爬虫爬取酷狗音乐主页歌曲 |
您所在的位置:网站首页 › 酷狗音乐网页版下载链接 › 爬虫爬取酷狗音乐主页歌曲 |
爬虫爬取酷狗音乐主页歌曲
|
一、功能介绍
功能1:利用Python技术爬取酷狗音乐网页版界面,将该网页的所有歌曲、歌手、超链接爬取并打印输出,将页面保存为本地文件,将所获得的所有歌曲、歌手、超链接分别写入名为歌曲清单.txt文件和名为歌手清单.txt文件; 功能2:从所有歌曲中选取一首自己喜欢的歌曲,去访问并提取相关信息,将访问的页面保存为本地文件,包含歌手、作曲人、演唱时间、歌曲简介、该歌曲所在的专辑超链接以及该歌手其他专辑的名字和超链接。 二、代码解读2.1导入所需的库 import requests import re from bs4 import BeautifulSoup 这部分导入了三个库:requests用于发送HTTP请求,re用于正则表达式,BeautifulSoup用于解析HTML。 2.2 设置请求头 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0', } 这部分定义了一个字典,其中包含一个User-Agent头信息,用于模拟一个常见的浏览器访问。这样做的目的是确保服务器认为这是一个真实的浏览器访问,而不是一个自动化脚本。 2.3 定义URL url = 'https://www.kugou.com/' 这里定义了要访问的URL,即酷狗音乐的官网。 2.4 发送GET请求并获取响应 response = requests.get(url=url, headers=headers) response.encoding = 'utf-8' pagetext = response.text 首先,使用requests.get()方法发送GET请求到上面定义的URL,并带上之前设置的headers。然后,设置响应的编码为'utf-8',确保能够正确地解析返回的文本。最后,将响应的内容存储在pagetext变量中。 with open('./kugoufrst.html', 'w', encoding='utf-8') as fp:fp.write(pagetext) print('网页保存结束') 这段代码首先使用Python的内置open函数打开一个名为kugoufrst.html的文件,并以写入模式打开。这意味着如果该文件已经存在,它的内容将被覆盖。然后,它将pagetext变量中的内容写入该文件。最后,它打印出“网页保存结束”的消息。 soup = BeautifulSoup(pagetext, 'lxml') 这行代码创建了一个BeautifulSoup对象,该对象将用于解析HTML。这里,它使用lxml作为解析器,这是Python中一个非常流行的HTML和XML解析器。 # 使用CSS选择器 singers= soup.select('div#content.content .homep_cm_item_st3_a2') songs = soup.select('div#content.content .homep_cm_item_st2 a') 这两行代码使用BeautifulSoup的select方法来查找HTML文档中的特定元素。这些元素是通过CSS选择器来指定的。 第一个选择器div#content.content .homep_cm_item_st3_a2查找ID为content且类为content的div元素下的类为homep_cm_item_st3_a2的子元素,也就是歌手以及歌手链接所在的位置。 第二个选择器div#content.content .homep_cm_item_st2 a查找ID为content且类为content的div元素下的类为homep_cm_item_st2的元素下的所有a元素,也就是歌曲名和歌曲链接所在的位置。 print('--' * 100) 这行代码打印100个连续的破折号,主要用于分隔输出,使输出结果更易读。 print('爬取的歌曲及歌曲超链接') 最后,这行代码打印出“爬取的歌曲及歌曲超链接”的消息。 2.5遍历歌曲链接并获取信息 遍历songs列表中的每一个song元素打印出歌曲的名字,并从song.text中移除换行符,提取song元素的href属性,也就是歌曲的超链接,然后打印出歌曲名和歌曲的链接。具体代码如下所示: for song in songs: print('歌曲名:', (song.text).replace("\n", "") print('歌曲链接:', song['href']) print('-' * 10) 2.6遍历歌手链接并获取信息 遍历singers列表中的每一个singer元素,打印出歌手的名字,提取singer元素的href属性,也就是歌手的超链接,打印出歌手的链接。 print('爬取的歌手及歌手的超链接:') for singer in singers: print('歌手名:', singer.text) print('歌手链接:',singer['href']) print('-' * 10) 2.7将数据写入文件歌手清单和歌曲清单 将歌手的名字和链接写入一个名为“歌手清单.txt”的文件中,将歌手名和歌手链接写入文件歌手清单.txt文件,在文件写入完成后输入文件写入成功。具体代码如下: with open('./歌手清单.txt', 'w', encoding='utf-8') as fp: for singer in singers: fp.write('歌手名:' + (singer.text).replace("\n", "") + ' \t' + '歌手链接:' + singer['href'] + '\n') # 将歌名和歌曲链接写入文件 with open('./歌曲清单.txt', 'w', encoding='utf-8') as fp: for song in songs: fp.write('歌名:' + (song.text).replace("\n", "") + ' \t' + '歌曲链接:' + song['href'] + '\n') print('文件写入成功') 2.8对喜欢歌曲的超链接发起请求 使用索引的方法提提取喜欢歌曲的超链接,在这里我以第一首歌曲为例,定义变量url2表示要访问的网页URL,songs[0]['href']使用索引的方式将对应的歌曲的超链接赋值给url2,使用 requests.get()方法发送GET请求到这个超链接。headers 参数表示发送请求时使用的HTTP头信息,这里 headers是一个之前定义好的字典,包含了要发送的头部信息。response.encoding = 'utf-8'` 设置响应的编码为UTF-8,pagetext1 = response.text获取响应的内容,并赋值给 pagetext1。具体代码如下所示: url2=url2 = songs[0]['href'] response = requests.get(url=url2,headers=headers) response.encoding = 'utf-8' pagetext1 = response.text 2.9提取歌曲相关信息 1.使用正则表达式re.findall()从 pagetext1中查找所有匹配'"encode_album_id":"(.*?)"的字符串,并提取出歌曲的歌单解码值encode_album_id,结果赋值给 album_id。使用字符串格式化构造新的 url1,这个URL基于找到的 album_id[0],第一个匹配的 encode_album_id 值, 使用 requests.get()方法发送GET请求到 url1。获取响应的内容,并赋值给 introduction_page。具体代码如下: album_id = re.findall(r'"encode_album_id":"(.*?)",', pagetext1) url1 = f'https://www.kugou.com/album/info/{album_id[0]}/' res = requests.get(url=url1, headers=headers) introduction_page = res.text 2.保存网页内容到本地文件,使用Python的open()函数,打开一个名为'./喜欢歌曲.html'的文件(如果该文件不存在,Python会自动创建它),使用`'w'`模式,表示写入模式,这意味着如果文件已经存在,它的内容会被覆盖。文件对象赋值给变量fp。使用fp.write(introduction_page),将introduction_page的内容写入到文件中。写入完成后,打印出“网页保存结束”的消息。具体代码如下所示: with open('./喜欢歌曲.html', 'w', encoding='utf-8') as fp: fp.write(introduction_page) print('网页保存结束') 3.解析并提取歌曲信息:创建一个BeautifulSoup对象,使用introduction_page作为输入内容,并指定解析器为'lxml',使用CSS选择器从解析后的HTML中选取特定的元素。+ `div.wrap.alm2.clear_fix p`:选取class为wrap、alm2和clear_fix的div元素下的所有p元素。 div#songs .songList a:选取id为songs的div元素下的class为songList的元素中的所有a元素,这些元素表示链接。遍历所有选取到的a元素(歌曲链接),并打印出每首歌的歌名和链接地址。div.list2 p a:选取div下的class为'st2'下的p元素下的 a元素(其他专辑的超链接)。在每首歌的信息之间,使用10个'-'作为分隔符。使用正则表达式从introduction_page中查找所有的匹配项,并将这些匹配项存储在Record_labels列表中。正则表达式的模式是:``,后面是``标签,* `(.*?)`:这是一个非贪婪匹配,它会匹配尽可能少的任何字符,直到遇到下一个模式。这部分是为了捕获“唱片公司:”后到下一个``标签之间的内容。输出提取的 “唱片公司:”后的文本内容。打印100个'-'字符,作为分隔符。打印前面使用CSS选择器选取的两个p元素的文本内容。循环遍历打印输出其他专辑的名字和专辑的超链接,再次打印100个'-'字符作为分隔符,最后输出结束,表示程序运行结束。具体代码如下所示: soup = BeautifulSoup(introduction_page, 'lxml') # 使用CSS选择器 divs = soup.select('div.wrap.alm2.clear_fix p') songs = soup.select('div#songs .songList a') others=soup.select('div.list2 p a') for song in songs: print('歌名:', song.text) print('歌曲链接:', song['href']) print('-' * 10) Record_labels =re.findall(r'',introduction_page) print('唱片公司:',Record_labels[0]) print('-' * 100) print(divs[0].text,divs[1].text) print('-' * 100) print('该歌曲所在的专辑链接为:',url1) print('该歌手的其他专辑有:') for zj in others: print('专辑名:', zj.text) print('专辑链接:',zj['href']) print('-' * 100) print('结束') 三、演示结果分析
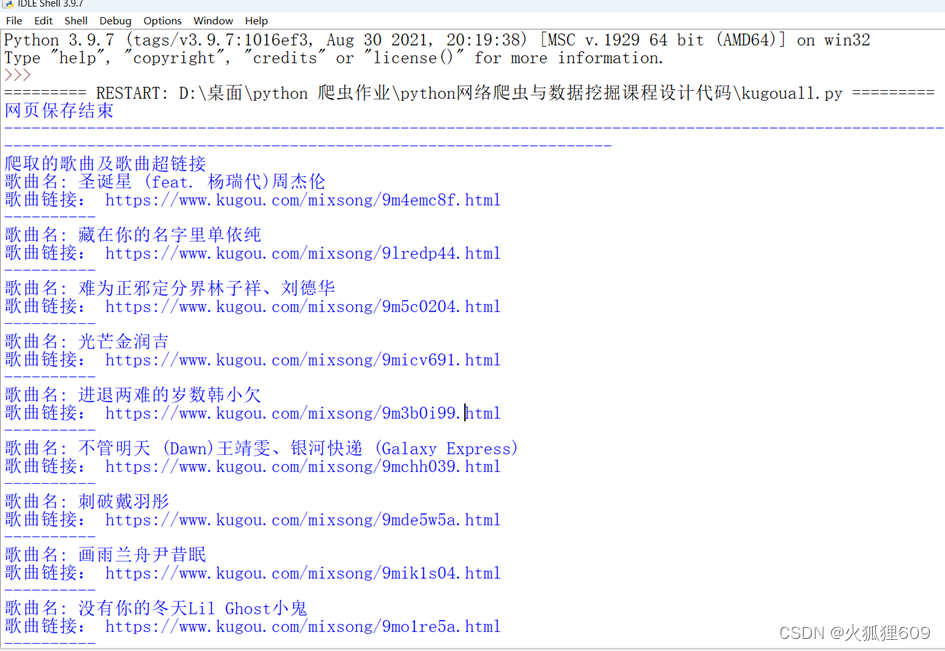
1.利用Python技术爬取酷狗音乐网页版界面,将该网页的所有歌曲、歌手、超链接爬取并打印输出,结果如图所示: 2. 从所有歌曲中选取一首自己喜欢的歌曲,去访问并提取相关信息,将访问的页面保存为本地文件,包含歌手、作曲人、演唱时间、歌曲简介、该歌曲所在的专辑超链接以及该歌手其他专辑的名字和超链接。结果如图所示 四、总结在爬取酷狗音乐过程中主要用到的python包有requests 、re、BeautifulSoup,requests用于发送HTTP请求,re用于正则表达式,以及BeautifulSoup用于解析HTML,设置请求头部信息,模拟真实浏览器的请求,如果不设置请求头,网页将不能正常访问页面会有报错,获取不到想要的信息。另外用到了一些关于关于BeautifulSoup提取想要的信息的知识,在使用BeautifulSoup 提取想要的信息时,需要先掌握网页中的ID和class的表示方法,其中ID使用#表示,class使用.表示,在使用正则表达式时使用(.*?)的方法去获取想要的部分,这属于一种贪婪的获取方法,可以用简单的语句获取到自己感兴趣的内容。 在爬取酷狗音乐,获取自己喜欢歌曲的信息时,会出现获取不到想要的歌曲信息的情况,在此可以是转换的方法去解决这个问题,因为我们所获取到的歌曲的超链接,如果我我们对它进行访问的话,其实它会返回到歌曲的播放页面,在歌曲的播放页面中我们可以看到,该歌曲的专辑和歌曲名,但是我们不能够获取到歌曲的出版时间、歌曲简介。所以我们还需要对网页进行进一步的爬取,将页面转移到和该歌曲介绍相关的链接中,其中的问题是我们如何去知道哪一个链接是和该歌曲相关的呢?在这里通过观察酷狗音乐的歌曲介绍页面得知,其实该歌曲的介绍包含在https://www.kugou.com/album/info/专辑号/ 的链接中,那么如何才能获取到专辑号,这又是一个问题,其实专辑号也是包含在我们访问的页面当中的,我们需要在我们访问的页面中打开开发者工具中的元素,在元素界面找到var dataFromSmarty = [{"hash":"5FA340B158C2E385E64338177384CFD7","timelength":182778,"audio_name":"\u5468\u6770\u4f26\u5723\u8bde\u661f","author_name":"\u5468\u6770\u4f26","song_name":"\u5723\u8bde\u661f","album_id":81544089,"encode_album_id":"1cjrtl84","mixsongid":581352708,"is_risk":0,"encode_album_audio_id":"9m4emc8f"}],然后找到里面的专辑号"album_id":81544089编码后的专辑号"encode_album_id":"1cjrtl84"对应的值,找到这些我们就可以使用正则表达式提取里面的encode_album_id对应的值,然后将提取到值加入到里面就可以了访问该页面的信息了。 五、代码 import requests import re from bs4 import BeautifulSoup headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0', } url = 'https://www.kugou.com/' response = requests.get(url=url, headers=headers) response.encoding = 'utf-8' pagetext = response.text with open('./kugoufrst.html', 'w', encoding='utf-8') as fp: fp.write(pagetext) print('网页保存结束') soup = BeautifulSoup(pagetext, 'lxml') # 使用CSS选择器 singers = soup.select('div#content.content .homep_cm_item_st3_a2') songs = soup.select('div#content.content .homep_cm_item_st2 a') print('--' * 100) print('爬取的歌曲及歌曲超链接') for song in songs: print('歌曲名:', (song.text).replace("\n", "")) print('歌曲链接:', song['href']) print('-' * 10) print('--' * 100) print('爬取的歌手及歌手的超链接:') for singer in singers: print('歌手名:',singer.text) print('歌手链接:', singer['href']) print('-' * 10) # 将歌手名和歌手链接写入文件歌手清单.txt文件 with open('./歌手清单.txt', 'w', encoding='utf-8') as fp: for singer in singers: fp.write('歌手名:' + (singer.text).replace("\n", "") + ' \t' + '歌手链接:' + singer['href'] + '\n') # 将歌名和歌曲链接写入文件 with open('./歌曲清单.txt', 'w', encoding='utf-8') as fp: for song in songs: fp.write('歌名:' + (song.text).replace("\n", "") + ' \t' + '歌曲链接:' + song['href'] + '\n') print('文件写入成功') import requests from bs4 import BeautifulSoup import re import 酷狗爬取页面 u = 酷狗爬取页面.songs[0]['href'] print(u) url2=u headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0', } response = requests.get(url=url2,headers=headers) response.encoding = 'utf-8' pagetext1 = response.text album_id = re.findall(r'"encode_album_id":"(.*?)",', pagetext1) url1 = f'https://www.kugou.com/album/info/{album_id[0]}/' print('访问网页为', url1) res = requests.get(url=url1, headers=headers) introduction_page = res.text print(album_id) with open('./喜欢歌曲.html', 'w', encoding='utf-8') as fp: fp.write(introduction_page) print('网页保存结束') soup = BeautifulSoup(introduction_page, 'lxml') # 使用CSS选择器 divs = soup.select('div.wrap.alm2.clear_fix p') print(divs) songs = soup.select('div#songs .songList a') print(songs) print('-' * 100) print(divs[0].text,divs[1].text) print('-' * 100) for song in songs: print('歌名:', song.text) print('歌曲链接:', song['href']) print('-' * 10) Record_labels =re.findall(r'',introduction_page) print('唱片公司:',Record_labels[0]) print('第二层超链接提取成功') |

【本文地址】
今日新闻 |
推荐新闻 |