逻辑回归梯度下降推导 |
您所在的位置:网站首页 › 逻辑回归求解推导 › 逻辑回归梯度下降推导 |
逻辑回归梯度下降推导
|
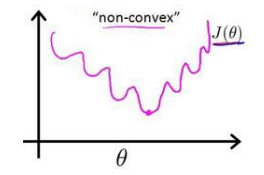
目录 什么是逻辑回归 逻辑回归的代价函数是怎么来的? 逻辑回归求导 参考 什么是逻辑回归 逻辑回归(Logistic Regression)是用于处理因变量为分类变量的回归问题,常见的是二分类或二项分布问题,也可以处理多分类问题,它实际上是属于一种分类方法。之所以顶着一个回归的马甲是因为和线性回归的联系太紧密了,我们常见的线性回归,预测函数如右: 这里我们先补充一下机器学习算法的基本算法步骤: 对于一个问题,用数学语言对它进行描述,然后建立一个相应的数学模型,比如回归模型或者分类模型。通过最大似然,最大后验概率密度,或者最小化分类误差等等建立模型的代价函数,也就是一个最优化问题,找到最优化问题的解,就是能拟合我们数据的最好模型参数。求解代价函数,找到最优解。 代价函数能够简单求导,且在求导后导数为0的式子存在解析解,即可直接得到最优参数。式子很难求导,例如变量相互依赖,矩阵求逆的巨量计算。此时需要取一个凸函数作为代价函数,进而通过梯度下降不断迭代去逼近最优解。回到正题,逻辑回归的代价函数是怎么来的。假设我们是逻辑回归的发明者,那么我们第一步肯定回想,既然逻辑回归和线性回归的关系这么紧密,那么代价函数的设计,直接依葫芦画瓢直接照搬线性回归,用MSE作为代价函数不就好了? 这个想法是非常美好的,但是很可惜这是一个非凸函数,其函数值如下:
所以上面这个函数并不适用,回到机器学习的基本步骤。可以先考虑最大似然,最大似然呢这个名词非常专业,但是我觉得可以做一个简单的理解,就是最大可能性是这样的意思。我个人理解是这样的,利用已知的样本结果,反推最有可能(最大概率,最大似然)导致这样结果的参数值。即“模型已定,观察数据已给出,根据观察数据反推参数值”。一般是对概率密度函数求导数得出相应的最优参数。 所以,对于逻辑回归,我们先来考虑单个样本的最大似然,多个样本是单个样本的联合概率密度,独立同分布,简单来说就是累乘。对于一个样本,假设我们已知在观察样本中出现1的概率是y,出现0的概率是1-y,预测1的概率是 于是回到机器学习基本步骤,将假设函数,联合概率密度等一一列出如下,准备进行求导:
前提条件: 1、sigmod函数的导数: 2. log的导数:(logax)'=1/(x * lna) 3. 上面的对数似然log即是In。 求导如下:
梯度下降:
https://www.cnblogs.com/hum0ro/p/9652674.html |
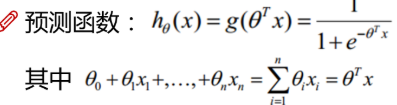

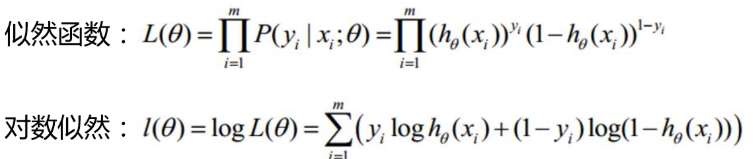
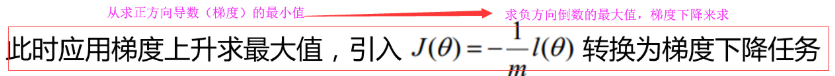


【本文地址】
今日新闻 |
推荐新闻 |