案例实战:Python实现逻辑回归(Logistic Regression)与梯度下降策略 |
您所在的位置:网站首页 › 逻辑回归模型例题分析 › 案例实战:Python实现逻辑回归(Logistic Regression)与梯度下降策略 |
案例实战:Python实现逻辑回归(Logistic Regression)与梯度下降策略
|
0. 案例背景
我们将建立一个逻辑回归模型来预测一个学生是否被大学录取。假设你是一个大学系的管理员,你想根据两次考试的结果来决定每个申请人的录取机会。你有以前的申请人的历史数据,你可以用它作为逻辑回归的训练集。对于每一个培训例子,你有两个考试的申请人的分数和录取决定。为了做到这一点,我们将建立一个分类模型,根据考试成绩估计入学概率。 1. 导入pythony库 #导入机器学习三大件:Numpy, Pandas, Matplotlib import numpy as np import pandas as pd import matplotlib import matplotlib.pyplot as plt %matplotlib inline for i in [np, pd, matplotlib]: print(i.__version__)输出: 1.17.4 0.25.3 3.1.2 2. 导入数据集 import os path = 'data' + os.sep + 'LogiReg_data.txt' pdData = pd.read_csv(path, header=None, names=['Exam1', 'Exam2', 'Admitted']) print(pdData.head(8)) print("Data shape:",pdData.shape)输出: Exam1 Exam2 Admitted 0 34.623660 78.024693 0 1 30.286711 43.894998 0 2 35.847409 72.902198 0 3 60.182599 86.308552 1 4 79.032736 75.344376 1 5 45.083277 56.316372 0 6 61.106665 96.511426 1 7 75.024746 46.554014 1 Data shape: (100, 3) 3. 数据可视化 positive = pdData[pdData['Admitted'] == 1] # 返回Admitted列值为1的样本 negative = pdData[pdData['Admitted'] == 0] # 返回Admitted列值为1的样本 fig, ax = plt.subplots(figsize=(10,5)) ax.scatter(positive['Exam1'], positive['Exam2'], s=30, c='b', marker='o', label='Admitted') ax.scatter(negative['Exam1'], negative['Exam2'], s=30, c='r', marker='x', label='Not Admitted') ax.legend() ax.set_xlabel('Exam1 Score') ax.set_ylabel('Exam2 Score')输出:
从上图可以看出:数据具有一定的可区分性。红色点(负样本)总体位于左下方,而蓝色点(正样本)总体位于右上方。 4. 数据处理在模型构建中为了方便书写和计算,将偏置项用W0表示,因此在数据所有样本的第一列插入1,即b=W0*1 try: pdData.insert(0, 'Ones', 1) # 写到try...except结构中以防第二次执行时报错 except: pass orig_data = pdData.as_matrix() # 将Pandas的DataFrame转换成矩阵形成 print(type(orig_data)) print(orig_data.shape) cols = orig_data.shape[1] X = orig_data[:,0:cols-1] y = orig_data[:,cols-1:cols] print("X shape:",X.shape) print("y shape:",y.shape) #X = np.matrix(X.values) #y = np.matrix(data.iloc[:,3:4].values) #np.array(y.values) W = np.zeros([3, 1]) print("W shape:",W.shape)输出: (100, 4) X shape: (100, 3) y shape: (100, 1) W shape: (3, 1)根据X, y, W的shape以及矩阵乘法相关知识可得:XW=y 5. 用Python手动实现逻辑回归目标:建立逻辑回归模型,即求解出参数𝑊W。由于数据共有3列:Exam1,Exam2,Admitted,其中Admitted作为标签使用。因此𝑊可以表示为3*1的向量(这里偏置项用𝑊0代替,方便书写和矩阵计算)。
设定阈值,根据阈值判断录取结果 需要完成的模块 sigmoid : 映射到概率的函数model : 返回预测结果值cost : 根据参数计算损失gradient : 计算每个参数的梯度方向descent : 进行参数更新accuracy: 计算精度 5.1 sigmoid 函数
输出:
可以看到Sigmoid函数的值域为(0,1),可以当作概率来看待。 5.2 model函数 def model(X, W): return sigmoid(np.dot(X, W))
根据逻辑回归目标函数:
公式推导见:逻辑回归(Logistic Regression)算法原理推导 def Loss(X, y, W): left = np.multiply(y, np.log(model(X, W))) right = np.multiply(1 - y, np.log(1 - model(X, W))) return -np.sum(left + right) / (len(X)) print(Loss(X, y, W))输出: 0.6931471805599453 5.4 梯度函数
公式推导见:逻辑回归(Logistic Regression)算法原理推导 def Gradient(X, y, W): grad = np.zeros(W.shape) error = (model(X, W)- y) grad = np.dot(X.T, error)/len(X) return grad grad = Gradient(X, y, W) print(grad)输出: [[ -0.1 ] [-12.00921659] [-11.26284221]]输出即为初始的梯度。 5.5 梯度下降(Gradient descent)比较3中不同梯度下降方法 STOP_ITER = 0 STOP_COST = 1 STOP_GRAD = 2 def stopCriterion(type, value, threshold): #设定三种不同的停止策略 if type == STOP_ITER: # return value > threshold elif type == STOP_COST: return abs(value[-1]-value[-2]) < threshold elif type == STOP_GRAD: return np.linalg.norm(value) < threshold def shuffleData(data): np.random.shuffle(data) cols = data.shape[1] X = data[:, 0:cols-1] y = data[:, cols-1:] return X, y import time def descent(data, W, batchSize, stopType, thresh, alpha): #梯度下降求解 init_time = time.time() i = 0 # 迭代次数 k = 0 # batch X, y = shuffleData(data) grad = np.zeros(W.shape) # 计算的梯度 costs = [Loss(X, y, W)] # 损失值 while True: grad = Gradient(X[k:k+batchSize], y[k:k+batchSize], W) k += batchSize #取batch数量个数据 if k >= n: k = 0 X, y = shuffleData(data) #重新洗牌 W = W - alpha*grad # 参数更新 costs.append(Loss(X, y, W)) # 计算新的损失 i += 1 if stopType == STOP_ITER: value = i elif stopType == STOP_COST: value = costs elif stopType == STOP_GRAD: value = grad if stopCriterion(stopType, value, thresh): break return W, i-1, costs, grad, time.time() - init_time def runExpe(data, W, batchSize, stopType, thresh, alpha): #import pdb; pdb.set_trace(); W, iter, costs, grad, dur = descent(data, W, batchSize, stopType, thresh, alpha) name = "Original" if (data[:,1]>2).sum() > 1 else "Scaled" name += " data - learning rate: {} - ".format(alpha) if batchSize==n: strDescType = "Gradient" elif batchSize==1: strDescType = "Stochastic" else: strDescType = "Mini-batch ({})".format(batchSize) name += strDescType + " descent - Stop: " if stopType == STOP_ITER: strStop = "{} iterations".format(thresh) elif stopType == STOP_COST: strStop = "costs change < {}".format(thresh) else: strStop = "gradient norm < {}".format(thresh) name += strStop print ("***{}\nW: {} - \nIter: {} - Last cost: {:03.2f} - Duration: {:03.2f}s".format( name, W, iter, costs[-1], dur)) fig, ax = plt.subplots(figsize=(12,4)) ax.plot(np.arange(len(costs)), costs, 'r') ax.set_xlabel('Iterations') ax.set_ylabel('Cost') ax.set_title(name.upper() + ' - Error vs. Iteration') return W 5.6 研究不同的停止策略对结果的影响 5.6.1 设定迭代次数 n=100 #选择的梯度下降方法是基于所有样本的,因为总共就有100个样本 runExpe(orig_data, W, n, STOP_ITER, thresh=5000, alpha=0.000001)输出: ***Original data - learning rate: 1e-06 - Gradient descent - Stop: 5000 iterations W: [[-0.00027127] [ 0.00705232] [ 0.00376711]] - Iter: 5000 - Last cost: 0.63 - Duration: 0.72s Out[297]: array([[-0.00027127], [ 0.00705232], [ 0.00376711]])
设定阈值 1E-6, 差不多需要110 000次迭代 n = 100 runExpe(orig_data, W, n, STOP_COST, thresh=0.000001, alpha=0.001)输出: ***Original data - learning rate: 0.001 - Gradient descent - Stop: costs change < 1e-06 W: [[-5.13364014] [ 0.04771429] [ 0.04072397]] - Iter: 109901 - Last cost: 0.38 - Duration: 15.96s Out[268]: array([[-5.13364014], [ 0.04771429], [ 0.04072397]])
设定阈值 0.05,差不多需要40 000次迭代 n = 100 runExpe(orig_data, W, n, STOP_GRAD, thresh=0.05, alpha=0.001)输出: ***Original data - learning rate: 0.001 - Gradient descent - Stop: gradient norm < 0.05 Theta: [[1.14934134] [2.79258729] [2.56635486]] - Iter: 40045 - Last cost: 0.49 - Duration: 6.46s Out[174]: array([[-2.37033409], [ 0.02721692], [ 0.01899456]])
注意:下面几个随机梯度下降的例子每次运行的结果可能不一样,因为是每次选取的随机样本不一样。 5.7.1 随机梯度下降(Stochastic descent) n = 1 runExpe(orig_data, W, n, STOP_ITER, thresh=5000, alpha=0.001)输出: ***Original data - learning rate: 0.001 - Gradient descent - Stop: 5000 iterations W: [[-0.36353926] [ 0.04708261] [-0.06730932]] - Iter: 5000 - Last cost: 1.42 - Duration: 0.71s Out[301]: array([[-0.36353926], [ 0.04708261], [-0.06730932]])
由上图可以看出,损失值振荡幅度很大。尝试调小学习率。 runExpe(orig_data, W, 1, STOP_ITER, thresh=15000, alpha=0.00002)输出: ***Original data - learning rate: 2e-05 - Stochastic descent - Stop: 15000 iterations Theta: [[1.14934134] [2.79258729] [2.56635486]] - Iter: 15000 - Last cost: 0.63 - Duration: 0.73s Out[177]: array([[-0.02101212], [ 0.01132223], [ 0.00104678]])
可以看出振荡幅度稍微有些缓和,可自行尝试更小的学习率,观察损失值振荡是否还会减弱。 5.7.2 批量随机梯度下降(Mini-batch descent)可尝试16,32,64等不同的批大小: 批大小为16时: runExpe(orig_data, W, 16, STOP_ITER, thresh=15000, alpha=0.001)输出: ***Original data - learning rate: 0.001 - Mini-batch (16) descent - Stop: 15000 iterations W: [[-1.01560025] [ 0.01830399] [ 0.01316626]] - Iter: 15000 - Last cost: 0.58 - Duration: 2.10s Out[304]: array([[-1.01560025], [ 0.01830399], [ 0.01316626]])
批大小为64时: runExpe(orig_data, W, 64, STOP_ITER, thresh=15000, alpha=0.001)输出: ***Original data - learning rate: 0.001 - Mini-batch (64) descent - Stop: 15000 iterations W: [[-0.99214625] [ 0.01786299] [ 0.00733927]] - Iter: 15000 - Last cost: 0.56 - Duration: 2.10s Out[306]: array([[-0.99214625], [ 0.01786299], [ 0.00733927]])
对比批大小16和64的结果图:很明显批大小为64时损失值振荡幅度更小。(注意:两张图的纵坐标范围大小不一样) 5.8 研究数据处理对结果的影响在机器学习建模前,通常需要对数据进行预处理。常见的处理方法是标准化(或称归一化),即将数据按其属性(按列进行)减去其均值,然后除以其方差,得到均值为0,方差为1的数据集。 from sklearn import preprocessing as pp scaled_data = orig_data.copy() scaled_data[:, 1:3] = pp.scale(orig_data[:, 1:3]) n = 100 runExpe(scaled_data, W, n, STOP_ITER, thresh=5000, alpha=0.001)输出: ***Scaled data - learning rate: 0.001 - Gradient descent - Stop: 5000 iterations W: [[0.3080807 ] [0.86494967] [0.77367651]] - Iter: 5000 - Last cost: 0.38 - Duration: 0.74s Out[316]: array([[0.3080807 ], [0.86494967], [0.77367651]])
5.6中利用原始数据建模预测的结果,最好的结果只能达到达到0.61。而对数据进行预处理后,已经达到了0.38好结果。通过调整其它参数,将会得到后面所示更好的结果。 n= 100 runExpe(scaled_data, W, n, STOP_GRAD, thresh=0.02, alpha=0.001)输出: ***Scaled data - learning rate: 0.001 - Gradient descent - Stop: gradient norm < 0.02 W: [[1.0707921 ] [2.63030842] [2.41079787]] - Iter: 59422 - Last cost: 0.22 - Duration: 9.05s Out[319]: array([[1.0707921 ], [2.63030842], [2.41079787]])
输出: ***Scaled data - learning rate: 0.001 - Stochastic descent - Stop: gradient norm < 0.0004 W: [[1.14745059] [2.79268354] [2.56859444]] - Iter: 72681 - Last cost: 0.22 - Duration: 3.32s Out[320]: array([[1.14745059], [2.79268354], [2.56859444]])
输出: ***Scaled data - learning rate: 0.001 - Mini-batch (16) descent - Stop: gradient norm < 0.004 W: [[1.04991433] [2.57978973] [2.36638254]] - Iter: 56083 - Last cost: 0.22 - Duration: 3.44s Out[321]: array([[1.04991433], [2.57978973], [2.36638254]])
通过尝试不同的参数发现,最好结果停留在损失值为0.22的结果上。 5.9 精确度计算函数 #设定阈值 def predict(X, W): return [1 if x >= 0.5 else 0 for x in model(X, W)] n = 100 W = runExpe(scaled_data, W, 64, STOP_GRAD, thresh=0.002*2, alpha=0.001) # 将W保存下来 scaled_X = scaled_data[:, :3] y = scaled_data[:, 3] predictions = predict(scaled_X, W) correct = [1 if ((a == 1 and b == 1) or (a == 0 and b == 0)) else 0 for (a, b) in zip(predictions, y)] accuracy = (sum(map(int, correct)) % len(correct)) print ('accuracy = {0}%'.format(accuracy))输出: ***Scaled data - learning rate: 0.001 - Mini-batch (64) descent - Stop: gradient norm < 0.004 W: [[1.11200715] [2.7166569 ] [2.49287266]] - Iter: 29877 - Last cost: 0.22 - Duration: 2.98s accuracy = 89%可以发现,模型最终的精确度达到89%。
|

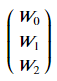
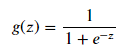

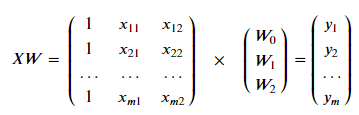











【本文地址】