Logistic Regression(逻辑回归)模型实现二分类和多分类 |
您所在的位置:网站首页 › 逻辑回归模型输出的取值范围 › Logistic Regression(逻辑回归)模型实现二分类和多分类 |
Logistic Regression(逻辑回归)模型实现二分类和多分类
|
一、逻辑回归
当将训练集的样本以其各个特征为坐标轴在图中进行绘制时,通常可以找到某一个 判定边界 去将样本点进行分类。例如: 线性判定边界: 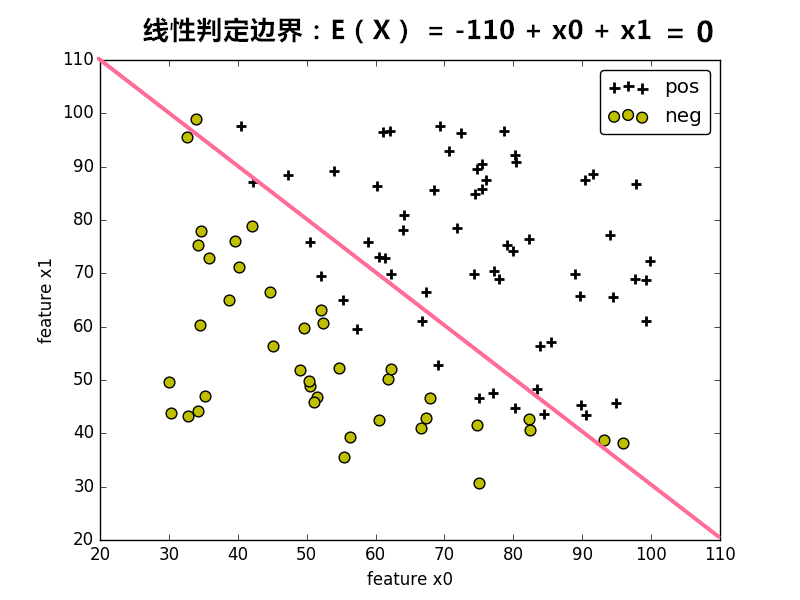
非线性判定边界: 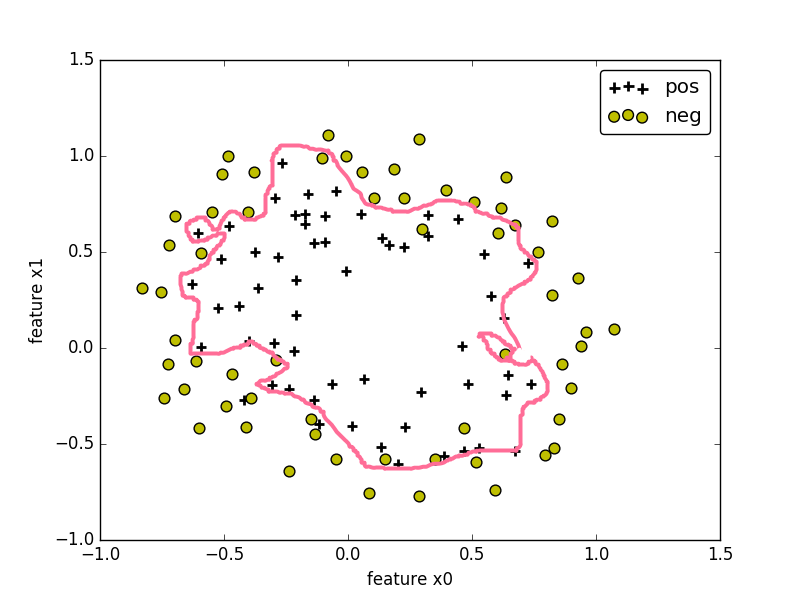
sigmoid函数图像如下: 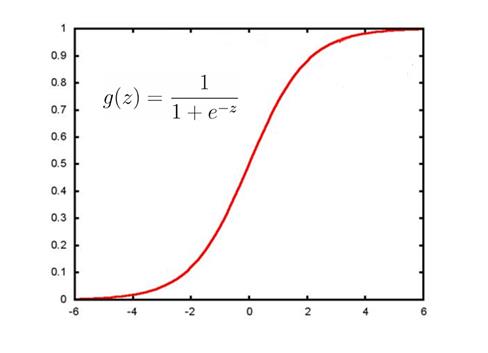
 四、损失函数
四、损失函数
上面是一种求损失函数的方式,我们也可以换一种方式来求损失函数,即极大似然估计。用极大似然估计来作为损失函数 同样,上式中的a为学习率(下山步长)。将上式的偏导展开,可得: 非正则化的损失函数的偏导: 含正则化项的损失函数的偏导: 其中 λ 为正则化的强度。 同线性回归般,可以通过学习率a对特征系数向量中的元素不断进行迭代,直到元素值收敛到某一值即可,这时可以得到损失函数较小时的特征向量系数Θ。 六、从二分类过渡到多分类在上面,我们主要使用逻辑回归解决二分类的问题,那对于多分类的问题,也可以用逻辑回归来解决? 1. one vs rest由于概率函数 hΘ(X) 所表示的是样本标记为某一类型的概率,但可以将一对一(二分类)扩展为一对多(one vs rest): 将类型class1看作正样本,其他类型全部看作负样本,然后我们就可以得到样本标记类型为该类型的概率p1; 然后再将另外类型class2看作正样本,其他类型全部看作负样本,同理得到p2; 以此循环,我们可以得到该待预测样本的标记类型分别为类型class i时的概率pi,最后我们取pi中最大的那个概率对应的样本标记类型作为我们的待预测样本类型。 2. softmax函数使用softmax函数构造模型解决多分类问题。 softmax回归分类器需要学习的函数为 : (这里下面的公式有问题,括号中的每一项应该都是以e为底的) 其中 k 个 类别的个数 , 其中 与 logistic回归 不同的是,softmax回归分类模型会有多个的输出,且输出个数 与 类别个数 相等,输出为样本 X 为各个类别的概率 ,最后对样本进行预测的类型为 概率最高 的那个类别。 我们需要通过学习得到 上式的代价函数也称作:对数似然代价函数。 在二分类的情况下,对数似然代价函数 可以转化为 交叉熵代价函数。 其中 m 为训练集样本的个数,k 为 类别的个数, 继续展开: 通过 梯度下降法 最小化损失函数 和 链式偏导,使用 化简可得: 再次化简可有: 因此由 梯度下降法 进行迭代: 同理 通过梯度下降法最小化损失函数也可以得到 同逻辑回归一样,可以给损失函数加上正则化项。 3. 选择的方案当标签类别之间是互斥时,适合选择softmax回归分类器 ;当标签类别之间不完全互斥时,适合选择建立多个独立的logistic回归分类器。 4. tensorflow代码示例: 使用softmax回归对sklearn中的digit手写数据进行分类 import tensorflow as tf from sklearn.datasets import load_digits import numpy as np digits = load_digits() X_data = digits.data.astype(np.float32) Y_data = digits.target.reshape(-1,1).astype(np.float32) print X_data.shape print Y_data.shape (1797, 64) (1797, 1) from sklearn.preprocessing import MinMaxScaler scaler = MinMaxScaler() X_data = scaler.fit_transform(X_data) from sklearn.preprocessing import OneHotEncoder Y = OneHotEncoder().fit_transform(Y_data).todense() #one-hot编码 Y matrix([[ 1., 0., 0., ..., 0., 0., 0.], [ 0., 1., 0., ..., 0., 0., 0.], [ 0., 0., 1., ..., 0., 0., 0.], ..., [ 0., 0., 0., ..., 0., 1., 0.], [ 0., 0., 0., ..., 0., 0., 1.], [ 0., 0., 0., ..., 0., 1., 0.]]) print Y.shape (1797, 10) 1797 batch_size = 10 # 使用MBGD算法,设定batch_size为10 def generatebatch(X,Y,n_examples, batch_size): for batch_i in range(n_examples // batch_size): start = batch_i*batch_size end = start + batch_size batch_xs = X[start:end, :] batch_ys = Y[start:end] yield batch_xs, batch_ys # 生成每一个batch tf.reset_default_graph() tf_X = tf.placeholder(tf.float32,[None,64]) tf_Y = tf.placeholder(tf.float32,[None,10]) tf_W_L1 = tf.Variable(tf.zeros([64,10])) tf_b_L1 = tf.Variable(tf.zeros([1,10])) pred = tf.nn.softmax(tf.matmul(tf_X,tf_W_L1)+tf_b_L1) loss = -tf.reduce_mean(tf_Y*tf.log(tf.clip_by_value(pred,1e-11,1.0))) # 也可以直接使用tensorflow的版本: # loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=tf_Y,logits=pred)) train_step = tf.train.GradientDescentOptimizer(0.2).minimize(loss) y_pred = tf.arg_max(pred,1) bool_pred = tf.equal(tf.arg_max(tf_Y,1),y_pred) accuracy = tf.reduce_mean(tf.cast(bool_pred,tf.float32)) # 准确率 with tf.Session() as sess: sess.run(tf.global_variables_initializer()) for epoch in range(2001): # 迭代2001个周期 for batch_xs,batch_ys in generatebatch(X_data,Y,Y.shape[0],batch_size): # 每个周期进行MBGD算法 sess.run(train_step,feed_dict={tf_X:batch_xs,tf_Y:batch_ys}) if(epoch%1000==0): res = sess.run(accuracy,feed_dict={tf_X:X_data,tf_Y:Y}) print (epoch,res) res_ypred = y_pred.eval(feed_dict={tf_X:X_data,tf_Y:Y}).flatten() print res_ypred (0, 0.86866999) (1000, 0.99332219) (2000, 0.99833053) [0 1 2 ..., 8 9 8] from sklearn.metrics import accuracy_score print accuracy_score(Y_data,res_ypred.reshape(-1,1)) 0.998330550918 八、Logistic Loss的另一种表达在上面的逻辑回归的二分类问题中,我们令正样本的标签 y = 1 ,负样本的标签 y = 0。对于单个样本来说,其损失函数Cost(hΘ(X),y)可以表示为:(hΘ(X)的值表示正样本的概率) 若我们 令正样本的标签 y = 1 ,负样本的标签 y = -1,则有: 其中(待续) 七、代码示例 使用ovr多分类的逻辑回归判断鸢尾属植物的类型 from sklearn import datasets iris = datasets.load_iris() # 加载数据 X = iris.data y = iris.target print X.shape print y.shape (150L, 4L) (150L,) from sklearn.model_selection import train_test_split #分隔训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y ,test_size = 1/3.,random_state = 8) from sklearn.preprocessing import PolynomialFeatures featurizer = PolynomialFeatures(degree=2) # 特征多项式化 X_train = featurizer.fit_transform(X_train) X_test = featurizer.transform(X_test) from sklearn.preprocessing import StandardScaler # 对数据归一化 scaler = StandardScaler() X_std_train = scaler.fit_transform(X_train) X_std_test = scaler.transform(X_test) from sklearn.linear_model import LogisticRegression from sklearn.linear_model import SGDClassifier # penalty:正则化 l2/l1 # C :正则化强度 # multi_class:多分类时使用 ovr: one vs rest lor = LogisticRegression(penalty='l1',C=100,multi_class='ovr') lor.fit(X_std_train,y_train) print lor.score(X_std_test,y_test) sgdv = SGDClassifier(penalty='l1') sgdv.fit(X_std_train,y_train) print sgdv.score(X_std_test,y_test) 0.94 0.92 LogisticRegression对参数的计算采用精确解析的方式,计算时间长但模型的性能高;SGDClassifier采用随机梯度下降/上升算法估计模型的参数,计算时间短但模型的性能较低。 使用Tensorflow实现线性逻辑回归: from sklearn.datasets import make_classification import matplotlib.pyplot as plt import numpy as np X, y = make_classification(n_features=2, n_redundant=0, n_informative=2, n_clusters_per_class=1,random_state=78,n_samples=200) X = X.astype(np.float32) y = y.astype(np.float32) plt.scatter(X[:,0],X[:,1],c=y) plt.show() |









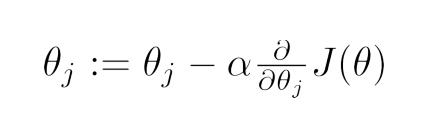
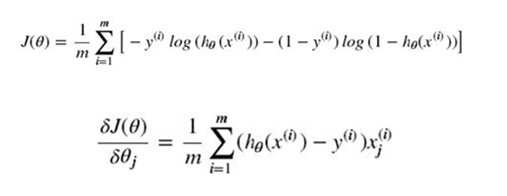
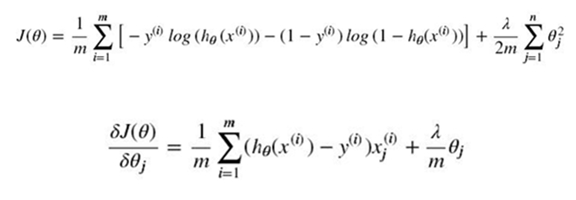

 和
和  为 第 i 个 类别对应的 权重向量 和 偏移标量。
为 第 i 个 类别对应的 权重向量 和 偏移标量。 可看作样本 X 的标签 为 第 j 个 类别的概率,且有
可看作样本 X 的标签 为 第 j 个 类别的概率,且有  。
。
 为示性函数,当
为示性函数,当  为真时,函数值为 1 ,否则为 0 ,即 样本类别正确时,函数值才为 1 。
为真时,函数值为 1 ,否则为 0 ,即 样本类别正确时,函数值才为 1 。


 对
对 



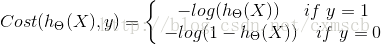


【本文地址】
今日新闻 |
推荐新闻 |