【论文阅读】略读 基于注意力门控图神经网络的文本分类 |
您所在的位置:网站首页 › 门控卷积神经网络 › 【论文阅读】略读 基于注意力门控图神经网络的文本分类 |
【论文阅读】略读 基于注意力门控图神经网络的文本分类
|
基于注意力门控图神经网络的文本分类 [1]邓朝阳,仲国强,王栋.基于注意力门控图神经网络的文本分类[J/OL].计算机科学:1-14[2022-03-06]. 模型将文本图数据输入到AGGNN,捕捉非连续单词之间的长距离依赖关系以及上下文语义信息。 具体来说: 1.首先,将每个输入的文本数据转换为独立的图结构数据;将构建的图结构数据(文本图)送入AGGNN,更新单词节点的特征信息; 2.然后,TextPool根据当前层中的所有单词节点,提取出其中具有判别性特征的关键节点; 3.最后,Readout基于提取出的关键节点构建文本嵌入表示,将结果送入文本分类器以完成文本分类。 总结:亮点看上去还是文本分类前的特征工程。特征处理,文本节点处理。对于文本分类倒不是重点。
文中用到的一些符号: 文本图G=⟨V,E⟩;V :节点,E:路径, X∈R n×d :n个单词节点的特征矩阵,n代表节点的个数,d代表每个单词是d维的词向量。 对于特征矩阵X,隐藏状态ht∈R n×d 表示其在训练过程中每个时间步t的更新状态,并使用X对h0进行初始化。 A:文本图G的邻接矩阵,当存在边(vi,vj)∈E,Aij=1,否则Aij=0。 D:图G的对角化度矩阵,其中Dii=∑j Aij
构建重点: 每个文章document构建图,每个文章里的单词word设为节点, 节点之间的关系(边)通过使用固定尺寸的滑动窗口捕捉来建立。 2. 注意力门控图神经网络AGGNNAGGNN捕捉文本图中单词节点之间的语义关系,目的是控制每个节点特征信息传递。 AGGNN通过门控机制对不同节点之间的语义信息进行聚合和更新,以获得有效的文本嵌入表示,其主要由3个门控组成:注意力门、更新门和重置门 注意力门: 捕捉每个节点与其一阶邻居节点之间的语义关联程度, 注意力分数: 决定着每个邻居节点中可以保留下来并整合到当前节点中的特征信息量。 对于图中的每个节点,其注意力分数的计算式如下: 我的理解是,公式1分子上是上一个时刻t-1节点i的一个更新状态h,乘以一个权重W,分母上是上一个时刻t-1时,对于包括节点i在内的所有相邻节点,计算他们的更新状态h乘以权重W。分子比分母,得到的就是上一个时刻节点i在所有一阶邻居节点中的一个重要性。 每个节点vi,其特征向量通过注意力加权,时刻t的时候的更新状态,为t时刻每一个一阶邻居节点的在t-1时刻的重要性乘以t-1时刻的更新状态之和,公式为:
AGGNN 使得每个单词节点能够在信息传递和聚合的过程中不断更新自身的特征表示。当每个节点的特征表示更新完成后,本文希望利用这些节点的特征提取出当前层文本级别的特征表示。 每个文本的标签由其中的关键单词决定,通过提取具有判别性语义特征的节点,便能为目标文档分配期望的标签。——————根据关键词给文章分类。 提出了基于注意力的TextPool,分为三步 我看到的步骤 1.根据ht和A计算注意力分数s 2.注意力分数排序选前k个节点 3.获取前k个节点后,再次用注意力分数s和h t-1 更新ht, 4.根据前k个节点,构建新的子图,更新邻接矩阵A,计算新子图隐藏状态 h t-1, 我的理解就是利用注意力机制(全局或者局部,这里也不是创新点,注意力的公式是以前论文中有的,)计算每个节点的得分,然后排序选择节点构建新的小图,然后更新隐藏状态,为了方便在readout中整合特征更新hG. 4. 图读出模块 Readout当提取出关键节点并建立新的子图后,Readout根据每个节点的特征表示构建文本图的嵌入表示hG 在该过程中,TextPool模块提取出的每个节点将贡献出自身的部分特征,同时最具代表性的节点应为文档表示做出更多贡献。 因此,Readout使用均值函数及最大化函数来整合每个关键节点的特征表示。 这一个部分我的理解就是对节点的h的一个筛选,按照最大或者均值来拼接筛选整合每个节点的特征表示,然后输入到分类器中,所以这里的readout 不是固定的也不是创新点。 (讲的不清楚的地方回去看一下论文公式。) 5. 文本分类在获得文本图嵌入表示hG后,分类器如式16表示 4个基准文本数据集:Ohsumed,R8,R52和 MR数据集。 实验的模型结构图: 主要是引入了一个注意力门,在原本GNN上进行了更改,实现了AGGNN,实现对节点之间关系的进一步限制,就是在原本基础上增加了一个注意力机制,(?),然后别的一些工作量在实验中有体现,多出进行了对比。 我好像很少在csdn上看见有中文的论文阅读的笔记,基本都是英文的,不知道是不是因为版权问题? 这篇主要是为了学习记忆,方便回顾所作笔记,如果有侵权问题麻烦告知! 如果有走过路过的大佬看见有错误请不吝赐教谢谢!! |
 具体的具体来说:
具体的具体来说: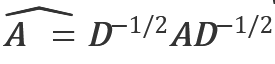 对称归一化邻接矩阵。
对称归一化邻接矩阵。 两曲线交汇的地方表示矩阵的拼接操作,两曲线分叉的地方表示矩阵的复制操作。
两曲线交汇的地方表示矩阵的拼接操作,两曲线分叉的地方表示矩阵的复制操作。 W∈R d×1:线性转换矩阵, N:当前节点及其一阶邻居节点的集合, 所以这是第i个节点在t-1时刻的更新状态,乘以线性转换矩阵,然后向量通过softmax归一化。
W∈R d×1:线性转换矩阵, N:当前节点及其一阶邻居节点的集合, 所以这是第i个节点在t-1时刻的更新状态,乘以线性转换矩阵,然后向量通过softmax归一化。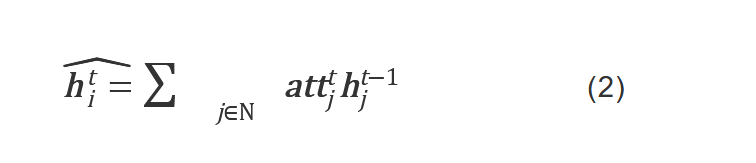 zt:更新门, rt:重置门, W,U:可训练权重, b:偏置向量, σ:sigmoid激活函数, ⊙:点积运算。
zt:更新门, rt:重置门, W,U:可训练权重, b:偏置向量, σ:sigmoid激活函数, ⊙:点积运算。 公式不太看懂。。。 注意力门就是a t吧
公式不太看懂。。。 注意力门就是a t吧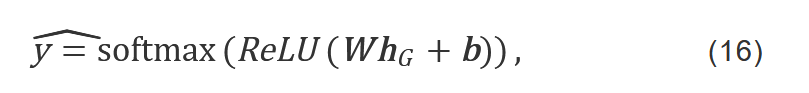 生成目标文本的预测标签yˆ,然后利用交叉熵损失函数。
生成目标文本的预测标签yˆ,然后利用交叉熵损失函数。 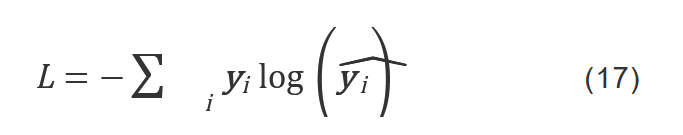
 多少有点不明觉厉。
多少有点不明觉厉。【本文地址】
今日新闻 |
推荐新闻 |