DBSCAN点云聚类 |
您所在的位置:网站首页 › 雷达dbs › DBSCAN点云聚类 |
DBSCAN点云聚类
|
1、DBSCAN算法原理
DBSCAN是一种基于密度的聚类方法,其将点分为核心点与非核心点,后续采用类似区域增长方式进行处理。下图为DBSCAN聚类结果,可见其可以对任意类别的数据进行聚类,无需定义类别数量。 DBSCAN聚类说明
从已有的聚类效果上来看,将一些点定义成噪声点,没有进行聚类。因此也可以理解成这样:先对点进行去噪处理,再使用距离聚类(如欧氏聚类)实现点的聚类。 对三维点云数据的聚类结果如下: 2、源码下载基于C++编写的源代码下载地址: https://download.csdn.net/download/qq_32867925/86246799 只需要将三个头文件加载到工程中即可 DBSCAN核心代码: DBSCANKdtreeCluster ec; ec.setCorePointMinPts(10); // test 4. uncomment the following line to test the EuclideanClusterExtraction // pcl::EuclideanClusterExtraction ec; pcl::search::KdTree::Ptr tree(new pcl::search::KdTree); tree->setInputCloud(cloud); std::vector cluster_indices; ec.setClusterTolerance(0.1);//搜索近邻点半径 ec.setMinClusterSize(100);//最小簇点数要求 ec.setMaxClusterSize(5000000);//最大簇点数限制 ec.setSearchMethod(tree); ec.setInputCloud(cloud); ec.extract(cluster_indices); clock_t end_ms = clock(); std::cout pcl::PointXYZI tmp; tmp.x = cloud->points[*pit].x; tmp.y = cloud->points[*pit].y; tmp.z = cloud->points[*pit].z; tmp.intensity = j % 8; cloud_clustered->points.push_back(tmp); } } 2、聚类效果
|
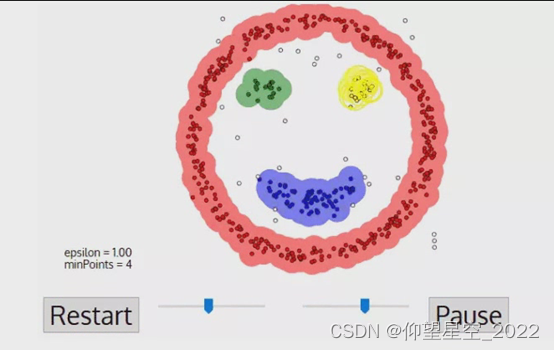 DBSCAN聚类过程如下: 1、首先,DBSCAN算法会以任何尚未访问过的任意起始数据点为核心点,并对该核心点进行扩充。这时我们给定一个半径/距离ε,任何和核心点的距离小于ε的点都是它的相邻点。 2、如果核心点附近有足够数量的点,则开始聚类,且选中的核心点会成为该聚类的第一个点。如果附近的点不够,那算法会把它标记为噪声(之后这个噪声可能会成为簇中的一部分)。在这两种情形下,选中的点都会被标记为“已访问”。 3、一旦聚类开始,核心点的相邻点,或者说以该点出发的所有密度相连的数据点(注意是密度相连)会被划分进同一聚类。然后我们再把这些新点作为核心点,向周围拓展ε,并把符合条件的点继续纳入这个聚类中。 4、重复步骤2和3,直到附近没有可以扩充的数据点为止,即簇的ε邻域内所有点都已被标记为“已访问”。 5、一旦我们完成了这个集群,算法又会开始检索未访问过的点,并发现更多的聚类和噪声。一旦数据检索完毕,每个点都被标记为属于一个聚类或是噪声。 与其他聚类算法相比,DBSCAN有一些很大的优势。首先,它不需要输入要划分的聚类个数。其次,即使数据点非常不同,它也会将它们纳入聚类中,DBSCAN能将异常值识别为噪声,这就意味着它可以在需要时输入过滤噪声的参数。第三,它对聚类的形状没有偏倚,可以找到任意大小和形状的簇。 DBSCAN的主要缺点是,当聚类的密度不同时,DBSCAN的性能会不如其他算法。这是因为当密度变化时,用于识别邻近点的距离阈值ε和核心点的设置会随着聚类发生变化。而这在高维数据中会特别明显,因为届时我们会很难估计ε。
DBSCAN聚类过程如下: 1、首先,DBSCAN算法会以任何尚未访问过的任意起始数据点为核心点,并对该核心点进行扩充。这时我们给定一个半径/距离ε,任何和核心点的距离小于ε的点都是它的相邻点。 2、如果核心点附近有足够数量的点,则开始聚类,且选中的核心点会成为该聚类的第一个点。如果附近的点不够,那算法会把它标记为噪声(之后这个噪声可能会成为簇中的一部分)。在这两种情形下,选中的点都会被标记为“已访问”。 3、一旦聚类开始,核心点的相邻点,或者说以该点出发的所有密度相连的数据点(注意是密度相连)会被划分进同一聚类。然后我们再把这些新点作为核心点,向周围拓展ε,并把符合条件的点继续纳入这个聚类中。 4、重复步骤2和3,直到附近没有可以扩充的数据点为止,即簇的ε邻域内所有点都已被标记为“已访问”。 5、一旦我们完成了这个集群,算法又会开始检索未访问过的点,并发现更多的聚类和噪声。一旦数据检索完毕,每个点都被标记为属于一个聚类或是噪声。 与其他聚类算法相比,DBSCAN有一些很大的优势。首先,它不需要输入要划分的聚类个数。其次,即使数据点非常不同,它也会将它们纳入聚类中,DBSCAN能将异常值识别为噪声,这就意味着它可以在需要时输入过滤噪声的参数。第三,它对聚类的形状没有偏倚,可以找到任意大小和形状的簇。 DBSCAN的主要缺点是,当聚类的密度不同时,DBSCAN的性能会不如其他算法。这是因为当密度变化时,用于识别邻近点的距离阈值ε和核心点的设置会随着聚类发生变化。而这在高维数据中会特别明显,因为届时我们会很难估计ε。 


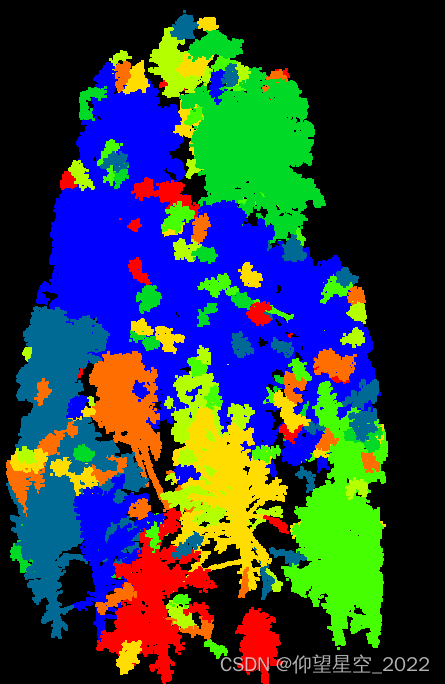
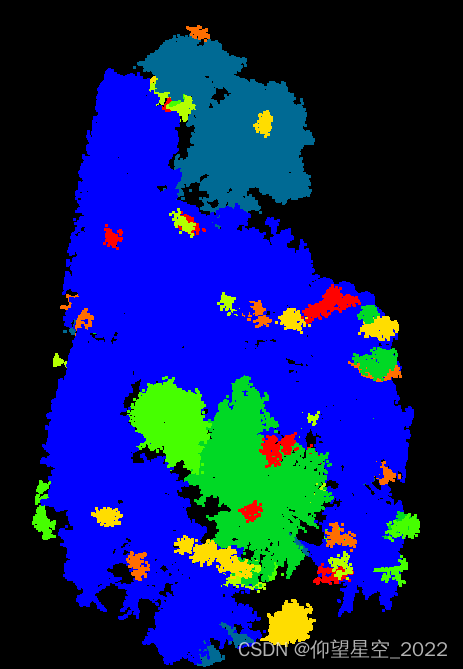 从另一个角度可见,DBSCAN是距离聚类的另一种形式,其相比较于常规距离聚类而言,多了核心点判别过程。
从另一个角度可见,DBSCAN是距离聚类的另一种形式,其相比较于常规距离聚类而言,多了核心点判别过程。【本文地址】
今日新闻 |
推荐新闻 |