岭回归、Lasso回归、logistic回归模型、决策树、随机森林与K近邻模型 |
您所在的位置:网站首页 › 随机森林和XGBoost区别 › 岭回归、Lasso回归、logistic回归模型、决策树、随机森林与K近邻模型 |
岭回归、Lasso回归、logistic回归模型、决策树、随机森林与K近邻模型
|
模型的假设检验(F与T)
F检验
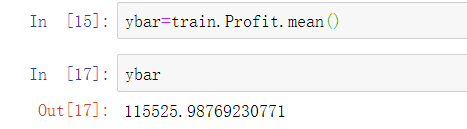
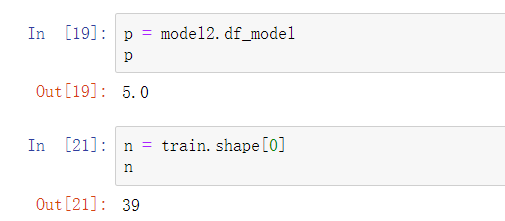
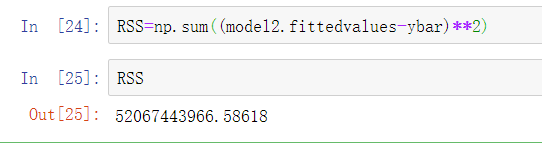
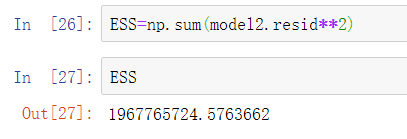
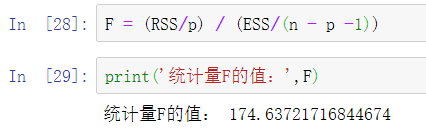
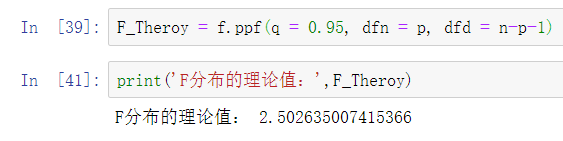
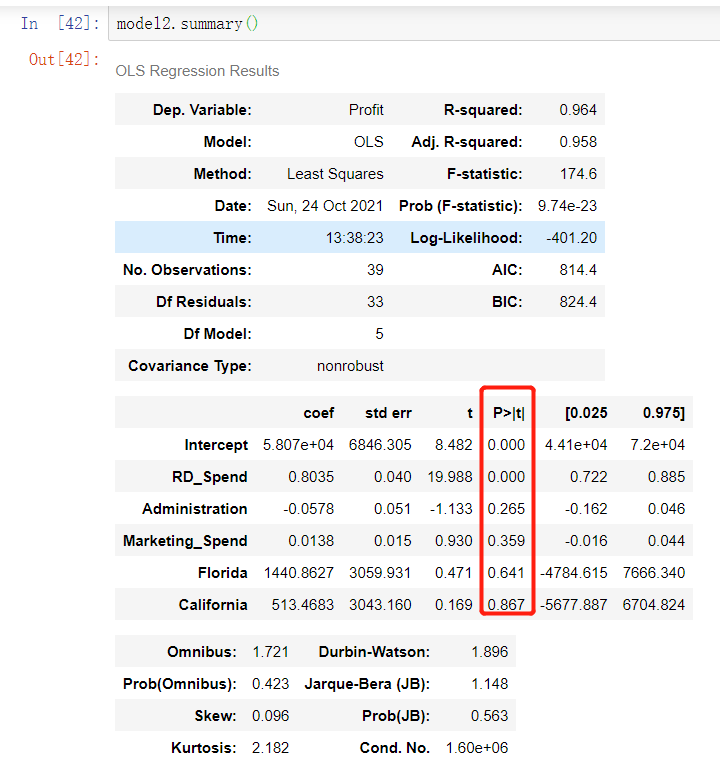
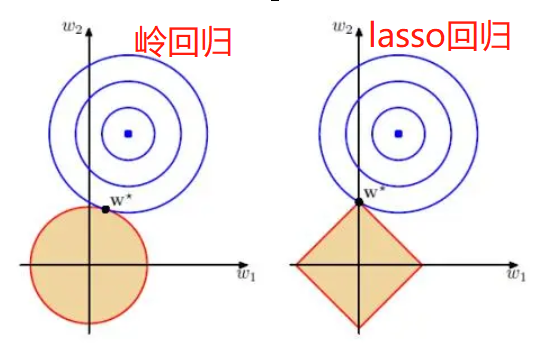
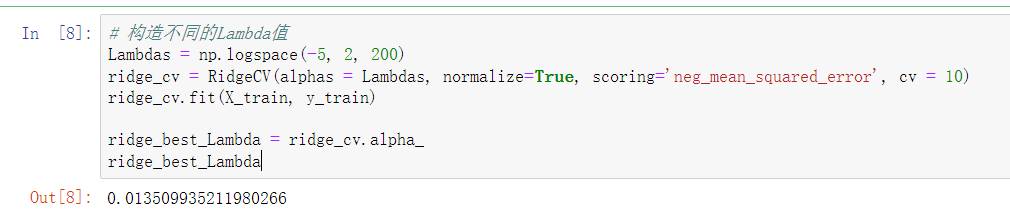
提出原假设和备用假设,之后计算统计量与理论值,最后进行比较。 F校验主要检验的是模型是否合理。 导入第三方模块 import numpy as np import pandas as pd from sklearn import model_selection import statsmodels.api as sm # 数据处理 Profit = pd.read_excel(r'Predict to Profit.xlsx') dummies = pd.get_dummies(Profit.State) Profit_New = pd.concat([Profit,dummies], axis = 1) Profit_New.drop(labels = ['State','New York'], axis = 1, inplace = True) train, test = model_selection.train_test_split(Profit_New, test_size = 0.2, random_state=1234) model2 = sm.formula.ols('Profit~RD_Spend+Administration+Marketing_Spend+Florida+California', data = train).fit() 统计变量个和观测个数 ybar=train.Profian() 统计变量个数和观察个数 p=model2.df_model n=train.shape[0] 计算回归离差平方和 RSS=np.sum((model2.fittedvalues-ybar)**2) 计算误差平方和 ESS=np.sum(model2.resid**2) 计算F统计量的值 F=(RSS/p)/(ESS/(n-p-1)) print('F统计量的值:',F) 计算F分布的理论值 from scipy.stats import f # 计算F分布的理论值 F_Theroy = f.ppf(q=0.95, dfn = p,dfd = n-p-1) print('F分布的理论值为:',F_Theroy) 结论: 可以看到计算出来的F统计值(174.6)远远大于F分布的理论值(2.5),所以应该拒绝原假设。 T检验 T检验更加侧重于检验模型的各个参数是否合理。 model.summary() # 绝对值越小影响越大 线性回归模型的短板 自变量的个数大于样本量 自变量之间存在多重共线性 解决线性回归模型的短板 岭回归模型 在线性回归模型的基础之上添加一个l2惩罚项(平方项、正则项),该模型最终转变成求解圆柱体与椭圆抛物线的焦点问题。 Lasso回归模型 在线性回归模型的基础之上添加一个l1惩罚项(绝对值项、正则项) 相较于岭回归降低了模型的复杂度,该模型最终转变成求解正方体与椭圆抛物线的焦点问题。 交叉验证 将所有数据都参与到模型的构建和测试中 最后生成多个模型,再从多个模型中筛选出得分最高(准确度)的模型。 岭回归模型的交叉验证 数据准备 # 导入第三方模块 import pandas as pd import numpy as np from sklearn import model_selection from sklearn.linear_model import Ridge,RidgeCV import matplotlib.pyplot as plt # 读取糖尿病数据集 diabetes = pd.read_excel(r'diabetes.xlsx', sep = '') # 构造自变量(剔除患者性别、年龄和因变量) predictors = diabetes.columns[2:-1] # 将数据集拆分为训练集和测试集 X_train, X_test, y_train, y_test = model_selection.train_test_split(diabetes[predictors], diabetes['Y'], test_size = 0.2, random_state = 1234 ) 获得lambda数值 # 构造不同的Lambda值 Lambdas = np.logspace(-5, 2, 200) # 岭回归模型的交叉验证 # 设置交叉验证的参数,对于每一个Lambda值,都执行10重交叉验证 ridge_cv = RidgeCV(alphas = Lambdas, normalize=True, scoring='neg_mean_squared_error', cv = 10) # 模型拟合 ridge_cv.fit(X_train, y_train) # 返回最佳的lambda值 ridge_best_Lambda = ridge_cv.alpha_ ridge_best_Lambda
预测 # 导入第三方包中的函数 from sklearn.metrics import mean_squared_error # 基于最佳的Lambda值建模 ridge = Ridge(alpha = ridge_best_Lambda, normalize=True) ridge.fit(X_train, y_train) # 返回岭回归系数 pd.Series(index = ['Intercept'] + X_train.columns.tolist(),data = [ridge.intercept_] + ridge.coef_.tolist()) # 预测 ridge_predict = ridge.predict(X_test) # 预测效果验证 RMSE = np.sqrt(mean_squared_error(y_test,ridge_predict)) RMSE
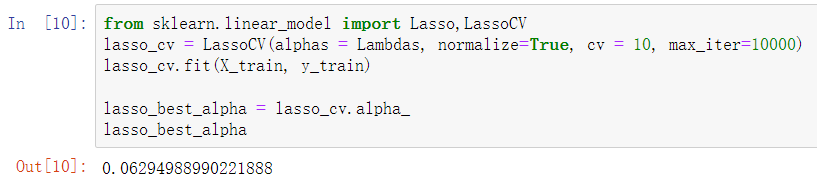
lasso回归模型交叉验证 获取lambda值 # 导入第三方模块中的函数 from sklearn.linear_model import Lasso,LassoCV # LASSO回归模型的交叉验证 lasso_cv = LassoCV(alphas = Lambdas, normalize=True, cv = 10, max_iter=10000) lasso_cv.fit(X_train, y_train) # 输出最佳的lambda值 lasso_best_alpha = lasso_cv.alpha_ lasso_best_alpha 建模并预测 # 基于最佳的lambda值建模 lasso = Lasso(alpha = lasso_best_alpha, normalize=True, max_iter=10000) lasso.fit(X_train, y_train) # 返回LASSO回归的系数 pd.Series(index = ['Intercept'] + X_train.columns.tolist(),data = [lasso.intercept_] + lasso.coef_.tolist()) # 预测 lasso_predict = lasso.predict(X_test) # 预测效果验证 RMSE = np.sqrt(mean_squared_error(y_test,lasso_predict)) RMSE Logistic回归模型 将线性回归模型的公式做Logit变换,即为Logistic回归模型,将预测问题变成了0到1之间的概率问题。
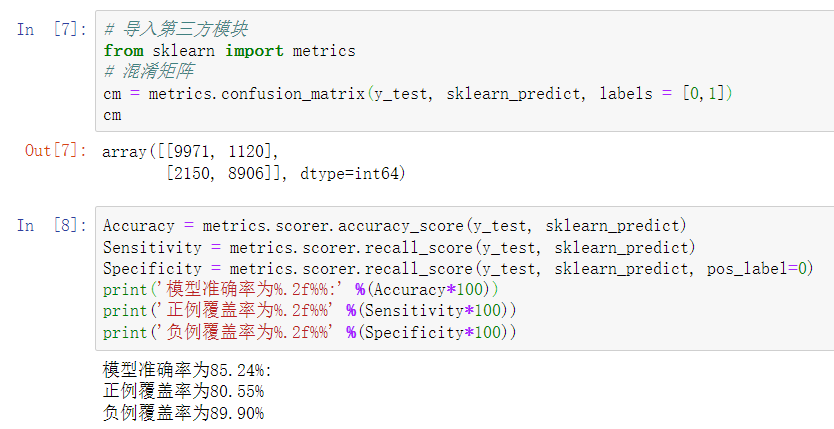
混淆矩阵
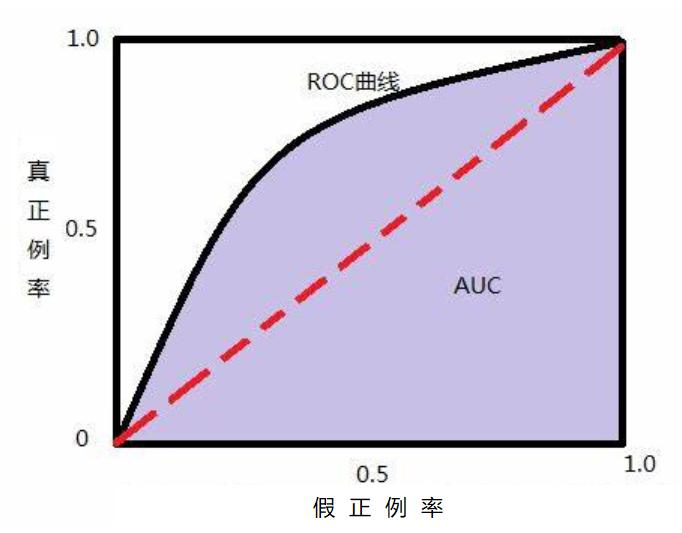
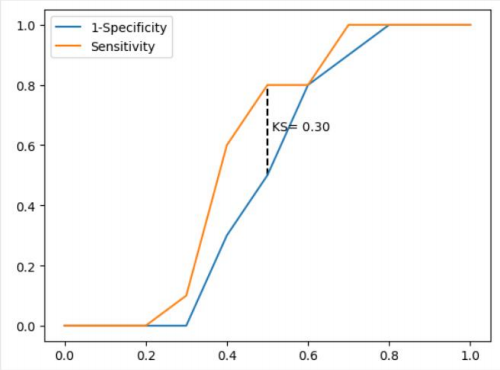
准确率 表示正确预测的正负例样本数与所有样本数量的⽐值,即(A+D)/(A+B+C+D) 正例覆盖率 表示正确预测的正例数在实际正例数中的⽐例,即D/(B+D) 负例覆盖率 表示正确预测的负例数在实际负例数中的⽐例,即A/(A+C) 正例命中率 表示正确预测的正例数在预测正例数中的⽐例,即D/(C+D) 代码 # 导入第三方模块 import pandas as pd import numpy as np from sklearn import model_selection from sklearn import linear_model # 读取数据 sports = pd.read_csv(r'Run or Walk.csv') # 提取出所有自变量名称 predictors = sports.columns[4:] # 构建自变量矩阵 X = sports.ix[:,predictors] # 提取y变量值 y = sports.activity # 将数据集拆分为训练集和测试集 X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size = 0.25, random_state = 1234) # 利用训练集建模 sklearn_logistic = linear_model.LogisticRegression() sklearn_logistic.fit(X_train, y_train) # 返回模型的各个参数 print(sklearn_logistic.intercept_, sklearn_logistic.coef_) # 模型预测 sklearn_predict = sklearn_logistic.predict(X_test) # 预测结果统计 pd.Series(sklearn_predict).value_counts() # 导入第三方模块 from sklearn import metrics # 混淆矩阵 cm = metrics.confusion_matrix(y_test, sklearn_predict, labels = [0,1]) cm Accuracy = metrics.scorer.accuracy_score(y_test, sklearn_predict) Sensitivity = metrics.scorer.recall_score(y_test, sklearn_predict) Specificity = metrics.scorer.recall_score(y_test, sklearn_predict, pos_label=0) print('模型准确率为%.2f%%:' %(Accuracy*100)) print('正例覆盖率为%.2f%%' %(Sensitivity*100)) print('负例覆盖率为%.2f%%' %(Specificity*100)) 模型的评估方法 ROC曲线 通过计算AUC阴影部分的面积来判断模型是否合理(通常大于0.8表示合理) KS曲线 通过计算两条折线之间最大距离来衡量模型是否合理(通常大于0.4表示合理)
绘制KS曲线代码 def内的代码保存下来即可 # 导入第三方模块 import pandas as pd import numpy as np import matplotlib.pyplot as plt # 自定义绘制ks曲线的函数 def plot_ks(y_test, y_score, positive_flag): # 对y_test重新设置索引 y_test.index = np.arange(len(y_test)) # 构建目标数据集 target_data = pd.DataFrame({'y_test':y_test, 'y_score':y_score}) # 按y_score降序排列 target_data.sort_values(by = 'y_score', ascending = False, inplace = True) # 自定义分位点 cuts = np.arange(0.1,1,0.1) # 计算各分位点对应的Score值 index = len(target_data.y_score)*cuts scores = np.array(target_data.y_score)[index.astype('int')] # 根据不同的Score值,计算Sensitivity和Specificity Sensitivity = [] Specificity = [] for score in scores: # 正例覆盖样本数量与实际正例样本量 positive_recall = target_data.loc[(target_data.y_test == positive_flag) & (target_data.y_score>score),:].shape[0] positive = sum(target_data.y_test == positive_flag) # 负例覆盖样本数量与实际负例样本量 negative_recall = target_data.loc[(target_data.y_test != positive_flag) & (target_data.y_score |




【本文地址】