二叉树的存储方式【顺序储存(数组)、链式存储、邻接表存储等】 |
您所在的位置:网站首页 › 链式特点 › 二叉树的存储方式【顺序储存(数组)、链式存储、邻接表存储等】 |
二叉树的存储方式【顺序储存(数组)、链式存储、邻接表存储等】
|
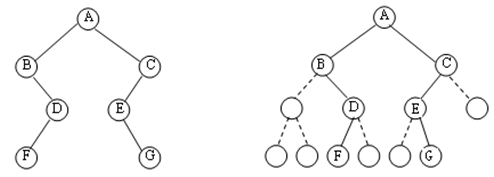
其他二叉树知识!二叉树知识汇总 目录 前言: 1.顺序存储结构 2.链式存储结构 3.二维数组直接存储 4.邻接表存储 前言:顺序存储和链式存储是经典讲解的内容,本文做简单理论介绍,而对于后两种:二维数组直接存储和邻接表存储,通过例题和代码做更深入更实用的讲解。 1.顺序存储结构二叉树的顺序存储,就是用一组连续的存储单元存放二叉树中的结点。因此,必须把二叉树的所有结点安排成为一个恰当的序列,结点在这个序列中的相互位置能反映出结点之间的逻辑关系,用编号的方法从树根起,自上层至下层,每层自左至右地给所有结点编号,缺点是有可能对存储空间造成极大的浪费,在最坏的情况下,一个深度为k且只有k个结点的右单支树需要2k-1个结点存储空间。 依据二叉树的性质,完全二叉树和满二叉树采用顺序存储比较合适,树中结点的序号可以唯一地反映出结点之间的逻辑关系,这样既能够最大可能地节省存储空间,又可以利用数组元素的下标值确定结点在二叉树中的位置,以及结点之间的关系。 对于一般的二叉树,如果仍按从上至下和从左到右的顺序将树中的结点顺序存储在一维数组中,则数组元素下标之间的关系不能够反映二叉树中结点之间的逻辑关系,只有增添一些并不存在的空结点,使之成为一棵完全二叉树的形式,然后再用一维数组顺序存储。 例子,如图a,b,c:
(a) 一棵二叉树 (b) 改造后的完全二叉树
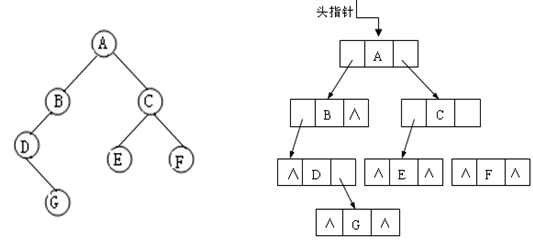
(c) 改造后完全二叉树顺序存储状态 显然,这种存储对于需增加许多空结点才能将一棵二叉树改造成为一棵完全二叉树的存储时,会造成空间的大量浪费,不宜用顺序存储结构。 2.链式存储结构 struct Node{ int data; Node* leftchild; Node* rightchild; };二叉树的链式存储结构是指,用链表来表示一棵二叉树,即用链来指示元素的逻辑关系。 通常的方法是链表中每个结点由三个域组成,数据域和左右指针域,左右指针分别用来给出该结点左孩子和右孩子所在的链结点的存储地址。其结点结构为: 其中,data域存放某结点的数据信息;lchild与rchild分别存放指向左孩子和右孩子的指针,当左孩子或右孩子不存在时,相应指针域值为空(用符号∧或NULL表示)。利用这样的结点结构表示的二叉树的链式存储结构被称为二叉链表。 例子如图: (a) 一棵二叉树 (b) 二叉链表存储结构 为了方便访问某结点的双亲,还可以给链表结点增加一个双亲字段parent,用来指向其双亲结点。每个结点由四个域组成,其结点结构为: 这种存储结构既便于查找孩子结点,又便于查找双亲结点;但是,相对于二叉链表存储结构而言,它增加了空间开销。利用这样的结点结构表示的二叉树的链式存储结构被称为三叉链表。 3.二维数组直接存储若是题目直接给出了每个节点的左右孩子,可以直接用二维数组存储,不用建树,在遍历以及其他操作时,可以直接使用这个二维数组。 例题:洛谷求二叉树的深度 https://www.luogu.com.cn/problem/P4913
代码: #include using namespace std; const int MaxN=1000050; int son[MaxN][2]; int dfs(int x){ if (x==0) return 0; int l=dfs(son[x][0]); int r=dfs(son[x][1]); return max(l,r)+1; } int main(){ int n; cin>>n; for (int i=1; i>son[i][0]>>son[i][1]; } coutroot; for (int i=1; i>x>>y; build(x,y); build(y,x); } dfs(root,0); for (int i=1; i |

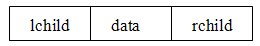


【本文地址】