零样本学习(zero |
您所在的位置:网站首页 › 零样本语义分割 › 零样本学习(zero |
零样本学习(zero
|
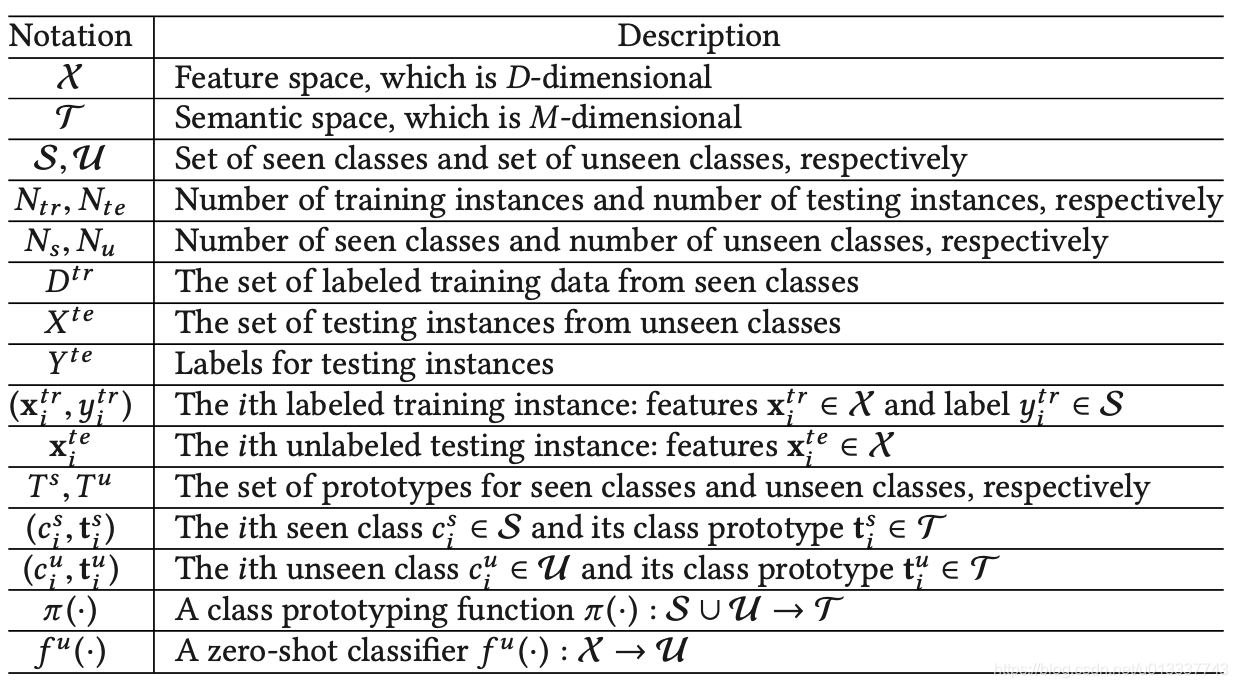
-------本文内容来自对论文A Survey of Zero-Shot Learning: Settings, Methods, and Applications 的理解和整理,这里省去了众多的数学符号,以比较通俗的语言对零样本学习做一个简单的入门介绍,用词上可能缺乏一定的严谨性。一些图和公式直接来自于论文,并且省略了论文中讲的比较细的东西,如果感兴趣建议还是去通读论文 注1:为了方便,文中“已知类别(标签)”都指训练集中出现的类别;“未知类别(标签)”指测试集中出现的新类别。 注2:“特征空间(feature space)”指样本的原始信息(即x)所在的空间;语义空间(sematic space)指类别描述信息所在空间,已知类别和未知类别在语义空间中被联系起来。 注3:文中用到的公式符号含义如下图所示: 本节首先介绍一下零样本学习相关的技术和概念。 1.1零样本学习概念零样本学习属于迁移学习,是迁移学习的一个子领域。迁移学习可分为同质迁移学习(homogeneous)和不同质迁移学习(heterogeneous),前者两个域的特征空间和标签空间都相同,后者特征空间和标签空间不同。因为零样本学习的特征空间相同,但是源领域的标签空间(seen class)已知,目标领域标签空间(unseen class)未知,所以零样本学习属于不同质迁移学习。零样本学习就是,在测试集中,有些类别不在训练集中,利用训练集的样本训练一个模型,使之应用到测试集能正确识别那些在训练集中不存在的标签。 1.2额外信息(Auxiliary information)因为零样本学习的特殊性,即测试集中包含训练集中不存在的类别。所以零样本学习需要引入一些额外信息,这些额外信息通常是对所有类别(包括已有类别和未知类别)的描述。由于这些描述通常是语义层面的,所以额外信息组成的空间又叫语义空间(sematic spaces),而原始样本组成的空间称为特征空间(feature spaces)。 1.2.1语义空间(sematic spaces)根据语义空间如何构建,可把语义空间分为手工语义空间,学习得到的语义空间。分类如下图所示: 手工语义空间即人们手动构造的一些关于类别额外信息。主要分为属性空间(attribute space),词法空间(lexical spaces),文本关键词空间(Text-keyword spaces)。 属性空间即找到关于类别的一些属性,基于这些属性值构建语义向量。如在动物识别中,动物类别的属性可以包括毛色,速度,体积等,通过手工构造这些属性和属性值,得到类别的语义向量,其中每一维是一个属性值。 词法空间即语义空间由类别的一些词法信息构成,这些词法信息可以来自一些泛化知识库如WordNet;或者来自一些针对特定问题的词法分析工具,如依存树;或者来自一些大型的语料,利用在语料中类别的共现关系。具体构造方法有很多,比如利用类别在WordNet中的父子关系,类别语义向量的每一维代表一个类别,如果是父子关系的类别,则相应位置置1。 文本关键词空间即从类别描述信息中抽取出的关键词构成语义空间。可以采用tf-idf,Bag of Words等技术得到。 手工语义空间的优点是可解释性好,灵活性高,缺点是需要手工构造,费时费力,并且由于手工构造的局限性导致语义信息丢失。 1.2.1.2 学习得到的语义空间(Learned sematic spaces)学习得到的语义空间不是手工构造的,而是通过其他机器学习模型训练得到的,这些语义向量可以是针对其他任务预训练好的,也可以是专门针对零样本学习训练得到的,语义向量的每一维没有实际意义,整个语义向量代表了这个类别的信息。 学习得到的语义空间包括标签向量空间(Label-embedding spaces),文本向量空间(Text-embedding spaces),图像表示空间(Image-representation spaces)等。 标签向量空间即通过类似于词向量的方式得到每个标签的向量表示,常用技术有word2vec,glove等。它的核心思想是,具有相似含义的标签具有相似的语义向量。 文本向量空间类似于标签向量空间,只不过它对标签的描述信息进行向量化,把标签的描述信息输入到预训练好的模型,输出的向量即可以表示为这个标签的语义信息。 图像表示空间即把某种类别对应的图像做为描述信息,输入到预训练的模型如GoogLeNet,得到的输出向量做这个标签的语义信息。 学习的得到的语义空间优点就是节省了人力,依赖机器学习模型可以捕捉到更多的语义信息,缺点是语义向量的含义是隐式的,不利于分析。 1.3直推式学习(Transductive)和归纳学习(Inductive)直推式学习和归纳学习是机器学习中的基本概念。按直推式学习和归纳学习的程度,零样本学习可分为如下图所示的三种方式: 零样本学习可以分为两大类:基于分类器的方法和基于实例的方法。基于分类器的方法主要致力于直接学习到一个用于未知类别分类的模型,是一个“改进模型”的方法,从模型入手,不改变训练数据。而基于实例的方法主要致力于为未知类别构造样本,然后用这些构造的样本去训练一个分类器,是一个“改进数据”的方法,从改变训练数据入手,让训练数据包含那些未知样本,这样训练出的模型就能正确分类未知样本了。 整个分类如下图所示: 根据分类器的构造方法,基于分类器的零样本学习又可分为映射方法,关系方法和组合方法。 首先需要说明的是,基于分类器的方法的主要思想:它是基于“1对多”的方式来训练N个分类器(想想为什么要多个分类器,而不是一个?),N为类别的数量,即它为每个类别单独训练一个分类器,每次训练的时候用属于当前待识别类别的样本做为正样本,其他所有样本做为负样本。 因为测试集中的有些类别不在训练集中,所以直接用训练集训练一个分类器,用在测试集上效果会很差。基于分类器方法的主要思想是利用额外知识----类别描述信息(语义空间),具有相似类别描述信息的类别,其分类器也比较相似。比如驴和马,它们之间的类别描述信息很相似,则用驴构成的训练集训练一个二分类模型f来判断样本是否属于驴,则这个二分类模型f利用到马构成的测试集上效果也不会很差:用1表示属于(驴)马,0表示不属于(驴)马,则f在驴数据集上训练时,分类器输出越接近1则越有信息认为它是一头驴,越接近0则相反;把训练好的f用到马数据集上分类马时,因为马和驴很相似,所以分类器的输出和在驴数据集上的输出相似,于是也大概率能正确分类出马。但是我们不可能只给训练集中出现的类别各自训练一个分类器,因为这样还是无法分类测试集中的具有新类别的样本(因为测试集中的新种类可能有多个,你不知道这个测试样本属于新种类还是训练集中的种类,如果是新种类你也不知道是哪个新种类),所以需要对每个类别(包括已知类别和未知类别)都构建一个二分类器,这样对于每个测试样本,可以采取“依次带入这些分类器取概率最高的类别做为它的类别”。通过上述分析我们知道,马和驴的分类器参数应该是相似的,现在的问题是,模型事先并不知道马和驴是相似的,所以也就不知道让马和驴的分类器参数相似,所以这时就需要额外信息的加入。通过加入类别描述信息,模型知道了马和驴相似,于是把马的分类器参数训练得和驴相似,也就得到了新类别马的分类器模型。 有了上面的主要思想,则要做的就是如何把类别的描述信息加入模型,被模型所感知和利用?于是有了以下的各种方法: 2.1.1 映射方法(correspondence methods)1)首先针对训练集中的每个类别训练一个二分类器 f i f_i fi,得到识别每个类别所需的分类器参数 w i w_i wi。 2)用训练集中每个类别的描述信息 t i t_i ti做为输入, w i w_i wi做为标签训练一个模型 φ \varphi φ,得到模型的中间参数 ζ \zeta ζ。这个模型 φ \varphi φ即映射函数(correspondence function),它的作用是求出每一种类别对应的分类器参数。求出映射函数 φ \varphi φ后,对于每个未知类别,用它的描述信息 t j t_j tj做为输入,输入到 φ \varphi φ,就可以得到相应类别的分类器参数 w j w_j wj,即得到了新类别的分类器参数。基于的思想正是具有相似描述信息的类别,它们的分类器参数也相似。 3)在测试阶段,对于每一个测试样本,带入到每个类别的分类器中,取概率最大的类别做为它的类别(论文中关于如何测试说的不太详细,这是我自己的想法)。 上述的方法是一个最基础的方法,现在的研究大多都基于以上思想进行了改进。比如上述方法中,类别分类器和映射函数是分开学习的,一个改进思想就是让分类器和映射函数联合学习,以使它们之间彼此促进。这种方法的损失函数如下式所示: 这里 θ \theta θ函数也叫兼容函数(compatibility function),它其实就是前文讲到的一种映射函数。 θ \theta θ函数说白了就是求输入 x i x_i xi和类别描述 t j t_j tj的相似度,常用的定义 θ \theta θ函数的方法有 θ ( x i , t j ; W ) = x i T W t j \theta(x_i,t_j;W)=x^T_iWt_j θ(xi,tj;W)=xiTWtj,但这是一种线性的分类器,所以也有使用 θ ( x i , t j ; W ) = ϕ ( x i ) T W φ ( t j ) \theta(x_i,t_j;W)=\phi(x_i)^TW\varphi(t_j) θ(xi,tj;W)=ϕ(xi)TWφ(tj)等等。 上述方法训练过程中只使用了训练样本和训练样本类别的描述信息,而没有使用测试样本和测试样本类别的描述信息。根据前文直推式学习和归纳式学习对零样本学习的分类,训练过程中也可以使用测试样本和测试样本类别的描述信息,这里不再详细展开。 2.1.2 关系方法(relationship methods)关系方式主要借助于类别之间的关系来构建模型。其核心思想和映射方法一样,即相似的类别描述信息,其类别分类器也相似。 它的过程如下: (1)利用训练集中的样本和标签,对训练集中出现的每个类别训练一个二分类器。 (2)对于测试集中每个新类别,通过对已有类别二分类器加权平均的方式,得到新类别的分类器。即 类别之间关系(相似度)有多种计算方法,比如计算它们描述信息的余弦相似度,或者利用WordNet中两个类别之间的结构关系。类别分类器的选择可以选择与未知类别关系最紧密(相似度最高)的K个类别加权平均。 训练的时候也可以加入未知类别的信息。一些工作已已知类别和未知类别为节点在语义空间中构建一个关系图,图的边权重为类别之间的关系。然后在图上学习类别的二分类器。 2.1.3 组合方法(combination methods)组合方法是把每个类别看成由一系列属性组成的。比如马可以有属性集合{肤色,速度,体积…}一系列属性构成。对训练集中的每个属性训练一个二分类器,这样给定一个样本x,就可以判断它是否拥有某个属性。在测试阶段,利用下式来计算测试样本
x
j
t
e
x^{te}_j
xjte是类别
c
i
u
c^u_i
ciu的概率: 基于实例的方法从数据入手,为那些训练集中没有出现过的类别构造样本,然后把这些样本加入训练集训练一个分类器或进行聚类(KNN)。根据这些样本是如何构造的,基于实例的方法可分为拟合方法,借助其他实例方法和合成方法。 2.2.1 拟合方法(projection methods)拟合方法基于的思想是,类别描述信息可以被当做样本标签看待(构造新实例)。首先通过拟合函数,将样本
x
i
x_i
xi和类别描述信息
t
j
t_j
tj拟合到一个同一空间P: 拟合空间P有多种选择,可以将语义空间做为拟合空间,将样本 x i x_i xi拟合到这个空间中;也可以将特征空间做为拟合空间,将类别描述信息 t j t_j tj拟合到这个空间;或者既不选择语义空间,也不选择特征空间,而使用其他空间,或者使用多个空间做拟合空间。 2.2.1.1 语义空间做为拟合空间(Semantic space as projection space)首先介绍语义空间做拟合空间。这种设置下类别描述信息
t
j
t_j
tj不用改变,只通过拟合函数
θ
\theta
θ来将样本
x
i
x_i
xi拟合到语义空间。损失函数为: 枢纽度问题 使用语义空间做拟合空间并且使用回归函数做拟合函数时,会产生枢纽度问题。在拟合空间P中,一些类别描述信息是很多样本的最近邻,而这些样本实际上类别并不相同,这个描述信息就被称为"枢纽(hubs)",这种现象称为"枢纽度问题(hubness)"。 一些工作为了解决枢纽度问题,采用其他损失函数如rank loss或采用不同的距离度量函数如余弦相似度等。 2.2.1.2 特征空间做为拟合空间(Feature space as projection space)特征空间做拟合空间即通过拟合函数
ξ
\xi
ξ将类别描述信息
t
j
t_j
tj拟合到特征空间,而样本特征
x
i
x_i
xi不用改变。损失函数为: 还有一些其他方法既不使用语义空间做拟合空间,也不使用特征空间做拟合空间,而是使用一些其他的空间甚至多个空间。具体可以参考一些相关论文。 2.2.2 借助其他实例方法(instance-borrowing methods)借助其他实例的方法即对于未知类别 c i c_i ci,虽然训练集中没有此类别的样本,但可以训练集中找到一些和 c i c_i ci相似的类别,用他们的样本作为类别 c i c_i ci的样本,然后放入训练集训练。比如未知类别是卡车,我们没有卡车的样本,但是训练集中有拖车和货车,于是把拖车和货车的样本拿出来,并给它们重新标上标签“卡车”,这样就“造”出了未知类别 c i c_i ci的样本,就可以用这些样本去训练类别 c i c_i ci的分类器了。 这其实还是那个思想“相似的类别,分类器也相似”。 下面的问题就是如何选择相似的样本?大多数研究根据类别描述信息,选择类别描述信息比较相似的类别对应的样本作为未知类别的样本。 2.2.3 合成方法(synthesizing methods)合成方法通过一些生成模型来生成未知类别的样本。未知类别的样本假设服从某些分布,比如高斯分布或均匀分布,首先求出已知类别的分布参数,然后根据未知类别描述信息和已知类别描述信息的关系求出未知类别的关系分布(比如对于高斯分布,参数是均值和方差)。有了未知类别样本的分布,就可以根据生成模型生成一些样本。生成模型比如generative mo-ment matching network (GMMN), denoising autoencoder, adversarial autoencoder, conditional variational autoencoder-based architecture, generative adversarial networks (GAN)等。生成模型的输入通常是未知类别描述信息和符合某一分布的噪音。 三.零样本学习方法的比较 方法优点缺点基于分类器的方法映射方法类别描述信息和分类器通过映射函数进行关联,这样的映射函数方便且有效没有对不同的类别之间的关系建模,这些类别间关系在零样本学习中是非常重要的知识关系方法对类别之间的关系进行了建模,并且未知类别的分类使用了已知类别的分类器,所以节省了时间语义空间中类别的关系直接应用到了特征空间,所以没有解决从语义空间到特征空间的适应问题组合方法对类别属性的分类器可以直接拿来使用,所以节省了时间属性分类器的训练,和属性到类别的推断是两个分离的过程,很难去联合优化基于实例的方法拟合方法拟合函数的选择很灵活,一些半监督学习方法可以拿来使用因为每个未知类别只有一个实例(类别描述信息),所以将测试样本映射到统一空间后只能用1NN的方法去寻找最接近的类别,是非常受限的借助实例方法借助的样本数量可以很大,所以很多监督学习方法都能用上因为借助的样本属于已知类别,所以训练出的未知类别分类起难免会不精确合成方法合成的样本数量可以很大,所以很多监督学习方法都能用上合成的样本事先假定服从某一分布,所以比起真实样本会有偏差 四.未来的研究方向一.样本的一些特性 样本的一些特性没有用到。比如图像物体识别,除了图像本身,物体的其他方面的特征也可以用上;一些多模态的数据;时间序列的特点等。 二.训练数据的选择 (1)现有的零样本学习,训练集和测试集往往是同一种类型,比如都是图片,或都是文字。实际上训练集和测试集的数据所对应的类别可以不在同一个语义空间,比如训练集是物体图片,测试集是场景图片。甚至训练集和测试集的实例都不相同,比如训练集是音频,测试集是图片。有些语义类型的数据很容易得到,而有的不容易得到,所以尝试一下异构零样本学习也是很有必要的。 (2)通过主动学习挑选训练数据。可以减轻标注压力 三.额外信息的选择和保持 额外信息不仅仅是在语义空间,也可以使用其他类型的语义信息。比如属性空间(attribute space),也有研究不适用语义空间,而使用人工构造的类别相似度信息。 得到额外信息后,如何在训练中保持这些额外信息也很重要,即使这些信息在训练过程中不丢失,不改变。因为当只学习样本分类器的时候,额外信息就很容易丢失。有些工作加入了重构模块,以尽大可能使额外信息在训练中保持。 四.更加实际和更加针对于特定任务的问题设置 (1)在现实生活中,测试集中往往即包括训练集中出现的类别,也包括未出现的类别,这种问题设置称为广义零样本学习(generalized zero-shot learning)。在这种问题设置下,模型的效果要比零样本学习差很多,所以有很大改进的地方。 (2)针对不同的任务设置不同的零样本学习方法。 五.理论研究 现有方法大多是一些启发式的,并没有严格的证明。比如(1)如何选择额外信息(2)哪些来自训练样本的信息对测试样本分类有帮助?(3)如何阻止无关信息迁移和负迁移? 六.与其他学习方法相结合 比如zero-shot和few-shot相结合;与机器学习方法相结合,比如零样本学习可以做为主动学习之前的步骤来加强主动学习的效果等等。 |

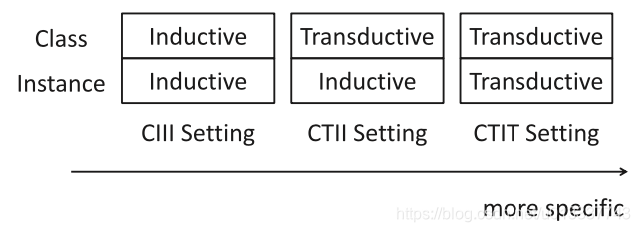 在训练过程中,如果用到了测试集中的样本,则称为实例直推式(Instance-Transductive),否则称为实例归纳式(Instance-Inductive);如果用到了未知的类别描述信息,则称为类别直推式(Class-Transductive),否则称为类别归纳式(Class-Inductive)。所以按上述进行分类,零样本的学习过程可分为上图所示三种,训练过程中利用的信息越多,可能会过拟合,越少可能会欠拟合,甚至导致领域漂移(domain shift )。所谓领域漂移指源领域和目标领域数据差别太大,比如已有类别是家具,未知类别是动物,这种情形下采用传统的零样本学习也达不到很好的效果,因为很难根据类别相似来识别新类别。
在训练过程中,如果用到了测试集中的样本,则称为实例直推式(Instance-Transductive),否则称为实例归纳式(Instance-Inductive);如果用到了未知的类别描述信息,则称为类别直推式(Class-Transductive),否则称为类别归纳式(Class-Inductive)。所以按上述进行分类,零样本的学习过程可分为上图所示三种,训练过程中利用的信息越多,可能会过拟合,越少可能会欠拟合,甚至导致领域漂移(domain shift )。所谓领域漂移指源领域和目标领域数据差别太大,比如已有类别是家具,未知类别是动物,这种情形下采用传统的零样本学习也达不到很好的效果,因为很难根据类别相似来识别新类别。
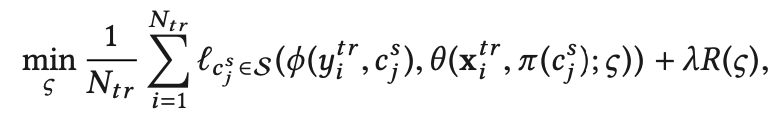 公式中符号含义在文章开头已给出。其中
θ
(
x
i
t
r
,
π
(
c
j
s
)
;
φ
)
\theta(x^{tr}_i,π(c^{s}_j);\varphi)
θ(xitr,π(cjs);φ)是要学习的分类器,
π
(
c
j
s
)
π(c^{s}_j)
π(cjs)即对
c
j
s
c^{s}_j
cjs这个类别的描述信息,可以看做
t
j
s
t^{s}_j
tjs=
π
(
c
j
s
)
π(c^{s}_j)
π(cjs)。对于一个输入样本
x
i
t
r
x^{tr}_i
xitr和任意一个类别的描述
t
j
s
t^{s}_j
tjs,如果
t
j
s
t^{s}_j
tjs是或接近
x
i
t
r
x^{tr}_i
xitr的类别描述,则
θ
\theta
θ函数的输出接近1(变大),反之,
θ
\theta
θ函数的输出接近0(变小),因为类别描述就代表了类别,所以根据
θ
\theta
θ函数的输出大小就可以判断样本输入哪个类别。那么如何训练这个
θ
\theta
θ函数来实现这种功能呢?上式给出的损失函数第一项
ϕ
(
y
i
t
r
,
c
j
s
)
\phi(y^{tr}_i,c^{s}_j)
ϕ(yitr,cjs)为标签
y
i
t
r
y^{tr}_i
yitr和类别
c
j
s
c^{s}_j
cjs的相似度,越相似数值越大。所以损失函数
l
l
l即最小化
ϕ
\phi
ϕ和
φ
\varphi
φ的差异,即
y
i
t
r
y^{tr}_i
yitr和类别
c
j
s
c^{s}_j
cjs越相似,
ϕ
\phi
ϕ越大,则
θ
\theta
θ也越大,则样本
x
i
t
r
x^{tr}_i
xitr属于类别
c
j
s
c^{s}_j
cjs的置信度越高;反之越小。 上述思想可按以下步骤实现: (1)对训练样本构造(样本,类别描述)对,即
(
x
i
t
r
,
t
j
)
(x^{tr}_i,t_j)
(xitr,tj),以这些(样本,类别描述)对和相应样本标签和类别的相似度
ϕ
(
y
i
t
r
,
c
j
s
)
\phi(y^{tr}_i,c^{s}_j)
ϕ(yitr,cjs)做为输入,最小化损失函数
l
l
l,学习到分类器函数
θ
\theta
θ的参数
φ
)
\varphi)
φ)。 (2)在测试阶段,对于输入的一个测试样本
x
i
u
x^{u}_i
xiu和一个类别描述
t
j
u
t^{u}_j
tju,
θ
\theta
θ分类器能输出
x
i
u
x^{u}_i
xiu属于类别描述对应类别
c
j
u
c^{u}_j
cju的概率,取所有类别中概率最大的类别做为测试样本
x
i
u
x^{u}_i
xiu的类别。
公式中符号含义在文章开头已给出。其中
θ
(
x
i
t
r
,
π
(
c
j
s
)
;
φ
)
\theta(x^{tr}_i,π(c^{s}_j);\varphi)
θ(xitr,π(cjs);φ)是要学习的分类器,
π
(
c
j
s
)
π(c^{s}_j)
π(cjs)即对
c
j
s
c^{s}_j
cjs这个类别的描述信息,可以看做
t
j
s
t^{s}_j
tjs=
π
(
c
j
s
)
π(c^{s}_j)
π(cjs)。对于一个输入样本
x
i
t
r
x^{tr}_i
xitr和任意一个类别的描述
t
j
s
t^{s}_j
tjs,如果
t
j
s
t^{s}_j
tjs是或接近
x
i
t
r
x^{tr}_i
xitr的类别描述,则
θ
\theta
θ函数的输出接近1(变大),反之,
θ
\theta
θ函数的输出接近0(变小),因为类别描述就代表了类别,所以根据
θ
\theta
θ函数的输出大小就可以判断样本输入哪个类别。那么如何训练这个
θ
\theta
θ函数来实现这种功能呢?上式给出的损失函数第一项
ϕ
(
y
i
t
r
,
c
j
s
)
\phi(y^{tr}_i,c^{s}_j)
ϕ(yitr,cjs)为标签
y
i
t
r
y^{tr}_i
yitr和类别
c
j
s
c^{s}_j
cjs的相似度,越相似数值越大。所以损失函数
l
l
l即最小化
ϕ
\phi
ϕ和
φ
\varphi
φ的差异,即
y
i
t
r
y^{tr}_i
yitr和类别
c
j
s
c^{s}_j
cjs越相似,
ϕ
\phi
ϕ越大,则
θ
\theta
θ也越大,则样本
x
i
t
r
x^{tr}_i
xitr属于类别
c
j
s
c^{s}_j
cjs的置信度越高;反之越小。 上述思想可按以下步骤实现: (1)对训练样本构造(样本,类别描述)对,即
(
x
i
t
r
,
t
j
)
(x^{tr}_i,t_j)
(xitr,tj),以这些(样本,类别描述)对和相应样本标签和类别的相似度
ϕ
(
y
i
t
r
,
c
j
s
)
\phi(y^{tr}_i,c^{s}_j)
ϕ(yitr,cjs)做为输入,最小化损失函数
l
l
l,学习到分类器函数
θ
\theta
θ的参数
φ
)
\varphi)
φ)。 (2)在测试阶段,对于输入的一个测试样本
x
i
u
x^{u}_i
xiu和一个类别描述
t
j
u
t^{u}_j
tju,
θ
\theta
θ分类器能输出
x
i
u
x^{u}_i
xiu属于类别描述对应类别
c
j
u
c^{u}_j
cju的概率,取所有类别中概率最大的类别做为测试样本
x
i
u
x^{u}_i
xiu的类别。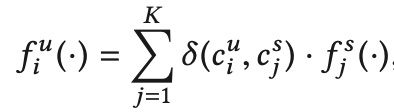 其中
δ
(
c
i
u
,
c
i
s
)
\delta(c^u_i,c^s_i)
δ(ciu,cis)为新类别
c
i
u
c^u_i
ciu和训练集中类别
c
i
s
c^s_i
cis之间的相似度,做为类别
c
i
s
c^s_i
cis分类器的权重。把所有已知类别分类器加权平均,即为未知类别的分类器。
其中
δ
(
c
i
u
,
c
i
s
)
\delta(c^u_i,c^s_i)
δ(ciu,cis)为新类别
c
i
u
c^u_i
ciu和训练集中类别
c
i
s
c^s_i
cis之间的相似度,做为类别
c
i
s
c^s_i
cis分类器的权重。把所有已知类别分类器加权平均,即为未知类别的分类器。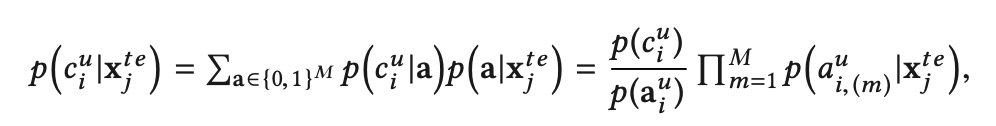 有点类似贝叶斯公式,具体细节需要阅读这方面的论文,在此省略。
有点类似贝叶斯公式,具体细节需要阅读这方面的论文,在此省略。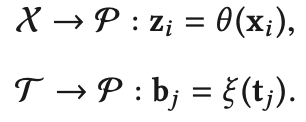 因为未知类别在特征空间中没有样本,且只在语义空间中有一个类别描述信息标签,所以每个未知类别相当于只有一个样本,无法用常规的分类方法去训练。但是可以借助KNN的思想,将样本
x
i
x_i
xi和类别描述信息
t
j
t_j
tj拟合到一个同一空间P,然后对于未知样本,也拟合到这个空间,并选择离它最近的类别描述信息所对应的类别做为它的类别(1NN)。
因为未知类别在特征空间中没有样本,且只在语义空间中有一个类别描述信息标签,所以每个未知类别相当于只有一个样本,无法用常规的分类方法去训练。但是可以借助KNN的思想,将样本
x
i
x_i
xi和类别描述信息
t
j
t_j
tj拟合到一个同一空间P,然后对于未知样本,也拟合到这个空间,并选择离它最近的类别描述信息所对应的类别做为它的类别(1NN)。 π
(
y
i
t
r
)
π(y^{tr}_i)
π(yitr)可以看做是类别描述信息
t
i
t
r
t^{tr}_i
titr,这个式子的目的就是学习一个拟合函数
θ
\theta
θ,来把样本
x
i
t
r
x^{tr}_i
xitr拟合到语义空间,并且在拟合空间的表示和它的类别描述信息的表示
t
i
t
r
t^{tr}_i
titr相似。 然后在测试阶段,对于每个测试样本
x
i
u
x^{u}_i
xiu,通过拟合函数
θ
\theta
θ拟合到语义空间,并找离它最近的类别描述信息所对应的类别做为它的类别(1NN)。
π
(
y
i
t
r
)
π(y^{tr}_i)
π(yitr)可以看做是类别描述信息
t
i
t
r
t^{tr}_i
titr,这个式子的目的就是学习一个拟合函数
θ
\theta
θ,来把样本
x
i
t
r
x^{tr}_i
xitr拟合到语义空间,并且在拟合空间的表示和它的类别描述信息的表示
t
i
t
r
t^{tr}_i
titr相似。 然后在测试阶段,对于每个测试样本
x
i
u
x^{u}_i
xiu,通过拟合函数
θ
\theta
θ拟合到语义空间,并找离它最近的类别描述信息所对应的类别做为它的类别(1NN)。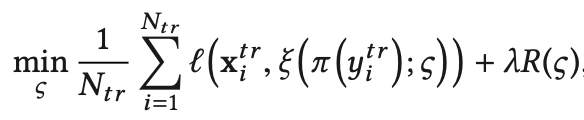 损失函数的主要思想和语义空间做拟合空间一样,这里不再赘述。把特征空间做拟合空间缓解了枢纽度问题。
损失函数的主要思想和语义空间做拟合空间一样,这里不再赘述。把特征空间做拟合空间缓解了枢纽度问题。【本文地址】