重疾险的逆选择风险识别 – 天云数据 |
您所在的位置:网站首页 › 重疾保险选择 › 重疾险的逆选择风险识别 – 天云数据 |
重疾险的逆选择风险识别 – 天云数据
|
背景
随着我国经济的发展与民众生活水平的提高,人口老龄化逐步加剧,居民健康意识不断增强,对保险保障的需求逐步释放,消费者越来越重视健康保险。同时,国家出台一系列政策支持商业健康保险的发展,我国健康险市场进入快速发展阶段,健康险增速领先于寿险及意外伤害险。仅在2009至2018的十年间,其保费收入从574亿元增长至5448.13亿元,暴涨近10倍,健康险保费的增长主要来自于重疾险。商业重大疾病保险可以作为基本医疗保险和大病保险的有效补充,保费占比近六成,是商业健康险中最重要的险种。
然而重疾险市场起步不久,各项指标体系和制度还不完善,存在明显的信息不对称现象,进而导致大量的逆向选择问题和道德风险。重疾险赔付件数10年内增长6倍,赔付金额10年间增长8倍,投保人在近期保单年度内出险情况无法得到有效控制,总体上存在明显的逆选择,重疾险逆选择缓慢地变得严重。目前,保险公司对于客户逆选择的防范非常被动,很大程度上依赖投保时客户能够如实告知其健康状况,但数据证明带病投保的客户仍然不在少数。 现状
在保险市场上的均衡状态下,高风险的人倾向于以高价购买更多的保障(如更大的保险金额或更小的免赔额),低风险的被保险人倾向购买更少的保障。即,被保险人所购买的保障与其风险类型存在正相关的关系,保险业将这种相关性作为检验保险市场逆选择的标准。
然而对于重疾险市场,投保人购买的保障(或者投保人的行为特征)和风险类型之间的相关性并不能反映重疾险市场的逆选择。一方面,较难精确判断投保人的风险类型,大多是在对样本进行分类之后,根据经验数据计算各样本组的重疾发生率,并据此判断各样本组的风险类型。另一方面,很难选择合适的变量来衡量投保人所购买重疾险的保障程度。常用的保险金额不是衡量重疾险保障高低的唯一因素,投保人所购买的保险金额除了与投保人的风险类型有关以外,还与很多其它因素有关,如风险偏好、购买能力等。同时,重疾险保障的重疾种类多达上百种,不同重疾的全程治疗费用相差很大。如果存在逆选择,投保人则会根据自己易发重疾的医疗费用来确定相应的保险金额。因此,不同重疾投保人所购买的保险金额相差很大,且缺乏可比较的基础。
而对于传统的逆选择问题研究,大都是基于对单张保单的建模,这种模型对检验期限较短的险种效果较好,例如车险和短期健康险等。然而,重疾险大多都是保险期限较长的险种,承保时间持续数十年以上。并且,由于我国重疾险的起步比较晚,重疾经验数据的观察期往往只有数年,属于删失比例较高的删失数据。因此,通过经验数据的分析只能观察到很小一部分保单的出险情况,此时这种建模方法显然会有较大的偏差。
因此,对于重疾险这种较为特殊的长期险种,用于检验短期险种逆选择的方法不太适用。通常无法准确衡量重疾险投保人所购买的保障,也无法准确衡量重疾险投保人的风险类型,更无法通过这两个变量之间的相关性来判断重疾险是否存在逆选择,因此必须根据重疾险的特征设计新的检验方法。
解决方案
在重疾险领域,保险行业结合医学界的经验发现,如果投保人未履行告知义务,曾经罹患过重大疾病或带病投保,或患有先天性的疾病,或具有亚健康的状态,则该投保人在低保单年度(如自保单生效开始两年内)确诊患有重疾的概率明显高于健康的被保险人。因此,可以通过计算N年保单年度(一般为前两年内)的重疾发生率来检验重疾险逆选择。例如,在《中国人身保险业重大疾病发生率表编制报告》的编制过程中,为防范逆选择风险、减少免责期及核保选择效应的影响,统计数据不包括第一保单年度经验数据。 采用这种方法评估重疾险逆选择程度,需要有足够大的数据样本。因为生效期两年内的保单占比较小,若样本总数不足,则计算的重疾发生率可信度较低。天云重疾率模型在建模时满足此种检验方法的条件。一方面,模型使用的一亿重疾数据,时间跨度20年以上,共有正常理赔800余万条数据样本。样本容量较大,数据质量整体较好,能够充分代表重疾险市场的现状。另一方面,模型充分挖掘样本数据信息价值,从保单的3000个字段数据中筛选并衍生出近300个维度指标精准预测重疾发生率。 模型以人为单位将其所有保单信息在时间轴上拆分叠加,充分关注保险人低保年年度数据变化,预测被保险人投保两年内的重疾发生率,并基于重疾发生率变化折算为被保人的综合逆选择风险值。通过量化风险值,保险公司进行客户风险识别,更精细化进行客户分群,进行精细化风险管理。 对于影响我国重疾险市场逆选择程度的各种因素,天云提供的建模工具,可直观分析各种因素对逆选择的影响程度。重疾率模型的每一个变量,如传统的性别、年龄、地区因素,以及被保险人BMI,吸烟等健康指标等因素,提供单变量分析、多变量交叉分析等模型评估服务,显式地评估各变量重要性及交叉变量影响程度,便于保险公司及精算进行业务解释与分析。 当然,保险公司也可不通过低保单年度出险的业务定义,选择其他方法评估重疾险逆选择程度。天云可提供包括进行业务咨询,项目建模及模型评估分析等完整的流程化服务。对于不同模型场景以往完全依赖数据科学家手动建模效率较低的问题,通过流程自动化的建模工具,也为后续业务人员更新和维护模型提供了便利。 模型效果与优势
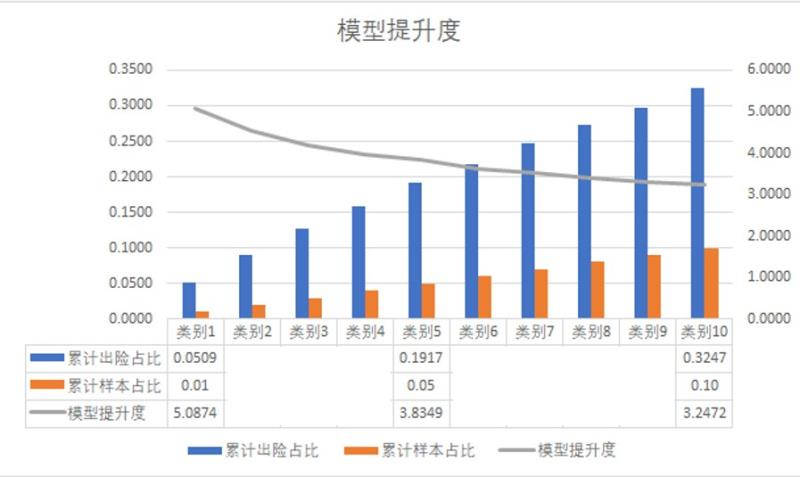
模型可有效区分出头部高风险客户,有效降低保险公司损失。例如下图所示,只需要拒绝1%的保险人投保申请,即可降低5%的逆选择出险理赔率,重疾模型有效提升了5倍客户区分率;同样的,如拒绝5%的高风险客户,即可有效降低19%的逆选择出险理赔率。
同时,通过精细化客户分群,根据客户风险值差异化调整重疾定价,实现将一定的低风险逆选择人群纳入客户服务,转变对于客户逆选择的被动防范,提高客户满意度和行业竞争力。
|
【本文地址】