【Python学习】 |
您所在的位置:网站首页 › 随机样本数据 › 【Python学习】 |
【Python学习】
|
一、随机划分
import numpy as np
from sklearn import datasets
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 1)归一化前,将原始数据分割
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X, y, test_size=0.2,
stratify=y, # 按照标签来分层采样
shuffle=True, # 是否先打乱数据的顺序再划分
random_state=1) # 控制将样本随机打乱
函数声明:train_test_split(test_size, train_size, random_state=None, shuffle=True, stratify=None) 参数说明:test_size:可以接收float,int或者None。如果是float,则需要传入0.0-1.0之间的数,代表测试集占总样本数的比例。如果传入的是int,则代表测试集样本数,如果是None,即未声明test_size参数,则默认为train_size的补数。如果train_size也是None(即两者都是None),则默认是0.25。 train_size:和前者同理。 random_state:可以接收int,随机种子实例,或者None。random_state是随机数生成器使用的种子,如果是None则默认通过 ' np.random ' 来生成随机种子。 stratify:接收一个类数组对象 或 None。如果不为None,则数据将以分层的方式进行分割,使用这个作为分类标签。(找了半天关于分层的方式进行分割的具体说明,总算找到个像样的,见下文) shuffle: 默认是True,是否在分割之前重新洗牌数据。如果shuffle = False那么stratify必须是None。 关于stratify参数的详细说明:stratify是为了保持split前类的分布。比如有100个数据,80个属于A类,20个属于B类。如果train_test_split(… test_size=0.25, stratify = y_all), 那么split之后数据如下: training: 75个数据,其中60个属于A类,15个属于B类。 testing: 25个数据,其中20个属于A类,5个属于B类。 用了stratify参数,training集和testing集的类的比例是 A:B= 4:1,等同于split前的比例(80:20)。通常在这种类分布不平衡的情况下会用到stratify。 将stratify=X_data(数据)就是按照X中的比例分配 将stratify=Y_data(标签)就是按照y中的比例分配 一般来说都是 stratify = y 的 二、K折交叉划分 传送门
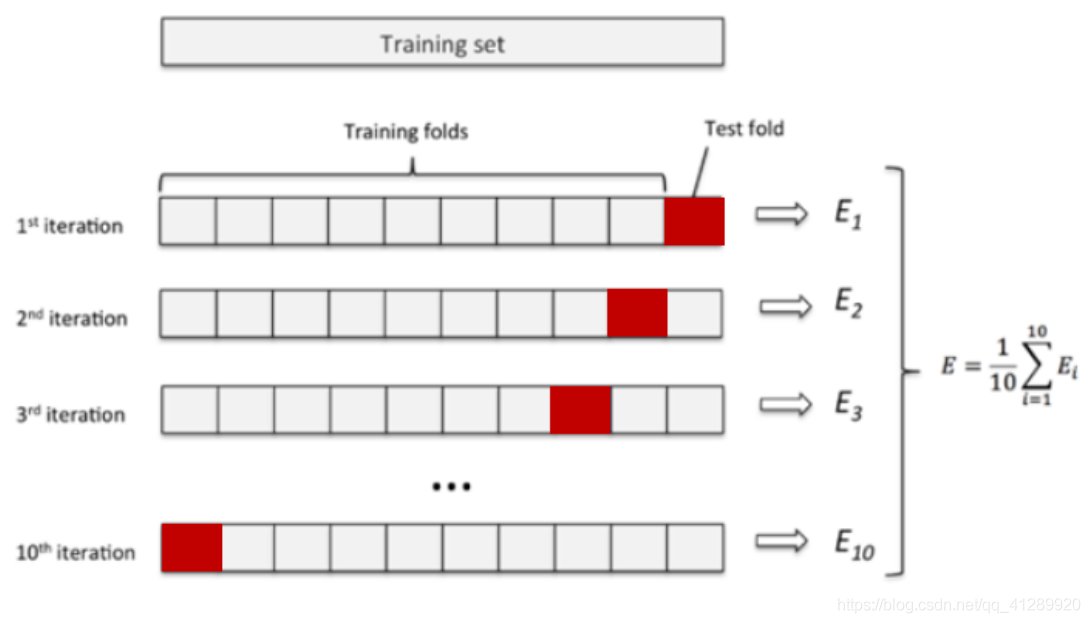
定义与原理:将原始数据D随机分成K份,每次选择(K-1)份作为训练集,剩余的1份(红色部分)作为测试集。交叉验证重复K次,取K次准确率的平均值作为最终模型的评价指标。过程如下图所示,它可以有效避免过拟合和欠拟合状态的发生,K值的选择根据实际情况调节。
注意这两句是等价的。而使用参数average='macro'或者'weighted'是不等价的 print(precision_score(y_test, y_pred,average='micro')) print(np.sum(y_test == y_pred) / len(y_test)) K-Fold是最简单的K折交叉,n-split就是K值,shuffle指是否对数据洗牌,random_state为随机种子 K值的选取会影响bias和viriance。K越大,每次投入的训练集的数据越多,模型的Bias越小。但是K越大,又意味着每一次选取的训练集之前的相关性越大,而这种大相关性会导致最终的test error具有更大的Variance。一般来说,根据经验我们一般选择k=5或10。 使用iris数据集进行简单实战: import numpy as np from sklearn import datasets iris = datasets.load_iris() X = iris.data y = iris.target from sklearn.model_selection import KFold from sklearn.ensemble import GradientBoostingClassifier as GBDT from sklearn.metrics import precision_score clf = GBDT(n_estimators=100) precision_scores = [] kf = KFold(n_splits=5, random_state=0, shuffle=False) for train_index, valid_index in kf.split(X, y): x_train, x_valid = X[train_index], X[valid_index] y_train, y_valid = y[train_index], y[valid_index] clf.fit(x_train, y_train) y_pred = clf.predict(x_valid) precision_scores.append(precision_score(y_valid, y_pred, average='micro')) print('Precision', np.mean(precision_scores)) 进一步加深理解K折交叉验证:
注意: 1. for循环中参数如果是两个,则永远都是训练集和验证集的下标!!而不是x和y!!(即不是数据和标签!) 2. for trn_idx,val_idx in kf.split(X) :,这里可以只有X,没有y!因为如果只需要提取出下标来的话,则和数据标签没啥关系,我只是要分出训练集和验证集! 如果有X和y,则维度必须一致!!否则报错:比如下面这个例子: 输入: XX = np.array(['A','B','C','D','E','F','G','H','I','J']) yy = np.array(range(15)) kf = KFold(n_splits=2, random_state=0, shuffle=False) for trn_idx,val_idx in kf.split(XX,yy) :# 如果带上y?但是维度不一致? print('验证集下标和验证集分别是:') print(val_idx) print(XX[val_idx]) 报错: ValueError: Found input variables with inconsistent numbers of samples: [10, 15]输入: XX = np.array(['A','B','C','D','E','F','G','H','I','J']) kf = KFold(n_splits=3, random_state=0, shuffle=False) for trn_idx,val_idx in kf.split(XX) : print('验证集下标和验证集分别是:') print(val_idx) print(XX[val_idx]) 输出: 验证集下标和验证集分别是: [0 1 2 3] ['A' 'B' 'C' 'D'] 验证集下标和验证集分别是: [4 5 6] ['E' 'F' 'G'] 验证集下标和验证集分别是: [7 8 9] ['H' 'I' 'J'] 输入: XX = np.array(['A','B','C','D','E','F','G','H','I','J']) kf = KFold(n_splits=5, random_state=0, shuffle=False) for trn_idx,val_idx in kf.split(XX) :# 如果带上y?但是维度不一致? # ============================================================================= # print('训练集下标和训练集分别是:') # print(trn_idx) # print(XX[trn_idx]) # ============================================================================= print('验证集下标和验证集分别是:') print(val_idx) print(XX[val_idx]) 输出: 验证集下标和验证集分别是: [0 1] ['A' 'B'] 验证集下标和验证集分别是: [2 3] ['C' 'D'] 验证集下标和验证集分别是: [4 5] ['E' 'F'] 验证集下标和验证集分别是: [6 7] ['G' 'H'] 验证集下标和验证集分别是: [8 9] ['I' 'J'] 输入: from sklearn.model_selection import KFold import numpy as np x = np.array(['B', 'H', 'L', 'O', 'K', 'P', 'W', 'G']) kf = KFold(n_splits=2) d = kf.split(x) for train_idx, test_idx in d: train_data = x[train_idx] test_data = x[test_idx] print('train_idx:{}, train_data:{}'.format(train_idx, train_data)) print('test_idx:{}, test_data:{}'.format(test_idx, test_data)) 输出: train_idx:[4 5 6 7], train_data:['K' 'P' 'W' 'G'] test_idx:[0 1 2 3], test_data:['B' 'H' 'L' 'O'] train_idx:[0 1 2 3], train_data:['B' 'H' 'L' 'O'] test_idx:[4 5 6 7], test_data:['K' 'P' 'W' 'G'] 为了更好的体现当前进行到的组数,可以进行如下更改: 输入: XX = np.array(['A','B','C','D','E','F','G','H','I','J']) yy = np.arange(10) kf = KFold(n_splits=2, random_state=0, shuffle=False) for fold_, (trn_idx,val_idx) in enumerate(kf.split(XX,yy)) : print("fold n°{}".format(fold_+1)) print('训练集下标和训练集分别是:') print(trn_idx) print(XX[trn_idx]) print('验证集下标和验证集分别是:') print(val_idx) print(XX[val_idx]) 输出: fold n°1 训练集下标和训练集分别是: [5 6 7 8 9] ['F' 'G' 'H' 'I' 'J'] 验证集下标和验证集分别是: [0 1 2 3 4] ['A' 'B' 'C' 'D' 'E'] fold n°2 训练集下标和训练集分别是: [0 1 2 3 4] ['A' 'B' 'C' 'D' 'E'] 验证集下标和验证集分别是: [5 6 7 8 9] ['F' 'G' 'H' 'I' 'J']或者这样: 输入: XX = np.array(['A','B','C','D','E','F','G','H','I','J']) yy = np.arange(10) num = np.arange(10) kf = KFold(n_splits=2, random_state=0, shuffle=False) for fold_, (trn_idx,val_idx) in zip(num,kf.split(XX)) : print("fold n°{}".format(fold_+1)) print('训练集下标和训练集分别是:') print(trn_idx) print(XX[trn_idx]) print('验证集下标和验证集分别是:') print(val_idx) print(XX[val_idx]) 输出: fold n°1 训练集下标和训练集分别是: [5 6 7 8 9] ['F' 'G' 'H' 'I' 'J'] 验证集下标和验证集分别是: [0 1 2 3 4] ['A' 'B' 'C' 'D' 'E'] fold n°2 训练集下标和训练集分别是: [0 1 2 3 4] ['A' 'B' 'C' 'D' 'E'] 验证集下标和验证集分别是: [5 6 7 8 9] ['F' 'G' 'H' 'I' 'J']三、StratifiedKFold StratifiedShuffleSplit允许设置设置train/valid对中train和valid所占的比例 # coding = utf-8 import numpy as np from sklearn.model_selection import train_test_split from sklearn.model_selection import StratifiedShuffleSplit from sklearn import datasets from sklearn.ensemble import GradientBoostingClassifier as GBDT from sklearn.metrics import precision_score iris = datasets.load_iris() X = iris.data y = iris.target x_train,x_test,y_train,y_test = train_test_split(X, y, test_size=0.2, stratify=y, # 按照标签来分层采样 shuffle=True, # 是否先打乱数据的顺序再划分 random_state=1) # 控制将样本随机打乱 clf = GBDT(n_estimators=100) precision_scores = [] kf = StratifiedShuffleSplit(n_splits=10, train_size=0.6, test_size=0.4, random_state=0) for train_index, valid_index in kf.split(x_train, y_train): x_train, x_valid = X[train_index], X[valid_index] y_train, y_valid = y[train_index], y[valid_index] clf.fit(x_train, y_train) y_pred = clf.predict(x_valid) precision_scores.append(precision_score(y_valid, y_pred, average='micro')) print('Precision', np.mean(precision_scores))四、StratifiedShuffleSplit StratifiedShuffleSplit允许设置设置train/valid对中train和valid所占的比例 # coding = utf-8 import numpy as np from sklearn.model_selection import train_test_split from sklearn.model_selection import StratifiedShuffleSplit from sklearn import datasets from sklearn.ensemble import GradientBoostingClassifier as GBDT from sklearn.metrics import precision_score iris = datasets.load_iris() X = iris.data y = iris.target x_train,x_test,y_train,y_test = train_test_split(X, y, test_size=0.2, stratify=y, # 按照标签来分层采样 shuffle=True, # 是否先打乱数据的顺序再划分 random_state=1) # 控制将样本随机打乱 clf = GBDT(n_estimators=100) precision_scores = [] kf = StratifiedShuffleSplit(n_splits=10, train_size=0.6, test_size=0.4, random_state=0) for train_index, valid_index in kf.split(x_train, y_train): x_train, x_valid = X[train_index], X[valid_index] y_train, y_valid = y[train_index], y[valid_index] clf.fit(x_train, y_train) y_pred = clf.predict(x_valid) precision_scores.append(precision_score(y_valid, y_pred, average='micro')) print('Precision', np.mean(precision_scores))其他的方法如RepeatedStratifiedKFold、GroupKFold等详见sklearn官方文档。 https://www.programcreek.com/python/example/91149/sklearn.model_selection.StratifiedShuffleSplit |
【本文地址】