看ChatGPT是如何教我爬取上千家上市公司的股票代码 |
您所在的位置:网站首页 › 遍历json的值得到的是什么类型 › 看ChatGPT是如何教我爬取上千家上市公司的股票代码 |
看ChatGPT是如何教我爬取上千家上市公司的股票代码
|
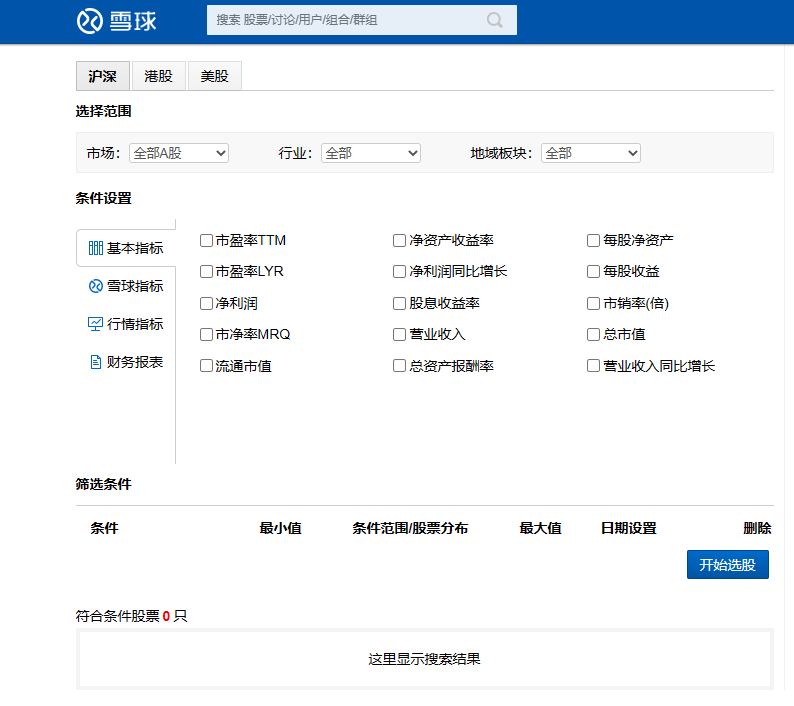
现在有一个这样的需求,要爬取雪球网上A股的股票名称、代码和总市值这些信息并把它保存到execl表格中。对于一个新手想学习爬虫,如何通过chatGPT来完成这个任务呢?
首先,我们把自己的需求详细的描述向ChatGPT提问,问题描写的越详细越好,例如:
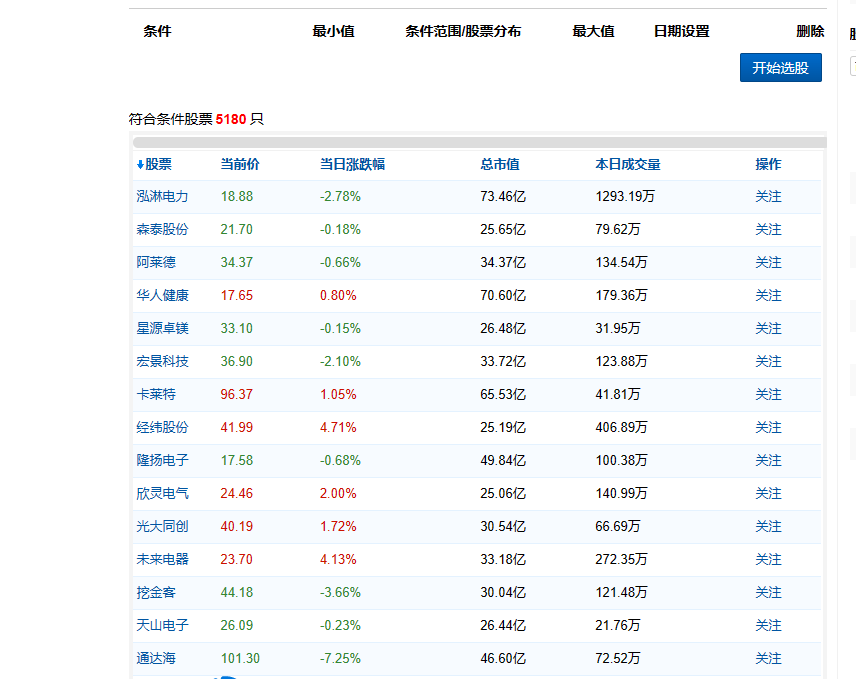
通过观察爬取的页面,刚打开页面是没有我们想要的信息,当我们点击了开始选股,才加载数据。
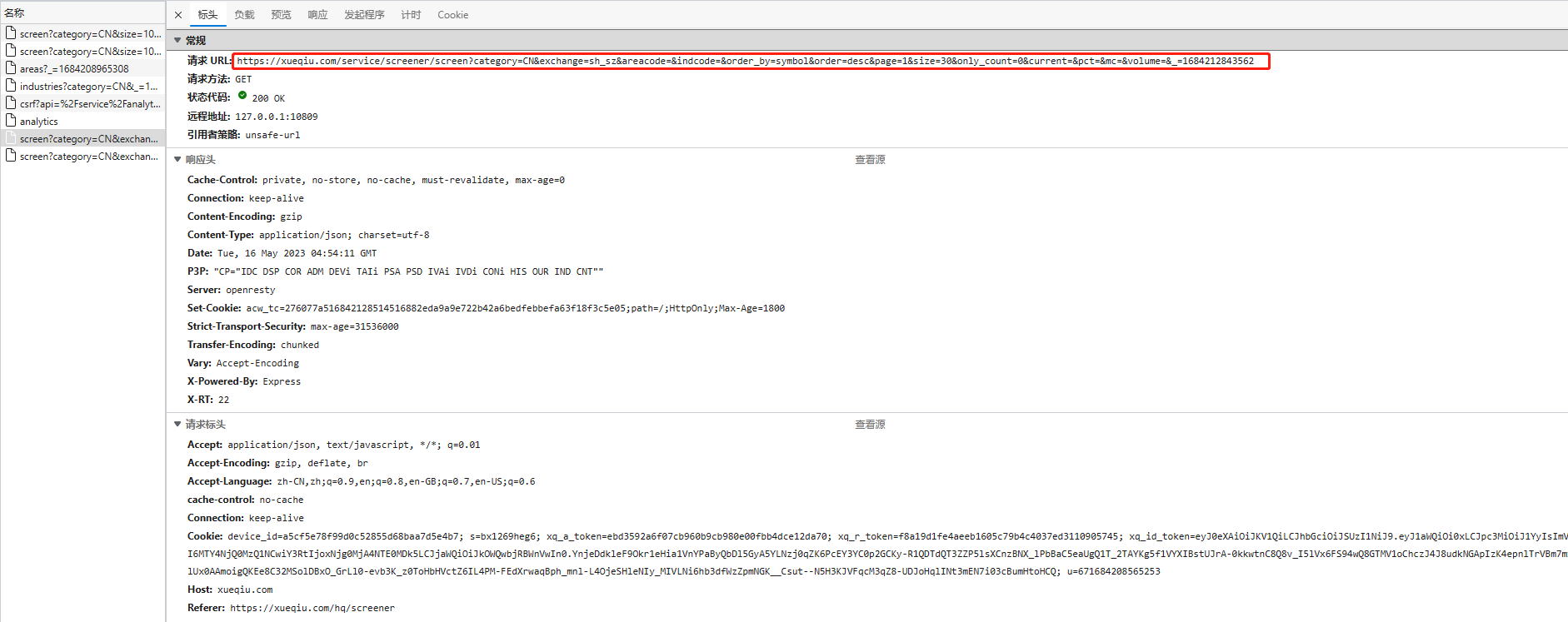
通过浏览器开发者工具,发现点击后,是请求以下这个地址,获取结果进行加载的。
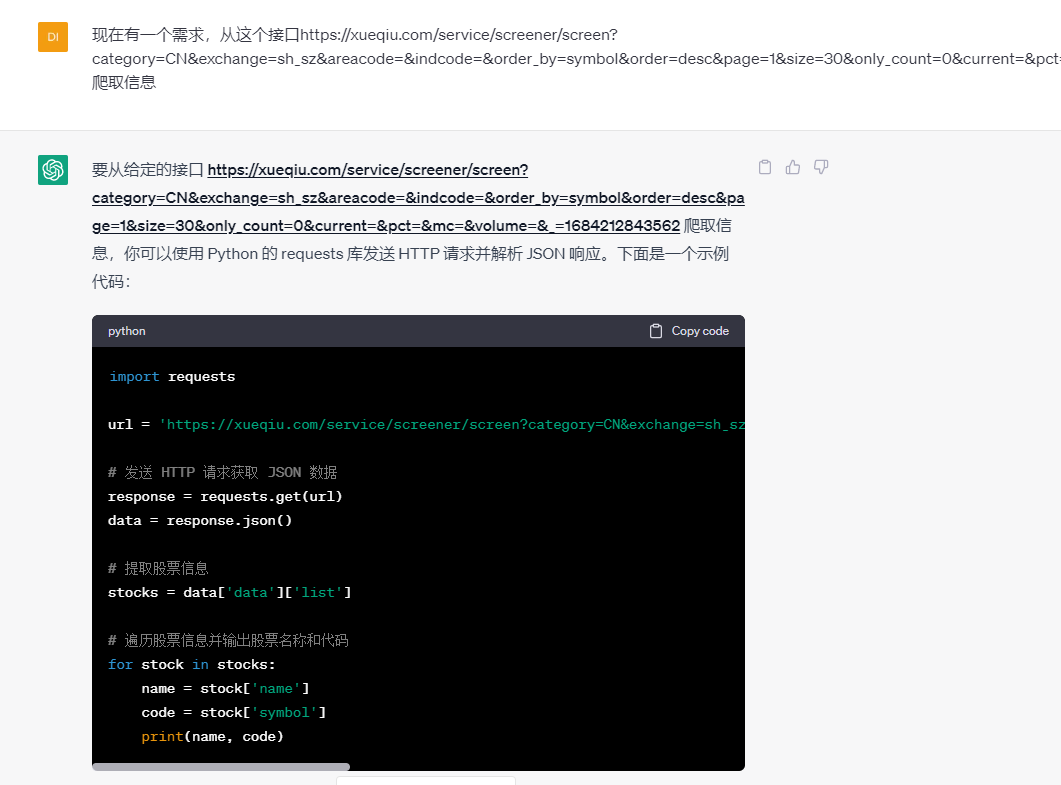
弄清楚了请求地址,我们再次向chatGPT提问。
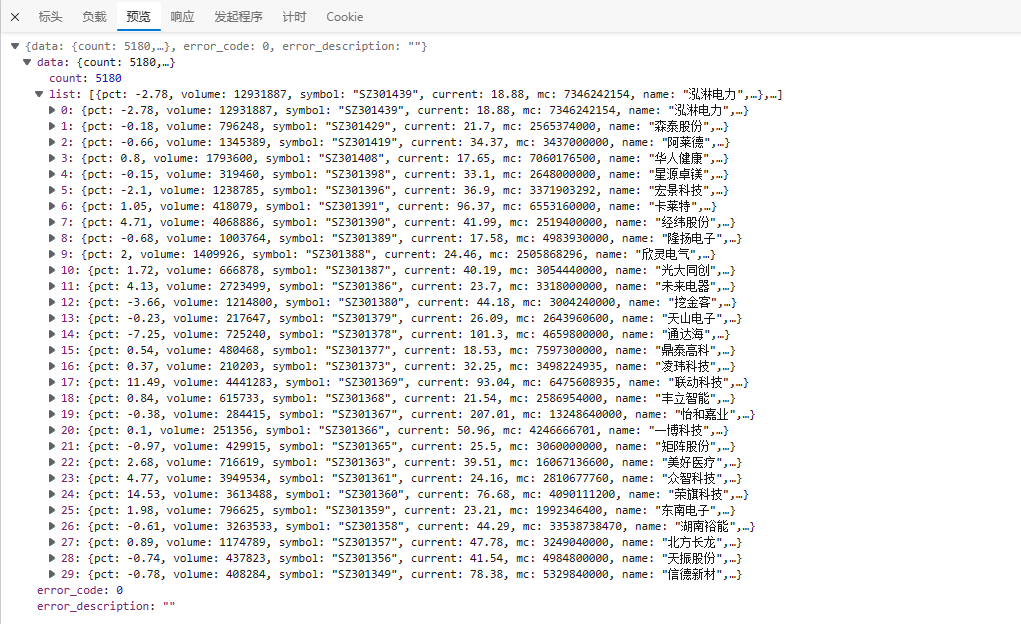
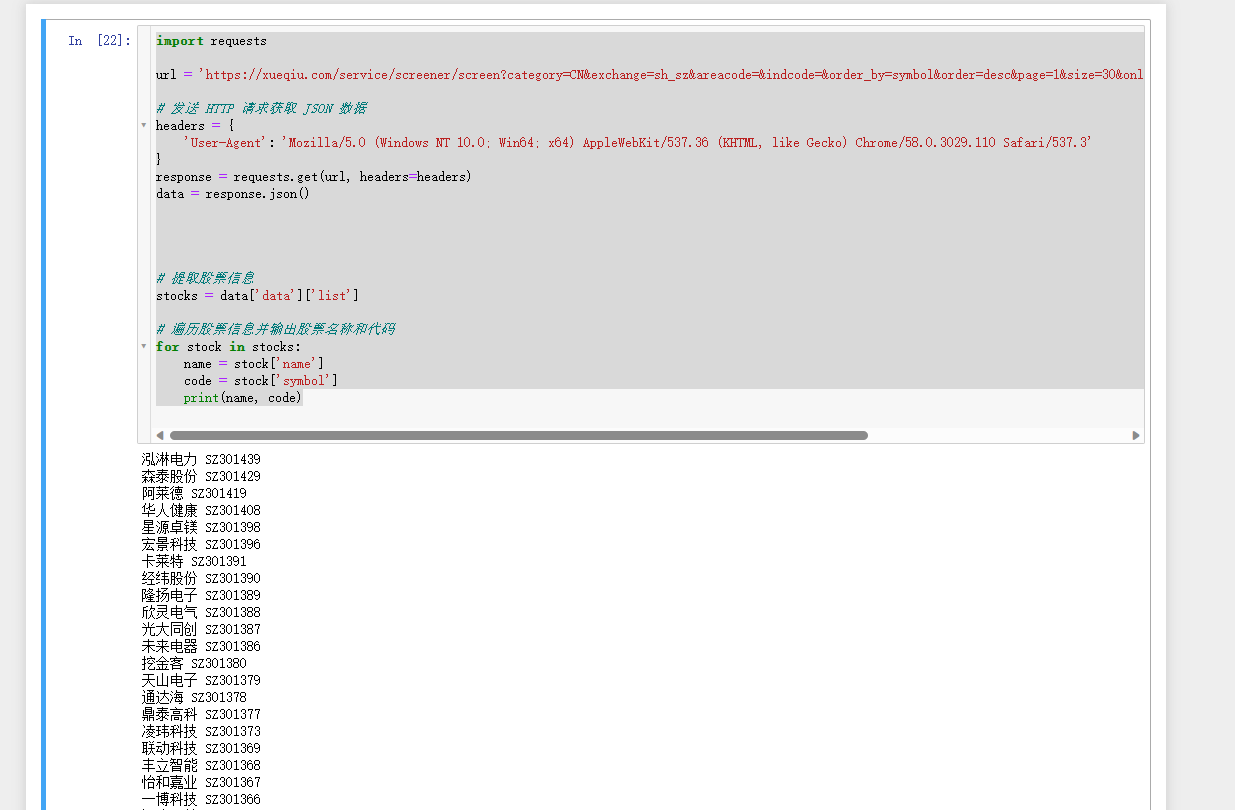
上述代码,它没有添加请求头,所以,我们要自行添加请求头 关键代码如下: import requests url = 'https://xueqiu.com/service/screener/screen?category=CN&exchange=sh_sz&areacode=&indcode=&order_by=symbol&order=desc&page=1&size=30&only_count=0¤t=&pct=&mc=&volume=&_=1684212843562' # 发送 HTTP 请求获取 JSON 数据 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3' } response = requests.get(url, headers=headers) data = response.json() # 提取股票信息 stocks = data['data']['list'] # 遍历股票信息并输出股票名称和代码 for stock in stocks: name = stock['name'] code = stock['symbol'] print(name, code)执行结果如下:
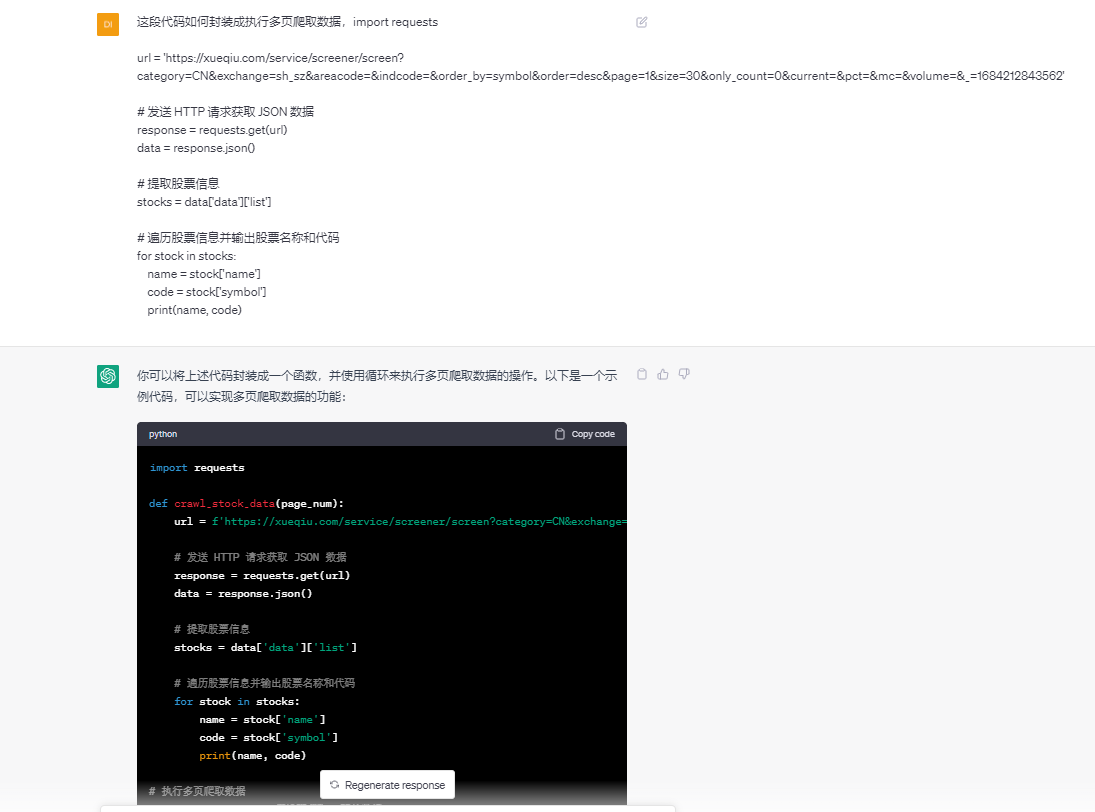
上述代码只是爬取单页的,现在我们要爬取多页的数据,把这个需求描述发给chatGPT,看它是如何解决的。
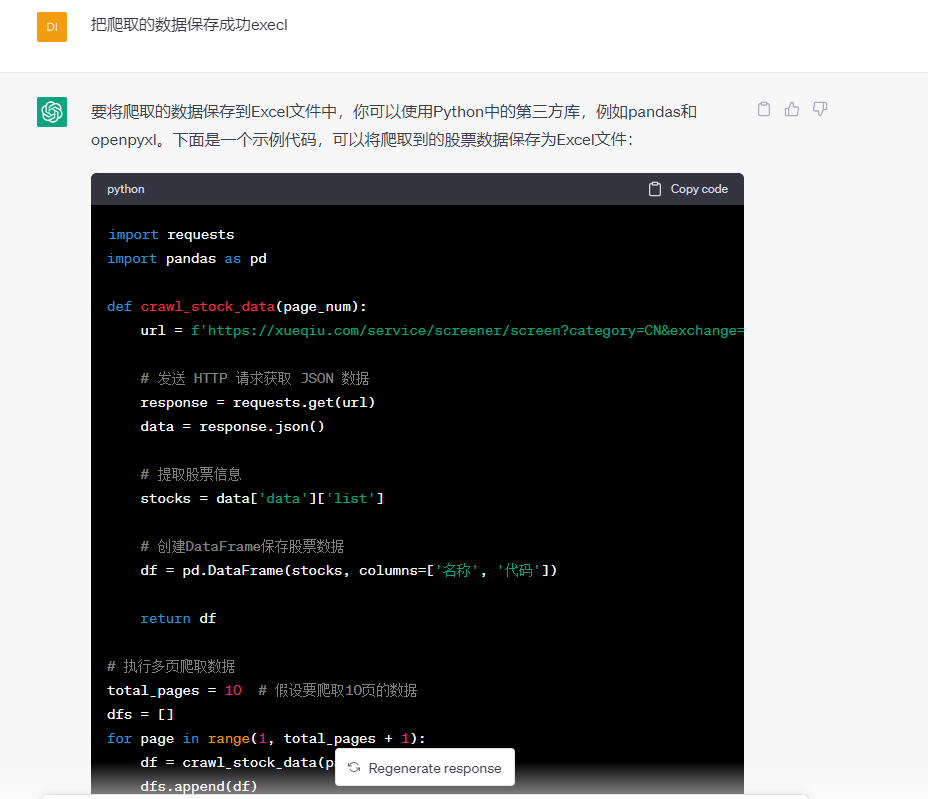
上述代码,它没有添加请求头,所以,我们要自行添加请求头 关键代码: import requests def crawl_stock_data(page_num): url = f'https://xueqiu.com/service/screener/screen?category=CN&exchange=sh_sz&areacode=&indcode=&order_by=symbol&order=desc&page={page_num}&size=30&only_count=0¤t=&pct=&mc=&volume=&_=1684212843562' # 发送 HTTP 请求获取 JSON 数据 response = requests.get(url) data = response.json() # 提取股票信息 stocks = data['data']['list'] # 遍历股票信息并输出股票名称和代码 for stock in stocks: name = stock['name'] code = stock['symbol'] print(name, code) # 执行多页爬取数据 total_pages = 10 # 假设要爬取10页的数据 for page in range(1, total_pages + 1): crawl_stock_data(page)下面就是把爬取的数据保存到execl中,再次把需求描述给chatGPT,看它是如何回复的:
执行成功的结果如下:
代码是完成了我们的需求,但是代码缺乏异常捕捉,如果代码出现错误后,会整个代码停止执行。 总结利用chatGPT学习爬虫是一个非常好的办法,只要我们把需求和问题向它描述,它都能分析错误和给出解决方法。大大的节省了收集资料的时间,提高了学习的效率。 本文由mdnice多平台发布 |
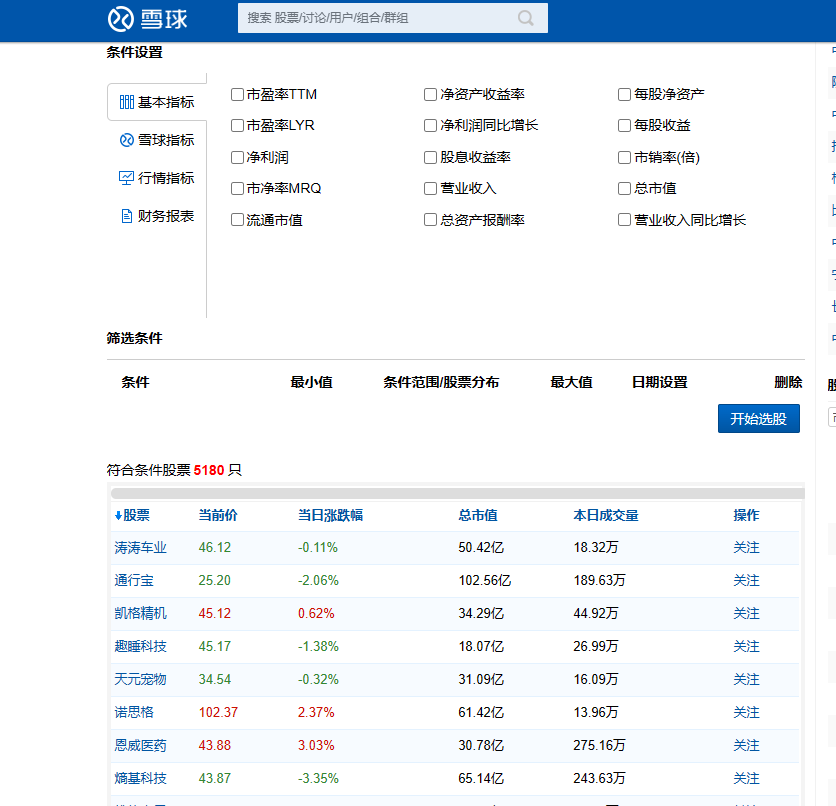
 然后,我们把代码复制到编辑器运行,如下图:
然后,我们把代码复制到编辑器运行,如下图:
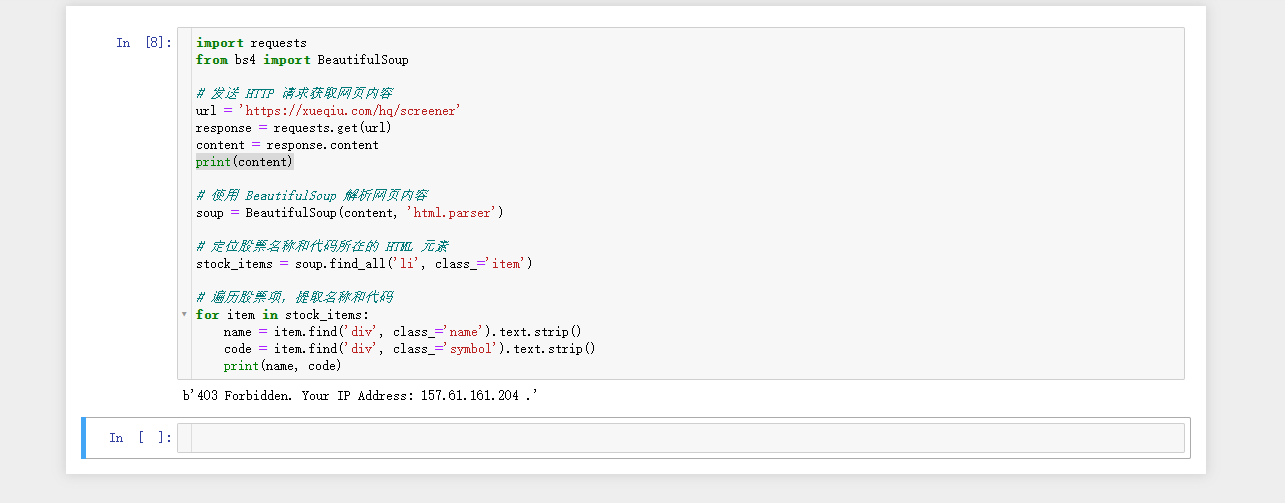
 没有任何返回值,估计是出错了,我们先打印一下content的值看看,如下图:
没有任何返回值,估计是出错了,我们先打印一下content的值看看,如下图:
 的确是出错了。我在把出错的问题进行描述,再向ChatGPT进行提问。如下图:
的确是出错了。我在把出错的问题进行描述,再向ChatGPT进行提问。如下图:
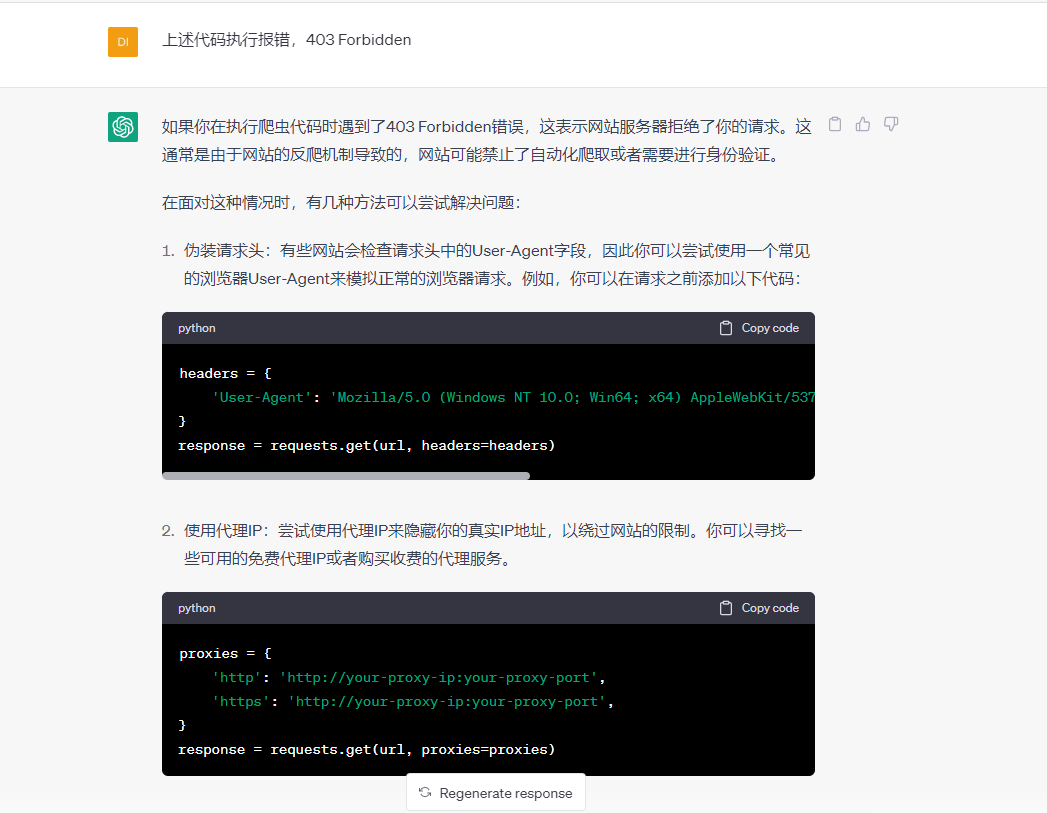 上述的回答中解析了为什么会出现这种错误,并给出了解决方法。我们采用第一种方式,为代码添加请求头,再次执行。
上述的回答中解析了为什么会出现这种错误,并给出了解决方法。我们采用第一种方式,为代码添加请求头,再次执行。
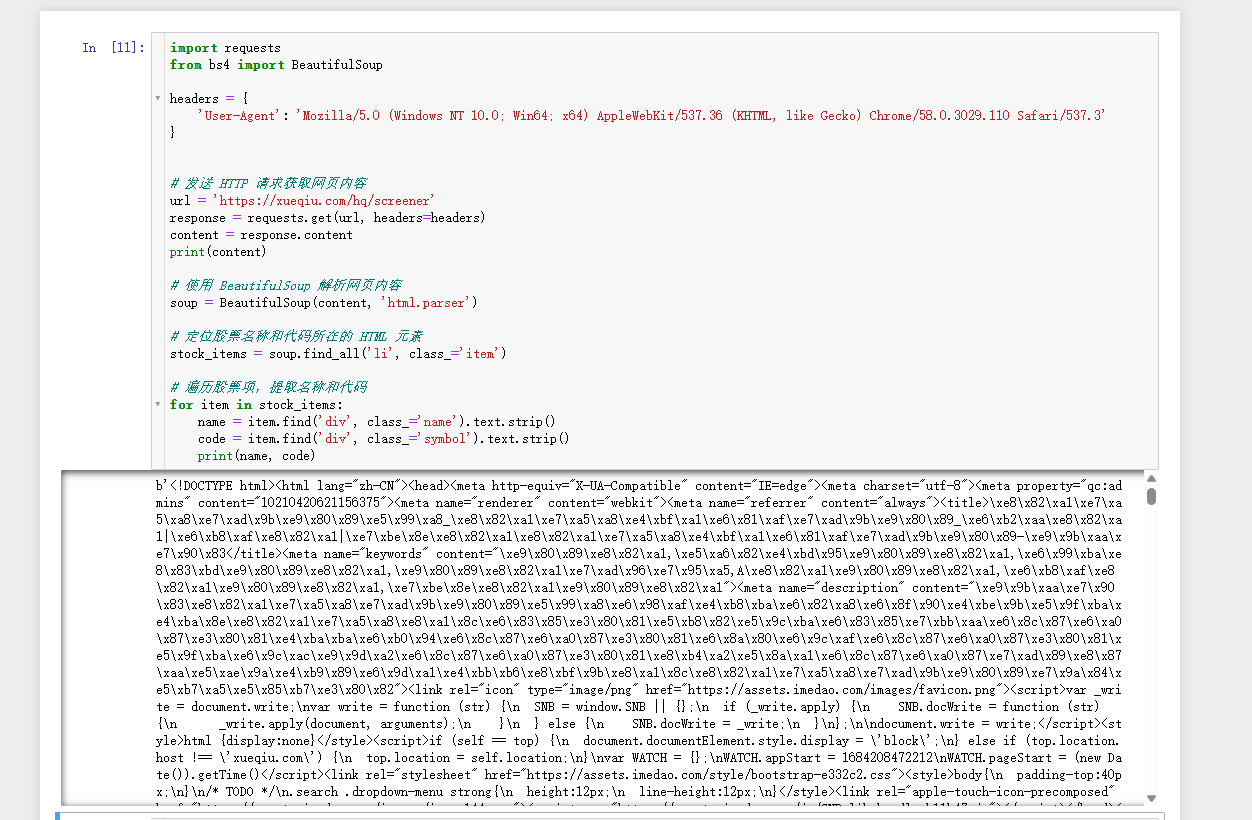 这次就成功把网页的内容返回了。但是页面中的内容并没有我们想要的信息。
这次就成功把网页的内容返回了。但是页面中的内容并没有我们想要的信息。

 这次又忘记添加请求头,于是,我提示它加上请求头。
这次又忘记添加请求头,于是,我提示它加上请求头。
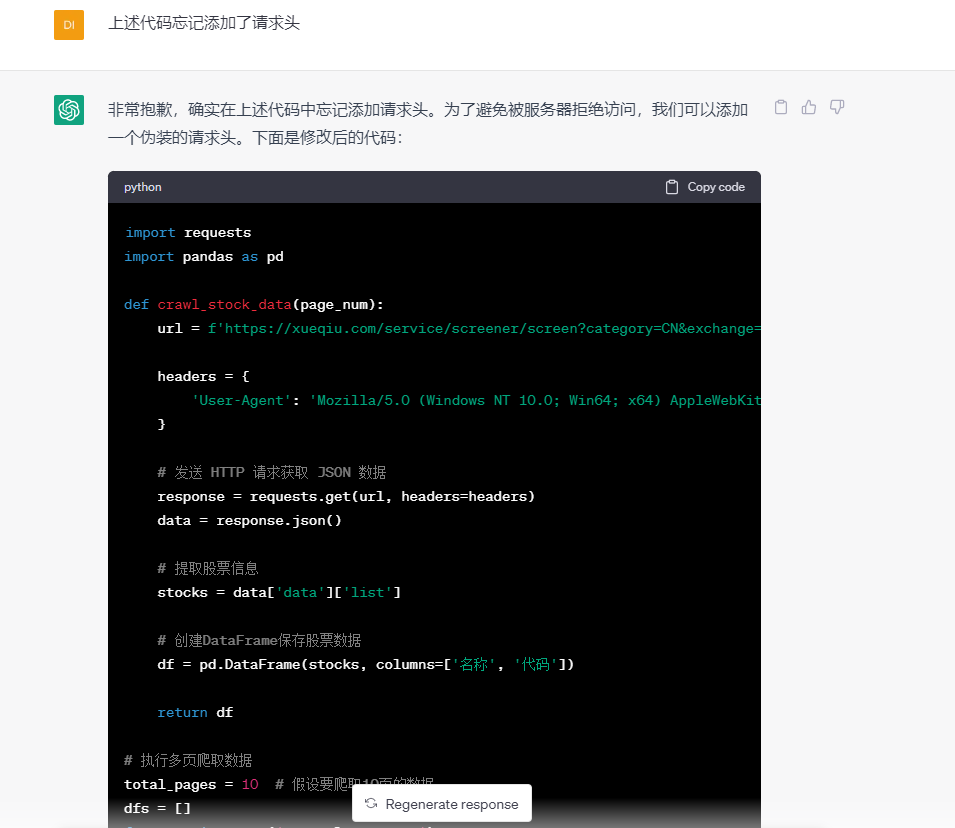 关键代码如下:
关键代码如下:
【本文地址】
今日新闻 |
推荐新闻 |