用PyTorch实现MNIST手写数字识别(最新,非常详细) |
您所在的位置:网站首页 › 驻波实验结果分析讨论手写 › 用PyTorch实现MNIST手写数字识别(最新,非常详细) |
用PyTorch实现MNIST手写数字识别(最新,非常详细)
|
目录
引言一、数据集(MNIST)1.1 读取MNIST数据集1.2 展示MNIST数据集:
二、构建模型(CNN)2.1 卷积层2.2 激活层2.3 池化层2.4 全连接层2.5 CNN模型
三、损失函数和优化器四、定义训练轮和测试轮4.1 训练轮4.2 测试轮
五、开始训练六、结果和分析七、完整代码
引言
本文基于PyTorch框架,采用CNN卷积神经网络实现MNIST手写数字识别,仅在CPU上运行。 已分别实现使用Linear纯线性层、CNN卷积神经网络、Inception网络、和Residual残差网络四种结构对MNIST数据集进行手写数字识别,并对其识别准确率进行比较分析。(另外三种还未发布) 看完B站大佬视频后,并且刚好深度学习的一个课程实验就是做手写数字识别,就记录下这个博客。 本文是笔者一个字一个字码上的,相信已经是非常详细的了,可供初学者入门使用,欢迎各位大佬提出意见和改进! 导入包: import torch import numpy as np from matplotlib import pyplot as plt from torch.utils.data import DataLoader from torchvision import transforms from torchvision import datasets import torch.nn.functional as F 一、数据集(MNIST)MNIST数据集是机器学习领域中非常经典的一个数据集,由60000个训练样本和10000个测试样本组成,每个样本都是一张28 * 28像素的灰度手写数字图片。 下载: 官方网站:http://yann.lecun.com/exdb/mnist/ 网盘地址:MNIST数据集(提取码: izsq ) 一共4个文件,训练集、训练集标签、测试集、测试集标签 文件名称大小内容train-labels-idx1-ubyte.gz9,681 kb55000张训练集,5000张验证集train-labels-idx1-ubyte.gz29 kb训练集图片对应的标签t10k-images-idx3-ubyte.gz1,611 kb10000张测试集t10k-labels-idx1-ubyte.gz5 kb测试集图片对应的标签 1.1 读取MNIST数据集直接下载下来的数据是无法通过解压或者应用程序打开的,因为这些文件不是任何标准的图像格式而是以字节的形式进行存储的,所以必须编写程序来打开它。 torchvision.datasets包中已经包含MNIST数据集,可以通过在编译器中输入代码进行数据集的获取,步骤如下: Step1:归一化,softmax归一化指数函数(https://blog.csdn.net/lz_peter/article/details/84574716),其中0.1307是mean均值和0.3081是std标准差 transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]) Step2:下载/获取数据集,其中root为数据集存放路径,train=True即训练集否则为测试集。 train_dataset = datasets.MNIST(root='./data/mnist', train=True, download=True, transform=transform) test_dataset = datasets.MNIST(root='./data/mnist', train=False, download=True, transform=transform) # train=True训练集,=False测试集 Step3:实例化一个dataset后,然后用Dataloader 包起来,即载入数据集。这里的batch_size为超参数,详见第五大节;shuffle=True即打乱数据集,这里我们打乱训练集进行训练,而对测试集进行顺序测试。 train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True) test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False) 1.2 展示MNIST数据集:这里举例展示12幅图,包含图片内容和标签。 fig = plt.figure() for i in range(12): plt.subplot(3, 4, i+1) plt.tight_layout() plt.imshow(train_dataset.train_data[i], cmap='gray', interpolation='none') plt.title("Labels: {}".format(train_dataset.train_labels[i])) plt.xticks([]) plt.yticks([]) plt.show()输出结果: 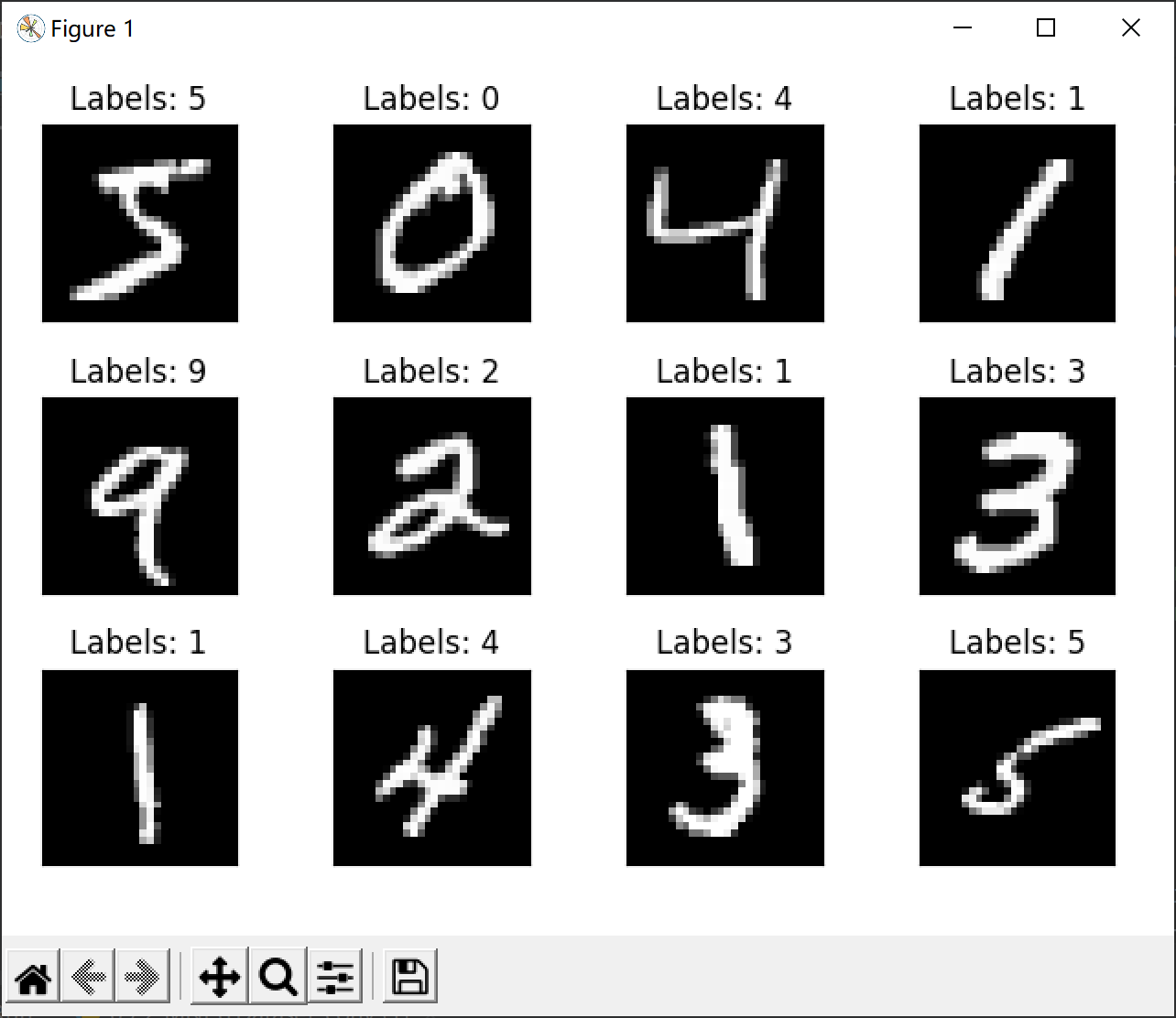 二、构建模型(CNN)
2.1 卷积层
二、构建模型(CNN)
2.1 卷积层
每一个卷积核的通道数量要求和输入通道数量一样,卷积核的总数和输出通道的数量一样。 卷积(convolution)后,C(Channels)变,W(width)和H(Height)可变可不变,取决于填充padding。 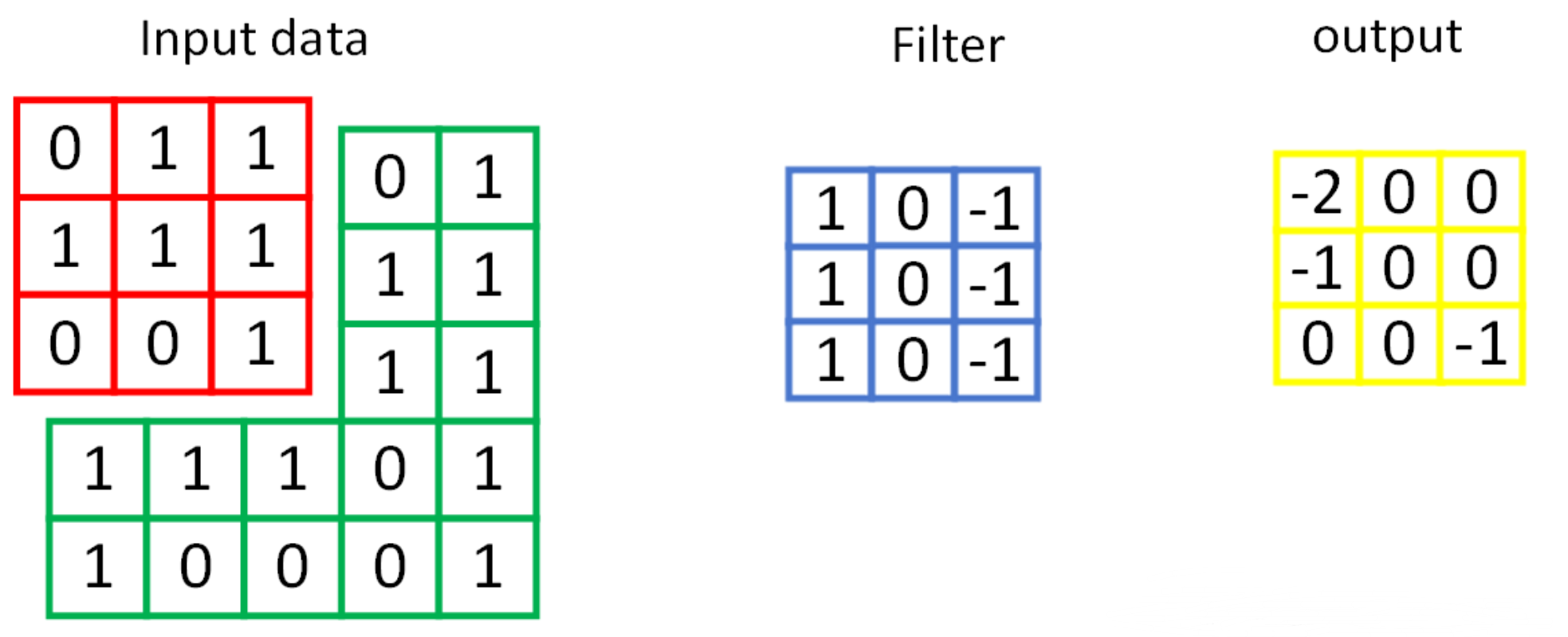
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding) 参数: in_channels:输入通道out_channels:输出通道kernel_size:卷积核大小stride:步长padding:填充 2.2 激活层激活层使用ReLU激活函数。 线性整流函数(Rectified Linear Unit, ReLU),又称修正线性单元,是一种人工神经网络中常用的激活函数(activation function),通常指代以斜坡函数及其变种为代表的非线性函数。 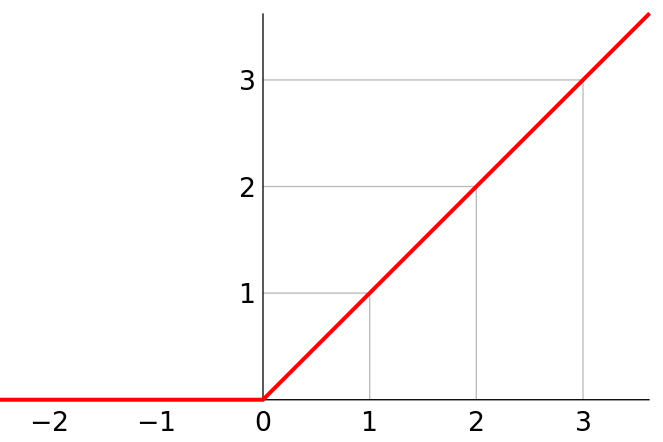
torch.nn.ReLU() 2.3 池化层池化层采用最大池化。 池化(pooling)后,C(C.hannels)不变,W(width)和H(Height)变。 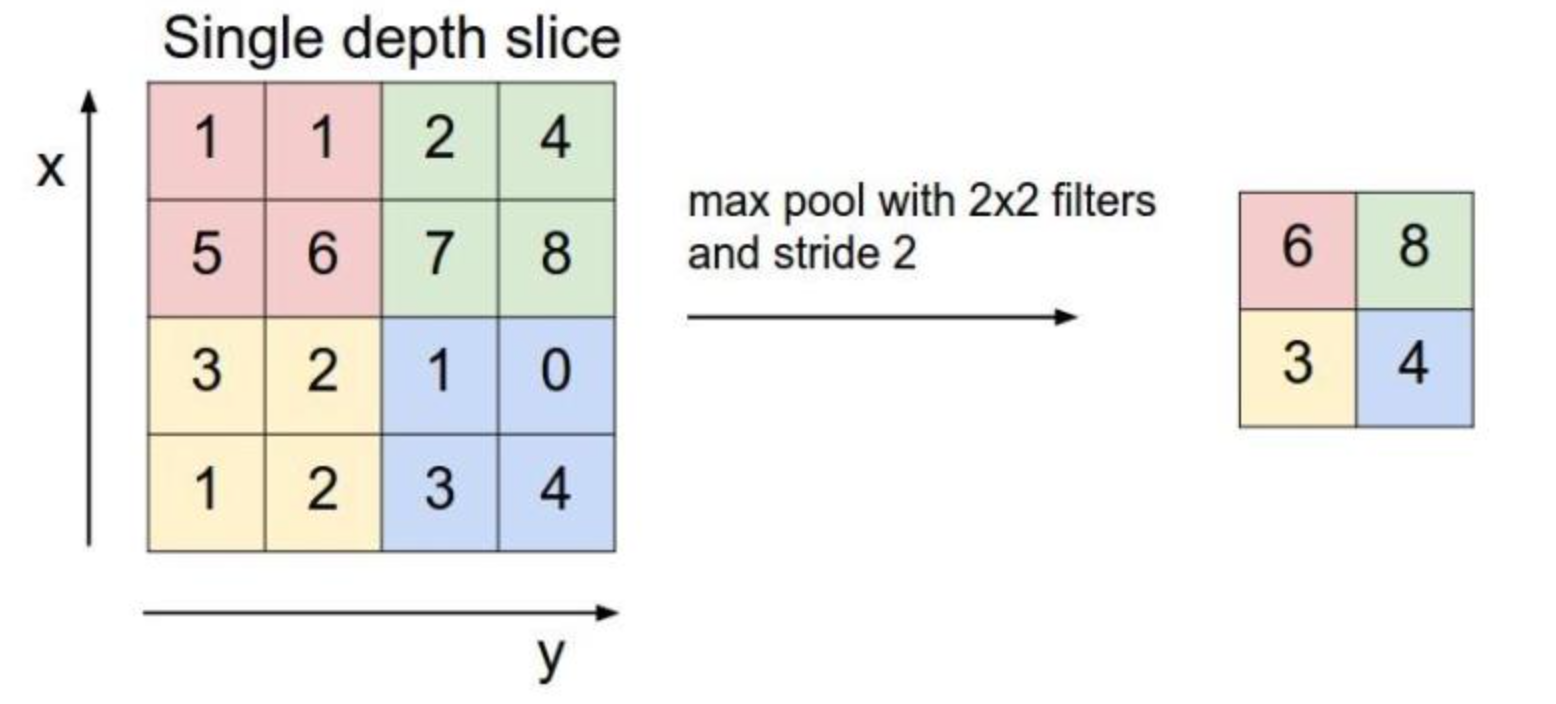
torch.nn.MaxPool2d(input, kernel_size, stride, padding) 参数: input:输入kernel_size:卷积核大小stride:步长padding:填充 2.4 全连接层之前卷积层要求输入输出是四维张量(B,C,W,H),而全连接层的输入与输出都是二维张量(B,Input_feature),经过卷积、激活、池化后,使用view打平,进入全连接层。 2.5 CNN模型模型如图所示: 
比如输入一个手写数字“5”的图像,它的维度为(batch,1,28,28)即单通道高宽分别为28像素。 首先通过一个卷积核为5×5的卷积层,其通道数从1变为10,高宽分别为24像素;然后通过一个卷积核为2×2的最大池化层,通道数不变,高宽变为一半,即维度变成(batch,10,12,12);然后再通过一个卷积核为5×5的卷积层,其通道数从10变为20,高宽分别为8像素;再通过一个卷积核为2×2的最大池化层,通道数不变,高宽变为一半,即维度变成(batch,20,4,4);之后将其view展平,使其维度变为320(2044)之后进入全连接层,用线性函数将其输出为10类,即“0-9”10个数字。代码: class Net(torch.nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = torch.nn.Sequential( torch.nn.Conv2d(1, 10, kernel_size=5), torch.nn.ReLU(), torch.nn.MaxPool2d(kernel_size=2), ) self.conv2 = torch.nn.Sequential( torch.nn.Conv2d(10, 20, kernel_size=5), torch.nn.ReLU(), torch.nn.MaxPool2d(kernel_size=2), ) self.fc = torch.nn.Sequential( torch.nn.Linear(320, 50), torch.nn.Linear(50, 10), ) def forward(self, x): batch_size = x.size(0) x = self.conv1(x) # 一层卷积层,一层池化层,一层激活层(图是先卷积后激活再池化,差别不大) x = self.conv2(x) # 再来一次 x = x.view(batch_size, -1) # flatten 变成全连接网络需要的输入 (batch, 20,4,4) ==> (batch,320), -1 此处自动算出的是320 x = self.fc(x) return x # 最后输出的是维度为10的,也就是(对应数学符号的0~9)实例化模型: model = Net() 三、损失函数和优化器损失函数使用交叉熵损失 参数优化使用随机梯度下降 criterion = torch.nn.CrossEntropyLoss() # 交叉熵损失 optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, momentum=momentum) # lr学习率,momentum冲量 四、定义训练轮和测试轮 4.1 训练轮Step1:前馈(forward propagation) Step2:反馈(backward propagation) Step3:更新(update) 训练轮代码: def train(epoch): running_loss = 0.0 # 这整个epoch的loss清零 running_total = 0 running_correct = 0 for batch_idx, data in enumerate(train_loader, 0): inputs, target = data optimizer.zero_grad() # forward + backward + update outputs = model(inputs) loss = criterion(outputs, target) loss.backward() optimizer.step() # 把运行中的loss累加起来,为了下面300次一除 running_loss += loss.item() # 把运行中的准确率acc算出来 _, predicted = torch.max(outputs.data, dim=1) running_total += inputs.shape[0] running_correct += (predicted == target).sum().item() if batch_idx % 300 == 299: # 不想要每一次都出loss,浪费时间,选择每300次出一个平均损失,和准确率 print('[%d, %5d]: loss: %.3f , acc: %.2f %%' % (epoch + 1, batch_idx + 1, running_loss / 300, 100 * running_correct / running_total)) running_loss = 0.0 # 这小批300的loss清零 running_total = 0 running_correct = 0 # 这小批300的acc清零 4.2 测试轮测试集不用算梯度(无需反馈),首先从test_loader中读取每一次的图片和标签,进行前馈运算后,预测每一轮的准确率 测试轮代码: def test(): correct = 0 total = 0 with torch.no_grad(): # 测试集不用算梯度 for data in test_loader: images, labels = data outputs = model(images) _, predicted = torch.max(outputs.data, dim=1) # dim = 1 列是第0个维度,行是第1个维度,沿着行(第1个维度)去找1.最大值和2.最大值的下标 total += labels.size(0) # 张量之间的比较运算 correct += (predicted == labels).sum().item() acc = correct / total print('[%d / %d]: Accuracy on test set: %.1f %% ' % (epoch+1, EPOCH, 100 * acc)) # 求测试的准确率,正确数/总数 return acc 五、开始训练超参数:用到的超参数主要有小批量数据的batch size,梯度下降算法中用到的学习率(learning rate)和冲量(momentum),同时定义进行10轮次的训练。 # super parameters batch_size = 64 learning_rate = 0.01 momentum = 0.5 EPOCH = 10主函数:共进行10轮次的训练:每训练一轮,就进行一次测试。 if __name__ == '__main__': acc_list_test = [] for epoch in range(EPOCH): train(epoch) # if epoch % 10 == 9: #每训练10轮 测试1次 acc_test = test() acc_list_test.append(acc_test) plt.plot(acc_list_test) plt.xlabel('Epoch') plt.ylabel('Accuracy On TestSet') plt.show() 六、结果和分析下表为训练集和测试集上的损失值和识别准确率的输入结果。 可以看到一共进行10轮次的训练和测试:每一轮的训练中,每300小批量数据输出一次损失值和准确率;每一轮训练结束后进行一次测试,并打印其在测试集上的准确率。 10轮后,在训练集上的平均识别准确率达到98.88%,在测试集上的准确率达到99%,其中测试集上准确率如下图所示。 [1, 300]: loss: 0.820 , acc: 76.82 % [1, 600]: loss: 0.237 , acc: 93.01 % [1, 900]: loss: 0.152 , acc: 95.35 % Accuracy on test set: 96.4 % [2, 300]: loss: 0.126 , acc: 96.27 % [2, 600]: loss: 0.109 , acc: 96.77 % [2, 900]: loss: 0.094 , acc: 97.15 % Accuracy on test set: 97.6 % [3, 300]: loss: 0.084 , acc: 97.55 % [3, 600]: loss: 0.080 , acc: 97.49 % [3, 900]: loss: 0.075 , acc: 97.64 % Accuracy on test set: 97.7 % [4, 300]: loss: 0.072 , acc: 97.85 % [4, 600]: loss: 0.066 , acc: 98.08 % [4, 900]: loss: 0.060 , acc: 98.16 % Accuracy on test set: 98.3 % [5, 300]: loss: 0.058 , acc: 98.21 % [5, 600]: loss: 0.060 , acc: 98.23 % [5, 900]: loss: 0.055 , acc: 98.31 % Accuracy on test set: 98.5 % [6, 300]: loss: 0.047 , acc: 98.57 % [6, 600]: loss: 0.054 , acc: 98.29 % [6, 900]: loss: 0.053 , acc: 98.39 % Accuracy on test set: 98.6 % [7, 300]: loss: 0.048 , acc: 98.61 % [7, 600]: loss: 0.044 , acc: 98.58 % [7, 900]: loss: 0.049 , acc: 98.54 % Accuracy on test set: 98.7 % [8, 300]: loss: 0.045 , acc: 98.77 % [8, 600]: loss: 0.043 , acc: 98.60 % [8, 900]: loss: 0.043 , acc: 98.72 % Accuracy on test set: 98.7 % [9, 300]: loss: 0.040 , acc: 98.78 % [9, 600]: loss: 0.037 , acc: 98.86 % [9, 900]: loss: 0.042 , acc: 98.73 % Accuracy on test set: 98.8 % [10, 300]: loss: 0.038 , acc: 98.84 % [10, 600]: loss: 0.034 , acc: 98.98 % [10, 900]: loss: 0.037 , acc: 98.88 % Accuracy on test set: 99.0 % 参考资料: https://www.bilibili.com/video/BV1Y7411d7Ys?p=10 |

【本文地址】
今日新闻 |
推荐新闻 |