零样本文本分类论文(一) |
您所在的位置:网站首页 › 零样本分类问题有哪些 › 零样本文本分类论文(一) |
零样本文本分类论文(一)
|
semantic knowledge word embeddings, class descriptions, class hierarchy, knowledge graph datasets Yahoo Topic detection Unify Emotion Emotion detection Situation Typing Situation detection DBpedia 20newsgroups CUB Zero-Shot Classification with Discriminative Semantic Representation Learningthree method visual feature projection methods:将实例投影到相同的语义空间,作为prototype label vectors,然后与unseen的类的原型进行相似度对比。 semantic similarity matching methods:训练分类器的时候与传统的分类方法是一样的,使用已训练的分类器进行预测,最终使用每对seen和unseen的分类器之间的相似度来获取在unseen类上的预测分数。 sparse coding method:是上述两种方法的综合,利用稀疏编码技术将实例转换为标签embedding空间,同时将每个测试实例分配到具有最接近语义embedding的unseen类中。 \[\begin{aligned} & input: X^s\in \mathcal{R}^{n_s\times d},X^u\in\mathcal{R}^{n_u\times d}, X=[X^s,X^u]\in \mathcal R^{K\times m} \\ & seen \ classes: Y^s= \{ 1,2,\dots, K^s \},Y_s\in \{ 0,1 \}^{n_s\times K}\\ & unseen \ classes: Y^u= \{ K^s+1, \dots,K \},K=K^s+K^u\\ & label\ representation\ matrix:M\in \mathcal R^{K\times m} \end{aligned}\]从可见类和不可见类中同时学习中间表示,对\(X\)使用稀疏NMF(非负矩阵分解): \(\begin{aligned} & \min_{Z\ge0,\Phi\ge0}\frac{1}{2}\| X-Z\Phi \|^2_F+\mu\|\Phi\|_1+\rho\|Z\|_1\\ & \Phi\in \mathcal R^{a\times d},Z\in\mathcal R^{n\times a},a=m+b \end{aligned}\) \(\Phi\)是因子矩阵,里面的参数应该与描述类标签的属性有关;\(m\)是与标签属性相关的项,\(b\)是隐属性。在图片上使用稀疏NMF比一般NMF更好。使用稀疏NMF可以将图像映射到与标签原型向量相同的语义空间中的潜在表示向量中。 \(B=[I_m;0_{d,m}]\) \(B\)作为列选择矩阵,\(ZB(n \times m)\)就是\(Z\)中每一行\(m\)个与标签属性相关的值组成的向量,利用\(ZB\)与\(M\)中的语义原型向量对齐。 semi-supervised sparse NMF: \(\begin{aligned} & \min_{Z\ge 0,\Phi \ge 0}\frac{1}{2}\Vert X-Z\Phi\Vert^2_F+\gamma\sum_{i=1}^{n_s}\xi_i+\mu\Vert\Phi\Vert_1+\rho\Vert Z\Vert_1\\ & alignment\ hinge\ loss: \xi_i=\max_{k\in y_s}(\Delta(Y_i1_k=0)-\Vert Z_iB-M_k\Vert^2+\Vert Z_iB-Y_i^sM\Vert^2)_+ \end{aligned}\) Zero-shot Text Classification via Reinforced Self-training零样本分类的问题:在可见标签向不可见迁移的时候,有时候可能可见标签内没有可以与不可见标签相似的。以情感分类为例,“sadness”和“joy”就是两个差的很远的词语,假设一个数据集里面都是“sadness”,需要分类的目标是“joy”,显然想要正确分类是困难的。从可见类转移到不可见类是非常困难的,因为匹配类之间由共享的特征是很稀少的情况。
ZSL是建立一个从特征空间到语义空间的映射,在文本分类领域就是文本(特征空间)与标签(语义空间)。文本和标签的模式匹配可以粗分为两类,类不变模式(class-invariant patterns)和特定类模式(class-specific ones)。前者认为不同的类之间共享模式,后者认为模式依托于特定的类。
上图中,红色高亮部分表示一个简单的可以在类之间共享的模式匹配,蓝色高亮部分表示一个无法在类间简单传递的模式匹配。 主要有两个方法来解决零样本学习问题: 使用更多额外的知识来描述类并且构建更复杂的类间的联系 聚集无标签的数据去提高泛化能力。本文聚焦于后一种方法,使用自学习方法来做ZSL。直观地理解,用上图举的例子来讲,如果把句子2加入了训练集中,那么模型就有能力区分句子3。这样,就可以通过类不变特征来挖掘类特定特征。 传统的自学习方法有以下问题: 传统的自训练方法使用人工设计的启发式方法来选择数据,人工调整选择策略的成本很高。 由于严重的域偏移(domain shift),传统的自我训练方法可能不能提供可靠的选择。自学习:迭代的从无标签数据中去找高置信的数据并且把这些“伪”数据放到训练集。自学习方法有以下缺陷: 其数据选择策略是简单的基于置信度的,可能无法提供可靠的选择,并导致误差积累。 自训练依赖于预定义的置信度阈值,而置信度阈值随数据集的变化而变化,人工调整代价较大。数据选择的强化学习 通过Deep Q-Network学习一种提高模型效果的数据选择能力 对于ZSL问题的定义 \(\mathcal{Y}^s\)为可见类,\(\mathcal{Y}^u\)为不可见类,\(\mathcal Y^s\cap\mathcal Y^u=\varnothing,\mathcal Y^s\cup\mathcal Y^u=\mathcal Y\)。 可见类\(\mathcal D^s= \{ (x_i^s,y_i^s \}_{i=1}^N\),不可见类\(\mathcal D^u= \{ (x_i^u,y_i^u \}_{i=1}^N\),\(x_i\)是第\(i\)个文本,\(y_i\)是对应的标签。如图1所示,ZSL模型将分类问题转换成了一个匹配问题,从可见类\(\mathcal D^s\)中学习匹配模型\(f(x,y;\theta)\),然后在不可见类上预测分类: \(\hat{y}=\arg \max_{y\in\mathcal Y}f(x,y;\theta)\) \(\mathcal D^s,\mathcal D^u\)都可以在训练过程使用。
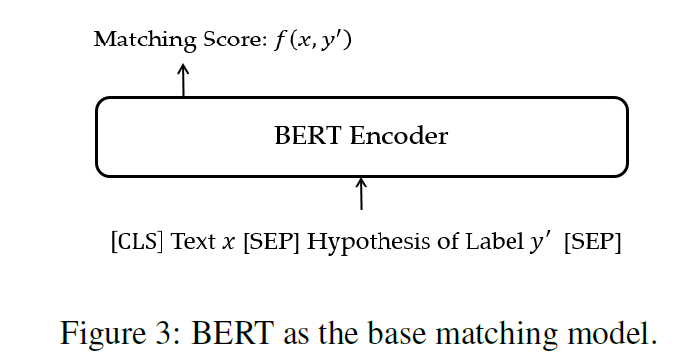
使用BERT作为base matching model。对于可见类,给定文本\(x\)和标签\(y\),生成\(\{ (x,y^{\prime})\vert y^{\prime}\in \mathcal Y^s \}\)作为训练样本,其中如果\(y=y^{\prime}\),则将\((x,y^{\prime})\)作为positive的训练样本。 input:\([{\rm CLS}]\ x[{\rm SEP}]\ {\rm hypotheis\ of} \ y^{\prime}\ [{\rm SEP}]\),使用\([\rm CLS]\)的隐向量\(C_{x,y^{\prime}}\in\R^H\)作为结果表示,新增一个线性层并计算损失函数: \(p_{x,y^{\prime}}=\sigma(W^Tc_{x,y^{\prime}}+b),\\ L=\left\{ \begin{aligned} & -\log(p_{x,y{\prime}}) & y^{\prime}=y \\ & -\log(1-p_{x,y{\prime}}) & y^{\prime}\neq y \end{aligned} \right.\)
State:对于每个文本\(x\),得到一个预测分数\(\{ p_{x,y^{\prime}} \in \mathcal Y^u\}\),将最大匹配分数的\(y^*\)作为伪标签。对于每个时间步\(t\),当前状态\(s_t\)包含两个部分:预测置信度\(p_{x,y^*}\)和实例表示\(c_{x,y^*}\),使用决策网络将\(p_{x,y^*},c_{x,y^*}\)作为输入来输出选择该伪标签的概率。 Action:智能体(agent)需要决定是否选取\((x,y^*)\)加入训练库。每个时间步\(t\)中,\(a_t=1\)代表智能体接受当前生成实例,并把它加入到训练集;\(a_t=0\)代表拒绝。值由\(P(a\vert s_t)\)采样得出。 Reward:如果将错误标注的例子添加到训练集合,会降低匹配模型的表现效果,因此,reward的作用是引导智能体选择与训练集一致的实例。reward由匹配模型再验证集上的表现决定,验证集包含两个部分:可见验证集\(D^s_{dev}\)和不可见验证集\(D^u_{dev}\),不可见验证集由伪标签数据产生,来引导新选择的数据与之前选择的数据保持一致。更具体地说,在每批选择之后,使用所选实例训练匹配模型并在验证集上面评估。使用macro-F1作为评估度量。假设每个episode里有\(N_3\)个batch,可见数据集:\(F^s=\{ F_1^s,F_2^s,\dots,F_{N_3}^s \}\),不可见数据集:\(F^u=\{ F_1^u,F_2^u,\dots,F_{N_3}^u \}\)。对batch\(k\),reward式子为:\(r_k=\frac{F_k^s-\mu^s}{\sigma^s}+\lambda\cdot\frac{F_k^u-\mu^u}{\sigma^u}\) episode是强化学习里面agent执行某个策略从开始到结束这一过程。 Policy Network使用一个多层感知机作为决策网络。接受状态:预测置信度\(p_{x,y^*}\)和实例表示\(c_{x,y^*}\),然后输出每一步action的概率: \(z_t=ReLU(W_1^Tc_{x,y^*}+W_2^Tp_{x,y^*}+b_1)\\ P(a\vert s_t)=softmax(W_3^Tz_t+b2)\) Optimization优化的目标是最大化同reward的期望 总reward的期望定义为: \(J(\phi)=E_{P_\phi(a\vert s)}[R(s,a)]\) 其中,\(R[s,a]\)是tate-action价值函数,\(\phi\)是决策网络的参数,使用policy gradient更新\(\phi\): \(\phi\leftarrow\phi+\eta\bigtriangledown_\phi\tilde{J}(\phi)\) 通过\(P_\phi(a\vert s)\)对每一个状态\(s_t\)取样一个状态\(a_t\)。每个episode结束后,计算reward\(\{ r_k \}_{k=1}^{N_3}\),梯度通过下式近似: \(\bigtriangledown_\phi\tilde{J}(\phi)=\frac{r_k}{\vert B_k\vert}\sum_{t=1}^{\vert B_k\vert}\bigtriangledown_\phi logP(a_t\vert s_t)\) 其中,\(\vert B_k\vert\)是一个batch里面实例的个数,\(r_k\)是\(B_k\)的reward。
每一代: 使用\(D_s\)和\(D_p\)训练匹配模型\(f\);在\(D_u\)上预测,得到置信度\(P\),根据\(P\)排名得到\(D_u\)的子集\(\Omega\); 每个episode: 满足提前终止条件则终止 将\(\Omega\)洗牌为多个Batch; 每个batch: 从\(\Omega\)获得batch\(B_k\);决定\(B_k\)中每个实例的action,得到所选的实例\(B_k^p\);用\(B_k^p\)训练模型\(f^{\prime}\);在\(D_{dev}^s\)和\(D_{dev}^u\)上评估;得到\(F_k^s,F_k^u;\) 计算\(r_K\); 更新决策网络; 更新参数 Dataset情感数据集(Yin et al. 2019) 除了上面的情感分类的数据集,在真实情景(电商平台)下,\(\mathcal Y^s\)包含用户搜索后点击的产品分类,\(\mathcal Y^u\)包含预先定义的用户偏好类别。
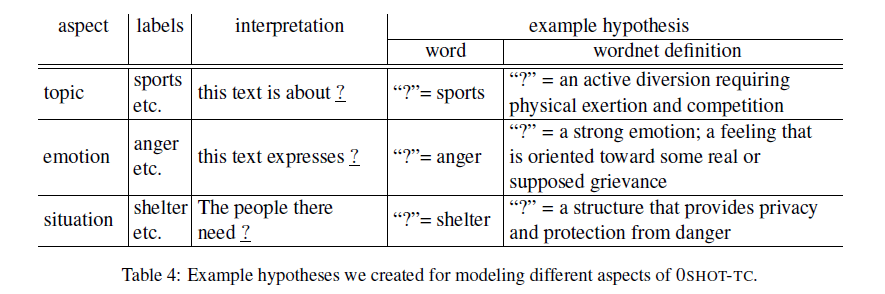
建模的局限性 多数研究只对单一任务进行了探索,主要是主题分类,这只是ZSL的冰山一角。 经常有一个前提条件,可以看到类的一部分然后再训练时这些可见类作为训练的一部分,这个条件定义为Definition-Restrictive。 Definition-Restrictive: 给定可见类的实例\(S\),ZSL的目标是学习一个分类器\(f(\cdot):X\rightarrow Y,Y=S\cup U\) Definition-Wild 不给定任何可见的类,学习一个分类器\(f(\cdot)\):\(X\rightarrow Y\) 标签的局限性 传统的文本分类将标签记为\(\{ 0,1,2,\cdots,n \}\),既没有对于标签角度(如情感、主题等)的解释,也没有赋予标签意义。这在ZSL中是做不到的, 因为既不能预先定义标签空间的大小,也不能预先知道有标签数据的可用性。ZSL的终极目标应该是可以跟上人类的能力:人类可以很容易地判断标签的正确性,因为人类可以正确地解释这些方面并理解这些标签的含义。 数据集的混乱 在之前学者的研究者,往往会使用的不同的数据集进行模型性能的衡量,由此带来的问题是不能公平的去比较不同模型之间的性能。 Benchmark the datasetTopic detection Yahoo Emotion detection Unify Emotion Situation detection Situation Typing Benchmark the evaluationLabel-partially-unseen 现有的大部分ZSL使用的方法,对数据集中的部分数据进行训练,然后在整个数据集上进行评估,通常所有的标签都描述了文本的某个方面(如情感、主题等)。 Label-fully-unseen 对于零样本学习的更广泛的定义,无论先前采用什么样的训练方法,最终都在开放的数据集上进行测试(例如对于规则的学习),这样的学习过程更像人类学习的过程。 entailment model将ZSL-TC作为一个文本蕴含的任务,基于以下几个理由: 文本分类本质上就是个文本蕴含问题。正如人类做文本分类时的思路“这篇文章有关体育吗?/这篇文章是否表现出来特定的情感倾向?”传统文本分类没有采用蕴含方法的原因是它总是有预定义的、固定大小的类,这些类有带注释的数据。既不能估计要处理多少类和哪些类,也不能使用带注释的数据来训练特定类的参数。文本蕴含不知道假设(hypothesis)空间的边界。 为了追求分类器的理想泛化能力,需要确保分类器理解了对于特定方面的编码和标签的意义。传统的监督分类器在这方面失败了,因为标签名称被转换成索引——这意味着分类器不能真正理解标签,更不用说问题了。因此,探索ZSL如何作为文本蕴含范式是一个解决问题的途径。labels to hypothesis 为了解决ZSL问题的第一步是将标签转换为假设空间。首先,将每个方面(aspect)转换为一种解释(interpretation)
classification data to entailment data 对于每个数据集的数据分割(train,dev,test),每个输入的文本都会作为一个前提(premise),对于pos的标签有一个pos的假设,对于每个neg的标签会有一个neg的假设。另外,不可见标签不会在训练时提供neg假设的实例。 entailment model learning 使用Bert等来预训练文本蕴含任务(在MNLI/FEVER/RTE数据集) harsh policy in testing 因为可见标签有标注数据用来训练,所以采取不同的策略来选取可见和不可见的标签。在选取可见标签的时候,使用一种更严格的规则: 在单标签的分类中,如果可见标签和不可见标签都被预测为pos,当且仅当可见标签的pos概率比不可见概率高\(\alpha\)时,选择可见标签;如果只有可见或不可见的标签被预测为pos,选择概率最高的那个。 在多标签分类中,如果可见和不可见的标签都预测为pos,如果可见标签的pos概率比不可见概率高不超过\(\alpha\)时,将可见标签改为neg。最终选取所有的pos标签的数据,如果没有pos标签,选择“none”。 hypothesis influence 通过本文的实验,发现: 无论使用哪一个预先训练的蕴含模型,单独使用definition通常不能很好地工作。 单独使用“word”还是“word&definition”的效果哪个更好,取决于具体的任务和预先训练的蕴含模型。 对于开放域零样本文本分类任务来说,只采用一种蕴含模型是不现实的,最好使用一种集成系统。 Using Semantic Similarity for Multi-Label Zero-Shot Classification of Text Documents(2016)对于一个文本\(\mathbf x_i\),从一个词表中以一系列词语的形式给出\(,w_i^j\in\mathcal V=\{ 1,2,\dots,\vert \mathcal V \vert \}\)。假设每个标签类型\(l\in\mathcal Y\)由一系列词语来命名\(\lambda_l=\) Similarity-Based Zero-Shot PredictionLabel Presence 一个严苛的条件是文本中出现的词语正好与标签有一一对应的关系:\(=\) Label Word Similarity 放宽上述严苛的条件,对于以下式子成立的话,就可以认为是标签与文本匹配: \(t\le \max_{1\le c\le c_{max}}\max_{1\le j\le\vert\mathbf x_i \vert-c}\sigma(,)\) \(c\)是一个参数,当\(c_{max}=\vert\lambda_l\vert,t=1,\sigma(\mathbf w_1,\mathbf w_2) =1 \ if \ \mathbf w_1=\mathbf w_2\ otherwise \ 0\)时,与label presence条件一致。 用余弦相似度:\(\sigma(w_1,w_2)=\frac{vec(\mathbf w_1)^T\cdot vec(\mathbf w_2)}{\Vert vec(\mathbf w_2)\Vert\cdot \Vert vec(\mathbf w_2)\Vert}\) Integrating Semantic Knowledge to Tackle Zero-shot Text Classification(2019)包含数据增强和特征增强的两步框架,在该框架中引入了四种语义知识(词嵌入、类描述、类层次结构和一般知识图),有效地处理不可见类的实例。 有三种主要的语义知识用于ZSL的情景: 最广泛使用的是类的语义属性(semantic attributes),例如视觉角度(颜色、形状等)和语义特征(行为、功能等) 第二类是概念本体,包括类层次和知识图,表示类和特征之间的关系 第三类是语义词嵌入,从大规模训练文本语料中捕获的词语之间的隐式关系然而,对于ZSL在文本分类中的应用,利用其中一种知识类型的研究很少,也没有考虑它们的组合。
第一阶段是粗粒度的文本分类,判断文本是来自可见类还是不可见类;第二阶段是细粒度的文本分类,最终决定文本所属分类。(所有的分类器都通过有标签数据训练,并且训练中不会看到不可见标签) 本文的主要贡献: 提出了一种包含粗粒度和细粒度文本的零样本文本分类方法。与之前的方法不同,本文采取的方法不需要类之间具有语义对应关系,换句话说,可见类和不可见类之间可以完全不同。 提出了一种新的数据增强技术:主题转换(topic translation)去强化模型高效地检测不可见类中文本的能力。 提出了一种使用集聚语义知识(integrated semantic knowledge)去将在可见类中学习到的知识迁移到不可见类的方法。 Methodology\({\mathcal C_S}\)和\({\mathcal C_U}\)分别可见类和不可见类。在学习阶段,\(\{ (x_1,y_1),\dots,(x_n,y_n) \}\)中\(x_i\)是第\(i\)个文本,其中包含一系列词语\([w_1^i,w_2^i,\dots,w_t^i]\),\(y_i\in{\mathcal C_S}\)是\(x_i\)的类。在推理阶段,目的是去预测每个文本所属的类,\(\hat{y_i}\),使用数据同样来自\({\mathcal C_S\cup C_U}\),但是类与训练集完全不同。
文本\(x_i\)的词嵌入:\(v_w^i=[v_{w1}^i,v_{w2}^i,\dots,v_{wt}^i]\) 标签的词嵌入:\(v_c,\forall c\in{\mathcal C_S\cup C_U}\) 特征增强:\(v_{w_j,c}^i\)表示词语\(w_j\)与类\(c\)之间的紧密程度(通过语义知识),可以通过一系列向量表示\(x_i\)与\(c\)之间的关系:\(v_{w,c}^i=[v_{w_1,c}^i,v_{w_2,c}^i,\dots,v_{w_t,c}^i]\) 粗粒度分类给定一个文本\(x_i\),阶段一使用了一个二分类去判断\(\hat{y_i}\in{\mathcal C_S}/\hat{y_i}\notin {\mathcal C_S}\),对于每个\(c_s\in{\mathcal C_S}\)都有一个CNN分类器去预测\(x_i\)来自类\(c_s\)的置信度。粗粒度分类器使用\(v_w^i\)作为输入并且使用一个二元交叉熵损失作为损失函数训练,训练的pos样本为可见类,其余为neg样本。 对每一个测试文本\(x_i\),这一步对所有的\(c_s\in{\mathcal C_S}\)计算\(p(\hat{y_i}=c_s\vert x_i)\),\(\exist c_s\ p(\hat{y_i}=c_s\vert x_i)>\tau_s \to\hat{y_i}\in{\mathcal C_S};otherwise\ \hat{y_i}\notin {\mathcal C_S}\) 数据增强 在学习阶段,阶段一的分类器仅从可见类中获得neg样本,这可能导致无法区分不可见类中的pos样本。通过使用数据增强将它们引入分类器中来学习排除来源于不可见类的实例。通过使用类比将文档从原来的可见类转换为新的可见类来实现数据增强。 在词语级别,将类\(c\)中词语\(w\)转换为类\(c^\prime\)中的词语\(w^\prime\):\(c:w::c^\prime:?\),例如“\(company:firm::village:?\)”,此处通过词嵌入可以知道”?”处是\(hamlet\)。在算法中,只对名词、动词、形容词和副词进行转换。使用3CosMul方法来寻找\(w^\prime\):
\(W^\prime=\arg\max_{x\in V}\frac{cos(x,c^\prime)cos(x,w)}{cos(x,c)+\epsilon}\)
对于可见标签的样本使用CNN分类器,对于不可见标签的样本使用零样本分类器(也是CNN分类器)。 传统的分类器和零样本分类器具有相同的跟着两层全链接层的基于CNN的结构,但是输入输出是不同的。传统的分类器使用softmax作为输出,只需要词嵌入\(v_w^i\)作为输入。分类器使用可见类的数据进行训练,使用交叉熵损失。 零样本分类器是一个使用sigmoid作为输出的二分类分类器。使用文本\(x_i\)和类\(c\)作为输入并且预测置信度\(p(\hat{y}_i=c\vert x_i)\),在实际操作时,使用\(v_w^i\)来代替\(x_i\),\(v_c\)来代替类\(c\),使用增强特征\(v_{w,c}^i\)来提供额外信息。对于每个词语,使用三个向量作为输入\(v_{w_j}^i;v_c;v_{w_j,c}^i\)作为输入。使用可见数据进行训练并在不可见数据集上测试 。 特征加强 \(v_{w_j,c}\)包含了输入零样本分类器的增强特征信息。本文使用ConceptNet网络来进行特征增强,概念网中的节点是单词或短语,而连接两个节点的边显示了它们在句法或语义上的联系。 ConceptNet包含了三种节点的集合:(1) educational institution, educational, institution(2) organization, agent(3) place, people, ages, education. \(v_{w_j,c}\)表示了\(w_j\)在\(K\)跳之内能否可以根据特定关系(RelatedTo, IsA, PartOf, andAtLocation)来连接到集合中的词语。对三个集合中的每个,建立了\(3K+1\)维度的向量:
\([^\alpha3k+1,^\beta3k+2,^\gamma3k+3]\),\(\alpha\):集合中是否有最短路径到\(w_j\);\(\beta\):到\(w_j\)最短路径为\(k+1\)的节点个数;\(\gamma\):\(\beta\)占集合总节点数的占比。 An Empirical Study on Large-Scale Multi-Label Text Classification Including Few and Zero-Shot Labels |




 初始化伪标签数据\(D_p\)
初始化伪标签数据\(D_p\)





【本文地址】
今日新闻 |
推荐新闻 |