获取验证码图片 code = soup.select('#imgCode')[0].attrs.get('src') code_url = 'https://so.gushiwen.cn' + code # import urllib.request # urllib.request.urlretrieve(url=code_url,filename='code.jpg') session = requests.session() # 验证码url的内容 response_code = session.get(code_url) # 图片下载要使用二进制数据 content_code = response_code.content # wb模式就是将二进制数据写入文件 with open('code.jpg', 'wb') as fp: fp.write(content_code) # 获取验证码图片后,使用超级鹰验证码识别工具,进行验证码自动识别 chaojiying = chaojiying.Chaojiying_Client('超级鹰用户名', '超级鹰用户名的密码', '超级鹰软件ID') im = open('code.jpg', 'rb').read() code_name = chaojiying.PostPic(im, 1902).get('pic_str') # 点击登录 url_post = 'https://so.gushiwen.cn/user/login.aspx?from=http%3a%2f%2fso.gushiwen.cn%2fuser%2fcollect.aspx' data_post = { '__VIEWSTATE': VIEWSTATE, '__VIEWSTATEGENERATOR': VIEWSTATEGENERATOR, 'from': 'http://so.gushiwen.cn/user/collect.aspx', 'email': '古诗文网账号', 'pwd': '古诗文网密码', 'code': code_name, 'denglu': '登录' } # 获取网络源代码(这里能用requests对象,要用验证码的session对象,保持一个Cookie环境) response_post = session.post(url=url_post, headers=headers, data=data_post) content_post = response_post.text print(content_post)效果: 参考:尚硅谷Python爬虫教程小白零基础速通杨杰授权网易云社区《常用验证码的识别方法》转载请注明出处:https://guangzai.blog.csdn.net/article/details/134762604 |
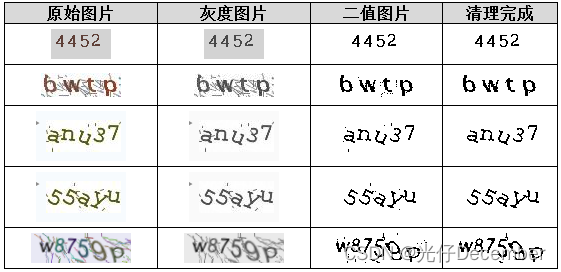 紧接着需要进行“彩色去噪”和“灰度化”、“二值化”、“底色统一”以及“干扰点清理”,这里我用PPT简单总结了一下这几个步骤:
紧接着需要进行“彩色去噪”和“灰度化”、“二值化”、“底色统一”以及“干扰点清理”,这里我用PPT简单总结了一下这几个步骤: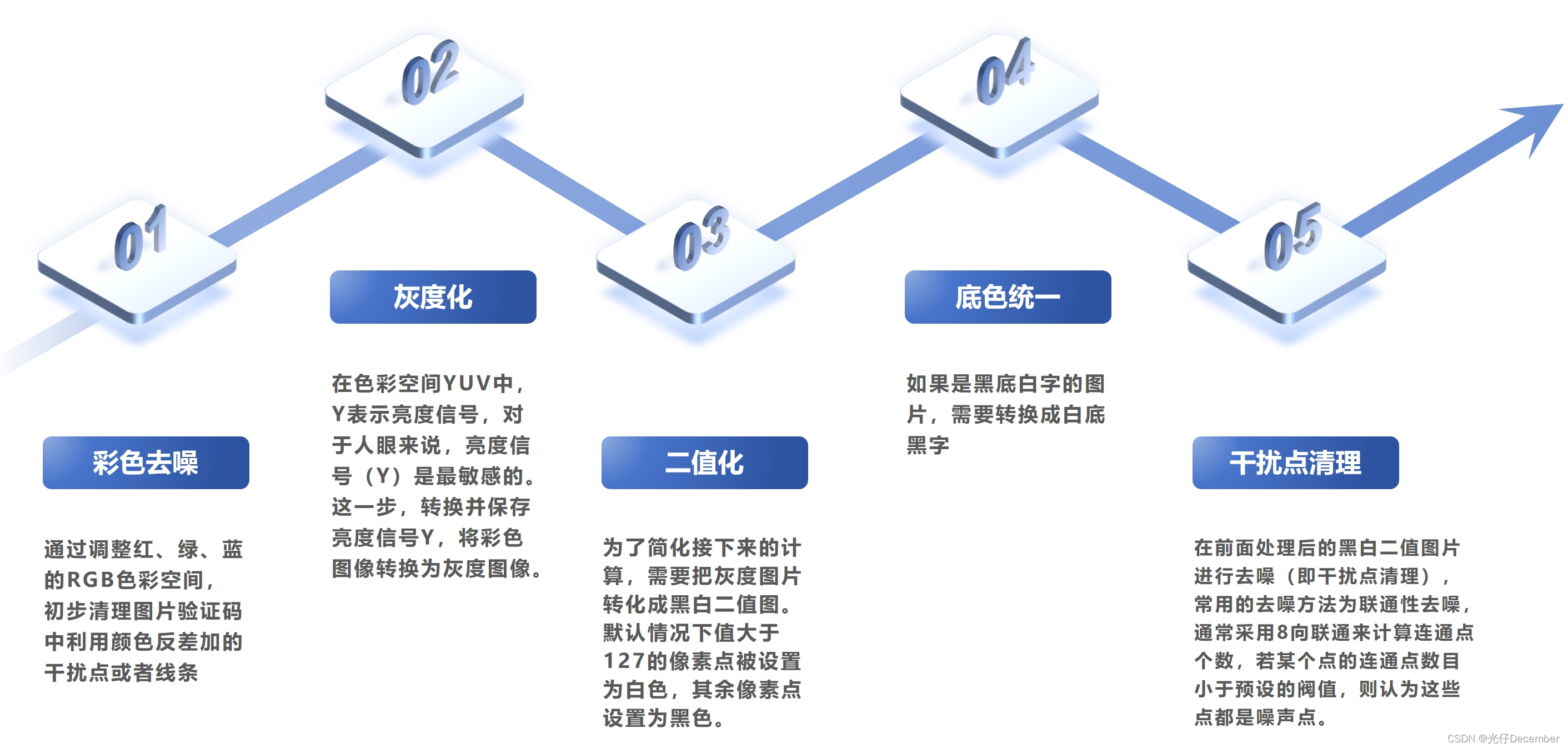
 开源的OCR识别引擎Tesseract(基于C++语言,在Python中被封装为Pytesseract),初期由HP实验室研发,后来贡献给了开源软件业。
开源的OCR识别引擎Tesseract(基于C++语言,在Python中被封装为Pytesseract),初期由HP实验室研发,后来贡献给了开源软件业。 该手段的的优点是:开发量少;比较通用,适合于各种变形较少的验证码;对于扭曲不严重的字母和数字识别率高。 缺点是:对于扭曲的字母和数字识别率大大降低;对于字符间有粘连的验证码几乎难以正确识别;很难针对特定网站的验证码做定制开发。
该手段的的优点是:开发量少;比较通用,适合于各种变形较少的验证码;对于扭曲不严重的字母和数字识别率高。 缺点是:对于扭曲的字母和数字识别率大大降低;对于字符间有粘连的验证码几乎难以正确识别;很难针对特定网站的验证码做定制开发。 然后把目标验证码图片按字符个数切分,使用汉明距离或编辑距离定义相似度,并用KNN方法得到K个最相似的字符,最后从K个字符中选取出现次数最多的那个作为匹配结果。 这种方法主要针对某个特定网站,不具备普适性。
然后把目标验证码图片按字符个数切分,使用汉明距离或编辑距离定义相似度,并用KNN方法得到K个最相似的字符,最后从K个字符中选取出现次数最多的那个作为匹配结果。 这种方法主要针对某个特定网站,不具备普适性。 谷歌拿自有的reCAPTCHA验证码做了测试,结果发现,对于难度最大的reCAPTCHA验证码,新算法的准确率都达到99.8%,这可能也好于大多数人为验证。
谷歌拿自有的reCAPTCHA验证码做了测试,结果发现,对于难度最大的reCAPTCHA验证码,新算法的准确率都达到99.8%,这可能也好于大多数人为验证。 首先我们点击首页右上角的登录按钮,进入登录页面,然后点击注册账号进行账号的开通:
首先我们点击首页右上角的登录按钮,进入登录页面,然后点击注册账号进行账号的开通: 注册完毕后,登录账号,进入个人中心,点击“开发文档”:
注册完毕后,登录账号,进入个人中心,点击“开发文档”: 然后点击“Python语言Demo下载”:
然后点击“Python语言Demo下载”: 下载完毕解压后,可以看到验证码识别的Python样例代码:
下载完毕解压后,可以看到验证码识别的Python样例代码: 代码如下:
代码如下:
 然后输入一个软件名即可,其他不用动,直接点提交:
然后输入一个软件名即可,其他不用动,直接点提交: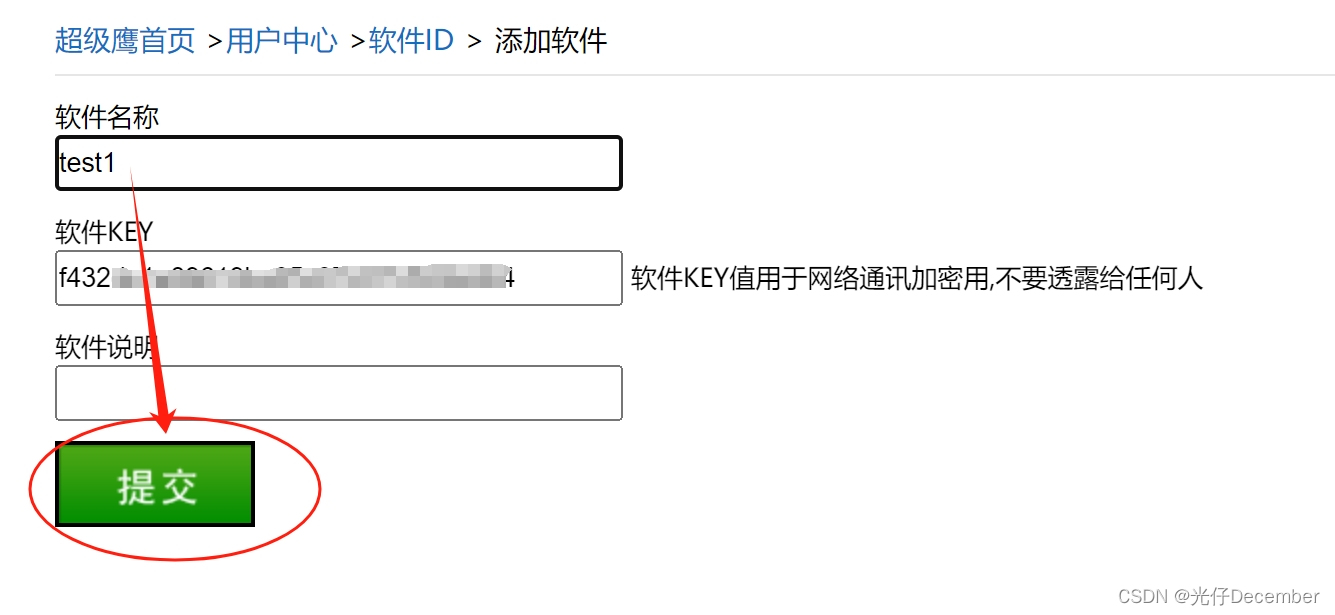 然后我们就可以看到生成的软件ID:
然后我们就可以看到生成的软件ID: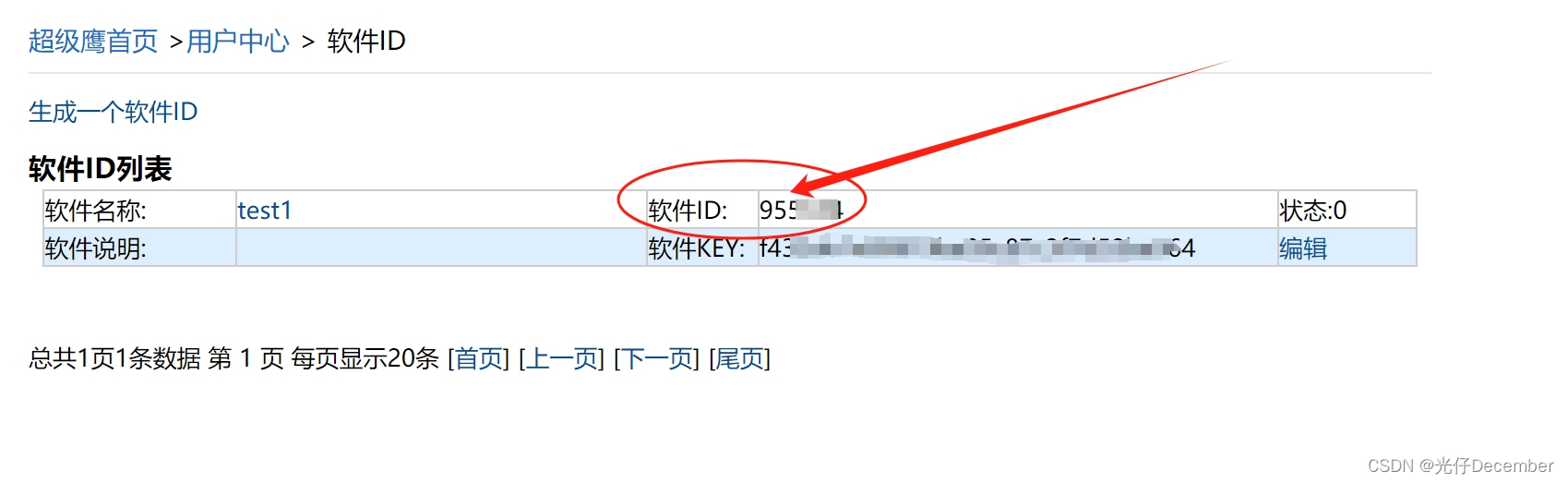 我们在代码的第三个参数里填写这个ID即可。 然后还要注意一点,如果我们使用的是Python的3.4+版 print 后要加(),不然运行会报错:
我们在代码的第三个参数里填写这个ID即可。 然后还要注意一点,如果我们使用的是Python的3.4+版 print 后要加(),不然运行会报错: 我们把代码和图片a.jpg放入我们的Python工作空间,填写好上面的所有参数,执行一下代码,如果咱们第一次用,会发现报错了,显示“无可用题分”:
我们把代码和图片a.jpg放入我们的Python工作空间,填写好上面的所有参数,执行一下代码,如果咱们第一次用,会发现报错了,显示“无可用题分”: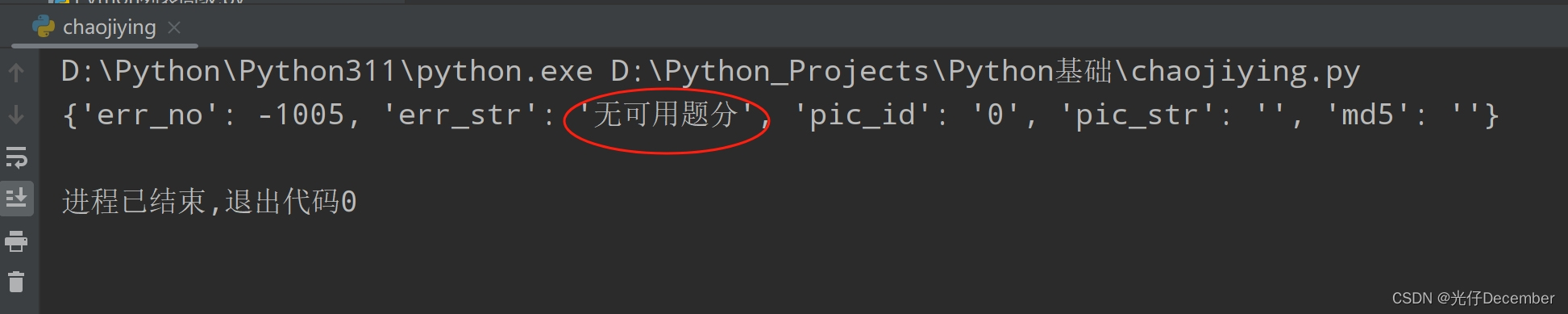 这里是因为需要进行充值,我们去用户中心的下面“购买题分”,充几块钱就行了:
这里是因为需要进行充值,我们去用户中心的下面“购买题分”,充几块钱就行了: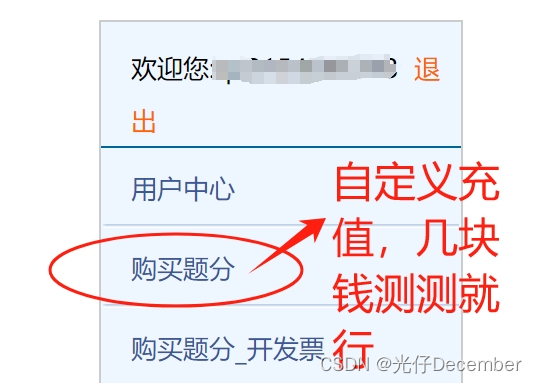 这里是他们官网的收费方式,大家自行决定(我充值了5块钱,有5000题分,基本上可以识别上百次4字验证码了):
这里是他们官网的收费方式,大家自行决定(我充值了5块钱,有5000题分,基本上可以识别上百次4字验证码了):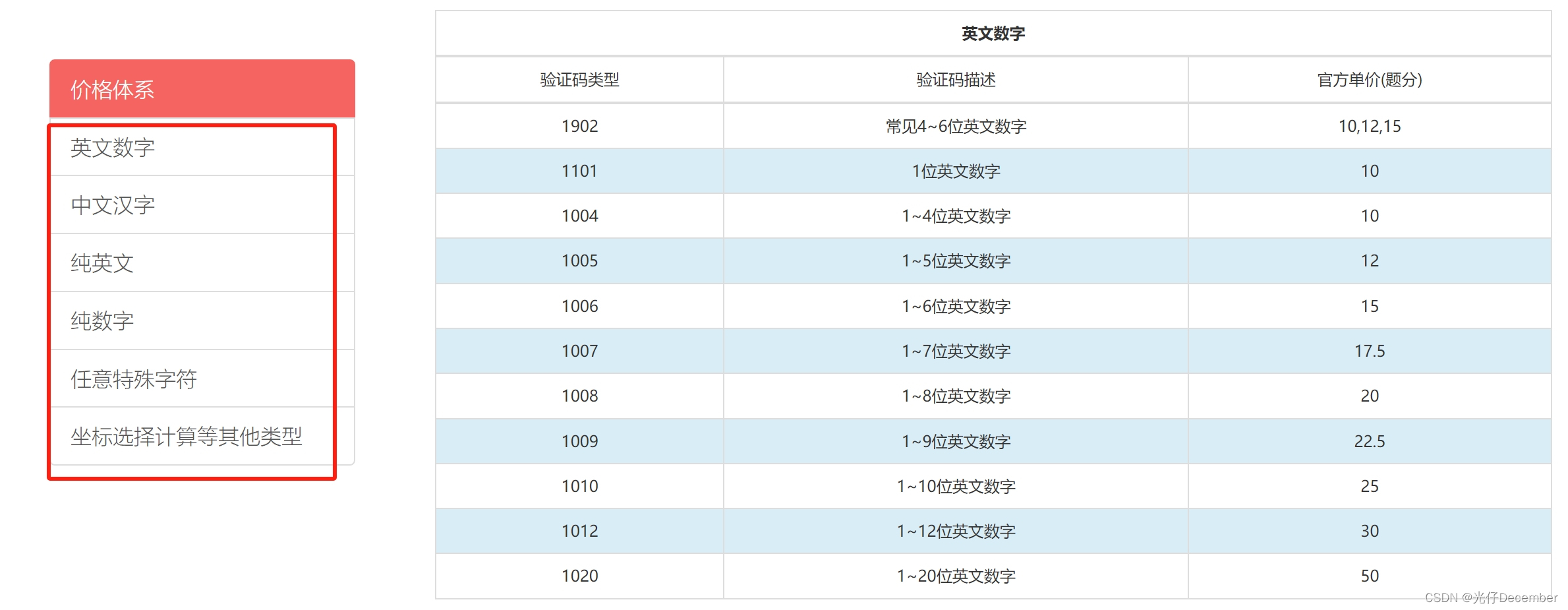 我们充值了几块钱后,再去执行代码,得到结果:
我们充值了几块钱后,再去执行代码,得到结果: 可以看到识别出的a.jpg的内容,这里我拿到的a.jpg确实是“7261”:
可以看到识别出的a.jpg的内容,这里我拿到的a.jpg确实是“7261”: 这个返回对象中的pic_str字段,就是识别结果,可以在调用代码的时候,加上“.get('pic_str')”直接获取结果:
这个返回对象中的pic_str字段,就是识别结果,可以在调用代码的时候,加上“.get('pic_str')”直接获取结果: 可以看到,这次不需要我们进行人工干预,直接就识别到了验证码进行自动登录,获取到古诗文网登录后个人中心的信息。
可以看到,这次不需要我们进行人工干预,直接就识别到了验证码进行自动登录,获取到古诗文网登录后个人中心的信息。【本文地址】
今日新闻 |
推荐新闻 |