Pytorch循环神经网络LSTM时间序列预测风速 |
您所在的位置:网站首页 › 风速预测模型怎么做 › Pytorch循环神经网络LSTM时间序列预测风速 |
Pytorch循环神经网络LSTM时间序列预测风速
|
#时间序列预测分析就是利用过去一段时间内某事件时间的特征来预测未来一段时间内该事件的特征。这是一类相对比较复杂的预测建模问题,和回归分析模型的预测不同,时间序列模型是依赖于事件发生的先后顺序的,同样大小的值改变顺序后输入模型产生的结果是不同的。 #时间序列模型最常用最强大的的工具就是递归神经网络(recurrent neural network, RNN)。相比与普通神经网络的各计算结果之间相互独立的特点,RNN的每一次隐含层的计算结果都与当前输入以及上一次的隐含层结果相关。通过这种方法,RNN的计算结果便具备了记忆之前几次结果的特点。 #LSTM(Long Short-Term Memory)模型是一种RNN的变型,可以处理rnn模型的局限性 #这里实现pytorch的LSTM来预测未来的风速的模型 #导包(都用得到) import torchfrom torch.autograd import Variableimport torch.nn as nnimport pandas as pd from pandas import DataFrameimport matplotlib.pyplot as pltimport numpy as np
#原始数据
#时间序列问题,时间的那一列是不代入训练或者测试的,所以时间列可以删除。是用前几行的预测下一行的。通俗点[1,2,3,4,5,6,7],可以通过1,2,3预测出4,。然后2,3,4预测出5.训练的时候跟时间列没关系 df1 = pd.read_excel(r'D:\Personal\Desktop\cs3h.xlsx') df1
#一、数据准备 datas = df1.values #归一化处理,这一步必不可少,不然后面训练数据误差会很大,模型没法用 max_value = np.max(datas) min_value = np.min(datas)scalar = max_value - min_valuedatas = list(map(lambda x: x / scalar, datas)) #数据集和目标值赋值,dataset为数据,look_back为以几行数据为特征维度数量 def creat_dataset(dataset,look_back): data_x = [] data_y = [] for i in range(len(dataset)-look_back): data_x.append(dataset[i:i+look_back]) data_y.append(dataset[i+look_back]) return np.asarray(data_x), np.asarray(data_y) #转为ndarray数据 #以2为特征维度,得到数据集 dataX, dataY = creat_dataset(datas,2)
train_size = int(len(dataX)*0.7) x_train = dataX[:train_size] #训练数据y_train = dataY[:train_size] #训练数据目标值 x_train = x_train.reshape(-1, 1, 2) #将训练数据调整成pytorch中lstm算法的输入维度y_train = y_train.reshape(-1, 1, 1) #将目标值调整成pytorch中lstm算法的输出维度 #将ndarray数据转换为张量,因为pytorch用的数据类型是张量 x_train = torch.from_numpy(x_train)y_train = torch.from_numpy(y_train)
二、创建LSTM模型 class RNN(nn.Module): def __init__(self): super(RNN,self).__init__() #面向对象中的继承 self.lstm = nn.LSTM(2,6,2) #输入数据2个特征维度,6个隐藏层维度,2个LSTM串联,第二个LSTM接收第一个的计算结果 self.out = nn.Linear(6,1) #线性拟合,接收数据的维度为6,输出数据的维度为1 def forward(self,x): x1,_ = self.lstm(x) a,b,c = x1.shape out = self.out(x1.view(-1,c)) #因为线性层输入的是个二维数据,所以此处应该将lstm输出的三维数据x1调整成二维数据,最后的特征维度不能变 out1 = out.view(a,b,-1) #因为是循环神经网络,最后的时候要把二维的out调整成三维数据,下一次循环使用 return out1 rnn = RNN() #参数寻优,计算损失函数 optimizer = torch.optim.Adam(rnn.parameters(),lr = 0.02)loss_func = nn.MSELoss()
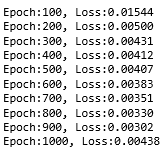
#三、训练模型 for i in range(1000): var_x = Variable(x_train).type(torch.FloatTensor) var_y = Variable(y_train).type(torch.FloatTensor) out = rnn(var_x) loss = loss_func(out,var_y) optimizer.zero_grad() loss.backward() optimizer.step() if (i+1)%100==0: print('Epoch:{}, Loss:{:.5f}'.format(i+1, loss.item())) #损失值
#四、模型测试 #准备测试数据 dataX1 = dataX.reshape(-1,1,2)dataX2 = torch.from_numpy(dataX1)var_dataX = Variable(dataX2).type(torch.FloatTensor)
pred = rnn(var_dataX) pred_test = pred.view(-1).data.numpy() #转换成一维的ndarray数据,这是预测值 dataY为真实值
#五、画图检验 plt.plot(pred.view(-1).data.numpy(), 'r', label='prediction')plt.plot(dataY, 'b', label='real')plt.legend(loc='best')
百分之七十是训练数据的目标值和真实目标值,剩下的为预测的目标值和真实目标值之间关系
|


【本文地址】