(数据结构与算法)哈夫曼编码计算方法(两种实现方法) |
您所在的位置:网站首页 › 颜色编码位数怎么算 › (数据结构与算法)哈夫曼编码计算方法(两种实现方法) |
(数据结构与算法)哈夫曼编码计算方法(两种实现方法)
|
哈夫曼编码
本来是想着慢慢找时间按顺序补上这些数据结构的内容,但前几天有朋友找我写一个计算出哈夫曼编码的程序(课程作业吧,好像~哈哈哈),所以就先把哈夫曼树的东西写下来。
先来介绍一下哈夫曼编码吧 哈夫曼树,二叉树的带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree)。哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近。 哈夫曼编码则是根据字符出现频率(权重分布),用最少的位数来表示。(字符出现多的,用较短编码;字符出现少的,用较长编码)。 举个例子:好比这个字符串“abcddddddd”,如果用相同长度的编码来表示,4个不同数字则选用2位(a->00,b->01,c->10,d->11),那也就是需要 10 * 2 = 20长度; 而使用哈夫曼编码,则根据权重(a->010,b->011,c->00,d->1),也就是需要:3+3+2+1*7 = 15长度。 在这个例子中相比平均编码则少了25%(当然这个例子比较夸张啦哈哈哈。权重分布一般不会这样,在这里主要是想说明哈夫曼编码能起到压缩编码长度的作用) 但是在取哈夫曼编码的时候,要避开前缀(有可能某个数的编码刚好是另外某个数的编码前缀),所以可以通过下面的方法计算出来。 一、基于建哈夫曼树的方法 算法过程: ①将输入的数值,每一个数值,分别都建立成一棵树(只有根节点的树),就形成了森林。 ②将森林排序( 按权重,从大到小排序,选用插入排序即可,因为之后的排序每一次都只插入一个数值,只需要移动少量即可) ③取出后两棵树n1、n2,新创建一个根节点,然后将n1、n2作为其左右孩子,从而构成一棵新树(由新建根节点+n1(lchild)+n2(rchild)组成),将这棵新树插入森林中。 ④重复②③,直到森林中只剩下一棵树,此时该树就是所求哈夫曼树。 ⑤遍历每一个叶子(每一个叶子就是输入数值),根据遍历路径(往lchild则 +‘1’,往rchild 则 + ‘0’),每一个叶子对应的数值+编码result,即是其哈夫曼编码。 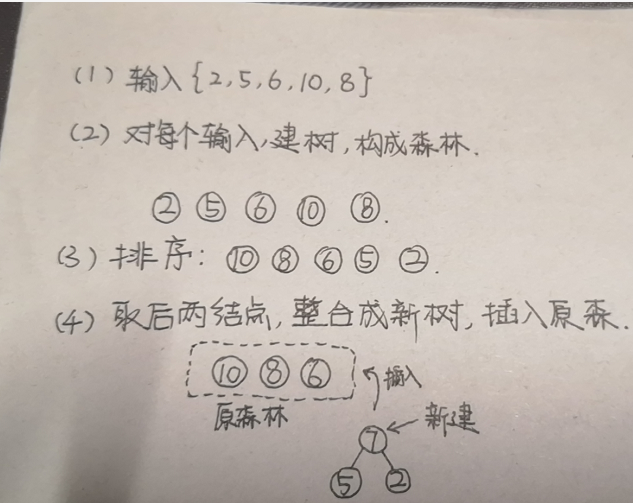
代码实现:C++ #include using namespace std; typedef struct tree_node { int temp; //存数值/对应字符 int weight; //存权重 tree_node* lchild; tree_node* rchild; tree_node(int t = -1, int w = 0) { //非叶子结点,temp都等于-1 temp = t; weight = w; lchild = NULL; rchild = NULL; } }; class huffma { public: huffma() { tree = new tree_node; } void destory_tree(tree_node* ntree) { if (ntree != NULL) { tree_node* lc = ntree->lchild; tree_node* rc = ntree->rchild; delete ntree; if (lc != NULL)destory_tree(lc); if (rc != NULL)destory_tree(rc); } } ~huffma() { destory_tree(tree); } void input(int* data, int len) { //一开始是选用vector,但是朋友说输入是需要数组,所以也就在这里转一下vector 哈哈哈 vectordata_in(data, data + len); make_trees(data_in); //建树 } void output() { //输出 vector a; print_result(tree,a); //输出编码 } private: tree_node* tree; //做根结点 vector trees; //森林 void sort_trees() { //森林排序:插入排序 for (int i = 1; i < trees.size(); i++) { tree_node* change = trees[i]; int j = i - 1; while (change->weight > trees[j]->weight) { trees[j + 1] = trees[j]; j--; if (j == -1)break; } trees[j + 1] = change; } } void built_it() { //建树 int len = trees.size(); sort_trees(); while (len >= 3) { tree_node* n1 = trees.back(); trees.pop_back(); tree_node* n2 = trees.back(); trees.pop_back(); tree_node* new_node = new tree_node(-1, n1->weight + n2->weight);//temp = -1,表示非叶子结点 new_node->lchild = n1; new_node->rchild = n2; trees.push_back(new_node); sort_trees(); len = trees.size(); } //剩下最后两棵,直接作为创建的根节点的左右孩子 tree_node* n1 = trees.back(); trees.pop_back(); tree_node* n2 = trees.back(); trees.pop_back(); tree->lchild = n1; tree->rchild = n2; } void print_result(tree_node* p, vector a) { //递归,找出编码 if (p->temp != -1) { cout temp rchild != NULL)print_result(p->rchild, a); a.pop_back(); } void make_trees(vector data) { //vector存入森林,并built_it() for (int i = 0; i < data.size(); i++) { tree_node* new_tree = new tree_node(data[i], data[i]); trees.push_back(new_tree); } built_it(); } }; int main() { huffma s; int data[8] = { 2,5,6,8,13,19,25,36 }; //输入:元素表示:字符和权重(相同) int len = sizeof(data) / sizeof(data[0]); s.input(data, len); s.output(); return 0; }二、不通过正常建树的方法 算法过程: 分别用两个数组in、out,来存下结点。 用in数组存下输入值,模拟方法一中的森林。 用out数组存下每次从in中取出来的结点。 过程: ①将输入数组存入 数组in ②对 数组in 进行排序(从大到小,这样在后两位、插入时都不需要移太多位) ③取出 数组in 的后两位,分别对其.result 赋值0或1,存到 数组out中,新建一个元素(=两元素的权值合,并记录子元素的位置,也即由两位合成后,记录这两位在 数组out 中的位置),将新建的元素插入 数组in。 ④重复②③,知道 数组in 为空。 ⑤此时由后往前遍历 数组out,对每一位元素进行操作:根据该元素的记录位置,找到 数组out 中对应的元素,添加上该元素的赋值。(按照下图来说明比较容易) |

 /* 好吧,其实两个方法是同样的思路,但是前一种会去体系的建成一棵哈夫曼树后遍历找到哈夫曼编码,而后一种方法则是通过建立各元素之间的关系来找到哈夫曼编码。 当然 ,第一个方法涉及各种指针,其中还没有去delete掉那部分不使用到的内存,造成内存泄漏,所以如果数量级大了可能就内存溢出了,所以还有待修改优化。 至于第二种方法,其实就是运用了方法一的计算方法,但是没有建成一棵哈夫曼树,所以如果在其他有关树的操作时则会很麻烦。所以只是来算出这个哈夫曼编码而已哈哈哈。 当然方法一比较直接,编程方法也比较简单。相比方法二则需要理清晰其间关系与操作顺序。在此建议:将整个过程想法写出,再编程。这是个好习惯!!!可以省去很多麻烦,特别是逻辑上的错误 */ 代码实现:C++
/* 好吧,其实两个方法是同样的思路,但是前一种会去体系的建成一棵哈夫曼树后遍历找到哈夫曼编码,而后一种方法则是通过建立各元素之间的关系来找到哈夫曼编码。 当然 ,第一个方法涉及各种指针,其中还没有去delete掉那部分不使用到的内存,造成内存泄漏,所以如果数量级大了可能就内存溢出了,所以还有待修改优化。 至于第二种方法,其实就是运用了方法一的计算方法,但是没有建成一棵哈夫曼树,所以如果在其他有关树的操作时则会很麻烦。所以只是来算出这个哈夫曼编码而已哈哈哈。 当然方法一比较直接,编程方法也比较简单。相比方法二则需要理清晰其间关系与操作顺序。在此建议:将整个过程想法写出,再编程。这是个好习惯!!!可以省去很多麻烦,特别是逻辑上的错误 */ 代码实现:C++【本文地址】
今日新闻 |
推荐新闻 |