【时间序列】MTAD |
您所在的位置:网站首页 › 预测模型的mad › 【时间序列】MTAD |
【时间序列】MTAD
|
❝
论文标题 | Multivariate Time-series Anomaly Detection via Graph Attention Network 论文来源 | ICDM 2020 论文链接 | https://arxiv.org/abs/2009.02040 源码链接 | https://github.com/mangushev/mtad-gat 转自|AISeer ❞ TL;DR针对当前大部分多时间序列异常检测方法未考虑不同时间序列间相关性的问题,论文中提出了一种新颖的自监督学习框架 MTAD-GAT 进行多变量时间序列异常检测。MTAD-GAT 考虑将每个单指标时间序列作为特征,然后利用 2 种并行的 GAT 网络层来学习多个时间序列间的时序和特征依赖关系。此外,MTAD-GAT 还联合优化了基于预测的模型和基于重构的模型,以此来获得更好地时间序列表示。实验部分不仅在三个真实时间序列数据集中验证了 MTAD-GAT 优于当前 baselines,还通过分析说明模型学习到参数具有较好的可解释性。 Problem Definition单变量指标异常检测时仅考虑了某个系统的一个指标进行告警,因此很多时候下都会产生误报的情况。如下图所示,绿色区域表示单指标存在异常但整体不异常,红色区域表示系统整体指标异常。 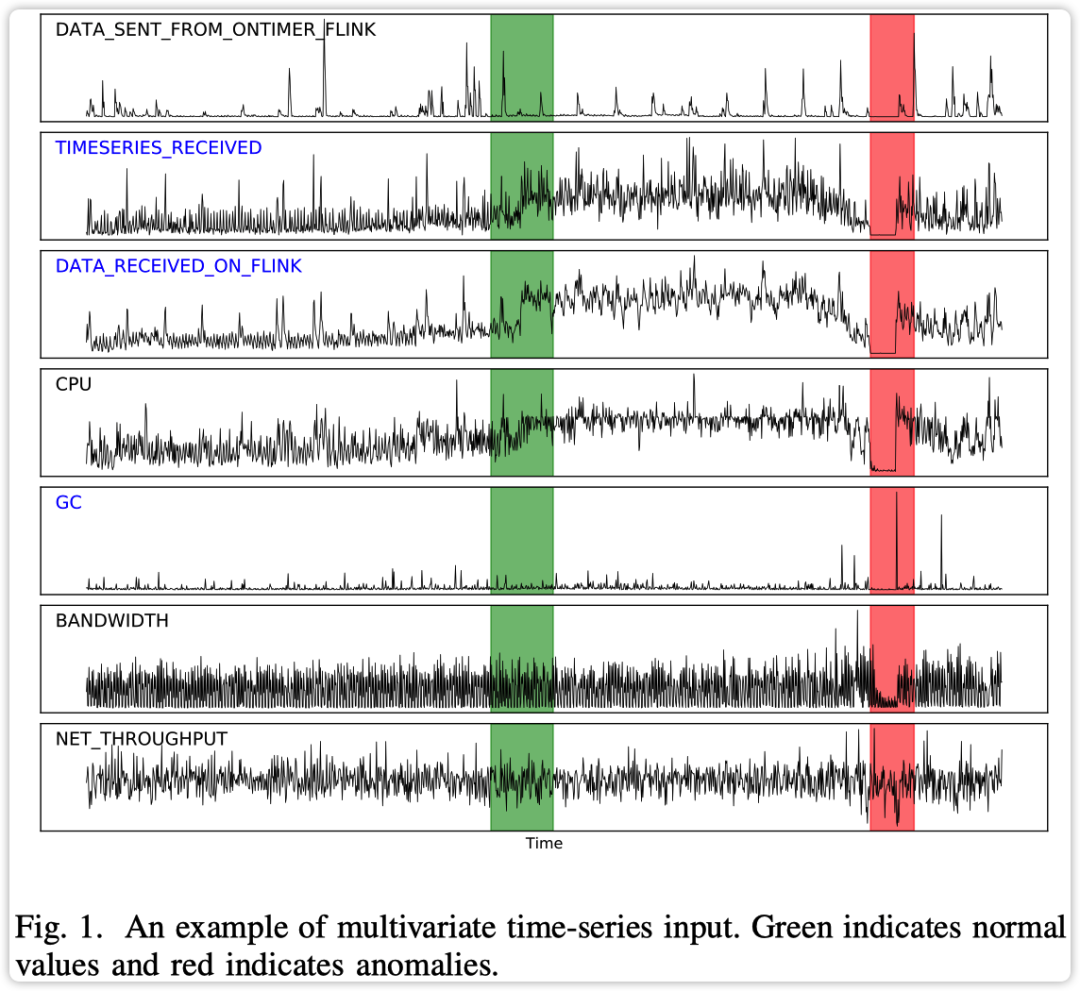 多变量时间序列示例
多变量时间序列示例
从上面的情况可以看出综合多变量时间序列进行异常检测是必要的,可以推送的告警信息更加准确。 「问题定义」:多变量时间序列的输入可以表示为 ,其中 表示最大时间戳长度(或者固定滑动窗口), 表示输入特征维度。多变量时间序列异常检测的目标是输出异常检测结果 其中 表示对应时间戳 是否为异常。 论文中涉及的符号含义如下表所示  符号含义
Algorithm/Model
符号含义
Algorithm/Model
论文提出的 MTAD-GAT 模型架构如下图所示 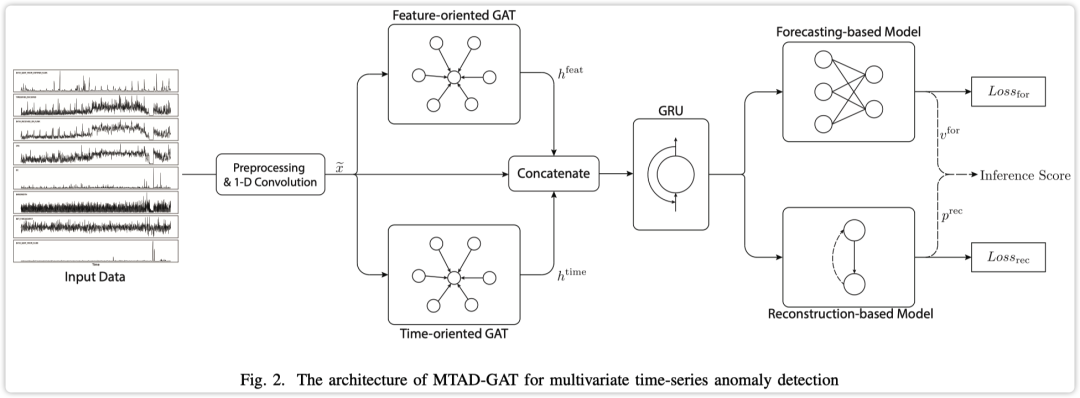 MTAD-GAT 模型架构
MTAD-GAT 模型架构
主要由以下模块组成: 1-D 卷积 (k=7) 获取时间序列高维特征; 两种 GAT 来捕获时间序列的特征和时序关系; 2 GAT 特征 + 1-D 卷积特征输入 GRU 来捕获序列模式; 将特征输入预测模型和重构模型来获取最终结果; 以下详细介绍每个模块度中的详细处理过程。 Data Preprocessing主要包括数据归一化和数据清洗。 数据归一化:使用的是最大-最小归一化方法。 数据清洗:使用「谱残差 (Spectral Residual,SR)」 的方法去除训练数据中的异常点。 Graph AttentionGAT 层可以表示任意图中两节点间的关系。假设给定 个节点特征的图 ,节点 的输出特征 如下:
其中 表示节点 和节点 间的注意力分数。计算方式如下: 其中 表示节点特征连接操作。 表示可学习权重且 表示节点特征维度。 论文中使用了两种类型的 GAT 层: Feature-oriented graph attention layer 考虑不同时间序列的相关性,输出维度为 。 个时间序列作为图中节点,每个节点对应的特征向量为 ,其关系可以通过图注意力机制学习注意力分数。如下图所示 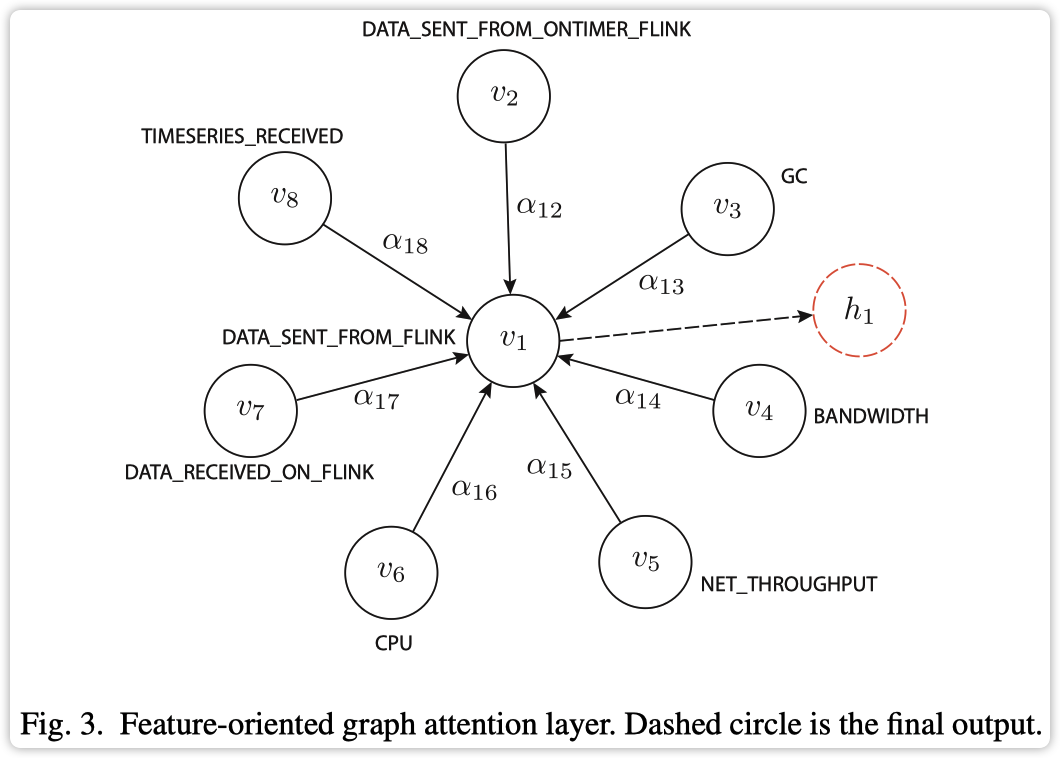 Feature-oriented
Feature-oriented
Time-oriented graph attention layer 考虑时间序列的时序依赖关系,输出维度为 。滑动窗口内每个时间戳作为节点,每个节点 表示 时刻的特征向量。 论文中将每个模块的输出 concatenate 得到 作为下一个模块的输入,每行表示每个时间戳对应的 维特征。???? 原始数据+相关序列特征+时序依赖特征 Joint Optimization基于预测的和基于重构的时间序列异常检测各有优势,所以论文中同时考虑了这两种类型的模型,优化的目标函数如下: 「Forecasting-based」 通过给定 个时间戳对应的值预测下一个时间戳对应的值,论文中使用的是 GRU 单元堆叠。 「Reconstruction-based」 通过历史数据学习正常数据分布,论文中使用的是 VAE 模型,细节可以参考我的另一篇博客:基于变分自编码器重构概率的异常检测模型 Model Inference基于预测的和基于重构的时间序列异常检测模型都有对应的输出结果 预测值输出结果为 概率值输出结果为 综合考虑每个特征的推断分数 作为最终异常分数,计算公式如下所示: 如果 大于某一阈值即为异常的,至于阈值可以使用 POT(Peak Over Treshold) 方法自动判断。其中 为超参数,可以通过训练集进行网格搜索最优参数。 Experiments实验部分采用了三种数据集,评价指标采用 ,不用 是因为作者发现所有的方法 都太高了... 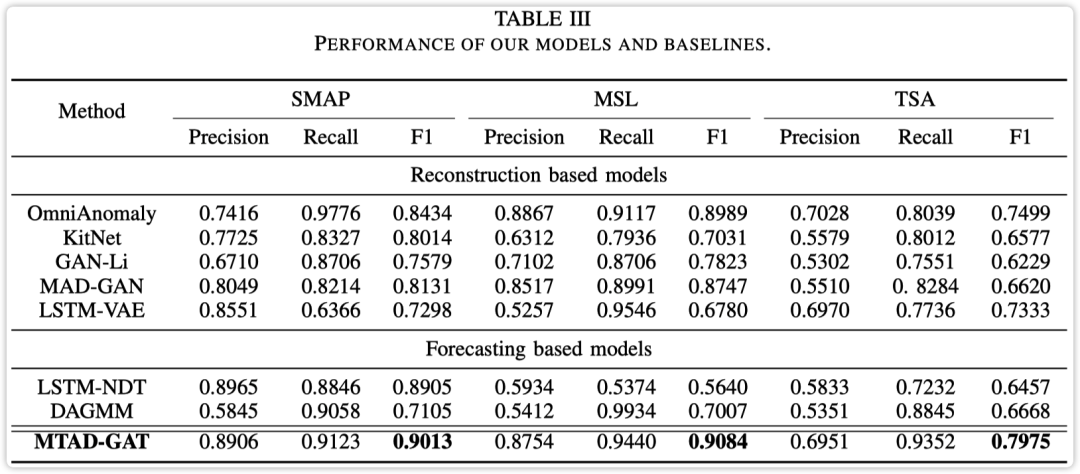 实验结果
实验结果
每个模块的消融实验结果如下 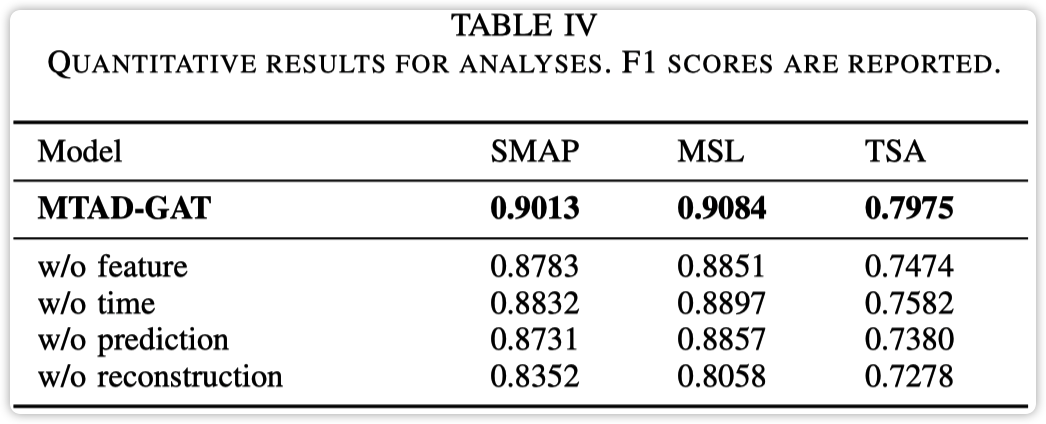 实验结果
实验结果
至于提到的可解释性,意思是可以从 attention score 看出故障前后指标的相关关系会发生变化,如下图所示 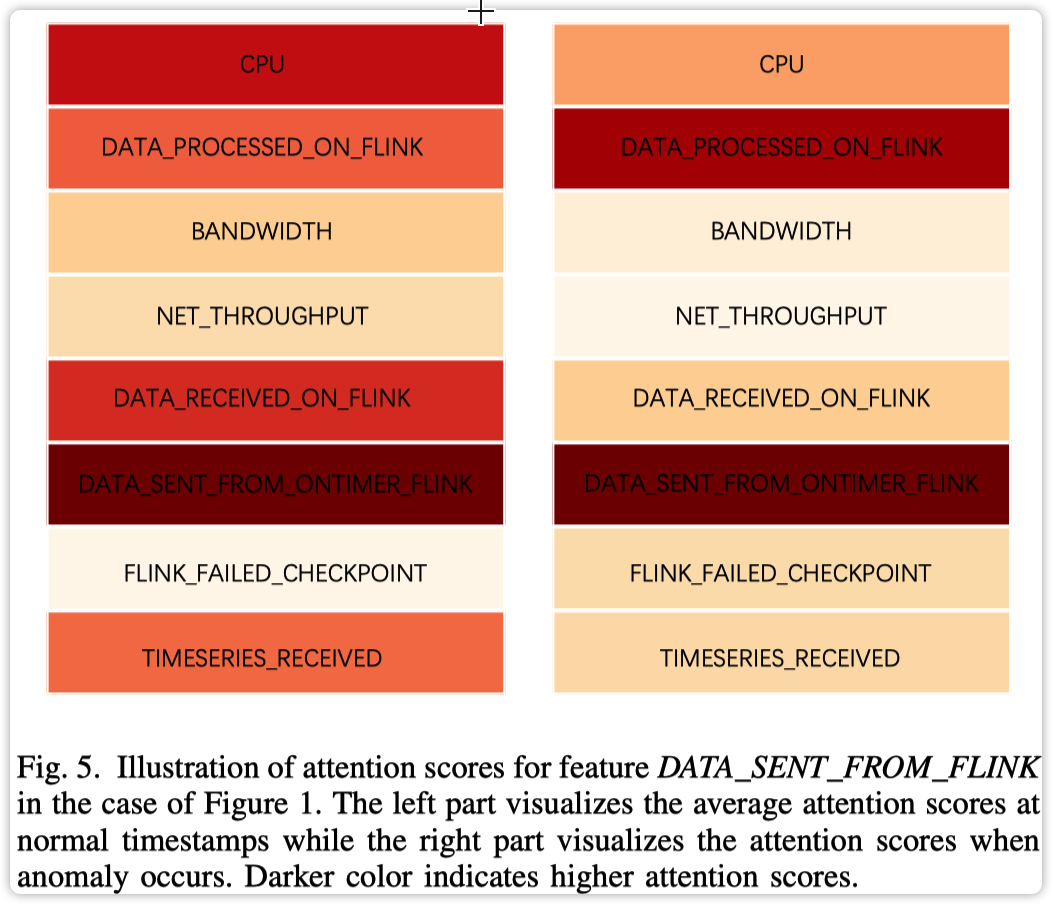 实验结果
实验结果
但是实际情况是异常前后故障指标间的仍存在比较相关的指标变化趋势,因此觉得这个解释并不靠谱。其它参数实验不再解释,感兴趣的可以参考原文~ Thoughts整体论文思路清晰,每个模块的设计思路及其需要解决的问题差强人意 ????。 图注意力机制模块设计可以参考,类似自动学习不同指标间的关联强度。 公众号:AI蜗牛车 保持谦逊、保持自律、保持进步
个人微信 备注:昵称+学校/公司+方向 如果没有备注不拉群! 拉你进AI蜗牛车交流群
|


【本文地址】