光谱特征选择 |
您所在的位置:网站首页 › 随机筛选公式是什么 › 光谱特征选择 |
光谱特征选择
|
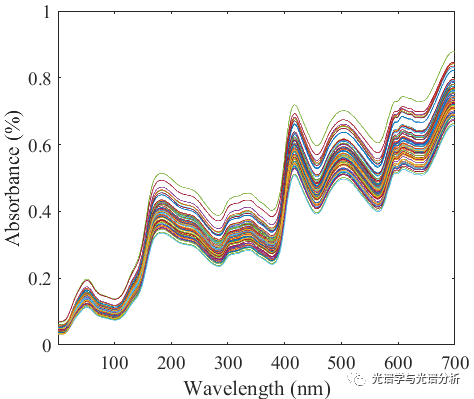
我们已经连续好几期在讲特征变量选择算法,这其中一个很重要的一个原因是:光谱数据的高维冗余性和目标值与少数解释变量之间的相关性,也就是特征解释问题。如何从实际测量的高维光谱数据中选择具有解释能力(特征变量)的变量是目前特征选择或者特征降维的主要研究内容,也是光谱分析建模的关键组成。 本期分享的随机蛙跳(Random Frog, RF)主要参考李宏东老师于2012年发表在ACA的论文(题目见文末),区别于由Kevin Lanes和Mustafa Eusuff于2003年提出的随机蛙跳算法(Shuffled Frog Leaping Algorithm, SFLA),RF迭代更新过程更加简单直观,而SFLA粒子群优化算法相似,本期就RF在光谱特征分析建模中的应用进行介绍,并以真实数据进行代码解析和结果展示,对于代码在光谱交流群内。 1. 随机蛙跳RF 作者原文以基因表达过程中的关键变量选择为背景提出了RF算法,结合光谱建模分析应用,我们首先介绍RF的基本原理。对于光谱变量X,其n行表示样本数,p列表示变量,对应的目标矩阵Y由nx1的变量组成,其迭代计算过程主要包括以下三步: (1)随机生成包含Q个变量的子集V0; (2)在V0的基础上提出一个包含Q*个变量的候选变量子集V*,以一定的概率接受V*作为V1,用V1代替V0,循环该过程; (3)计算各个变量选择的概率值,以此作为变量重要性评价指标。 在RF算法计算过程中,主要涉及5个关键参数,分别是: (1)N:迭代次数,一般根据数据规模设置; (2)Q:初始数据子集所含变量数; (3) (4)w:用于重采样时调整变量个数; (5) 上述变量中,除了Q和N外,其余变量均设置为默认值,此外,变量的重要性不再是单纯的以回归系数的大小为依据,而是以N次迭代中变量出现的概率为依据。 2. 代码分析 RF的matlab调用如下所示: function F=randomfrog_pls(X,Y,A,method,N,Q,criterion)%+++ Random Frog for variable selection for high dimensional data.%+++ Input: X: m x n (Sample matrix)% Y: m x 1 (measured property)% A: The maximal number of latent variables for% cross-validation% method: data pretreat method,'center' or 'autoscaling'% N: The number of Simulation.% Q: Intial number of variables to sample%+++ Criterion: index for variable assessment:'RegCoef',or 'sr'%+++ Output: Structural data: F输出的结构体F包含的主要变量有: F.N=N; %迭代次数F.Q=Q0; %子集变量数F.model=model; %模型参数,此处选PLSF.minutes=toc/60; %计算时间/SF.method=method; %预处理方法F.Vrank=Vrank; %变量序号F.Vtop10=Vtop10; % top-10 变量F.probability=probability; % 各变量被选概率F.nVar=nVar; %迭代建模过程中子集变量个数F.RMSEP=RMSEP; %迭代模型RMSEP3. 实例分析 本文以公开数据集Corn进行测试分析,对应下载链接已在前期中给出,原始光谱为:
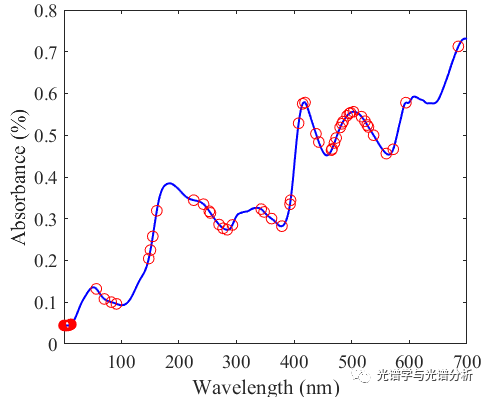
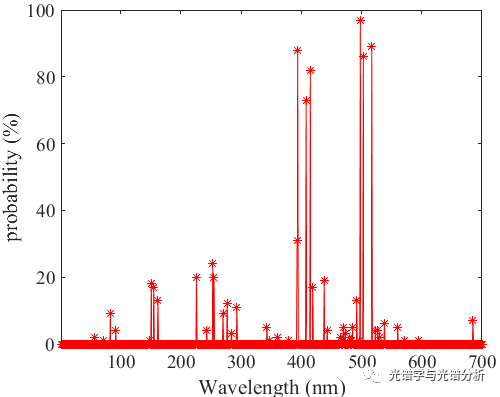
基于RF算法,我们选择前60个变量,具体的分布如图所示,其中有部分点分布在起始点附近,而大部分分布在500左右,对于起始点附近的点,可能是我们子集变量个数设置过小,导致这些变量的选择概率较高。
各变量在100次迭代循环过程中的选择概率分布如下图所示,对应上图,我们可以看到选择概率大于0的个数较少,而且分布相对集中,对于上图所选前60变量过多,可能需要多次交叉验证才能确定最佳的特征变量个数。
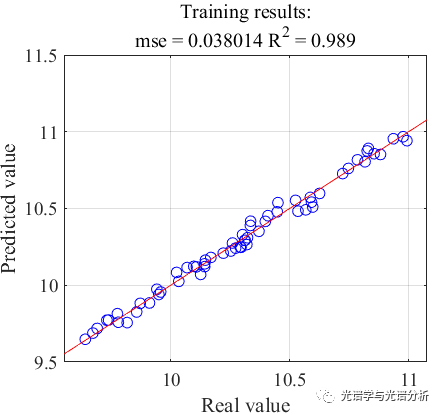
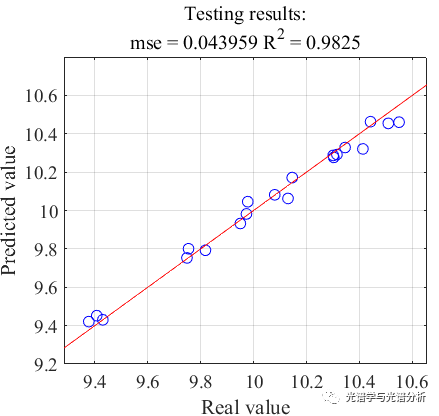
基于所选变量所建模型的PLS预测结果如下所示,可知预测结果精度较高,能够实现目标指标的有效预测。
对比发现,RF算法能够有效选择光谱特征变量,其基本分析过程跟iPLS相似,区别在于区间的可变性和变量的随机选择性,也正是这种过程产生了变量的竞争选择机制,进而确保了变量的有效性。 至此,我们简要介绍了RF算法并应用实例数据进行了分析,下期会介绍区间随机蛙跳iRF算法,欢迎大家交流分析,有需要的可通过私信公众号加入光谱交流群。 |
【本文地址】
今日新闻 |
推荐新闻 |