负采样,yyds! |
您所在的位置:网站首页 › 链路预测模型是什么 › 负采样,yyds! |
负采样,yyds!
|
文 | 徐澜玲源 | RUC AI Box 引言:负采样方法最初是被用于加速 Skip-Gram 模型的训练,后来被广泛应用于自然语言处理 (NLP)、计算机视觉 (CV) 和推荐系统 (RS) 等领域,在近两年的对比学习研究中也发挥了重要作用。本文聚焦于负采样方法,将各领域的相关工作分为五类进行介绍:静态负采样、强负例采样、对抗式负采样、基于图的负采样和引入额外信息的负采样。 开始之前先介绍一下!RUC AI Box 开发和维护了一个统一、全面、高效的推荐系统代码库 RecBole(发表在 CIKM 2021)。 https://github.com/RUCAIBox/RecBole RecBole 可以通过参数 neg_sampling 改变负采样策略,支持推荐系统中的随机负采样 (RNS, uniform) 、基于流行度的负采样 (PNS, popularity) 和动态负采样 (DNS, dynamic) 三种经典的方式。大家也可以在此基础上进行拓展,欢迎 Clone, Fork 和 Star ~ 目录1. 研究背景 1.1 什么是负采样? 1.2 为什么需要负采样? 1.3 为什么需要高质量的负采样? 2. 负采样方法分类梳理 2.1 静态负采样 2.2 强负例采样 2.3 对抗式负采样 2.4 基于图的负采样 2.5 引入额外信息的负采样 3. 未来展望 3.1 伪负例问题 3.2 融入课程学习 3.3 负采样比例 3.4 去偏采样 3.5 无采样 4. 小结 GitHub Repo 1. 研究背景 1.1 什么是负采样?在深度神经网络模型中,数据集中的每个句子、每对交互、每张图片都可以看作是模型的正样本,也称正例 (postive example)。在模型的训练过程中,一种常见的训练方式是同时给模型提供正例与负例 (negative example,不一定真实存在),并构造损失函数增大正负例的区分度,从而学到数据中的信息。基于一定的策略构造与正例相对的负例的过程,称为负采样 (Negative Sampling) 。 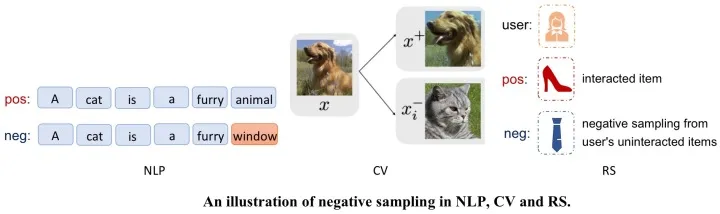
在 NLP 中随机替换连贯句子中的词语、在 CV 中不同图片数据增强的样例,以及 RS 中选择用户未交互的商品,都可以看作是在进行负采样。相关的损失函数有贝叶斯个性化排序损失 (BPR, viz. Bayesian Personalized Ranking loss)、二元交叉熵损失函数 (BCE, viz. Binary Cross Entropy loss) 和对比学习中常用的 InfoNCE loss 等。 1.2 为什么需要负采样?对于不同的领域,这个问题可能需要具体进行分析。但总的来说,负采样的作用有以下两点: Efficient: 提升了模型的计算效率。 以推荐系统基于隐式反馈的协同过滤算法 (Implicit Collaborative Filtering) 为例,对于用户交互的每个商品,如果我们不进行负采样,而是将该用户未交互的所有商品都作为负例进行优化,这样每个用户的更新都会涉及所有 item embedding,效率低下。 负采样的目的之一是仅对求代价过程中涉及的向量进行优化,减少训练的负荷。 Effective: 保证了模型的训练效果。 即使我们有充足的计算资源可以每次优化所有负例,但使用一定的策略对负例进行采样选择可以达到相同甚至更好的结果。 通常来说,我们能够使用的正例相对于随机构造的负例来说是非常有限的,即使对正例进行数据增广,正例与候选负例的数量往往也不在一个量级。 训练时我们会优化正例对的得分高于负例对,经过几轮训练后,正例 pair 的分数相对随机负例而言已经比较高了。尽管负例候选集十分庞大,但能带来信息增益的负例才是训练的关键,盲目地同等看待所有候选样例很有可能事倍功半。 负采样的另一目的是有针对性地提供高质量的负例,既加快收敛速度,又可以让模型朝着我们希望的方向进行优化。 1.3 为什么需要高质量的负采样?前面的描述可能比较抽象,让我们从《三国演义》的一个例子来具体地体会负例选择的重要性(对《三国演义》不太熟悉的读者可以依次代入四郎、甄嬛、静白、浣碧和纯元,或者贾宝玉、晴雯、刘姥姥、多姑娘和林黛玉)。 
正所谓“得人才者得天下”,已知刘备有关羽和张飞两位大将,那么张飞就可以作为刘备的一个正例 (positive example)。由于人才永远是最稀缺的资源,如果我们随机从三国时期的千万人群中选一个作为负例,那么随机负例 (random negative) 能被刘备赏识并重用的概率微乎其微。换句话说,刘备张飞刘备无名小兵 很难让模型学到有用的信息。因此,模型可能无法进行良好的参数更新,也不能将略微相关的样例与非常相关的样例区分开来。 我们希望采样得到的是 informative negative,在文献中常被称作 hard negative,即强负例。 在《三国演义》的设定中,张飞和吕布都是勇猛过人的将领,有万夫之勇,也都有各自的缺点。张飞鞭笞士卒、嗜酒无度;吕布骄奢淫逸、好色贪利。刘备视张飞为手足,却在白门楼说出“公不见丁建阳、董卓之事乎?”,精准为吕布补刀。 正是因为刘备以仁义闻名天下,最不喜的就是吕布此等忘恩负义、背信弃义的小人。将吕布这种具有一定竞争力的强负例作为训练样本,模型便能更好地挖掘刘备重情重义的特点。 强负例可能增进模型的训练效果,但至坚易断,过强易折,强负例超过一定界限后可能会采到未来的正例。对于当前的训练而言,这种样例在学术中被称作伪负例 (false negative)。也就是说,如果将刘备很有可能感兴趣的赵云作为与张飞配对的负例,刘备张飞刘备赵云 非但不能带来正向激励,有时甚至会对模型造成负面影响。 针对负例的质量和重要性,Facebook 进行了一项很有意思的研究工作,定量分析了 CV 领域对比学习里的负例对模型性能的影响。 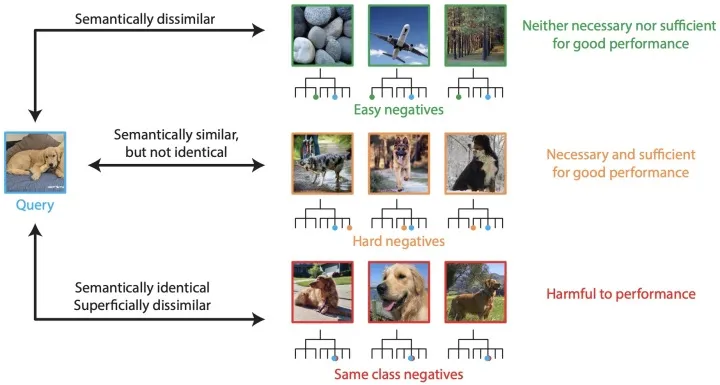 ▲Are all negatives created equal in contrastive instance discrimination? [93]
▲Are all negatives created equal in contrastive instance discrimination? [93]
文章研究发现: 绝大多数 (约95%) 负例是 easy negatives,它们与查询在语义上并不相似,仅用 easy negatives 不足以训练出一个好的模型。 其次,约 5% 的负例是 hard negatives,它们与查询在语义上相似但不同,这些强负例几乎决定了模型的结果,在训练中发挥了关键作用。 还有近 0.1% 的负例是 same class negatives,也就是我们之前提到的伪负例。这些负例表面上看与查询并不相似,但本质上语义是相同的(都是狗),把它们作为负例反而会影响模型的结果。 2. 负采样方法分类梳理本文聚焦于负采样方法,将 NLP、CV、RS、GRL、CL 等领域的相关工作分为五类进行介绍:静态负采样 (Static Negative Sampling)、强负例采样 (Hard Negative Sampling)、对抗式负采样 (Adversarial Sampling)、基于图的负采样 (Graph-based Sampling) 和引入额外信息的负采样 (Additional Data Enhanced Sampling)。 参考文献末尾给出了该篇工作的所属领域和 PDF 链接,读者可以根据自己的研究领域和兴趣方向选择性地阅读原文。 2.1 静态负采样 (Static Negative Sampling)如果我们限定从未交互集中选择已知的样例作为负例,那么,通过给不同的样例设置不同的权重,我们便能根据负例分布进行采样。 在不考虑合成新负例的前提下,负采样本质上是学习负例分布的问题。当每个样例被采样为负例的概率不随训练发生变化时,我们就称这种采样策略为静态负采样 (Static Negative Sampling)。 在静态负采样方法中,最简单也是应用最广泛的方法是随机负采样 (RNS, viz. Random Negative Sampling),也被称为均匀负采样 (Uniform Negative Sampling)。RNS [1, 2, 11] 随机从负例候选集中选择一个作为负例,在不考虑负采样的研究中,研究者们一般使用 RNS 作为基础的采样方法,以便公平地和 baseline 进行比较。 显然,对于每个正例而言,不同的负例带来的影响并不相同,一种启发式的负例分布的策略是基于流行度的负采样 (PNS, viz. Popularity-biased Negative Sampling)。流行度可以通过频次 (frequency) 或度 (degree) 来反映, ,即样本 被选为负例的概率和 的流行度的 次方具有比例关系。 当 时,PNS 就退化成了 RNS。 402 Payment RequiredPNS 首先在 word2vec [3] 中被提出。在 word2vec 词嵌入的表示中,实验发现 的结果较好,[4] 从理论角度对这种负采样策略进行了一定的解释,大多数嵌入表示算法 [5, 6, 7, 8] 也沿用了该方法和超参数。 然而, 并不是适用于所有领域, 甚至不一定需要为正数。[10] 将 word2vec 的负采样方式应用到推荐系统中发现,PNS 超参数 的选择依赖于数据集和任务。 [10] 在音乐推荐任务上研究了 对推荐结果的影响,结果发现 时的结果最佳。为负数意味着更多地选择不受欢迎的音乐作为负样本,这种情况下的 PNS 旨在更好地区分不同受欢迎程度的歌曲,文中也强调了超参数在不同任务场景下的关键作用。 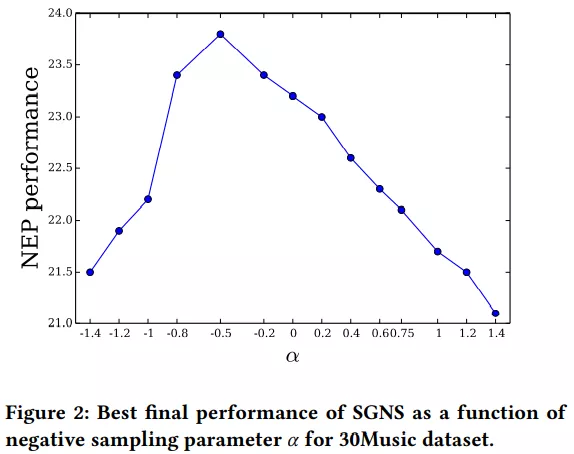 ▲Word2vec applied to Recommendation: Hyperparameters Matter [10]
▲Word2vec applied to Recommendation: Hyperparameters Matter [10]
在推荐系统领域,更常见的基于流行度的采样方法 [9, 12, 17] 是直接将商品在训练集中的流行程度作为候选负例的权重,即倾向于选择更流行的商品作为负例。 这种策略可以用流行度偏差来解释,借用 @Zilize 的描述:在高流行度(高曝光度)的情况下用户没有给予商品正反馈,说明用户大概率(比如 90%)不喜欢这件物品;在低流行度时则是完全不确定的状态(比如 50%)。当我们采样高流行度的负例时,可能只会带来 10% 的偏差,而随机采样会带来 50% 的偏差,从而后者对推荐系统的训练不利。 尽管具有一定的解释性,但从学术界的相关实验结果来看,PNS 在推荐系统中并不是稳定地优于 RNS,有时还会显著降低模型结果。如何合理利用商品流行度仍然是推荐系统中未被充分探索的问题。  ▲Reinforced Negative Sampling over Knowledge Graph for Recommendation [73]
▲Reinforced Negative Sampling over Knowledge Graph for Recommendation [73]
[1]. BPR: Bayesian Personalized Ranking from Implicit Feedback. UAI(2009) [RS] [PDF] [2]. Real-Time Top-N Recommendation in Social Streams. RecSys(2012) [RS] [PDF] [3]. Distributed Representations of Words and Phrases and their Compositionality. NIPS(2013) [NLP] [PDF] [4]. word2vec Explained: Deriving Mikolov et al.'s Negative-Sampling Word-Embedding Method. arXiv(2014) [NLP] [PDF] [5]. Deepwalk: Online learning of social representations. KDD(2014) [GRL] [PDF] [6]. LINE: Large-scale Information Network Embedding. WWW(2015) [GRL] [PDF] [7]. Context- and Content-aware Embeddings for Query Rewriting in Sponsored Search. SIGIR(2015) [NLP] [PDF] [8]. node2vec: Scalable Feature Learning for Networks. KDD(2016) [NLP] [PDF] [9]. Fast Matrix Factorization for Online Recommendation with Implicit Feedback. SIGIR(2016) [RS] [PDF] [10]. Word2vec applied to Recommendation: Hyperparameters Matter. RecSys(2018) [RS] [PDF] [11]. General Knowledge Embedded Image Representation Learning. TMM(2018) [CV] [PDF] [12]. Alleviating Cold-Start Problems in Recommendation through Pseudo-Labelling over Knowledge Graph. WSDM(2021) [RS] [PDF] 2.2 强负例采样 (Hard Negative Sampling)静态负采样方法不随训练发生变化,无法动态地适应并调整候选负例的分布,也就难以挖掘更有利的负样本。尽管我们没有显式的负例标签,但在训练过程中,模型对每个候选负例的分数是可以被利用的。 所谓强负例 (hard negative) 的 hard 取决于模型,那些被错误分类的样例,或是预测得分更高的负例,与改进模型结果更为相关。我们可以把这种思路类比到小明做题,得分低的负例是小明已经掌握的简单题,得分高的负例是小明不太会做的提高题或是错题,这些对于小明来说相对 hard 的题更能帮助他掌握所学知识。 Hard Negative Sampling,又称 Hard Example Mining,早在 1998 年 CV 领域的人脸识别 [13] 中,研究者们就开始将分类器识别错误的图片加入到负例集来提升训练质量。  ▲Example-based learning for view-based human face detection [13]
▲Example-based learning for view-based human face detection [13]
在近十年的深度学习中,无论是 CV 领域的图片分类 [16, 28]、目标检测 [21, 23, 26, 29]、跨模态学习 [37],还是 NLP 领域的语言模型 [14]、问答系统 [19]、结点表示 [30],或是推荐系统 [15, 17, 18, 20, 24, 31, 33, 35],或是知识图谱的表示学习 [25, 27, 36],都可以通过强负例采样提升模型的训练结果。  ▲Graph Convolutional Neural Networks for Web-Scale Recommender Systems [70]
▲Graph Convolutional Neural Networks for Web-Scale Recommender Systems [70]
无论哪个领域,挖掘强负例的最常见方法都是选择离 anchor/user/query 最近的样本(即在 embedding 空间中最相似的样本)。 既然锚点样本对负例选择有帮助,那么自然而然可以想到正例也能为配对的负例提供相似度的信息。[19] 在问答系统中选择与正例最相似的样本作为负例,[25, 27, 36] 中为知识图谱三元组选取负例时也是选择离正例最接近的实体。KGPolicy [73] 既考虑了与 anchor 的相似度,又考虑了与 positive example 的相似度,将两者相加作为选择强负例的标准。 不过,上述方法仍然是选择已有的样例作为强负例,那么我们能不能根据需要生成 (synthesize) 所需强负例呢? 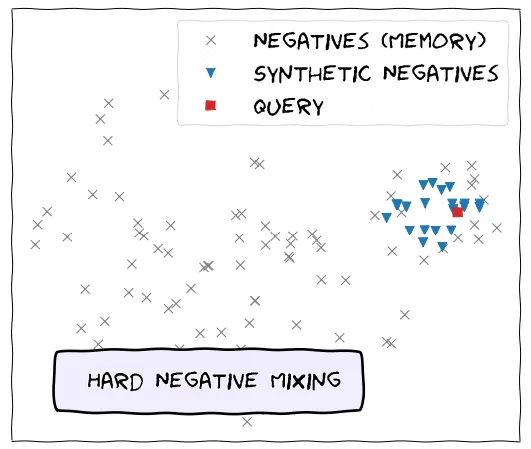 ▲Hard Negative Mixing for Contrastive Learning [32]
▲Hard Negative Mixing for Contrastive Learning [32]
答案是可以的,MoCHi [32] 在对比学习的任务中直接合成强负例,通过 Hard Negative Mixing 的方式融合了现有强负例与 query 的表示,从 embedding 空间得到了更能为训练带来增益的负例。 也就是说,我们不一定要执着于学习已知负例的分布,还可以从 synthetic sampling 的角度出发合成我们需要的负样本表示。 [13]. Example-based learning for view-based human face detection. TPAMI(1998) [CV] [PDF] [14]. Adaptive Importance Sampling to Accelerate Training of a Neural Probabilistic Language Model. T-NN(2008) [NLP] [PDF] [15]. Optimizing Top-N Collaborative Filtering via Dynamic Negative Item Sampling. SIGIR(2013) [RS] [PDF] [16]. Bootstrapping Visual Categorization With Relevant Negatives. TMM(2013) [CV] [PDF] [17]. Improving Pairwise Learning for Item Recommendation from Implicit Feedback. WSDM(2014) [RS] [PDF] [18]. Improving Latent Factor Models via Personalized Feature Projection for One Class Recommendation. CIKM(2015) [RS] [PDF] [19]. Noise-Contrastive Estimation for Answer Selection with Deep Neural Networks. CIKM(2016) [NLP] [PDF] [20]. RankMBPR: Rank-aware Mutual Bayesian Personalized Ranking for Item Recommendation. WAIM(2016) [RS] [PDF] [21]. Training Region-Based Object Detectors With Online Hard Example Mining. CVPR(2016) [CV] [PDF] [22]. Hard Negative Mining for Metric Learning Based Zero-Shot Classification. ECCV(2016) [ML] [PDF] [23]. Vehicle detection in aerial images based on region convolutional neural networks and hard negative example mining. Sensors(2017) [CV] [PDF] [24]. WalkRanker: A Unified Pairwise Ranking Model with Multiple Relations for Item Recommendation. AAAI(2018) [RS] [PDF] [25]. Bootstrapping Entity Alignment with Knowledge Graph Embedding. IJCAI(2018) [KGE] [PDF] [26]. Improving Occlusion and Hard Negative Handling for Single-Stage Pedestrian Detectors. CVPR(2018) [CV] [PDF] [27]. NSCaching: Simple and Efficient Negative Sampling for Knowledge Graph Embedding. ICDE(2019) [KGE] [PDF] [28]. Meta-Transfer Learning for Few-Shot Learning. CVPR(2019) [CV] [PDF] [29]. ULDor: A Universal Lesion Detector for CT Scans with Pseudo Masks and Hard Negative Example Mining. ISBI(2019) [CV] [PDF] [30]. Distributed representation learning via node2vec for implicit feedback recommendation. NCA(2020) [NLP] [PDF] [31]. Simplify and Robustify Negative Sampling for Implicit Collaborative Filtering. arXiv(2020) [RS] [PDF] [32]. Hard Negative Mixing for Contrastive Learning. arXiv(2020) [CL] [PDF] [33]. Bundle Recommendation with Graph Convolutional Networks. SIGIR(2020) [RS] [PDF] [34]. Supervised Contrastive Learning. NIPS(2020) [CL] [PDF] [35]. Curriculum Meta-Learning for Next POI Recommendation. KDD(2021) [RS] [PDF] [36]. Boosting the Speed of Entity Alignment 10×: Dual Attention Matching Network with Normalized Hard Sample Mining. WWW(2021) [KGE] [PDF] [37]. Hard-Negatives or Non-Negatives? A Hard-Negative Selection Strategy for Cross-Modal Retrieval Using the Improved Marginal Ranking Loss. ICCV(2021) [CV] [PDF] 2.3 对抗式负采样 (Adversarial Sampling)生成对抗网络 (GAN, viz. Generative Adversarial Network) 是近几年热门的一种无监督算法,多次出现在各类顶会论文中。对抗式负采样方法通常基于 GAN 来选择负例,为负采样方法注入了新的活力。 与 GAN 类似,对抗式负采样方法往往也有一个生成器 (generator) 和一个判别器 (discriminator),其中生成器充当采样器生成样例以混淆判别器,而判别器需要判断给定的样例是正例还是生成的样例。理想的均衡状态是判别器生成非常近似于正例的样例,而判别器无法区分正例与生成器产生的样例。 对抗式负采样的关键在于对抗式的采样器,它在 generator 和 discriminator 之间进行 minimax 博弈,从而更好地挖掘强数据中的负例信息。从本质上来说,对抗式负采样的目的仍然是为了学习到更好的负例分布。 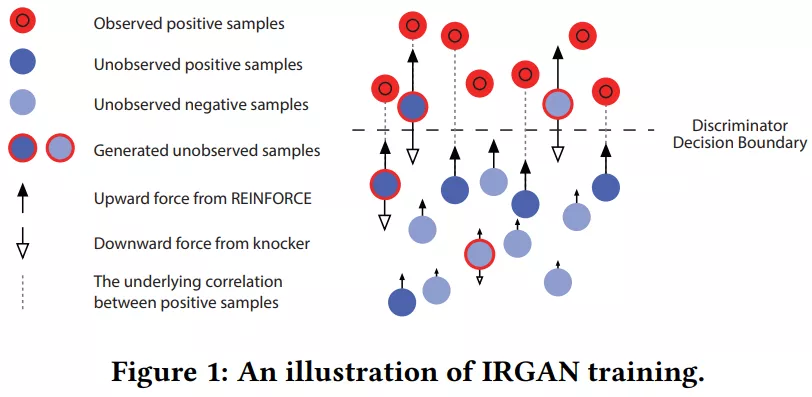 ▲IRGAN: A Minimax Game for Unifying Generative and Discriminative Information Retrieval Models [39]
▲IRGAN: A Minimax Game for Unifying Generative and Discriminative Information Retrieval Models [39]
然而,对抗式负采样方法的缺点也很突出,复杂的框架、不稳定的训练结果和较长的训练时间都极大地限制了该方法的应用场景,生成器与对抗器之间的博弈也不一定能收敛到理想的纳什均衡状态,对抗式负采样方法仍有探索和改进的空间。 [38]. Deep Generative Image Models using a Laplacian Pyramid of Adversarial Networks. NIPS(2015) [CV] [PDF] [39]. IRGAN: A Minimax Game for Unifying Generative and Discriminative Information Retrieval Models. SIGIR(2017) [IR] [PDF] [40]. SeqGAN: Sequence Generative Adversarial Nets with Policy Gradient. AAAI(2017) [NLP] [PDF] [41]. KBGAN: Adversarial Learning for Knowledge Graph Embeddings. NAACL(2018) [KGE] [PDF] [42]. Neural Memory Streaming Recommender Networks with Adversarial Training. KDD(2018) [RS] [PDF] [43]. GraphGAN: Graph Representation Learning with Generative Adversarial Nets. AAAI(2018) [GRL] [PDF] [44]. CFGAN: A Generic Collaborative Filtering Framework based on Generative Adversarial Networks. CIKM(2018) [RS] [PDF] [45]. Adversarial Contrastive Estimation. ACL(2018) [NLP] [PDF] [46]. Incorporating GAN for Negative Sampling in Knowledge Representation Learning. AAAI(2018) [KGE] [PDF] [47]. Exploring the potential of conditional adversarial networks for optical and SAR image matching. IEEE J-STARS(2018) [CV] [PDF] [48]. Deep Adversarial Metric Learning. CVPR(2018) [CV] [PDF] [49]. Adversarial Detection with Model Interpretation. KDD(2018) [ML] [PDF] [50]. Adversarial Sampling and Training for Semi-Supervised Information Retrieval. WWW(2019) [IR] [PDF] [51]. Deep Adversarial Social Recommendation. IJCAI(2019) [RS] [PDF] [52]. Adversarial Learning on Heterogeneous Information Networks. KDD(2019) [HIN] [PDF] [53]. Regularized Adversarial Sampling and Deep Time-aware Attention for Click-Through Rate Prediction. CIKM(2019) [RS] [PDF] [54]. Adversarial Knowledge Representation Learning Without External Model. IEEE Access(2019) [KGE] [PDF] [55]. Adversarial Binary Collaborative Filtering for Implicit Feedback. AAAI(2019) [RS] [PDF] [56]. ProGAN: Network Embedding via Proximity Generative Adversarial Network. KDD(2019) [GRL] [PDF] [57]. Generating Fluent Adversarial Examples for Natural Languages. ACL(2019) [NLP] [PDF] [58]. IPGAN: Generating Informative Item Pairs by Adversarial Sampling. TNLLS(2020) [RS] [PDF] [59]. Contrastive Learning with Adversarial Examples. arXiv(2020) [CL] [PDF] [60]. PURE: Positive-Unlabeled Recommendation with Generative Adversarial Network. KDD(2021) [RS] [PDF] [61]. Negative Sampling for Knowledge Graph Completion Based on Generative Adversarial Network. ICCCI(2021) [KGE] [PDF] [62]. Synthesizing Adversarial Negative Responses for Robust Response Ranking and Evaluation. arXiv(2021) [NLP] [PDF] [63]. Adversarial Feature Translation for Multi-domain Recommendation. KDD(2021) [RS] [PDF] [64]. Adversarial training regularization for negative sampling based network embedding. Information Sciences(2021) [GRL] [PDF] [65]. Adversarial Caching Training: Unsupervised Inductive Network Representation Learning on Large-Scale Graphs. TNNLS(2021) [GRL] [PDF] [66]. A Robust and Generalized Framework for Adversarial Graph Embedding. arxiv(2021) [GRL] [PDF] [67]. Instance-wise Hard Negative Example Generation for Contrastive Learning in Unpaired Image-to-Image Translation. ICCV(2021) [CV] [PDF] 2.4 基于图的负采样 (Graph-based Sampling)如果说前面介绍的 Hard Negative Sampling 和 Adversarial Sampling 充分利用的是样例在 embedding 空间的语义 (semantic) 信息,那么基于图的负采样方法则是进一步结合样例在图上的结构 (structural) 信息。 GNEG [69] 是 word2vec 负采样方法的改进,先根据语料库中词语的共现关系构造共现 (co-occurrence) 网络,再在通过目标结点上的随机游走获得更强的负例。RWS [68]、SamWalker [71] 和 SamWalker++ [75] 也是类似的随机游走 (Random Walking) 策略,只是应用的领域为推荐系统。 KGPolicy [73] 利用知识图谱的辅助信息和强化学习的方法寻找高质量的负例,DSKReG [76] 则是在知识图谱上根据相连的关系和结点嵌入计算邻居结点的相关性分数。 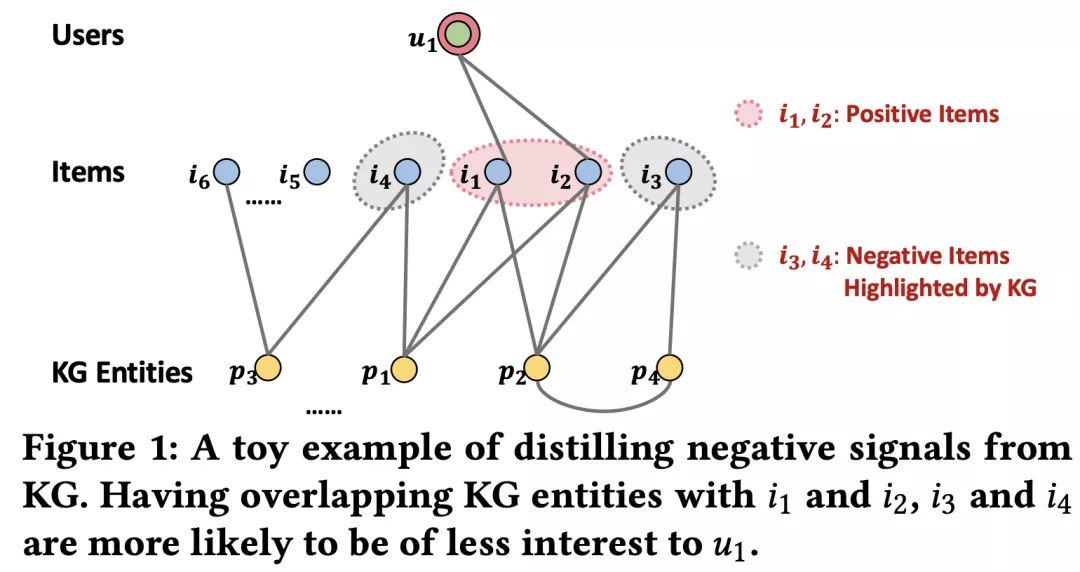 ▲Reinforced Negative Sampling over Knowledge Graph for Recommendation [73]
▲Reinforced Negative Sampling over Knowledge Graph for Recommendation [73]
作为 GNN 的归纳变体,PinSage [70] 提出基于 PageRank 分数对强负例进行采样,相比随机游走进一步利用了图上的结构信息。 马尔可夫链蒙特卡罗负采样(MCNS)[72] 是从理论上分析负采样在链路预测中的影响的先驱。基于推导出的理论,MCNS 提出通过近似正分布来对负样本进行采样,根据图上的结构相关性重新设计正负例的样本分布,并通过 Metropolis-Hastings 算法加速该过程。 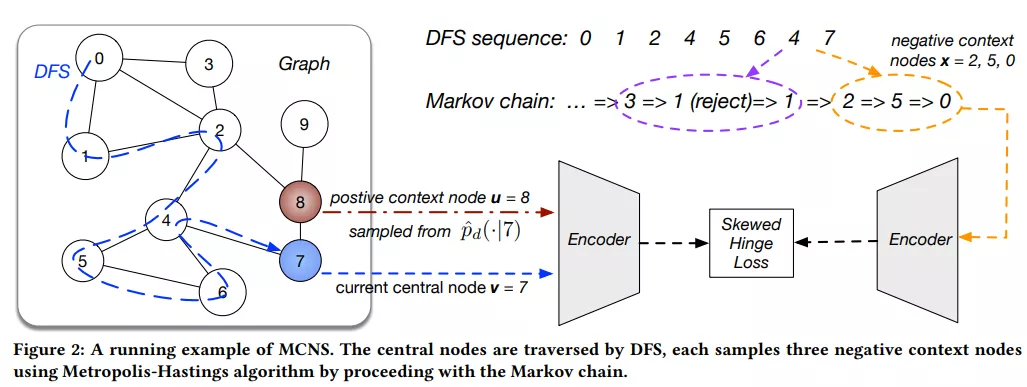 ▲Understanding Negative Sampling in Graph Representation Learning [72]
▲Understanding Negative Sampling in Graph Representation Learning [72]
类似 MoCHi [32] 的合成机制,MixGCF [74] 设计了两种策略:正例混合 (positive mixing) 和邻域混合 (hop mixing)。positive mixing 通过注入正例的嵌入使得原始负样本获得正例的表示信息,而 hop mixing 通过 GNN 聚合邻域生成信息增强的负例,在基于图神经网络推荐系统的采样方法中取得了 SOTA 的结果。 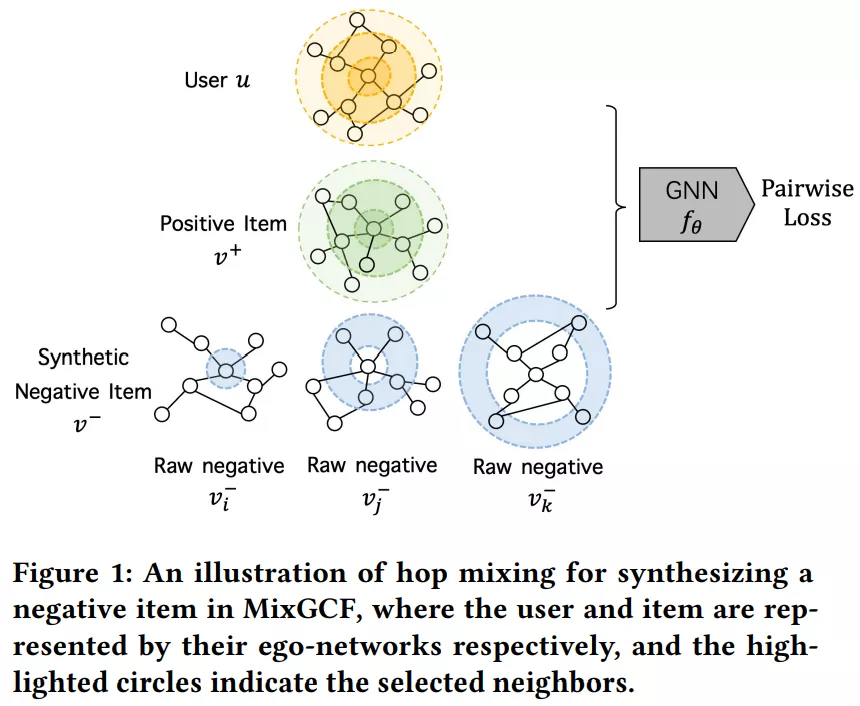 ▲MixGCF: An Improved Training Method for Graph Neural Network-based Recommender Systems [74]
▲MixGCF: An Improved Training Method for Graph Neural Network-based Recommender Systems [74]
[68]. ACRec: a co-authorship based random walk model for academic collaboration recommendation. WWW(2014) [RS] [PDF] [69]. GNEG: Graph-Based Negative Sampling for word2vec. ACL(2018) [NLP] [PDF] [70]. Graph Convolutional Neural Networks for Web-Scale Recommender Systems. KDD(2018) [RS] [PDF] [71]. SamWalker: Social Recommendation with Informative Sampling Strategy. WWW(2019) [RS] [PDF] [72]. Understanding Negative Sampling in Graph Representation Learning. KDD(2020) [GRL] [PDF] [73]. Reinforced Negative Sampling over Knowledge Graph for Recommendation. WWW(2020) [RS] [PDF] [74]. MixGCF: An Improved Training Method for Graph Neural Network-based Recommender Systems. KDD(2021) [RS] [PDF] [75]. SamWalker++: recommendation with informative sampling strategy. TKDE(2021) [RS] [PDF] [76]. DSKReG: Differentiable Sampling on Knowledge Graph for Recommendation with Relational GNN. CIKM(2021) [RS] [PDF] 2.5 引入额外信息的负采样 (Additional Data Enhanced Sampling)本小节主要针对推荐系统中引入额外信息的负采样,一些工作利用社交网络中的联系 [77, 78, 85, 86]、用户的地理位置 [80, 81, 84]、商品的类别信息 [87] 以及额外的交互数据,例如用户浏览但没有被点击的商品 (viewed but non-clicked) [82, 83],以及用户点击了却没有购买的商品 (clicked but non-purchased) [79] 来增强负例的选取。 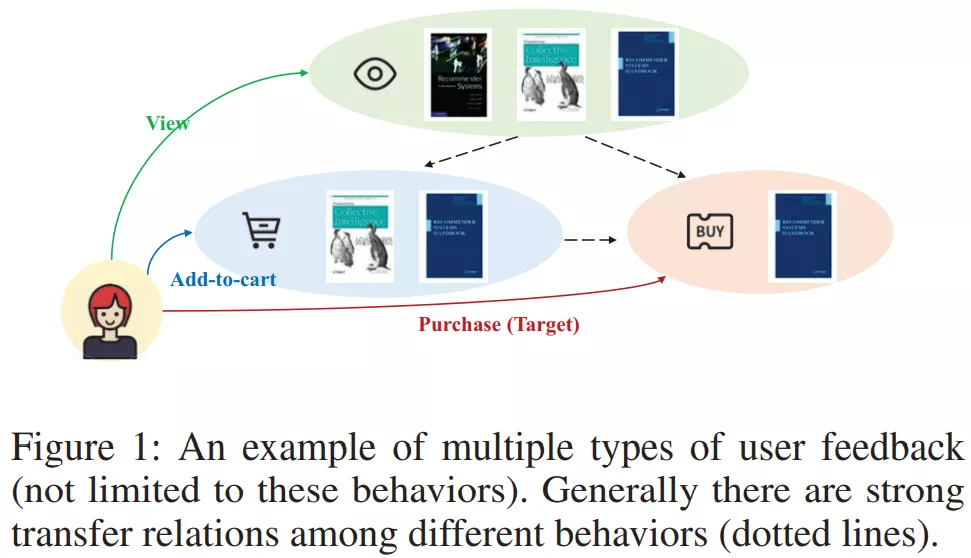 ▲Efficient Heterogeneous Collaborative Filtering without Negative Sampling for Recommendation [99]
▲Efficient Heterogeneous Collaborative Filtering without Negative Sampling for Recommendation [99]
在工业的推荐场景中,不同的行为 (比如浏览、点击、添加购物车、购买) 是建模用户偏好的关键。 [77]. Leveraging Social Connections to Improve Personalized Ranking for Collaborative Filtering. CIKM(2014) [RS] [PDF] [78]. Social Recommendation with Strong and Weak Ties. CIKM(2016) [RS] [PDF] [79]. Bayesian Personalized Ranking with Multi-Channel User Feedback. RecSys(2016) [RS] [PDF] [80]. Joint Geo-Spatial Preference and Pairwise Ranking for Point-of-Interest Recommendation. ICTAI(2017) [RS] [PDF] [81]. A Personalised Ranking Framework with Multiple Sampling Criteria for Venue Recommendation. CIKM(2017) [RS] [PDF] [82]. An Improved Sampling for Bayesian Personalized Ranking by Leveraging View Data. WWW(2018) [RS] [PDF] [83]. Reinforced Negative Sampling for Recommendation with Exposure Data. IJCAI(2019) [RS] [PDF] [84]. Geo-ALM: POI Recommendation by Fusing Geographical Information and Adversarial Learning Mechanism. IJCAI(2019) [RS] [PDF] [85]. Bayesian Deep Learning with Trust and Distrust in Recommendation Systems. WI(2019) [RS] [PDF] [86]. Socially-Aware Self-Supervised Tri-Training for Recommendation. arXiv(2021) [RS] [PDF] [87]. DGCN: Diversified Recommendation with Graph Convolutional Networks. WWW(2021) [RS] [PDF] 3. 未来展望 3.1 伪负例问题 (False Negative Problem)现有基于负采样方法的研究集中在如何挖掘强负例,较少地关注伪负例 (False Negative) 问题。 一方面,我们希望模型能从一定的强负例中挖掘信息;另一方面,我们不希望模型总是将未来可能感兴趣的样例视作负例。两者的平衡不应人为去调整设定,而应该让模型具有一定的鉴别能力。 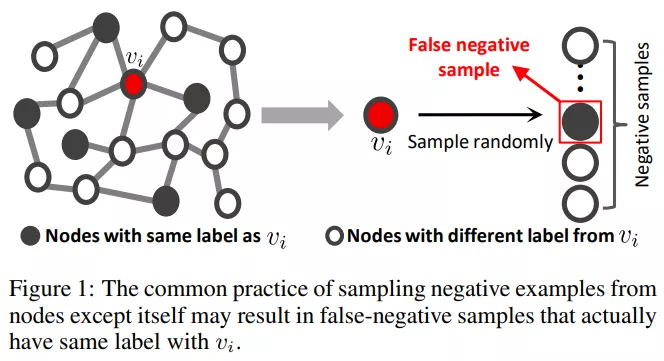 ▲Graph Debiased Contrastive Learning with Joint Representation Clustering [89]
▲Graph Debiased Contrastive Learning with Joint Representation Clustering [89]
SRNS [31] 从统计学的角度观测到数据集中的伪负例在训练过程中方差较小,而强负例具有较高的方差。根据这一现象,文章结合评分函数和样例多轮得分的标准差,在新的得分上进行采样得到强负例。然而,SRNS 文中提到的负例现象只体现在某些数据集上,该启发式的统计学思路也缺少理论的支撑。 ASA [90] 在强负例采样中不是选择得分最高的负例,而是考虑对应的正样本分数,选择得分不超过正样本的难度适中的负例来缓解伪负例问题。在对比学习中,[88] 提出一种自监督对比学习框架逐步检测并删除伪负例,而 [89] 通过图表示学习中的聚类结果有效地减少伪负例样本。 [88]. Incremental False Negative Detection for Contrastive Learning. arXiv(2021) [CL] [PDF] [89]. Graph Debiased Contrastive Learning with Joint Representation Clustering. IJCAI(2021) [GRL & CL] [PDF] [90]. Relation-aware Graph Attention Model With Adaptive Self-adversarial Training. AAAI(2021) [KGE] [PDF] 3.2 融入课程学习 (Curriculum Learning)仍然是小明做题的例子,如果小明只练习简单的加减乘除,即使平时练习次次满分,也无法在高中的数学考试中取得佳绩。但如果小明天天做高考压轴题而不巩固基础,一样无法拿到高分。换句话说,模型训练需要强负例,但是不能只有最强的负例。 为了均衡较强与较弱的负例,融入课程学习 (Curriculum Learning) 是个不错的选择。[91, 92] 的研究都是让模型先从简单的负例学起,逐渐增大负例的强度,而其他领域、其他任务中融入课程学习进行负例选取的结果值得我们去探索。 [91]. On The Power of Curriculum Learning in Training Deep Networks. ICML(2016) [CV] [PDF] [92]. Graph Representation with Curriculum Contrastive Learning. IJCAI(2021) [GRL & CL] [PDF] 3.3 负采样比例 (Negative Sampling Ratio)负采样方法主要是为了提升负例质量,而负采样比例则是决定了负例的数量。 [93] 在图像分类的对比学习中定量分析了各种负例的重要性;SimpleX [94] 表明,即使是最基础的协同过滤方法,在合适的负采样比例与损失函数的加持下,也能优于目前最优的推荐算法;[95] 对基于 InfoNCE 模型训练中的负例数量进行了分析,提出了一种动态适应采样比例的负采样方法。就目前的研究来看,负采样比例也是一个尚待深挖的方向。 [93]. Are all negatives created equal in contrastive instance discrimination. arXiv(2020) [CL] [PDF] [94]. SimpleX: A Simple and Strong Baseline for Collaborative Filtering. CIKM(2021) [RS] [PDF] [95]. Rethinking InfoNCE: How Many Negative Samples Do You Need. arXiv(2021) [CL] [PDF] 3.4 去偏采样 (Debiased Sampling)在只能访问正例和未标记数据 (Positive-Unlabeled) 的场景下,采样不可避免会有一定的偏差,比如前面提到的 false negative 问题就是负采样中一种典型的采样偏差 (sample bias)。 [96] 首先对比了 Biased 和 Unbiased 方法的结果差异,并提出了一个去偏差的对比学习目标,一定程度上纠正了负例的采样偏差,在 CV、NLP 和强化学习任务上验证了方法的有效性。针对推荐系统曝光偏差对采样的影响,CLRec [97] 从理论上证明了对比损失的流行度选择相当于通过逆倾向加权减少曝光偏差,为理解对比学习的有效性提供了新的视角。 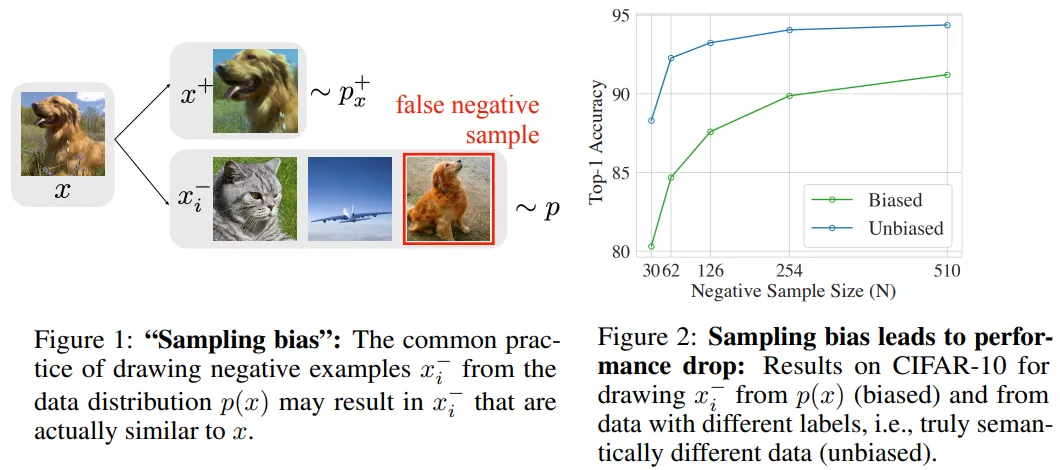 ▲Debiased Contrastive Learning [96]
▲Debiased Contrastive Learning [96]
[96]. Debiased Contrastive Learning. NIPS(2020) [CL] [PDF] [97]. Contrastive Learning for Debiased Candidate Generation in Large-Scale Recommender Systems. KDD(2021) [RS] [PDF] 3.5 无采样 (Non-Sampling)前面都是考虑负采样方法的应用和展望,但负采样真的是必须的吗?[98, 99, 100] 分别在 CV、RS 和 KGE 领域提出了无需采样 (Non-Sampling) 的训练方法。 [98] 基于傅立叶变换推导出一种对 Gram 矩阵进行块对角化的变换,同时消除冗余并划分学习问题。重点在于,它允许使用数千张图像集中的所有潜在样本进行训练,通过考虑全集,在一轮迭代中就可以生成最优解,而强负采样方法需要好几轮才能达到相同的结果。 EHCF [99] 认为采样不适合学习推荐系统中的异构行为数据 (heterogeneous scenarios),并推导出一种有效的优化方法,以可控的时间复杂度解决了从整个数据中学习神经模型的挑战性问题。 NS-KGE [100] 认为在知识图谱的嵌入学习中,以前基于负采样的学习方法仅考虑负实例的子集,虽然有助于降低模型学习的时间复杂度,但由于采样过程的不确定性,这可能无法提供稳定的模型性能。NS-KGE 在模型学习中考虑 KG 中的所有负实例,从而避免负采样,并利用数学推导来降低无采样损失函数的复杂性。实验结果表明 NS-KGE 框架可以在效率和准确性方面取得更好的性能。 负采样方法是辅助模型训练的手段而不是目的,更不是必需品。倘若我们能在可承受的计算负荷下自适应地考虑所有候选负例,那么不进行负采样的无采样 (Non-Sampling) 方法也未尝不可。 [98]. Beyond Hard Negative Mining: Efficient Detector Learning via Block-Circulant Decomposition. ICCV(2013) [CV] [PDF] [99]. Efficient Heterogeneous Collaborative Filtering without Negative Sampling for Recommendation. AAAI(2020) [RS] [PDF] [100]. Efficient Non-Sampling Knowledge Graph Embedding. WWW(2021) [KGE] [PDF] 4. 小结负采样 (Negative Sampling) 方法最初是被用于加速 Skip-Gram 模型的训练,后来被广泛应用于自然语言处理 (NLP)、计算机视觉 (CV) 和推荐系统 (RS) 等领域,在近两年的对比学习 (Contrastive Learning) 研究中也发挥了重要作用。本文聚焦于负采样方法,将各领域的相关工作分为五类进行介绍,并展望了未来的研究方向。 笔者将文中涉及的 100 篇论文整理在了 RUC AI Box 小组的 GitHub 中,读者也可以在论文列表中快捷地找到论文的 PDF 链接。本仓库将继续关注负采样方法 (Negative Sampling) 的研究进展并持续更新,欢迎 Star ~ https://github.com/RUCAIBox/Negative-Sampling-Paper
加入卖萌屋NLP/IR/Rec与求职讨论群 后台回复关键词【顶会】 获取ACL、CIKM等各大顶会论文集! 
|

 后台回复关键词【入群】
后台回复关键词【入群】【本文地址】