机器学习中randomforest随机森林调参影响参数 |
您所在的位置:网站首页 › 随机森林的参数设置 › 机器学习中randomforest随机森林调参影响参数 |
机器学习中randomforest随机森林调参影响参数
|
随机森林调参的影响参数
对结果影响较大的参数 1.n_estimators:表示森林里树的个数。 理论上是越大越好,但是计算时间也相应增长。所以,并不是取得越大就会越好,预测效果最好的将会出现在合理的树个数。当使用的训练特征值增多时,经研究n_estimators也应增大以保证训练结果为最佳。 通常为100到1000 2.max_features:每个决策树的随机选择的特征数目。 每个决策树在随机选择的这max_features特征里找到某个“最佳”特征,使得模型在该特征的某个值上分裂之后得到的收益最大化。max_features越少,方差就会减少,但同时偏差就会增加。 如果是回归问题,则max_features=n_features,如果是分类问题,则max_features=sqrt(n_features),其中,n_features 是输入特征数。 默认为auto,通常不用调整 3.max_depth: 树的最深深度。 如果max_depth=None,节点会拟合到增益为0,或者所有的叶节点含有小于min_samples_split个样本。如果同时min_sample_split=1, 决策树会拟合得很深,甚至会过拟合。 下面是一段用sklearn包以网格搜索GridSearchCV调参的方法,通过将max_depth,n_estimators一同 import pandas as pd from sklearn.ensemble import RandomForestRegressor from sklearn.model_selection import GridSearchCV, train_test_split from application import logger from application.utils import ModelScoreUtil def train(X_data, y_data): # 数据拆分: 训练集、测试集 X_train, X_test, y_train, y_test = train_test_split(X_data, y_data, test_size=0.2, random_state=42) # 创建模型并寻参 model = GridSearchCV( estimator=RandomForestRegressor(), param_grid={ 'max_depth': range(20,50,5), 'n_estimators':range(500,1000,100) }, verbose=4, n_jobs=4, ) # logger.info(f"训练模型:开始") model.fit(X_train, y_train) logger.info(f"训练模型:完成") # model_score_check_result = ModelScoreUtil.check(model=model, X_test=X_test, y_test=y_test) logger.info(f"模型评分结果: \n {pd.DataFrame([model_score_check_result])}") # 返回数据 return { "model": model, "best_param": model.best_params_, "model_score_check_result": model_score_check_result } pass if __name__ == '__main__': pass下面是用rf训练模型的结果 |
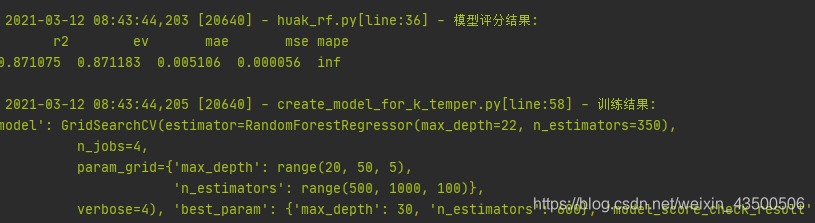 看到选取的最佳匹配值为max_depth: 30, n_estimators: 600
看到选取的最佳匹配值为max_depth: 30, n_estimators: 600【本文地址】
今日新闻 |
推荐新闻 |