浅析声音的数字化过程 |
您所在的位置:网站首页 › 阳泉平定五矿哪里高峰禁行了 › 浅析声音的数字化过程 |
浅析声音的数字化过程
|
浅析声音的数字化过程
小伙伴们很好奇,声音是怎么存放在计算机里的?这就涉及到音频数字化的概念,下面我们来一探究竟。 引言什么是声音? 由物体振动产生的声波。是通过介质(空气或固体、液体)传播并能被人或动物听觉器官所感知的波动现象。 声音只能用来听吗? 当我们将喇叭连接信号发生仪,金属板上均匀撒些沙子后,开启信号发生仪,不同的信号频率,会产生不同的图案。
那声音是怎么变成数字存储在硬件设备中的呢? 音频数字化也就是将模拟的(连续的)声音波形数字化(离散化),以便利用数字计算机进行处理。 模拟信号:现实生活中的声音表现为连续的、平滑的波形,其横坐标为时间轴,纵坐标表示声音的强弱。数字信号:将所有样本二进制编码连起来存储在计算机上就形成了数字信号。那从模拟信号(analogue)到数字信号(digital)要经过哪些过程呢? 采样:按照一定的时间间隔在连续的波上进行采样取值。量化:将采样得到的值进行量化处理,也就是给纵坐标定一个刻度,记录下每个采样的纵坐标的值。编码:将每个量化后的样本值转换成二进制编码。如下图: 下面具体介绍: 采样多长间隔采样每个点呢? 奈奎斯特取样定理认为,只要取样频率大于等于信号中所包含的最高频率的两倍,则可以根据其取样完全恢复出原始信号,这相当于当信号是最高频率时,每一周期至少要采取两个点。(但这只是理论上的定理,在实际操作中,人们用混叠波形,从而使取得的信号更接近原始信号。) 如何具体描述采样呢? 采样率:1s内采样的点数。 一般采样率有8kHz、16kHz、32kHz、22050Hz、44.1kHz、48kHz等,采样频率越高,声音的还原就越真实越自然,当然数据量就越大。 人类听觉范围是20-20000Hz,如果按照44.1kHz的频率进行采样(为什么是44.1?不是44或45,见后文),对20Hz音频进行采样,一个正弦波采样44100/20=2200次;对20000HZ音频进行采样,平均一个正弦波采样44100/20000=2.2次。 量化取样的离散音频要转化为计算机能够表示的数据范围,这个过程称为量化。量化的等级取决于量化精度,也就是用多少位二进制数来表示一个音频数据。一般有8位,12位或16位,单位bit,如16bit。 量化精度越高,声音的保真度越高。 编码音频信号取样并量化成二进制,但实际上就是对音频信号进行编码,但用不同的取样频率和不同的量化位数记录声音,在单位时间中,所需存贮空间是不一样的。 常见的编码方式如:PCM编码(Pulse Code Modulation)。 运作原理如下。首先我们考虑声音经过麦克风,转换成一连串电压变化的信号,如下图所示。这张图的横座标为秒,纵座标为电压大小。要将这样的信号转为 PCM 格式的方法,是先以等时距分割,时间间隔是固定的 0.01 秒。
好了,我们现在已经把这个波形以数字记录下来了。由于我们已经知道时间间隔是固定的 0.01 秒,因此我们只要把纵座标记录下来就可以了,得到 的结果是 11.65 14.00 16.00 17.74 19.00 19.89 20.34 20.07 19.44 18.59 17.47 16.31 15.23 14.43 13.89 13.71 14.49 15.94 17.70 20.00 这一数列。这一串数字就是将以上信号数字化的结果。看吧,我们确实用数字记录了事物。在以上的范例中,我们的采样频率是100Hz(1/0.01 秒 ) 。其实电脑中的 .WAV 档的内容就是类似这个样子,文件头中记录了采样频率和可容许最大记录振幅,后面就是一连串表示振幅大小的数字,有正有负。 常见CD唱盘是以PCM格式记录,而它的采样频率是 44100Hz ,振幅采样精度/数位是 16Bits ,也就是说振幅最小可达 -32768(-2 ^ 16/2) ,最大可达 +32767(2^16/2-1) 。CD唱盘是以螺旋状由内到外储存资料,可以存储74分钟的音乐。 CD唱盘的规格为什么是 44.1kHz、16Bits呢? 关于 44.1kHz 这个数字的选取分为两个层面。首先人耳的聆听范围是 20Hz 到 20kHz ,根据奈奎斯特理论,只要用 40kHz 以上的采样频率就可以完整记录 20kHz 以下的信号。那么为什么要用44.1kHz 这个数字呢?那是因为在 CD 发明前硬盘还很贵,所以主要将数字音频信号储存媒体是录像带,用黑白来记录 0 与 1 。而当时的录像带格式为每秒 30 张,而一张图又可以分为 490 条线,每一条线又可以储存三个取样信号,因此每秒有 304903=44100 个取样点,而为了研发的方便, CD唱盘也继承了这个规格,这就是 44.1kHz 的由来。 在这里我们可以发现无论使用多么高的采样精度/数位,记录的数字跟实际的信号大小总是有误差,因此数字化无法完全记录原始信号。这个数字化造成失真称为量化失真。 其他波形声音的主要参数包括:采样频率、量化位数、声道数、压缩编码方案和数码率等。 声道数: 为了播放声音时能够还原真实的声场,在录制声音时在前后左右几个不同的方位同时获取声音,每个方位的声音就是一个声道。声道数是声音录制时的音源数量,有单声道、双声道、多声道。 数码率: 简称码率,也叫比特率,是指每秒传送的bit数。单位为 bps(Bit Per Second),比特率越高,每秒传送数据就越多,音质就越好。 未压缩前,波形声音的码率计算公式为: 波形声音的码率=采样频率 × 量化位数 × 声道数 波形声音的码率一般比较大,所以有时需对转换后的数据进行压缩。 总结音频数字化就是将模拟的(连续的)声音波形数字化(离散化),以便利用数字计算机进行处理的过程,主要包参数括采样频率(Sample Rate)和采样数位/采样精度(Quantizing,也称量化级)两个方面,这二者决定了数字化音频的质量。 采样频率是对声音波形每秒钟进采样的次数。根据这种采样方法,采样频率是能够再现声音频率的一倍。人耳听觉的频率上限在20kHz左右,为了保证声音不失真,采样频率应在40kHz左右。经常使用的采样频率有11.025kHz、22.05kHz和44.1kHz等。采样频率越高,声音失真越小、音频数据量越大。 采样数位是每个采样点的振幅动态响应数据范围,经常采用的有8位、12位和16位。例如,8位量化级表示每个采样点可以表示256个(0-255)不同量化值,而16位量化级则可表示65536个不同量化值。采样量化位数越高音质越好,数据量也越大。 常见的音频格式音频文件播放格式分为 有损压缩 和 无损压缩 两种。使用不同的格式的音乐文件,在音质的表现上有差很大的差异。 有损压缩:顾名思义就是降低音频采样频率与比特率,输出的音频文件会比原文件小。如MP3格式。无损压缩:能够在100%保存原文件的所有数据的前提下,将音频文件的体积压缩的更小,而将压缩后的音频文件还原后,能够实现与源文件相同的大小、相同的码率。如WAV格式。由MICROSOFT公司开发的WAV声音文件格式,是如今计算机中最为常见的声音文件类型之一,它符合RIFF文件规范,用于保存WINDOWS平台的音频信息资源,被WINDOWS平台机器应用程序所广泛支持。另外,WAVE格式支持MSADPCM、CCIPTALAW、CCIPT-LAW和其他压缩算法,支持多种音频位数,采样频率和声道,但其缺点是文件体积较大,所以不适合长时间记录。因此,才会出现各种音频压缩编/解码技术的出现,例如,MP3,RM,WMA,VQF,ASF等等它们各自有自己的应用领域,并且不断在竞争中求得发展。 WAVE–WINDOWS系统最基本音频格式—*.wav 1、占用巨大硬盘空间,音质最好,支持音乐与语音 2、通常采样使用44KHZ采样/秒,16位/采样,立体声,双声道,CD音质 3、一分钟音乐占用大约10M硬盘空间,56K调制解调器需要30分钟才能完成网络传送 MIDI–电子合成音乐—*.mid 1、与WAVE格式截然不同,只有音乐,没有语音 2、使用音色库回放,有软硬波表之分, 3、十分节省磁盘空间,但是音质回放对声卡依赖较大 4、无法使用Total Recorder录制mid音乐 5、可以使用Wingroove软波表或其它软件转为wave MP3–最流行音频压缩格式—*.mp3 1、节省硬盘空间,有损压缩,无法复原 2、音质与不同压缩编码软件有关 3、音乐与语音,可以使用各种采样比率 RM–网络流媒体压缩格式—.rm/.ra 1、节省磁盘空间,有损压缩,无法复原 2、在目前比较窄的网络带宽下,与Real Server服务器配合,使用Real Player在客户端 比较流畅地播放音视频媒体 其它还有: 1、微软的WMA编码–.wma 2、微软的ASF流媒体编码–.asf 3、Yamaha的VQF编码–*.vqf 后记当然,存储在硬件设备里的声音又怎么放出来被人耳听到的呢? 数字转模拟 比如耳机接收数据并解压后再通过解码器将数字转为模拟电波形,此波形会被发送到音圈,音圈根据波形来回移动。或通过扬声器播出。 从而在空气中产生能被耳朵感知的压力波,这就是我们所到的声音。 2、频率(Hz):人们能感知的声音音高。男性语音为180Hz,女性歌声为600Hz,钢琴上 C调至A调间为440Hz,电视机发出人所能听到的声音是17kHz,人耳能够感知的最高声音频 率为20kHz。 那么,数字化的资料如何转换成原来的音频信号呢?在计算机的声卡中一块芯片叫做 DAC(Digital to Analog Converter) ,中文称数模转换器。DAC的功能如其名是把数字信号转换回模拟信号。我们可以把DAC想像成 16 个小电阻,各个电阻值是以二的倍数增大。当 DAC 接受到来自计算机中的二进制 PCM 信号,遇到 0 时相对应的电阻就开启,遇到 1 相对应的电阻不作用,如此每一批 16Bits 数字信号都可以转换回相对应的电压大小。我们可以想像这个电压大小看起来似乎会像阶梯一样一格一格,跟原来平滑的信号有些差异,因此再输出前还要通过一个低通滤波器,将高次谐波滤除,这样声音就会变得比较平滑了。 |

 声音频率越高图案越复杂,换成液体后,也能产生同样的效果。这就是著名的克拉尼图形,实验中用于显示克拉尼图形的金属板,就被称为克拉尼板。 其最早由18世纪的德国物理学家,恩斯特克拉德尼发现。他用弓弦拉动铺有沙子的金属薄片,结果细沙自动排列成美丽的图案,随着弓弦节奏的不断增加,图案也不断变幻和越趋复杂。 这也是人们最早认识声音样貌的案例。其实声音不仅可以通过图案展现,甚至还能被转化为数字。当你的手机连接蓝牙耳机后,开始播放音乐或视频,手机就会将声音压缩转化为数据形态,发送到蓝牙耳机中。
声音频率越高图案越复杂,换成液体后,也能产生同样的效果。这就是著名的克拉尼图形,实验中用于显示克拉尼图形的金属板,就被称为克拉尼板。 其最早由18世纪的德国物理学家,恩斯特克拉德尼发现。他用弓弦拉动铺有沙子的金属薄片,结果细沙自动排列成美丽的图案,随着弓弦节奏的不断增加,图案也不断变幻和越趋复杂。 这也是人们最早认识声音样貌的案例。其实声音不仅可以通过图案展现,甚至还能被转化为数字。当你的手机连接蓝牙耳机后,开始播放音乐或视频,手机就会将声音压缩转化为数据形态,发送到蓝牙耳机中。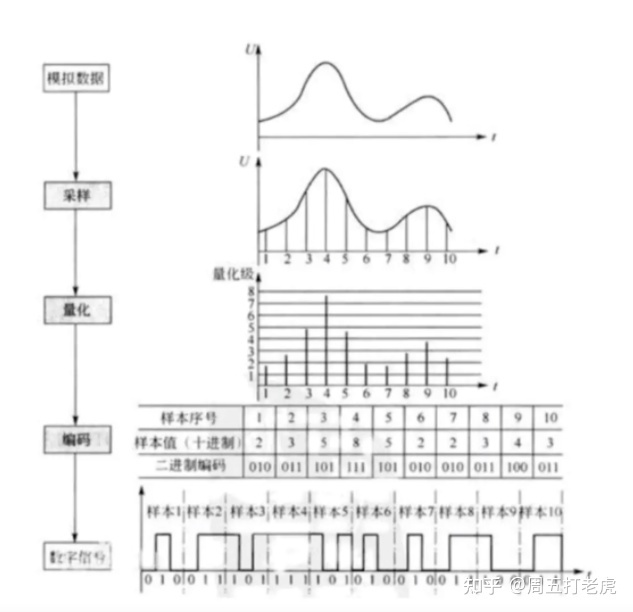
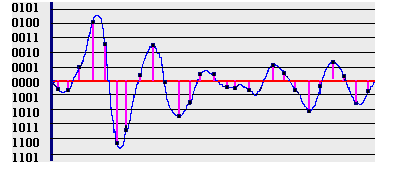 我们把分割线与信号图形交叉处的座标位置记录下来,可以得到如下资料,(0.01,11.65) ,(0.02,14.00) 、 (0.03,16.00) 、 (0.04,17.74) … …(0.18,15.94) 、 (0.19 ,17.7) 、 (0.20,20) 。
我们把分割线与信号图形交叉处的座标位置记录下来,可以得到如下资料,(0.01,11.65) ,(0.02,14.00) 、 (0.03,16.00) 、 (0.04,17.74) … …(0.18,15.94) 、 (0.19 ,17.7) 、 (0.20,20) 。 具体有关内容:WAV
具体有关内容:WAV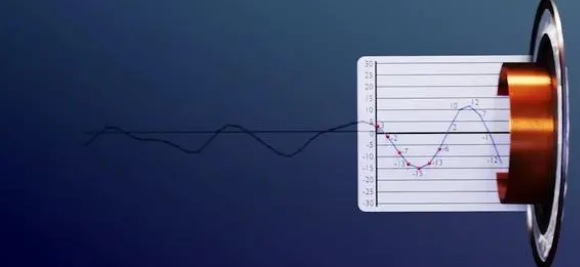 两个基本概念: 1、分贝(dB):声波振幅的度量单位,非绝对、非线性、对数式度量方式。以人耳所能听到的最静的声音为1dB,那么会造成人耳听觉损伤的最大声音为100dB。人们正常语音交谈大约为20dB。10dB意味着音量放大10倍,而20dB却不是20倍,而是100倍(10的2次方)。
两个基本概念: 1、分贝(dB):声波振幅的度量单位,非绝对、非线性、对数式度量方式。以人耳所能听到的最静的声音为1dB,那么会造成人耳听觉损伤的最大声音为100dB。人们正常语音交谈大约为20dB。10dB意味着音量放大10倍,而20dB却不是20倍,而是100倍(10的2次方)。【本文地址】
今日新闻 |
推荐新闻 |