【网络编程实践 |
您所在的位置:网站首页 › 陈硕blog › 【网络编程实践 |
【网络编程实践
|
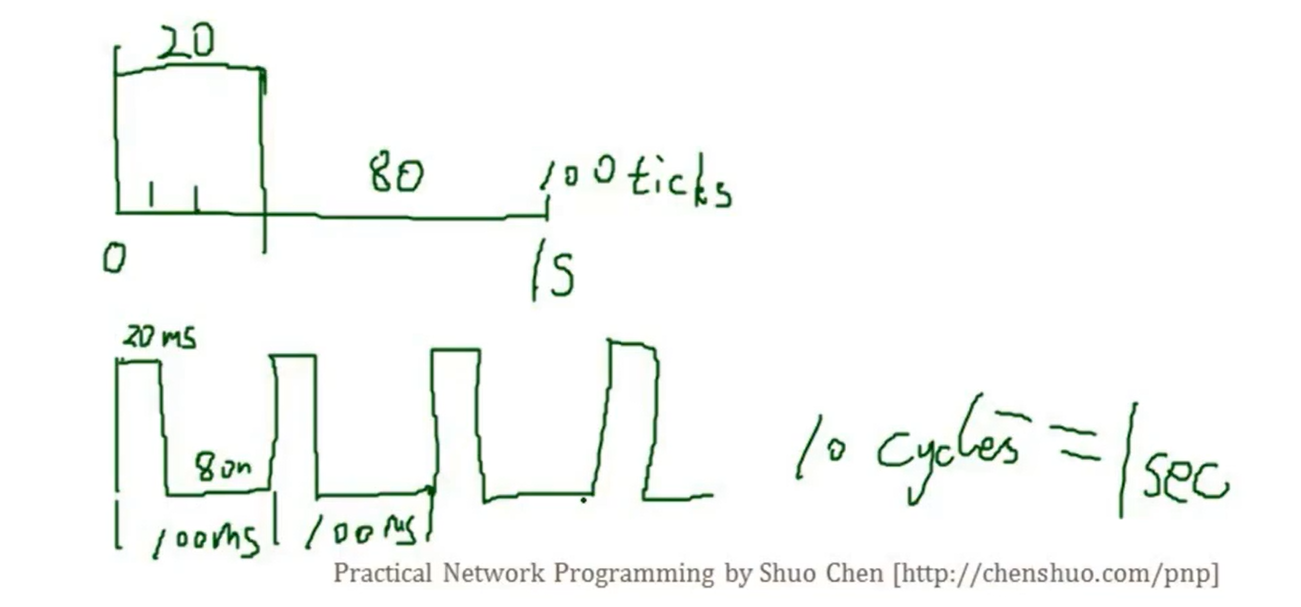
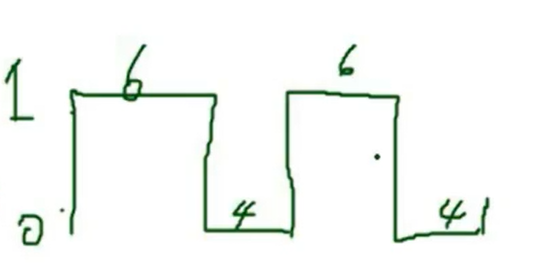
本文参考《网络编程实践》–陈硕(Muduo作者)视频课程所写。基于课程内容所做归纳和整理。 《网络编程实战》配套页面:http://chenshuo.com/pnp Blog https://www.cnblogs.com/Solstice/ github:https://github.com/chenshuo 注:由于内容较多,本篇文章将采用目录的形式,将各章节内容聚合在各标题的连接中。 文章目录 一、网络编概要1.1 网络分层(Layered NetworK)1.2 新手的常见陷阱(Common pitfalls of novices)1.3 一个简单的TCP实验1.3.1 测量用netcat在千兆以太网的TCP吞吐量1.3.2 CPU占用率对网络传输的影响 二、简单的非并发编程2.1 ttcp性能测试工具2.1.1 网络性能指标2.1.2 实现 ttcp 程序2.1.3 阻塞IO下的 echo实验2.1.4 tcp 自连接 2.2 roundtrip 测试两台服务器之间的时间差(使用udp的例子)2.2.1 网络时间同步(NTP)原理2.2.2 UDP编程,roundtrip 测量RTT时延2.2.3 测试两台服务器之间的延迟2.2.4 UDP vs. TCP2.2.5 扩展:UTC and GMT 2.3 netcat 工具:TCP/IP 的瑞士军刀2.3.1 netcat 基本功能简介2.3.2 TCP连接错误关闭示例2.3.3 使用安全的断开方式2.3.4 TCP网络编程三部曲(SIGPIPE、Nagle、SO_REUSEADDR)2.3.4.1 应忽略SIGPIPE信号2.3.4.2 建议关闭 Nagle 算法2.3.4.3 使用SO_REUSEADDR选项 2.3.5 实现 netcat 程序2.3.5.1 代码资源2.3.5.2 基于多线程阻塞IO实现的 netcat2.3.5.3 基于 IO 复用(阻塞IO)实现的 netcat2.3.5.4 IO复用配合阻塞IO使用,可能会阻塞整个程序2.3.5.5 基于IO复用(非阻塞IO)实现的 netcat 2.3.6 测试 netcat 性能2.3.7 非阻塞IO中需要关注的问题 2.4 procmon 慢速的收发工具2.4.1 进程间监控工具2.4.2 muduo库安装 及 代码编译:2.4.3 使用procmon观察dummyload2.4.4 procmon 程序的设计实现2.4.5 dummyload 程序设计与实现2.4 慢速的收发工具,模拟网速慢的情况:在应用层模拟,收到数据后延迟一段时间再发送,用于测试服务端是否能因对接收慢的情况(特别对于非阻塞) 并发网络编程:Socket代理服务器:阻塞情况下:easy,非阻塞情况下,如果两段带宽不匹配需要特殊处理数独求解:客户端发数独难题,服务器返回求解结果简单的memcached应用层的TCP广播:一个消息发送给多个tcp客户端:连接的生命期管理、某个连接有延迟 多台机器进行数据处理并行的N皇后问题求解求分布在多台机器上的数的中位数查询出现次数最多的项,跨机器,从日志中出现的最频繁的1k个查询有哪些分布式排序,map-redis 高级主题RPC:远程调用服务负载均衡:round-robin服务系统容量管理:测试数据+预测延迟:测延迟,机器时间同步、测百分位数的延迟 一、网络编概要 1.1 网络分层(Layered NetworK)在网络编程中,主要关注以下四层: 网络接口层(Ethernet frame):帧(Frame)网络层(IP packet):分组 / 数据包(Packet)传输层(TCP segment):TCP 报文段(Segment)、UDP 数据报(Datagram)应用层(Application message):消息(Message) 1.2 新手的常见陷阱(Common pitfalls of novices)在网络编程中,有一些新手容易踩的坑特别需要我们关注。 阅读全文 >: https://blog.csdn.net/weixin_43919932/article/details/121611027 1.3 一个简单的TCP实验 1.3.1 测量用netcat在千兆以太网的TCP吞吐量下面我们使用 netcat 来测试一下在千兆网中 tcp 可以达到的吞吐量。 阅读全文 >: https://blog.csdn.net/weixin_43919932/article/details/121610830 1.3.2 CPU占用率对网络传输的影响网络传输速率不只和网络环境相关,也与该网络程序运行时所占主机的资源相关。 例如在本次测试中,测试主机是一个双核机器,在运行 服务端nc、客户端nc、dd 等命令时,它们之间实际上存在着资源的竞争,例如CPU资源。因此,nc 程序并没有全力运行,而所测试的结果也并未达到真正的 netcat 的性能结果。 阅读全文 >: https://blog.csdn.net/weixin_43919932/article/details/121610365 二、简单的非并发编程 2.1 ttcp性能测试工具测试两台机器之间的吞吐量。 2.1.1 网络性能指标 带宽(Bandwidth):每秒收发的数据量,MB/s。(只关注数据量,不关注消息数)吞吐量(Throughput):消息/s、查询/s(QPS)、事物数/s(TPS)延迟(Latency):毫秒级延迟,百分位延迟资源使用率(Utilization):资源的利用程度(比例),如磁盘使用率、CPU使用率、额外开销(例如在拷文件时,需要实时压缩和加密产生的开销)(Overhead) 测试数据应小于Overhead,如果测试结果大于Overhead,则考虑可能有数据压缩 如果远小于Overhead且CPU使用率很低,则考虑程序在网络带宽和CPU带宽是均不理想 如果远小于Overhead且CPU使用率很高,则考虑程序在计算上消耗很大(例如SSH在拷文件时,数据加密涉及CPU计算) 2.1.2 实现 ttcp 程序ttcp:测试网络吞吐量的性能测试工具 阅读全文 >: https://blog.csdn.net/weixin_43919932/article/details/121601105 2.1.3 阻塞IO下的 echo实验下面使用 echo.cc、echo_client.cc 演示一个阻塞IO实验。 阅读全文 >: https://blog.csdn.net/weixin_43919932/article/details/121601070 2.1.4 tcp 自连接如果本地tcp程序本地通信,且客户端先于服务端启动,那么有极大可能会产生一种自连接现象。本质上是 tcp 的服务端和客户端同时打开了同一个端口造成的。 全文阅读 >: https://blog.csdn.net/weixin_43919932/article/details/121600989 2.2 roundtrip 测试两台服务器之间的时间差(使用udp的例子) 2.2.1 网络时间同步(NTP)原理Network Time Protocol(NTP)是用来使计算机时间同步化的一种协议,它可以使计算机对其服务器或时钟源(如石英钟,GPS等等)做同步化,它可以提供高精准度的时间校正(LAN上与标准间差小于1毫秒,WAN上几十毫秒),且可介由加密确认的方式来防止恶毒的协议攻击。NTP的目的是在无序的Internet环境中提供精确和健壮的时间服务。 阅读全文 >: https://blog.csdn.net/weixin_43919932/article/details/121600890 2.2.2 UDP编程,roundtrip 测量RTT时延我们仿照NTP时间同步的原理,实现一个测量两台机器之间误差的程序,在实现中服务端将收到数据的时间与发送应答的时间抽象为一个时间点,即忽略server端处理数据的机器误差。 利用这三个时间点 T1, T2, T3,从而计算两台机器的时延。 阅读全文 >: https://blog.csdn.net/weixin_43919932/article/details/121600634 2.2.3 测试两台服务器之间的延迟基于以上原理实现的程序,可用于测试两台服务器之间的时间差,而测试的角度必然是一个多维的结果,下面探讨一些测试的角度。 阅读全文 >: https://blog.csdn.net/weixin_43919932/article/details/121600533 扩展知识:在配置机房时,至少4台机器需要配置NTP,两台机器接GPS校准,2台机器接原子钟校准,互相作为参考,以免某个NTP服务异常导致时钟不准。 2.2.4 UDP vs. TCP TCP:传输控制协议。面向连接的、可靠的、基于字节流的传输层通信协议。UDP:用户数据报协议。无连接的、 不可靠的、 面向数据报的协议。全文阅读 >: https://blog.csdn.net/weixin_43919932/article/details/121600472 2.2.5 扩展:UTC and GMT对于时间而言,我们需要关注 UTC、GMT、Unix Time 这几种格式的时间表示方式。其中 闰秒:为保持协调世界时接近于世界时时刻,由国际计量局统一规定在年底或年中(也可能在季末)对协调世界时增加或减少1秒的调整。 而Unix Time是不考虑闰秒的,因此在发生闰秒调整时,怎样对类Unix计算机的时间进行调整是个问题。 全文阅读 >: https://blog.csdn.net/weixin_43919932/article/details/121600381 2.3 netcat 工具:TCP/IP 的瑞士军刀在 ttcp、round_trip 程序中,都只是与一个Socket进行通信,而 netcat 除了与Socket进行通信外,还与标准输入与标准输出相关。 2.3.1 netcat 基本功能简介 信号发生器:发送数据。nc > /dev/zero、类似chargen服务负载:接收数据。nc > /dev/null、类似discard服务通过dd产生定量数据,通过nc发送测试网络带宽,dd /dev/zero | nc、类似ttcp服务两台机器之间通过nc拷贝文件,nc < file, nc > file、类似scp服务关于使用 nc 传输文件,示例如下: 不要直接使用 close() 关闭连接,这可能会引发 tcp 的RST分解,从而使得数据接收不完整。尽量使用 shutdown() + close() 的方式关闭连接和套接字。 阅读全文 >: https://blog.csdn.net/weixin_43919932/article/details/121600106 2.3.3 使用安全的断开方式正确关闭连接的方式为使用 shutdown() ,发起FIN报文断开连接 发送方不再发送数据后,使用 shutdown(sock,SHUT_WR) 关闭本端套接字的输出流。 shutdown() 会向对方发送 FIN 包。FIN 包通过四次挥手过程断开连接,可以有效的等待数据发送完成再断开连接。调用 read() 函数,read()/resv() 将会返回0,代表对方也不再发送数据。此时连接已断开。 (这里read()返回0应考虑客户端存在Bug或恶意的不返回0的情况,使得客户端永远不满足read()=0的情况。因此这里因考虑有超时机制,在shutdown之后若干秒内如果没有满足read()=0,则强制断开连接并有相应的错误处理)调用 close() 函数关闭套接字。按照上述TCP安全断开的方式,我们将 recipes/tpc/sender.cc 程序完整的代码运行,则不会发生数据接收不完整的情况。 2.3.4 TCP网络编程三部曲(SIGPIPE、Nagle、SO_REUSEADDR) 2.3.4.1 应忽略SIGPIPE信号如果向一个已经关掉的管道写数据,write系统调用会返回一个 SIGPIPE 信号 ,该信号默认情况下这个信号会终止整个进程。 一般情况下,我们都会忽略该信号。 signal(SIGPIPE, SIG_IGN);全文阅读 >: https://blog.csdn.net/weixin_43919932/article/details/121599738 2.3.4.2 建议关闭 Nagle 算法Nagle算法主要是避免发送小的数据包,要求TCP连接上最多只能有一个未被确认的小分组,在该分组的确认到达之前不能发送其他的小分组。 Nagle算法会严重影响请求响应式协议的延迟。 如果我们的程序设计的不够合理,Nagle算法可能会增加程序的延迟。 全文阅读 >: https://blog.csdn.net/weixin_43919932/article/details/121599120 2.3.4.3 使用SO_REUSEADDR选项SO_REUSEADDR ——复用地址选项 。 服务器进程应该打开此选项,以便在服务器端进程异常退出后可以快速重启。 阅读全文 >: https://blog.csdn.net/weixin_43919932/article/details/121598944 2.3.5 实现 netcat 程序对于 netcat 程序,存在两种模式,即 服务端 和 客户端, 它们的区别在于连接建立的方式。 一旦连接建立,客户端/服务器 的行为都是一样的,使用两个并行的循环处理: 从标准输入,写到 TCP Socket从 TCP Socket 读, 写到标准输出主要有两种基本的并发模型: 多线程配合阻塞IOIO多路复用配合非阻塞 2.3.5.1 代码资源这里提供三种netcat的实现: recipes/tpc/netcat.cc thread-per-connectionrecipes/python/netcat.py IO-multiplexingrecipes/python/netcat-nonblock.py IO-multiplexing以及,为了测试以上 netcat 程序,这里还提供了对应的负载生成器: recipes/tpc/chargen.ccrecipes/python/chargen.pymuduo/examples/simple/chargen/*对于 netcat 的实现这里提供了三个版本,多线程配合阻塞IO、IO多路复用配合阻塞IO、IO多路复用配合非阻塞IO。其中 IO多路复用配合非阻塞IO 实现的netcat使用不当会使整个程序阻塞。 2.3.5.2 基于多线程阻塞IO实现的 netcatThread-per-connection 适用于连接数目不太多,或者线程非常廉价的情况。推荐使用这种方式。 一般情况下,使用主线程创建监听套接字等待客户端连接,建立连接后分发到工作线程进行处理。 该版本 netcat 多线程的方式实现, 一个连接对应两个线程去处理,每个线程负责连接上的一个方向,即读 或 写。 阅读全文 >: https://blog.csdn.net/weixin_43919932/article/details/121598543 2.3.5.3 基于 IO 复用(阻塞IO)实现的 netcatIO 复用(事件驱动)使得一个线程可以处理多个连接上的请求,值得注意的是它是同步IO。 IO复用一般和非阻塞的IO一起使用。因为使用阻塞IO的话可能会存在阻塞程序的风险。 如果程序通过阻塞IO实现,并且发送端和接收端并不是相互独立的,那么它极有可能会发生阻塞。(墨菲定理😂) 全文阅读 >: https://blog.csdn.net/weixin_43919932/article/details/121598267 2.3.5.4 IO复用配合阻塞IO使用,可能会阻塞整个程序阻塞IO 如果和 IO复用 配合使用,一旦发生阻塞就会影响到同一事件循环下的其他IO事件。 全文阅读 >: https://blog.csdn.net/weixin_43919932/article/details/121598267 2.3.5.5 基于IO复用(非阻塞IO)实现的 netcat使用非阻塞IO可以有效避免上述情况的发生。但非阻塞IO在编程上要比阻塞IO更难,并且在程序的维护上比较痛苦。一般使用非阻塞IO编程时建议使用一些封装好的网络库比较容易编写。 全文阅读 >: https://blog.csdn.net/weixin_43919932/article/details/121598145 2.3.6 测试 netcat 性能以下将以截图形式,展示测试结果,并且结合cpu资源分配情况,分析整个测试结果。 阅读全文 >: https://blog.csdn.net/weixin_43919932/article/details/121611316 2.3.7 非阻塞IO中需要关注的问题在 2.3.5.5 标题中实现的 netcat 使用了非阻塞IO编程,可以看到非阻塞IO在逻辑处理上并没有阻塞IO编程那么好实现,比如如何处理short write等。 阅读全文 >: https://blog.csdn.net/weixin_43919932/article/details/121583937 2.4 procmon 慢速的收发工具 2.4.1 进程间监控工具代码:muduo/examples/procmon 功能:实现一个带web界面的top,无需远程登录到某个主机查看他的资源消耗量,通过浏览器web查看。 演示:查看 pid=1的进程,将它映射到3000端口,然后使用浏览器指定3000端口查看。 相关源码的编译和下载请参考如下链接。 阅读全文 >: https://blog.csdn.net/weixin_43919932/article/details/121645156 2.4.3 使用procmon观察dummyloaddummyload 是一个cpu负载生成器,能够把cpu负载维持在指定的水平。 下面利用dummyload工具将cpu负载按照时间余弦函数曲线变化,并使用procmon程序观察。 阅读全文 >: https://blog.csdn.net/weixin_43919932/article/details/121656379 2.4.4 procmon 程序的设计实现要实现这样一个procmon 程序,不仅是在 /proc/pid 下将文件读出就行了,我们还有还需要考虑的更多。 阅读全文 >: https://blog.csdn.net/weixin_43919932/article/details/121658436 2.4.5 dummyload 程序设计与实现控制CPU使用可以使用脉冲宽度调制,控制CPU一段时间内“忙”和“闲”的比例。 CPU使用率的测量:某段时间内,CPU“忙”所占的比例。 (多核情况下,可以大于 100%) CPU使用率的控制:通过控制一个测量周期内,CPU“忙”所占时间与总周期时间的占比。 示例说明如何控制CPU使用率: 例如控制CPU使用率在20%。我们需要做的是在一个测量周期 T = 100 s T=100s T=100s内,使CPU忙的时间占 T x = 20 s T_x=20s Tx=20s , 空闲时间占 T y = 80 s T_y=80s Ty=80s 。这样,在一个 T T T周期内,CPU所占时间占比总的时间 = T x / T = 20 % T_x/T = 20\% Tx/T=20% 。 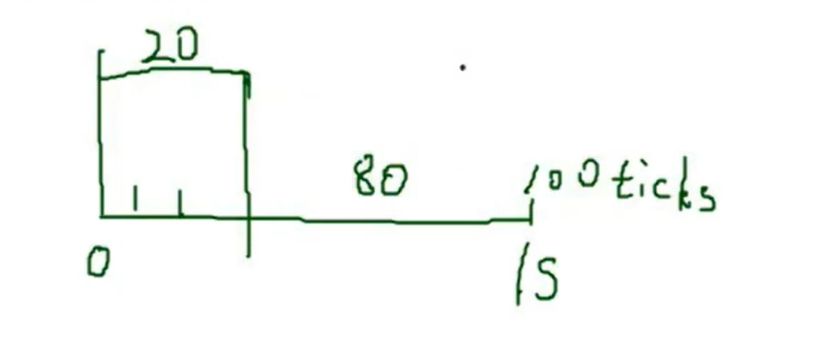
这样的做法使得CPU在一个
T
T
T周期内的利用率并不均匀。最好的做法就是,将一个
T
T
T的周期均分为若干个小的周期
T
n
T_n
Tn,在每个小周内依然按照
T
x
:
T
y
T_x:T_y
Tx:Ty 的比例进行CPU的“忙”/“闲”切换。 根据以上的方式我们可以调节CPU的占空比,从而在某种意义上而言我们可以控制CPU的使用率。 例如,我们要控制 60% 的使用率,那么它的波形应该如下图所示,其中波峰代表cpu busy loop,波谷代表cpu等待,这样我们在宏观上通过调整波峰与波谷的比例,将各自的时间比例维持在6:4 便可以得到一个这样的矩形波。 同样的,如果我们以一个小的 T n T_n Tn为单位,动态的调整波峰与波谷的时间比例,例如 T 0 { T x : T y = 5 : 5 } , T 1 { T x : T y = 6 : 4 } , T 0 { T x : T y = 7 : 3 } , . . . . . T_0\{T_x:T_y = 5:5\},T_1\{T_x:T_y = 6:4\},T_0\{T_x:T_y = 7:3\},. . . . . T0{Tx:Ty=5:5},T1{Tx:Ty=6:4},T0{Tx:Ty=7:3},..... 。那么我们得到的将是一个锯齿波形图。 dummyload 实现 代码地址:muduo/examples/procmon/dummyload.cc #include #include #include #include #include #include #include #include #include #include using namespace muduo; using namespace muduo::net; int g_cycles = 0; int g_percent = 82; AtomicInt32 g_done; bool g_busy = false; MutexLock g_mutex; Condition g_cond(g_mutex); double busy(int cycles) { double result = 0; for (int i = 0; i Timestamp start = Timestamp::now(); busy(cycles); return timeDifference(Timestamp::now(), start); } void findCycles() { g_cycles = 1000; while (getSeconds(g_cycles) { MutexLockGuard guard(g_mutex); while (!g_busy) g_cond.wait(); } busy(g_cycles); } printf("thread exit\n"); } // this is open-loop control void load(int percent) // 设定CPU使用率 { percent = std::max(0, percent); percent = std::min(100, percent); // Bresenham's line algorithm int err = 2*percent - 100; int count = 0; for (int i = 0; i busy = true; err += 2*(percent - 100); ++count; // printf("%2d, ", i); } else { err += 2*percent; } { MutexLockGuard guard(g_mutex); g_busy = busy; g_cond.notifyAll(); } CurrentThread::sleepUsec(10*1000); // 10 ms } assert(count == percent); } void fixed() // 固定的cpu使用率 { while (true) { load(g_percent); // 对于cpu使用率固定,每次load相同的percent } // g_percent 全局变量,且峰值由参数指定 } void cosine() // 余弦曲线 { while (true) for (int i = 0; i while (true) for (int i = 0; i if (argc threads.push_back(new Thread(threadFunc)); threads.back().start(); } switch (argv[1][0]) // 处理参数 { case 'f': // 固定cpu使用率到某个范围,例如固定cpu使用率到30% { fixed(); } break; case 'c': // 余弦曲线 { cosine(); } break; case 'z': // 锯齿波形 { sawtooth(); } break; // TODO: square and triangle waves default: break; } g_done.getAndSet(1); { MutexLockGuard guard(g_mutex); g_busy = true; g_cond.notifyAll(); } for (int i = 0; i |
 注意:1) 在使用nc传输文件后,校验一下文件的完整性,例如使用md5校验。2) netcat 版本不同,某些特性可能会存在差异。例如,该版本nc以EOF为断开连接的标志,而其他版本的nc可能需要识别Ctrl-C信号才断开连接(如果是这样的话,请试一下参数-q0 参数 或 -N 参数)。
注意:1) 在使用nc传输文件后,校验一下文件的完整性,例如使用md5校验。2) netcat 版本不同,某些特性可能会存在差异。例如,该版本nc以EOF为断开连接的标志,而其他版本的nc可能需要识别Ctrl-C信号才断开连接(如果是这样的话,请试一下参数-q0 参数 或 -N 参数)。 演示:查看当前shell中运行的bash。
演示:查看当前shell中运行的bash。 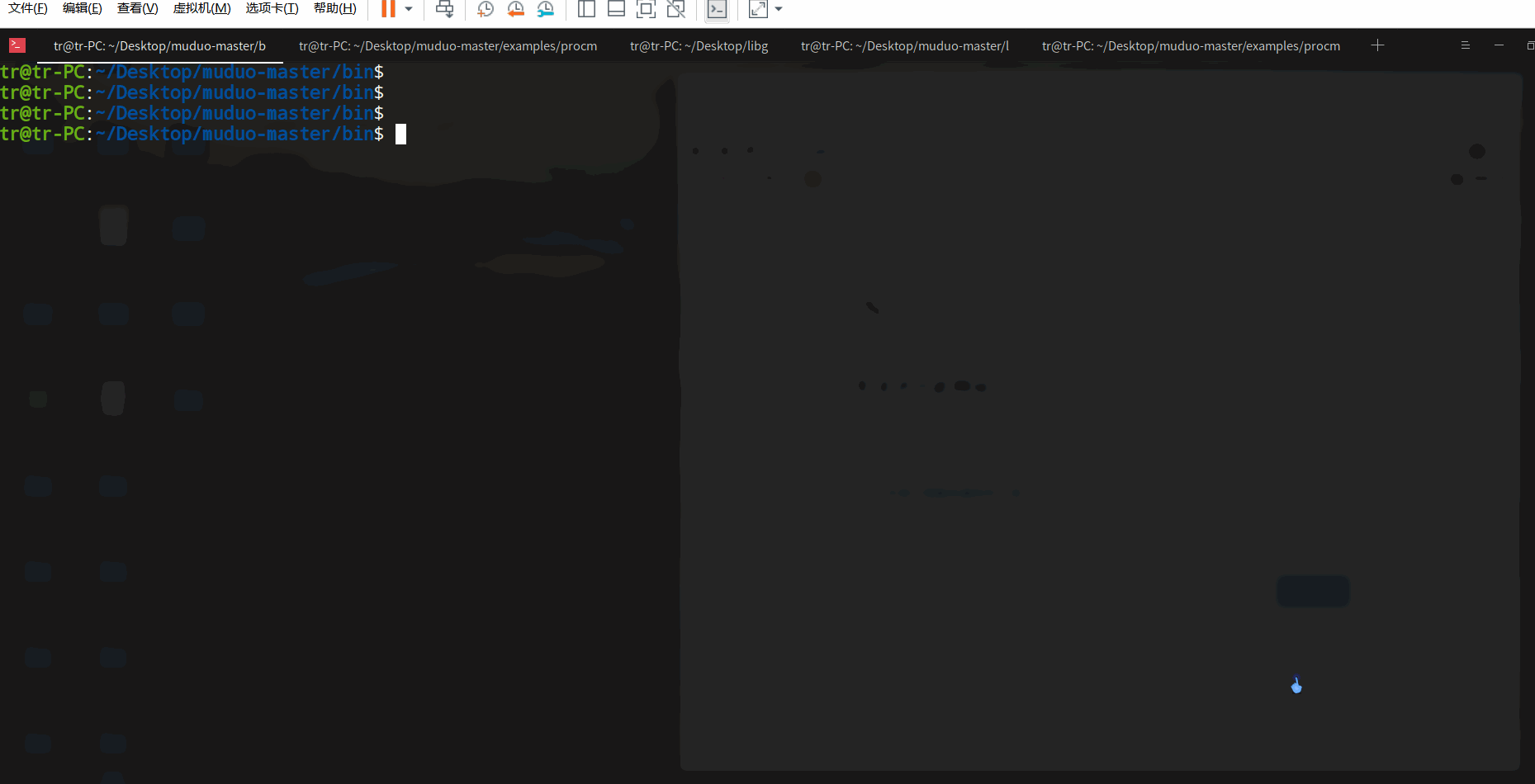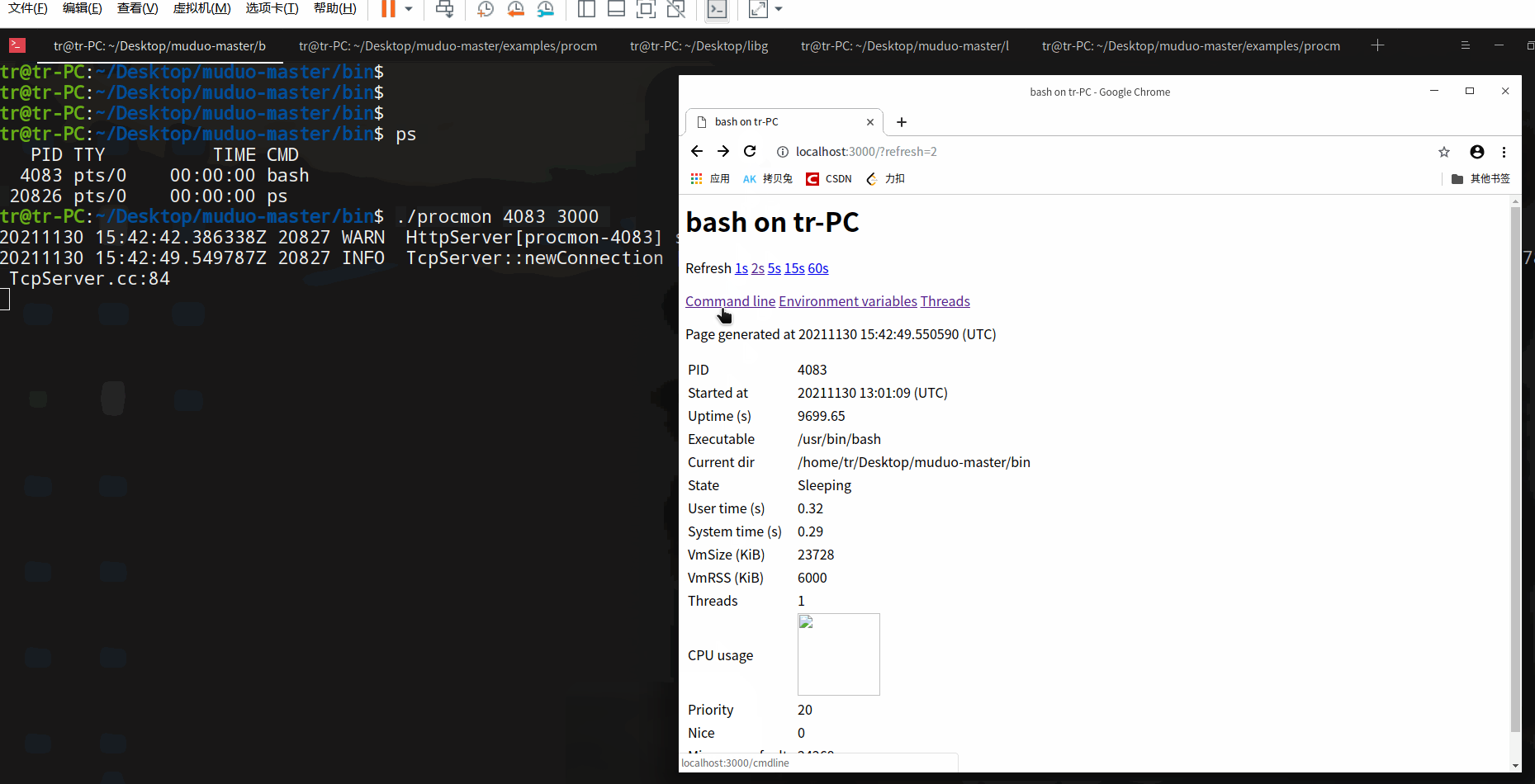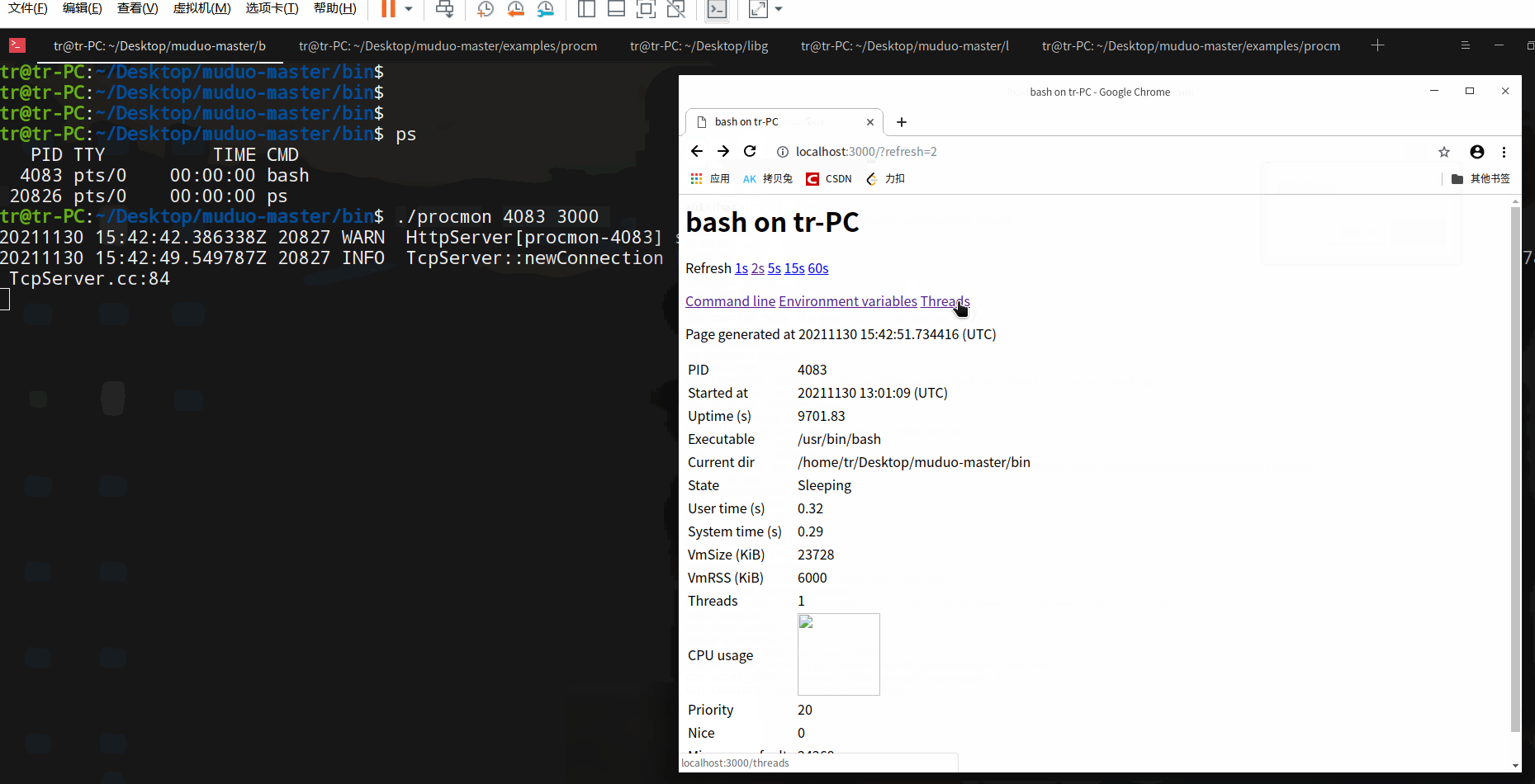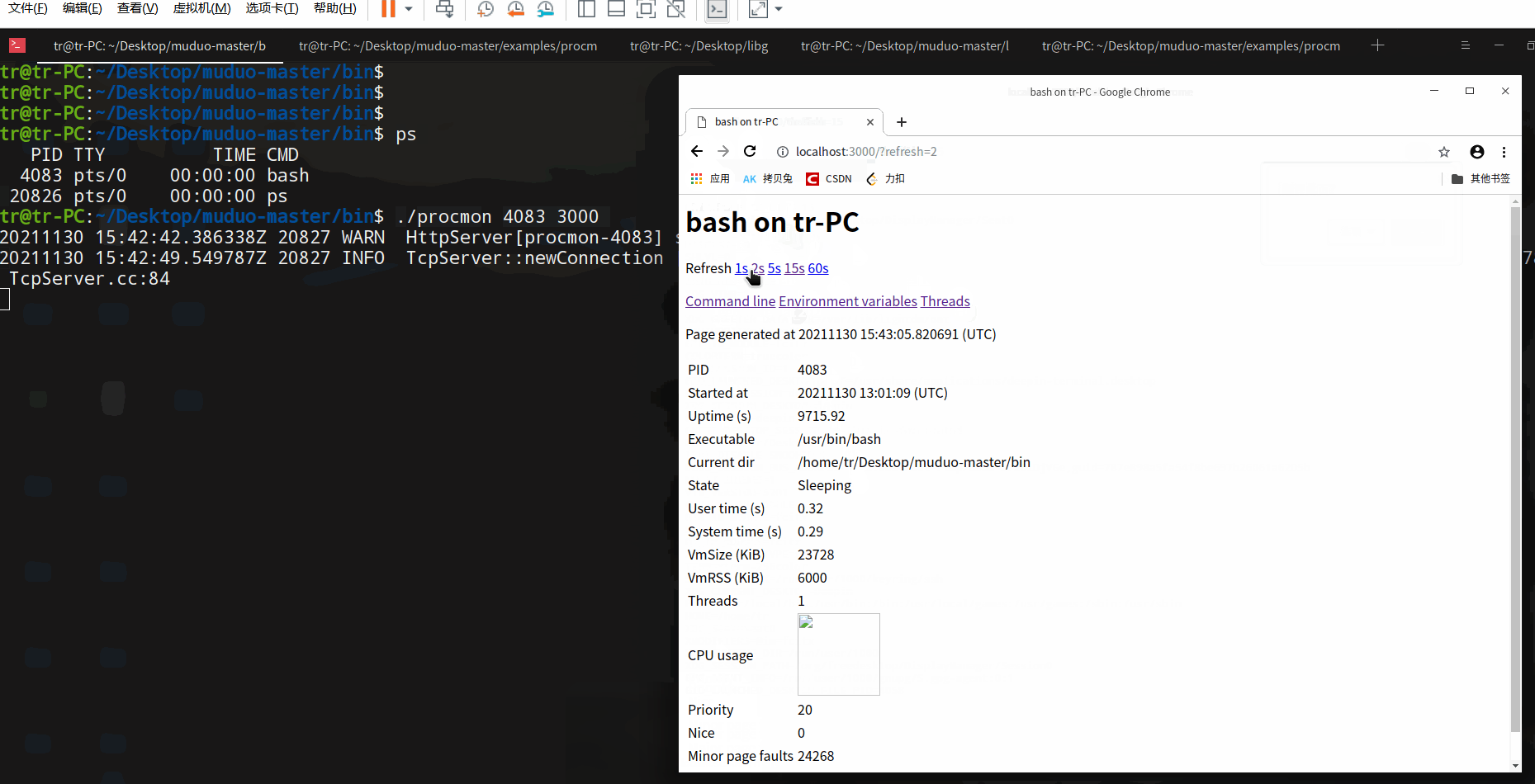
【本文地址】
今日新闻 |
推荐新闻 |