酷狗音乐爬取(2023/10/11) |
您所在的位置:网站首页 › 酷狗音乐怎么形容 › 酷狗音乐爬取(2023/10/11) |
酷狗音乐爬取(2023/10/11)
|
一、前言
完成时间是2023.10.11,相对来说比较新。本博客包含的内容有本地查询、展示前30个搜索结果,下载音乐。注意仅能获取试听音乐的前60s,和直接在网上听效果是一样的,只不过可以下载,整首全部下载目前笔者做不到,这篇博客算是一个记录,也有点逆向那味儿了哈哈哈。 我默认你懂计算机网络的基础知识和F12网页开发者工具的基础操作。不懂得可以自行百度,本篇没有太难的东西。 目录 一、前言 二、需求 三、现实过程 四、代码分析及实现 (一)搜索 (二)列表展示 (三)选择下载 (四)全部代码及运行结果 五、总结 二、需求对于整个过程,我想实现的是,可以在本地代码运行过后,直接输入歌曲名称进行搜索,然后可以输出搜索结果,大概前30首,再输入你要下载的歌曲,输入1代表下载输出列表的第一首这样,然后即可开始下载,将音乐下载到本地。 我使用的环境是Anaconda,使用python完成了爬取的工作,当然pycharm肯定也可以,只不过我懒得再配环境了。 三、现实过程现实中如果想要下载酷狗音乐,那首先需要进入酷狗音乐官网, 酷狗音乐 - 就是歌多!小说相声也很多! (kugou.com)
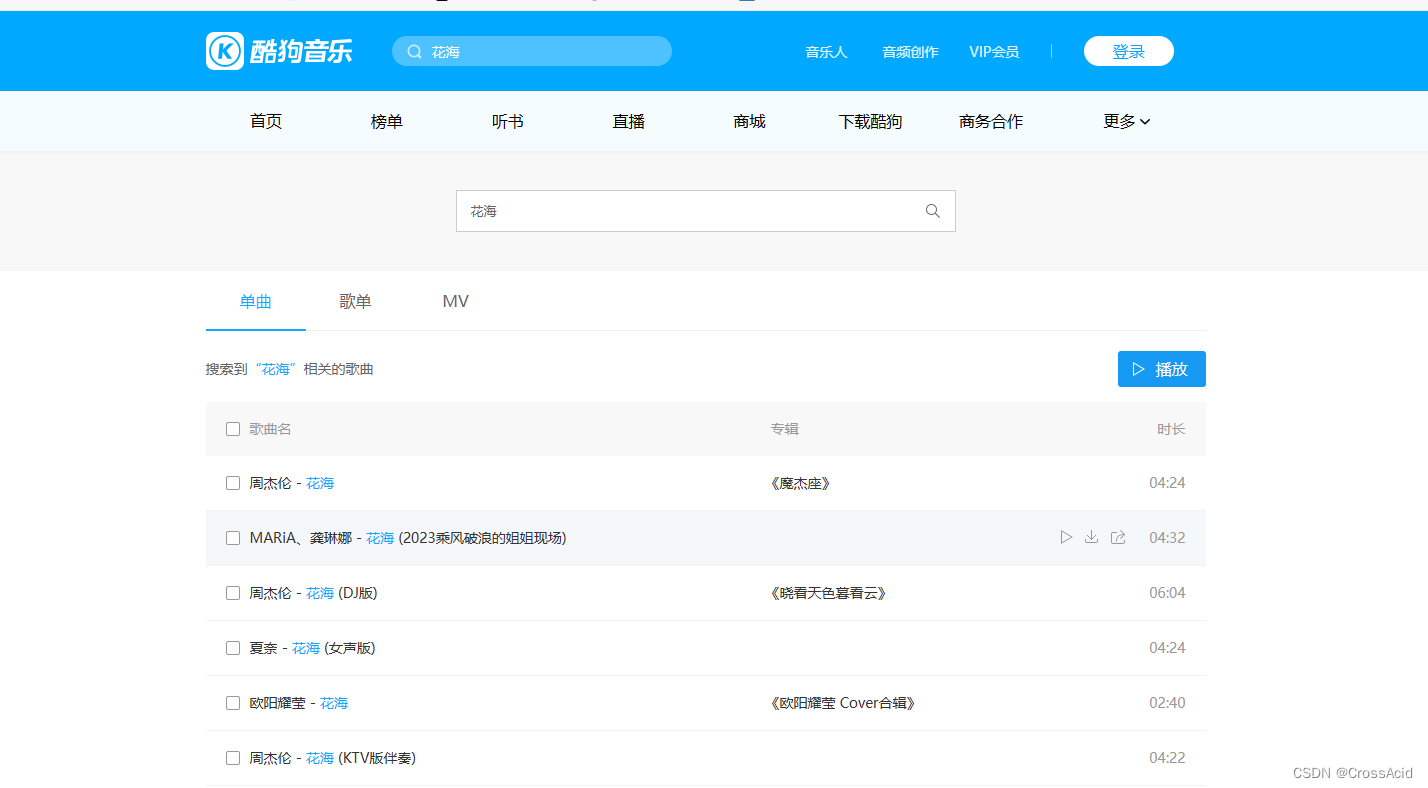
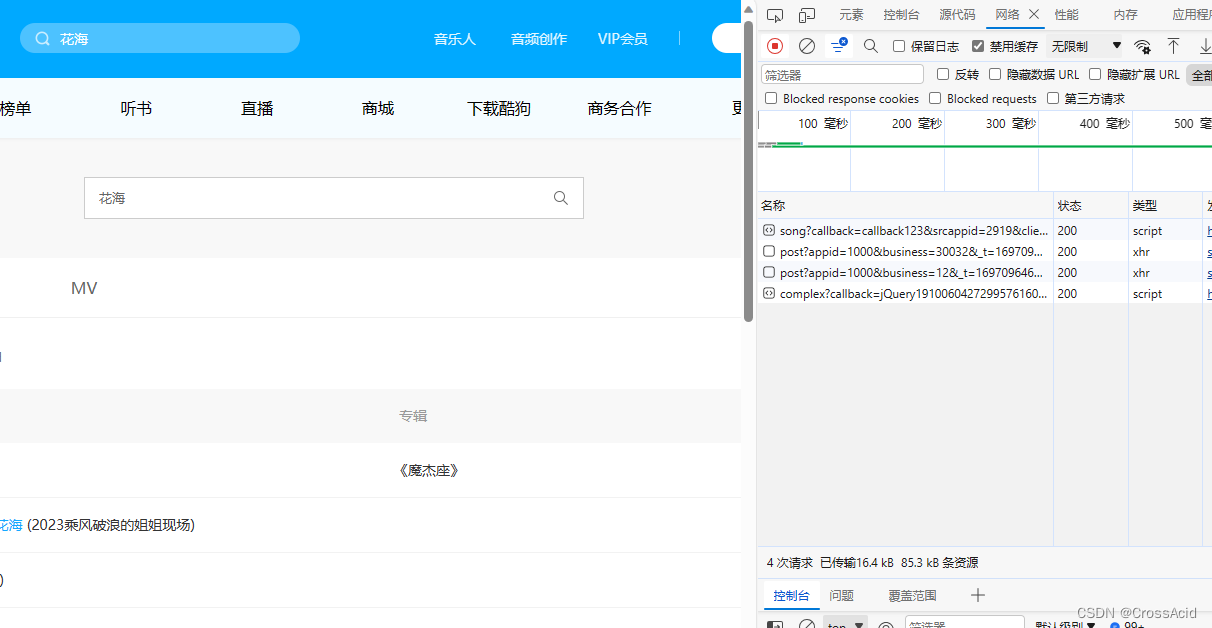
接着即可选择某一首,来试听并下载。这就是我们正常的下载音乐的流程,酷狗音乐下载需要客户端,咱虽然没实现整首下载,但也算方便了点是吧。(滑稽) 爬取的过程其实就是模仿上述流程,接下来进行详细阐述。 四、代码分析及实现 (一)搜索这一部分其实相对更复杂,可以先看第三部分选择下载,最后再看这一部分,我也是最后实现的,但写博客我放在最前面了。 进入酷狗音乐的搜索界面,打开F12,或者右键选择检查,进入开发者工具界面,选择Network(网络),来查看搜索过程的请求和响应(嫌网络界面请求太多可以clear一下),我搜索花海,可以看到网络界面出现了四条新的记录,如图所示:
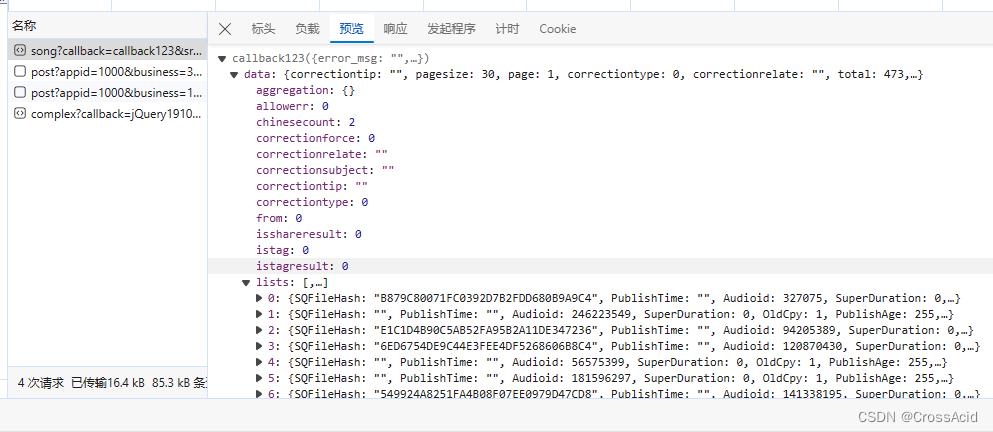
一条一条点进去看,可以看到在song?callback=callback123这条请求的预览(preview)中看到一个data,以及data展开后的list,里面刚好有30条数据,和网页检索出来的30首音乐一一对应,由此,我们可以认为,这个请求就完成了从酷狗音乐那儿获取搜索音乐结果的功能,如图所示:
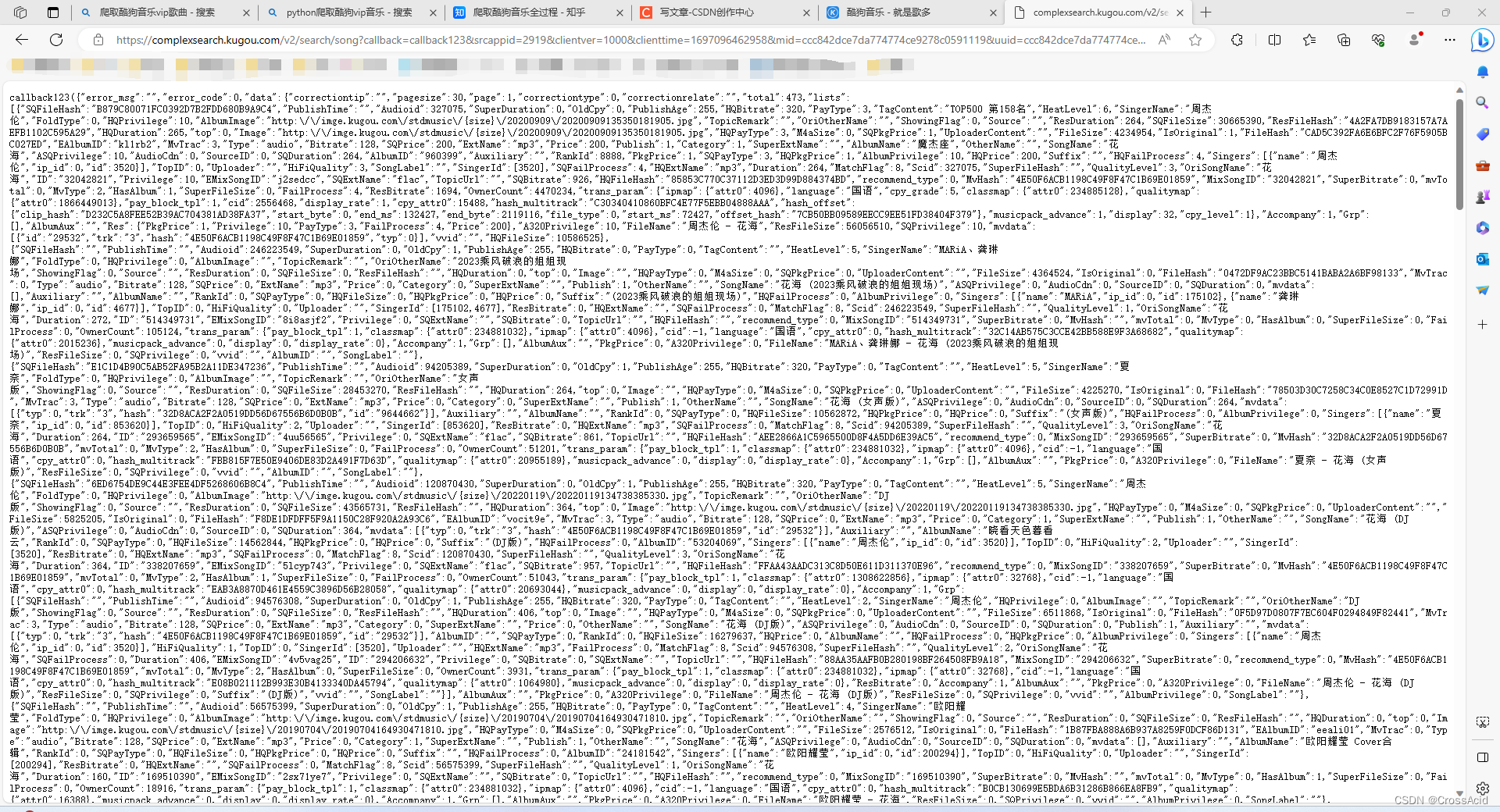
此时,我们可以将这个请求的url复制下来(标头选项卡里能看到request url),在浏览器的地址栏里输入,就可以在网页看到获取的数据,如图:
那么,在python 中我们就需要自己构造这个url,然后使用python发起请求,并获取这个酷狗返回的数据,如下为我搜索花海的url。 complexsearch.kugou.com/v2/search/song?callback=callback123&srcappid=2919&clientver=1000&clienttime=1697096462958&mid=ccc842dce7da774774ce9278c0591119&uuid=ccc842dce7da774774ce9278c0591119&dfid=0R7g5f2OX6eY2EBfN92rrRN0&keyword=花海&page=1&pagesize=30&bitrate=0&isfuzzy=0&inputtype=0&platform=WebFilter&userid=0&iscorrection=1&privilege_filter=0&filter=10&token=&appid=1014&signature=d9087cb7baa10655d4f04275f87ad5d5 可以看到这个url非常之长,慢慢来看 。 假设你有一定的web基础,那你应该知道,这个url后面使用 ? 开头,并使用 & 连接的,就是这个请求(request)的负载(payload),也可以说是参数,我们同样可以通过刚才F12中该请求的负载(payload)选项卡查看到,一共包含21个负载,从callback到signature。 观察这21个负载,多尝试几次搜索,会发现这个搜索的url中,其实真正改变的,只有几项,如下表所示: 负载名称介绍clientime时间keyword关键词signature签名(瞎翻译的)对于上表中的clienttime,显然这是毫秒时间戳,没什么可说的,然后keyword,显然就是搜索关键词,也没什么好说的。最后的signature就有点摸不着头脑了,这也是关键所在。 当然,你们自己尝试时部分参数应该会和我不一样,但每次搜索时都不会变化,比如mid和uuid这种,这个url中还有page和pagesize,这个是页面和页大小,就不介绍了,可以自行学习。 这个时候,我们就可以把其他负载或者说参数准备好,记录下来,留作备用,对于signature,接下来详细展开说。 第一次看到signature时,应该要想到这个有点像MD5编码生成的32位结果(关于MD5,我也不解释了,可以自行搜搜)。那么我们就要思考,这串字符在编码前的原始的字符串应该是什么,那么,在F12中,我们就可以进行全局搜索,搜索一下signature,结果如图:
如果没有,那你刷新一下页面,可能是你clear请求时把这个也clear了。在这六个结果中查看,可以发现只有前三个和signature的构造相关,是三个js文件(JavaScrip的基础知识我也不讲,只要知道这个signature时js构造出来的就可以了)。 其中也可以看出,它就是MD5编码 ,此时可以右键右侧的响应页面,点击在源面板中打开,由此跳转到源代码界面,如图:
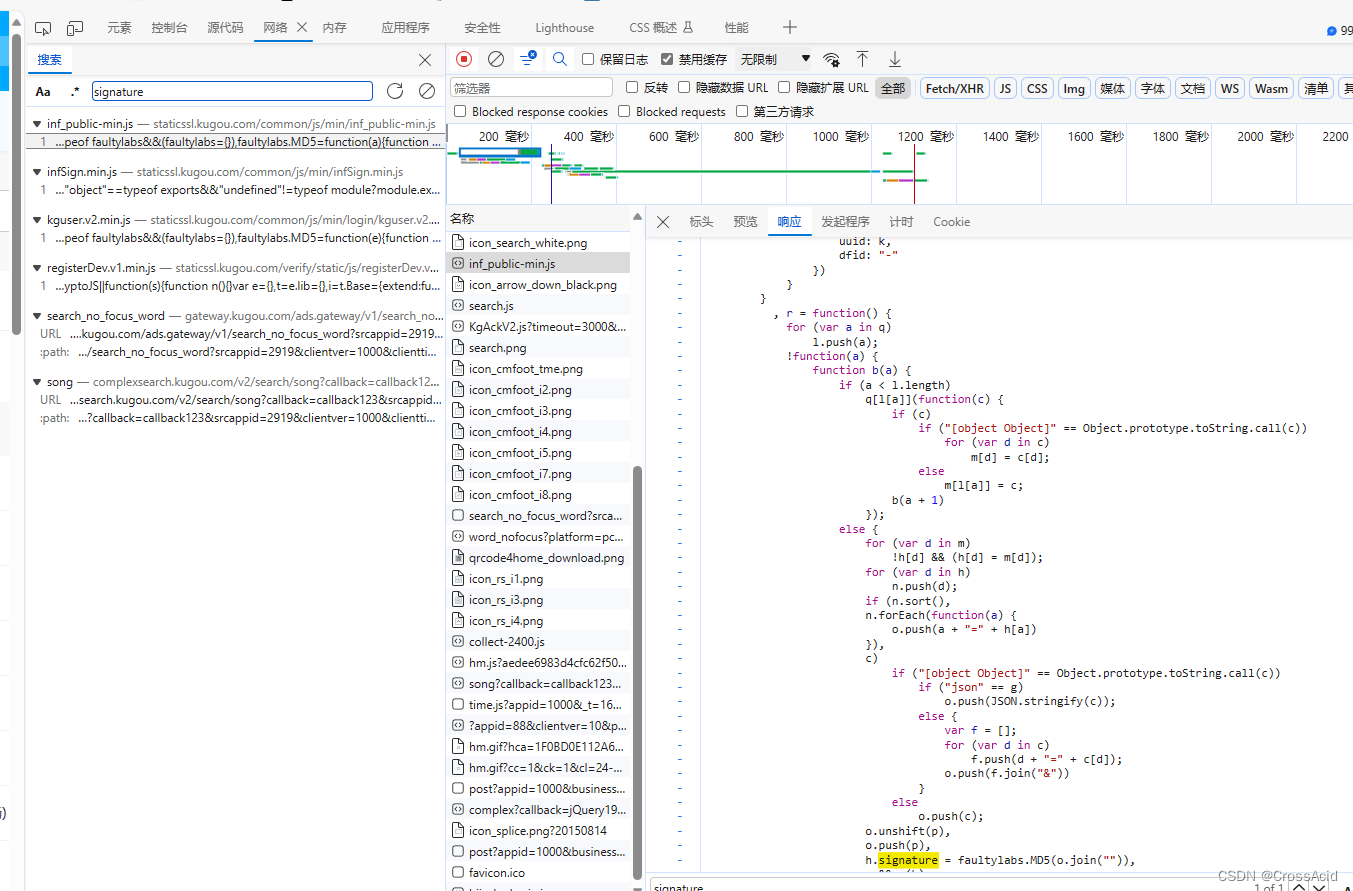
在此界面即可进行对js代码的断点调试(F12中的js断点调试功能可以自行搜索,很多教程),在三个js中依次在这个signature行左边打上断点,刷新页面进行调试,可以发现只有infSign.min.js这个文件的断点生效了,由此得出这个signature的生成与这个js文件相关。 l.signature = d(s.join("")),确定好是这个js起的作用时,就观察这行代码,大致意思就是将s这个变量中的数据直接连接起来,再将其作为参数输入d函数,获取的结果就是signature。全局搜索d函数,结果却是在另一个js中,于是一头雾水,但是参考其他两个js文件,发现这行与其他两个js文件这块的写法类似。 // kguser.v2.min.js a.signature = faultylabs.MD5(K.join("")) // inf_public.min.js h.signature = faultylabs.MD5(o.join(""))于是可以初步判断这个d就是MD5函数,那么,接下来,我们将s变量加入watch(方法就是选中s变量,右键,选择将所选文本加入到监视),然后重新断点调试,由此,我们就能发现,这个s包含了哪些东西,如图所示:
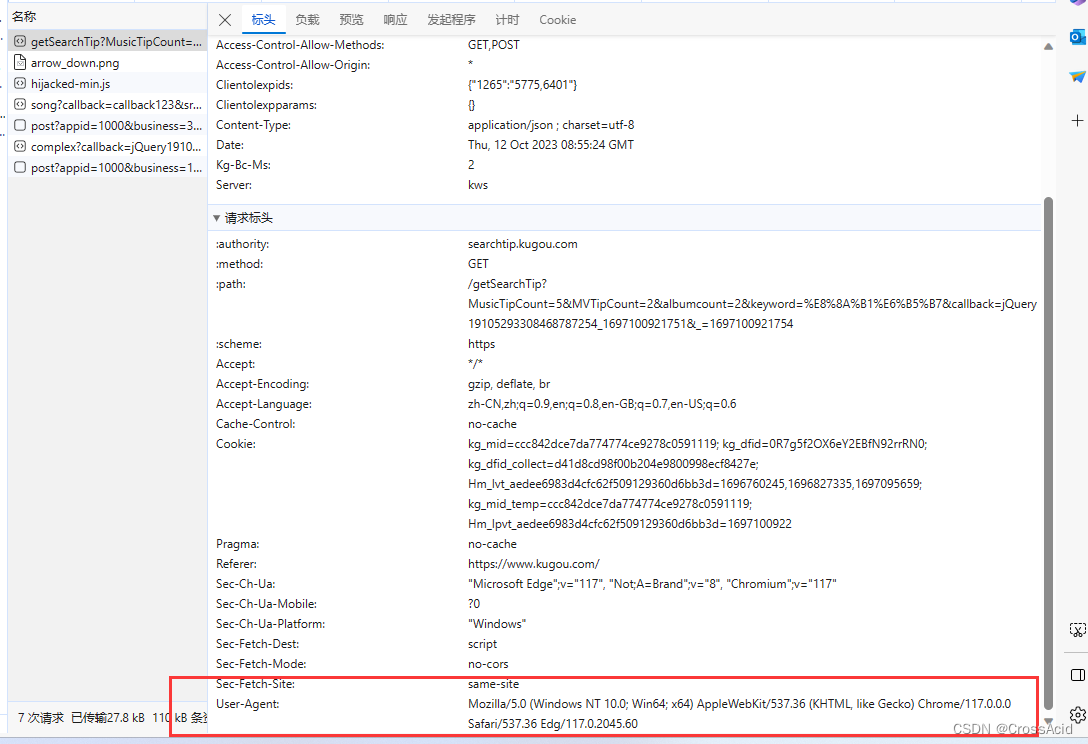
可以看到s是一个长度为22的数组,观察数组,可以得出其变化项也只有clienttime和keyword。通过s.join(“”)操作,即可得到如下结果: 'NVPh5oo715z5DIWAeQlhMDsWXXQV4hwtappid=1014bitrate=0callback=callback123clienttime=1697100089829clientver=1000dfid=0R7g5f2OX6eY2EBfN92rrRN0filter=10inputtype=0iscorrection=1isfuzzy=0keyword=花海mid=ccc842dce7da774774ce9278c0591119page=1pagesize=30platform=WebFilterprivilege_filter=0srcappid=2919token=userid=0uuid=ccc842dce7da774774ce9278c0591119NVPh5oo715z5DIWAeQlhMDsWXXQV4hwt'那么接下来对这个串进行MD5编码,即可获得一个32位的signature,将其拼接到url上去即可完成。经过后来的测试,发现这个思路就是正确的,现实中遇到其爬取的问题,可能会更加复杂,这个相对比较简单。 由此这一部分搜索的内容的分析就结束了,这一部分代码如下所示: import requests import json import urllib from hashlib import md5 import time # MD5编码 def get_signature(text): new_md5 = md5() new_md5.update(text.encode(encoding='utf-8')) signature = new_md5.hexdigest() return signature # 构造搜索的url,并获取搜索结果 def get_list(keyword): headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.47' } mid = 'ccc842dce7da774774ce9278c0591119' url = 'https://complexsearch.kugou.com/v2/search/song?callback=callback123&srcappid=2919&clientver=1000&clienttime={time}&mid={mid}&uuid={mid}&dfid=0R7g5f2OX6eY2EBfN92rrRN0&keyword={keyword}&page=1&pagesize=30&bitrate=0&isfuzzy=0&inputtype=0&platform=WebFilter&userid=0&iscorrection=1&privilege_filter=0&filter=10&token=&appid=1014&signature={signature}' key_code = 'NVPh5oo715z5DIWAeQlhMDsWXXQV4hwtappid=1014bitrate=0callback=callback123clienttime={time}clientver=1000dfid=0R7g5f2OX6eY2EBfN92rrRN0filter=10inputtype=0iscorrection=1isfuzzy=0keyword={keyword}mid={mid}page=1pagesize=30platform=WebFilterprivilege_filter=0srcappid=2919token=userid=0uuid={mid}NVPh5oo715z5DIWAeQlhMDsWXXQV4hwt' millis = str(round(time.time() * 1000)) p = key_code.format(time=millis, mid=mid, keyword=keyword) signature = get_signature(p) search_url = url.format(keyword=keyword, time=millis, signature=signature, mid=mid) # print(search_url) list_res = requests.get(search_url, headers = headers) return list_resget_signature()函数可以将我们构造的s.join(“”)的结果转化为32位字符串。get_list()函数可以通过关键词,构造url,获取搜索结果。 headers是伪装用的,使用python这种发起请求,需要将我们自己伪装成正常的浏览器,可以在刚才的F12界面的请求标头那儿直接复制,里面的user-agent就是我们需要的东西,如图:
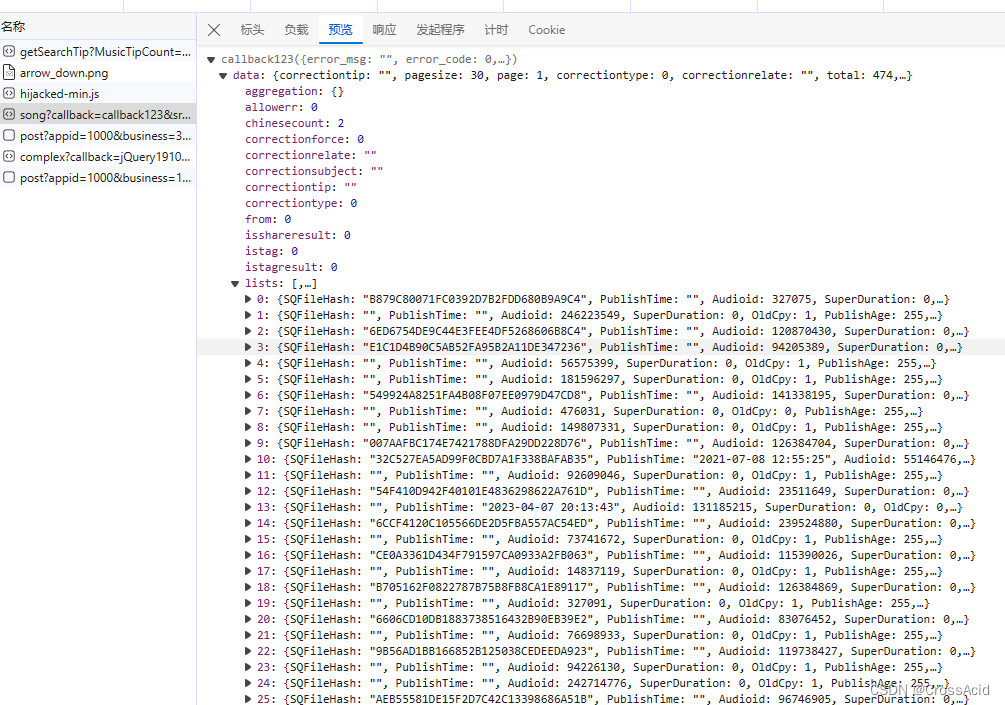
mid和uuid的值是一样的,我也不知道为什么,而且每次都是固定的,我就直接粘过来当个变量用了。 keycode就是我们s中22个属性,join后的结果。miles即clienttime,通过python的time库获取。 最后,通过python的format方法,将keycode中的变量进行替换,就可以得到get_signature()函数的输入,从而获取signature。 获取完signature后,对我们的搜索url进行format,将keyword、signature等进行替换,得到最终的可以搜索结果的url。从而我们便可以通过requests的get方法,获取返回结果,你可以print一下看看,结果就是我们直接将这个url在浏览器打开的结果。 (二)列表展示上述获取的结果,其实就是我们刚开始看到如下这张图里的内容:
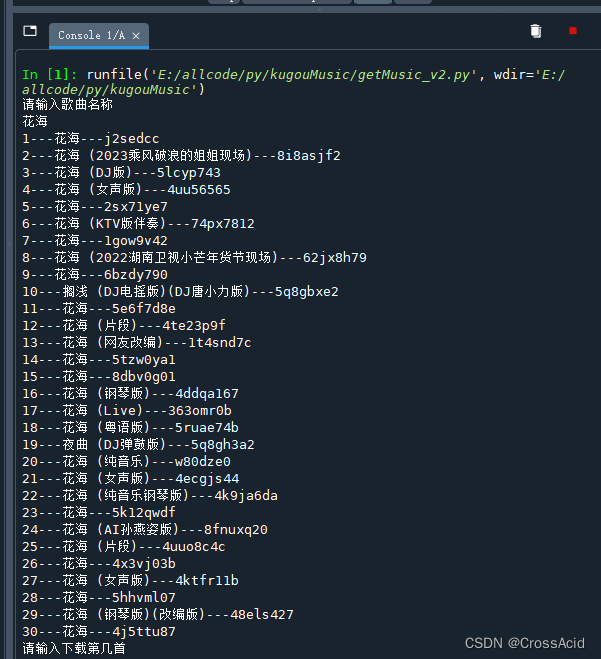
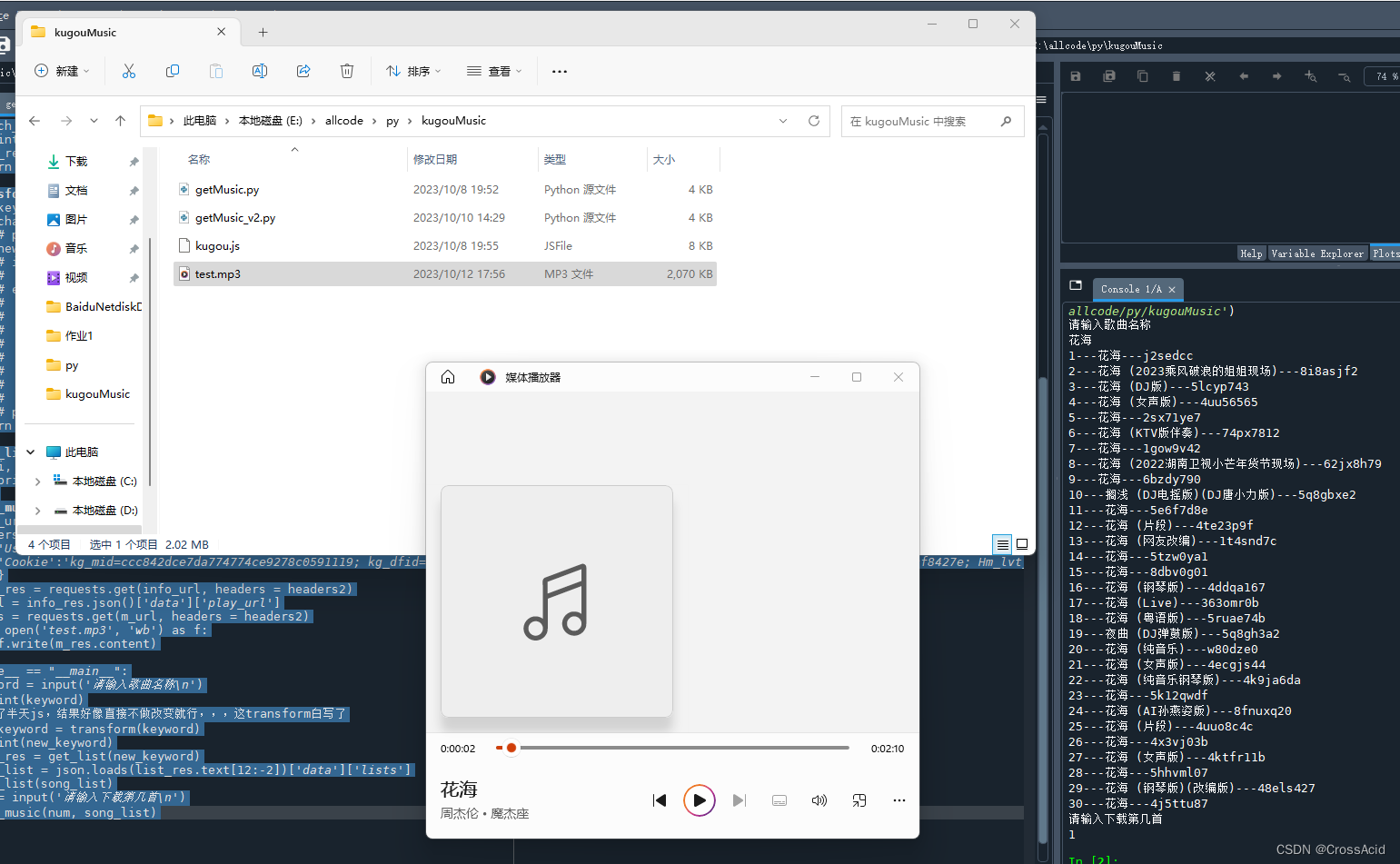
所以,我们要展示的歌曲列表信息,其实就包含在这个响应数据里的data里的list中,为了简介展示,我们仅取list中每条数据的SongName和EMixSongID(这个是每首歌的ID,和以前教程的hash不一样了,可以参考下载部分)。 这部分代码如下: def show_list(song_list): for i, song in enumerate(song_list): print(f'{i+1}---{song.get("SongName")}---{song.get("EMixSongID")}') if __name__ == "__main__": keyword = input('请输入歌曲名称\n') list_res = get_list(keyword ) song_list = json.loads(list_res.text[12:-2])['data']['lists'] show_list(song_list)list_res.text[12:-2]可以获取response中 “callback123(” 和 “)” 之间的部分,这部分才能通过json串进行解析,具体语法就不讲了。 获取完之后,即可通过['data']['list']获取到我们前文提到的歌曲list,将其使用song_list保存,并将其传出show_list函数进行展示,show_list函数仅展示SongName和EMixSongID,并在前面加上个编号。 输出结果如下:
这一部分即可根据EMixSongID进行下载。 在获取列表后,看到喜欢的歌,我们会点击进入该歌曲的主页进行播放或者下载,进入该页面后,打开F12。思考,下载音乐,就是要找到mp3文件,于是ctrl+f,全局搜索mp3,可以看到如下页面:
其中我们进入这些请求,查看他们的preview,就可以看到其中有一个play_url,凭借我们浅薄的英语,猜测它就是播放的音乐,将其复制到地址栏,发现果然如此,如图所示:
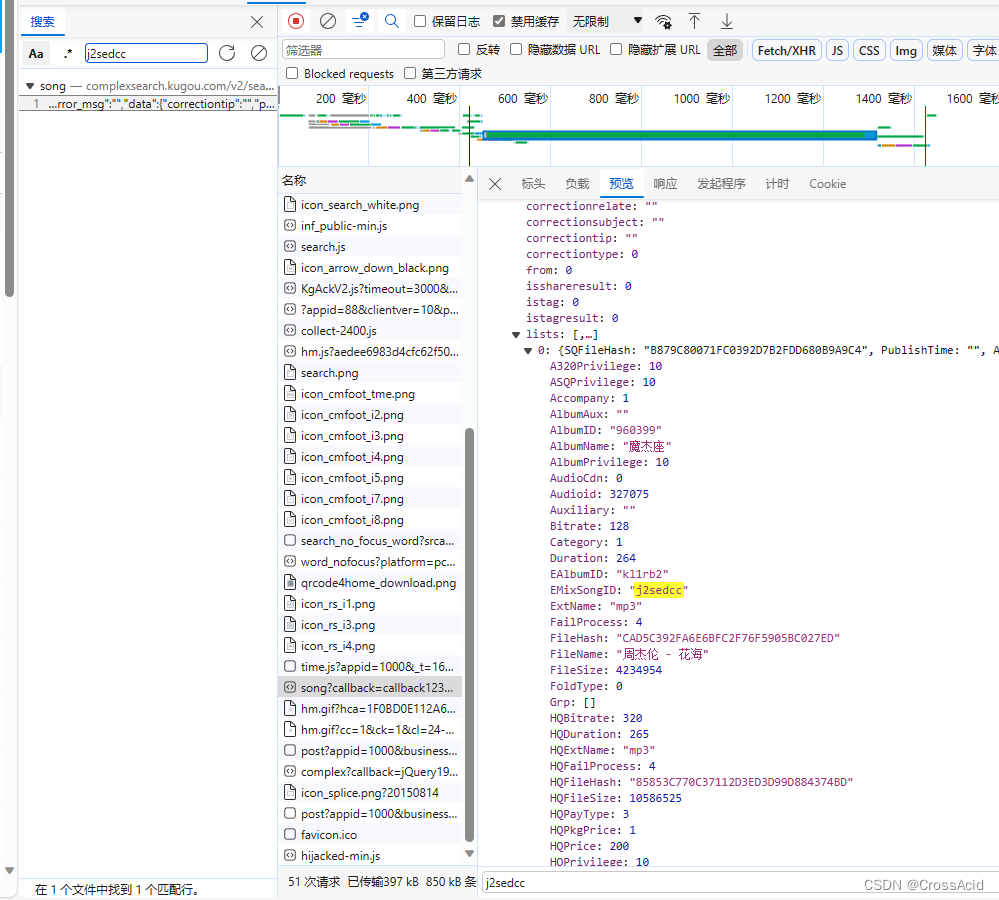
那么我们就认为,这个请求,就是我们需要的请求(这一堆请求的url都是一样的)。花海这个例子,它的url如下所示(不是play_url) https://wwwapi.kugou.com/yy/index.php?r=play/getdata&callback=jQuery19106863316783818381_1697102769850&dfid=0R7g5f2OX6eY2EBfN92rrRN0&appid=1014&mid=ccc842dce7da774774ce9278c0591119&platid=4&encode_album_audio_id=j2sedcc&_=1697102769851其实看到它那个wwwapi,也能有点想法hhh。 对于这个url,我们将其在地址栏输入,可以得到如下结果(格式化过了): { "status":1, "err_code":0, "data":{ "hash":"CAD5C392FA6E6BFC2F76F5905BC027ED", "timelength":264646, "filesize":4234954, "audio_name":"\u5468\u6770\u4f26 - \u82b1\u6d77", "have_album":1, "album_name":"\u9b54\u6770\u5ea7", "album_id":"960399", "img":"http:\/\/imge.kugou.com\/stdmusic\/20200909\/20200909135350181905.jpg", "have_mv":0, "video_id":0, "author_name":"\u5468\u6770\u4f26", "song_name":"\u82b1\u6d77", "lyrics":"\ufeff[id:$00000000]\r\n[ar:\u5468\u6770\u4f26]\r\n[ti:\u82b1\u6d77]\r\n[by:]\r\n[hash:cad5c392fa6e6bfc2f76f5905bc027ed]\r\n[al:]\r\n[sign:]\r\n[qq:]\r\n[total:264770]\r\n[offset:0]\r\n[00:00.00]\u5468\u6770\u4f26 - \u82b1\u6d77\r\n[00:02.10]\u8bcd\uff1a\u53e4\u5c0f\u529b\/\u9ec4\u6de9\u5609\r\n[00:04.47]\u66f2\uff1a\u5468\u6770\u4f26\r\n[00:05.79]\u7f16\u66f2\uff1a\u9ec4\u96e8\u52cb\r\n[00:07.37]\u5236\u4f5c\u4eba\uff1a\u5468\u6770\u4f26\r\n[00:09.22]\u5409\u4ed6\uff1a\u674e\u5ead\u5321\r\n[00:10.80]\u5f55\u97f3\u5e08\uff1a\u6768\u745e\u4ee3\r\n[00:12.64]\u5f55\u97f3\u5ba4\uff1aJVR Studio\r\n[00:16.33]\u6df7\u97f3\u5e08\uff1a\u6768\u5927\u7eac\r\n[00:18.18]\u6df7\u97f3\u5ba4\uff1a\u6768\u5927\u7eac\u5de5\u4f5c\u5ba4\r\n[00:20.81]OP\uff1aJVR Music Int'l Ltd.\r\n[00:26.87]\u9759\u6b62\u4e86 \u6240\u6709\u7684\u82b1\u5f00\r\n[00:33.29]\u9065\u8fdc\u4e86 \u6e05\u6670\u4e86\u7231\r\n[00:39.58]\u5929\u90c1\u95f7 \u7231\u5374\u5f88\u559c\u6b22\r\n[00:45.95]\u90a3\u65f6\u5019\u6211\u4e0d\u61c2\u8fd9\u53eb\u7231\r\n[00:52.45]\u4f60\u559c\u6b22 \u7ad9\u5728\u90a3\u7a97\u53f0\r\n[00:58.76]\u4f60\u597d\u4e45 \u90fd\u6ca1\u518d\u6765\r\n[01:05.23]\u5f69\u8272\u7684\u65f6\u95f4\u67d3\u4e0a\u7a7a\u767d\r\n[01:12.29]\u662f\u4f60\u6d41\u7684\u6cea\u6655\u5f00\r\n[01:17.15]\u4e0d\u8981\u4f60\u79bb\u5f00\r\n[01:20.44]\u8ddd\u79bb\u9694\u4e0d\u5f00\r\n[01:23.58]\u601d\u5ff5\u53d8\u6210\u6d77\r\n[01:26.45]\u5728\u7a97\u5916\u8fdb\u4e0d\u6765\r\n[01:30.08]\u539f\u8c05\u8bf4\u592a\u5feb\r\n[01:33.26]\u7231\u6210\u4e86\u963b\u788d\r\n[01:36.39]\u624b\u4e2d\u7684\u98ce\u7b5d\u653e\u592a\u5feb\u56de\u4e0d\u6765\r\n[01:43.06]\u4e0d\u8981\u4f60\u79bb\u5f00\r\n[01:46.00]\u56de\u5fc6\u5212\u4e0d\u5f00\r\n[01:49.24]\u6b20\u4f60\u7684\u5ba0\u7231\r\n[01:52.12]\u6211\u5728\u7b49\u5f85\u91cd\u6765\r\n[01:55.69]\u5929\u7a7a\u4ecd\u707f\u70c2\r\n[01:58.81]\u5b83\u7231\u7740\u5927\u6d77\r\n[02:02.04]\u60c5\u6b4c\u88ab\u6253\u8d25\r\n[02:05.29]\u7231\u5df2\u4e0d\u5b58\u5728\r\n[02:34.85]\u4f60\u559c\u6b22 \u7ad9\u5728\u90a3\u7a97\u53f0\r\n[02:41.27]\u4f60\u597d\u4e45 \u90fd\u6ca1\u518d\u6765\r\n[02:47.60]\u5f69\u8272\u7684\u65f6\u95f4\u67d3\u4e0a\u7a7a\u767d\r\n[02:54.80]\u662f\u4f60\u6d41\u7684\u6cea\u6655\u5f00\r\n[02:59.63]\u4e0d\u8981\u4f60\u79bb\u5f00\r\n[03:02.85]\u8ddd\u79bb\u9694\u4e0d\u5f00\r\n[03:05.99]\u601d\u5ff5\u53d8\u6210\u6d77\r\n[03:08.85]\u5728\u7a97\u5916\u8fdb\u4e0d\u6765\r\n[03:12.48]\u539f\u8c05\u8bf4\u592a\u5feb\r\n[03:15.67]\u7231\u6210\u4e86\u963b\u788d\r\n[03:18.80]\u624b\u4e2d\u7684\u98ce\u7b5d\u653e\u592a\u5feb\u56de\u4e0d\u6765\r\n[03:25.19]\u4e0d\u8981\u4f60\u79bb\u5f00\r\n[03:28.41]\u56de\u5fc6\u5212\u4e0d\u5f00\r\n[03:31.64]\u6b20\u4f60\u7684\u5ba0\u7231\r\n[03:34.53]\u6211\u5728\u7b49\u5f85\u91cd\u6765\r\n[03:38.10]\u5929\u7a7a\u4ecd\u707f\u70c2\r\n[03:41.22]\u5b83\u7231\u7740\u5927\u6d77\r\n[03:44.45]\u60c5\u6b4c\u88ab\u6253\u8d25\r\n[03:47.69]\u7231\u5df2\u4e0d\u5b58\u5728\r\n", "author_id":"3520", "privilege":10, "privilege2":"1010", "play_url":"https:\/\/webfs.hw.kugou.com\/202310121738\/7f4ca0d82980d183744b3c74cc9c6bff\/v2\/cad5c392fa6e6bfc2f76f5905bc027ed\/part\/0\/2119116\/KGTX\/COS201\/clip_b37d88fd7e0d891099d8eabedf94c0c7.mp3", "authors":[ { "author_id":"3520", "author_name":"\u5468\u6770\u4f26", "is_publish":"1", "sizable_avatar":"http:\/\/singerimg.kugou.com\/uploadpic\/softhead\/{size}\/20230510\/20230510173043311.jpg", "e_author_id":"3E0KCC3671E7", "avatar":"http:\/\/singerimg.kugou.com\/uploadpic\/softhead\/400\/20230510\/20230510173043311.jpg" } ], "is_free_part":1, "bitrate":128, "recommend_album_id":960399, "store_type":"audio", "album_audio_id":32042821, "is_publish":1, "e_author_id":"3E0KCC3671E7", "audio_id":"327075", "has_privilege":true, "play_backup_url":"https:\/\/webfs.tx.kugou.com\/202310121738\/2b46318cd828878ad8488ee3f14d84f4\/v2\/cad5c392fa6e6bfc2f76f5905bc027ed\/part\/0\/2119116\/KGTX\/COS201\/clip_b37d88fd7e0d891099d8eabedf94c0c7.mp3", "trans_param":{ "cpy_level":1, "classmap":{ "attr0":234885128 }, "cpy_grade":5, "qualitymap":{ "attr0":1866449013 }, "pay_block_tpl":1, "cid":2556468, "language":"\u56fd\u8bed", "hash_multitrack":"C30340410860BFC4E77F5EBB04888AAA", "cpy_attr0":15488, "ipmap":{ "attr0":4096 }, "hash_offset":{ "clip_hash":"D232C5A8FEE52B39AC704381AD38FA37", "start_byte":0, "end_ms":132427, "end_byte":2119116, "file_type":0, "start_ms":72427, "offset_hash":"7CB50BB09589EECC9EE51FD38404F379" }, "musicpack_advance":1, "display":32, "display_rate":1 }, "small_library_song":1, "encode_album_id":"kl1rb2", "encode_album_audio_id":"j2sedcc", "e_video_id":"0df" } }这个里面就包含play_url。 我也是学习别人的教程,才知道这个url可以删减,我们一段一段删除它的 & ,并输入地址栏测试,可以最终将url简化为如下结果: https://wwwapi.kugou.com/yy/index.php?r=play/getdata&encode_album_audio_id=j2sedcc发现仅有encode_album_audio_id=j2sedcc起到作用,仅用这一个参数就能获取play_url,那么我们的任务就变成了获取这个id(也就是歌曲ID),复制这个id,我们在搜索歌曲界面进行F12全局检索j2sedcc,即可获取如图所示结果:
只有这一个请求能获取这个j2sedcc,这个请求就是我们(一)搜索中讲到的请求,所以,在找(一)搜索中的搜索url时,这样先看下载这块,反而能更快的找到所需的url。 如果你是从(三)选择下载开始看的,那么,你现在就可以回头去看(一)搜索和(二)列表展示了。 假定你已经看完,那么这一部分的代码如下: def save_music(num, song_list): info_url = f'https://wwwapi.kugou.com/yy/index.php?r=play/getdata&encode_album_audio_id={song_list[int(num)-1].get("EMixSongID")}' headers2 = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.47', 'Cookie':'kg_mid=ccc842dce7da774774ce9278c0591119; kg_dfid=0R7g5f2OX6eY2EBfN92rrRN0; kg_dfid_collect=d41d8cd98f00b204e9800998ecf8427e; Hm_lvt_aedee6983d4cfc62f509129360d6bb3d=1696760245; Hm_lpvt_aedee6983d4cfc62f509129360d6bb3d=1696762195' } info_res = requests.get(info_url, headers = headers2) m_url = info_res.json()['data']['play_url'] m_res = requests.get(m_url, headers = headers2) with open('test.mp3', 'wb') as f: f.write(m_res.content) if __name__ == "__main__": keyword = input('请输入歌曲名称\n') list_res = get_list(keyword ) song_list = json.loads(list_res.text[12:-2])['data']['lists'] show_list(song_list) num = input('请输入下载第几首\n') save_music(num, song_list)其中save_music函数中的info_url,就是我们这一部分所说的获取歌曲play_url的url。 在这个函数中加入了cookie,因为没有这个cookie就无法完成这个请求,获取方法和user-agent一样(具体原理不讲)。 接下来就是老生常谈的发起请求,在响应中获取play_url,再通过play_url发起请求,获取音乐,存储音乐这段的代码没什么解释了。 (四)全部代码及运行结果代码如下: import requests import json import urllib from hashlib import md5 import time def get_signature(text): new_md5 = md5() new_md5.update(text.encode(encoding='utf-8')) signature = new_md5.hexdigest() return signature def get_list(keyword): headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.47' } mid = 'ccc842dce7da774774ce9278c0591119' url = 'https://complexsearch.kugou.com/v2/search/song?callback=callback123&srcappid=2919&clientver=1000&clienttime={time}&mid={mid}&uuid={mid}&dfid=0R7g5f2OX6eY2EBfN92rrRN0&keyword={keyword}&page=1&pagesize=30&bitrate=0&isfuzzy=0&inputtype=0&platform=WebFilter&userid=0&iscorrection=1&privilege_filter=0&filter=10&token=&appid=1014&signature={signature}' key_code = 'NVPh5oo715z5DIWAeQlhMDsWXXQV4hwtappid=1014bitrate=0callback=callback123clienttime={time}clientver=1000dfid=0R7g5f2OX6eY2EBfN92rrRN0filter=10inputtype=0iscorrection=1isfuzzy=0keyword={keyword}mid={mid}page=1pagesize=30platform=WebFilterprivilege_filter=0srcappid=2919token=userid=0uuid={mid}NVPh5oo715z5DIWAeQlhMDsWXXQV4hwt' millis = str(round(time.time() * 1000)) p = key_code.format(time=millis, mid=mid, keyword=keyword) signature = get_signature(p) search_url = url.format(keyword=keyword, time=millis, signature=signature, mid=mid) # print(search_url) list_res = requests.get(search_url, headers = headers) return list_res def show_list(song_list): for i, song in enumerate(song_list): print(f'{i+1}---{song.get("SongName")}---{song.get("EMixSongID")}') def save_music(num, song_list): info_url = f'https://wwwapi.kugou.com/yy/index.php?r=play/getdata&encode_album_audio_id={song_list[int(num)-1].get("EMixSongID")}' headers2 = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.47', 'Cookie':'kg_mid=ccc842dce7da774774ce9278c0591119; kg_dfid=0R7g5f2OX6eY2EBfN92rrRN0; kg_dfid_collect=d41d8cd98f00b204e9800998ecf8427e; Hm_lvt_aedee6983d4cfc62f509129360d6bb3d=1696760245; Hm_lpvt_aedee6983d4cfc62f509129360d6bb3d=1696762195' } info_res = requests.get(info_url, headers = headers2) m_url = info_res.json()['data']['play_url'] m_res = requests.get(m_url, headers = headers2) with open('test.mp3', 'wb') as f: f.write(m_res.content) if __name__ == "__main__": keyword = input('请输入歌曲名称\n') list_res = get_list(keyword ) song_list = json.loads(list_res.text[12:-2])['data']['lists'] show_list(song_list) num = input('请输入下载第几首\n') save_music(num, song_list)结果如下:
这是一次爬虫的简单尝试,也是一次记录,挺有意思,可惜只能下载60s,道阻且长吧,如果有反爬,早就凉凉了~~ 历时:2023/10/9 ~ 2023/10/11 |




【本文地址】