机器学习实战:Python基于Logistic逻辑回归进行分类预测(一) |
您所在的位置:网站首页 › 逻辑回归主要用于回归分析 › 机器学习实战:Python基于Logistic逻辑回归进行分类预测(一) |
机器学习实战:Python基于Logistic逻辑回归进行分类预测(一)
|
目录
1 前言1.1 Logistic回归的介绍1.2 Logistic回归的应用
2 iris数据集数据处理2.1 导入函数2.2 导入数据2.3 简单数据查看
3 可视化3.1 条形图/散点图3.2 箱线图3.3 三维散点图
4 建模预测4.1 二分类预测4.2 多分类预测
5 讨论
1 前言
1.1 Logistic回归的介绍
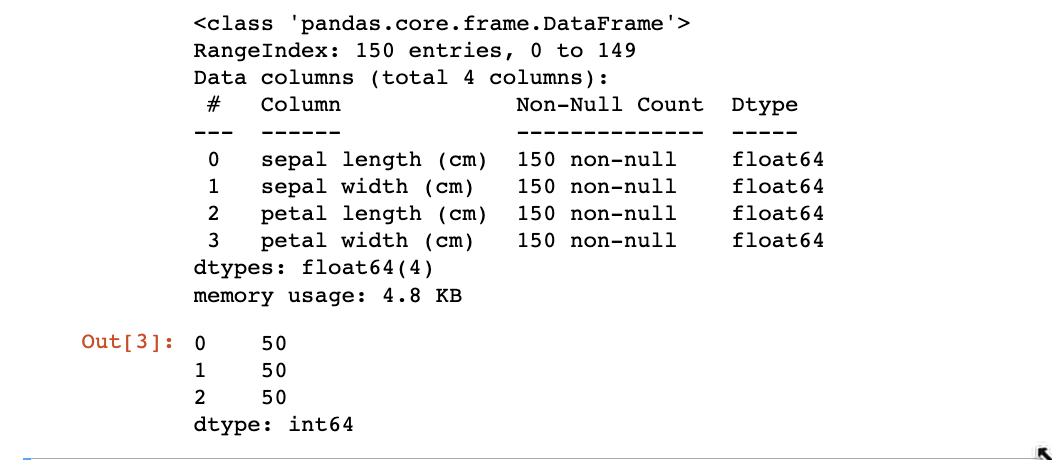
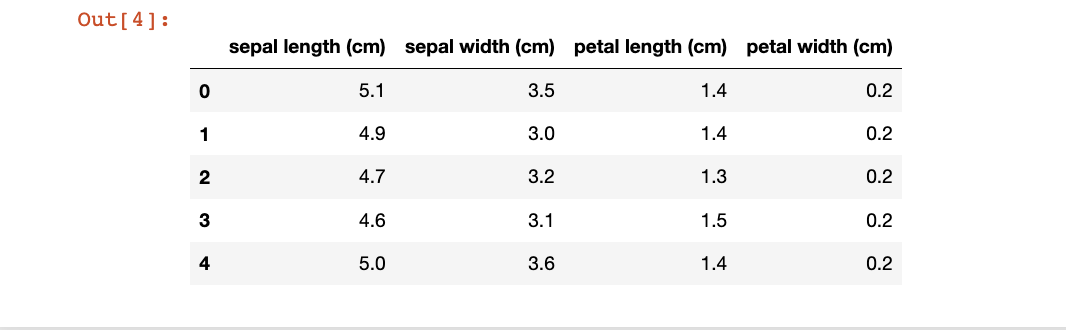
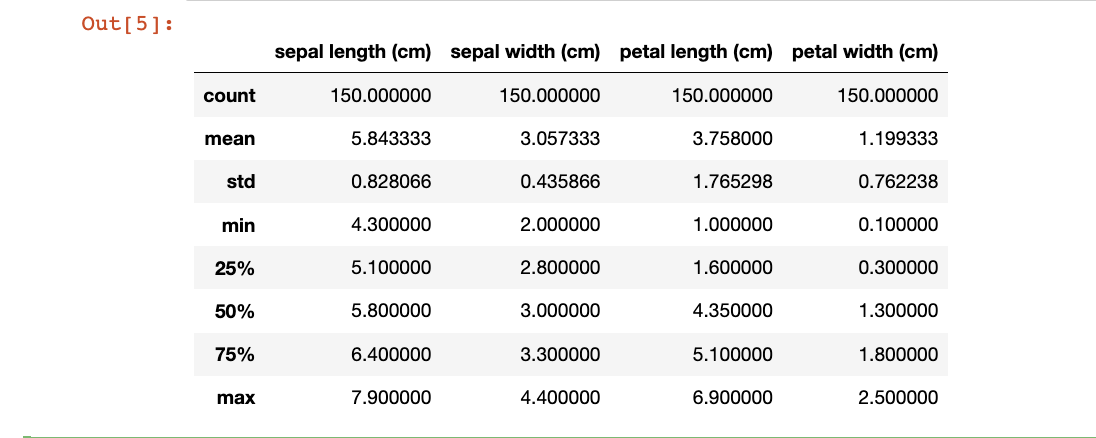
逻辑回归(Logistic regression,简称LR)是一种经典的二分类算法,它将输入特征与一个sigmoid函数进行线性组合,从而预测输出标签的概率。该算法常被用于预测离散的二元结果,例如是/否、真/假等。 优点: 实现简单。Logistic回归的参数可以用极大似然估计法进行求解,算法本身非常简单。 速度快。Logistic回归计算量小,训练速度快。 输出结果易于理解。Logistic回归的输出结果是概率,易于解释。 容易扩展。Logistic回归可用于多分类问题和不平衡数据集。 缺点: 只适用于线性可分的问题。当特征之间存在非线性关系时,Logistic回归的效果会受到限制。 对异常值敏感。由于Logistic回归使用了sigmoid函数,对于异常值非常敏感。 容易欠拟合。当特征与目标变量之间的关系非常复杂时,Logistic回归很容易出现欠拟合现象。 1.2 Logistic回归的应用Logistic回归广泛应用于许多领域,包括: 金融风险评估。银行和信用卡公司使用Logistic回归来评估借款人的信用风险,预测贷款违约的概率。 医学诊断。Logistic回归可以用于预测患者是否患有某种疾病或病情的严重程度。 市场分析。Logistic回归可以用于预测产品或服务的市场需求,并帮助企业做出更好的决策。 自然语言处理。Logistic回归可以用于文本分类,例如判断一段文本是否属于某个主题或情感极性。 图像处理。Logistic回归可以用于图像分类和目标检测,例如识别数字和字母。 总之,Logistic回归是一种灵活的算法,可以应用于许多不同的领域和问题,特别是在需要预测二元结果的场景中表现出色。 2 iris数据集数据处理iris数据集共有150个样本,目标变量为花的类别其都属于鸢尾属下的三个亚属(target),分别是山鸢尾 (Iris-setosa),变色鸢尾(Iris-versicolor)和维吉尼亚鸢尾(Iris-virginica)。 四个特征,分别是花萼长度(sepal length)、花萼宽度(sepal width)、花瓣长度(petal length)、花瓣宽度(petal width)。 2.1 导入函数 import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns 2.2 导入数据 from sklearn.datasets import load_iris data = load_iris() iris_target = data.target iris_features = pd.DataFrame(data=data.data, columns=data.feature_names) #利用Pandas转化为DataFrame格式 2.3 简单数据查看 ## 查看数据的整体信息 iris_features.info() ## 查看每个类别数量 pd.Series(iris_target).value_counts()
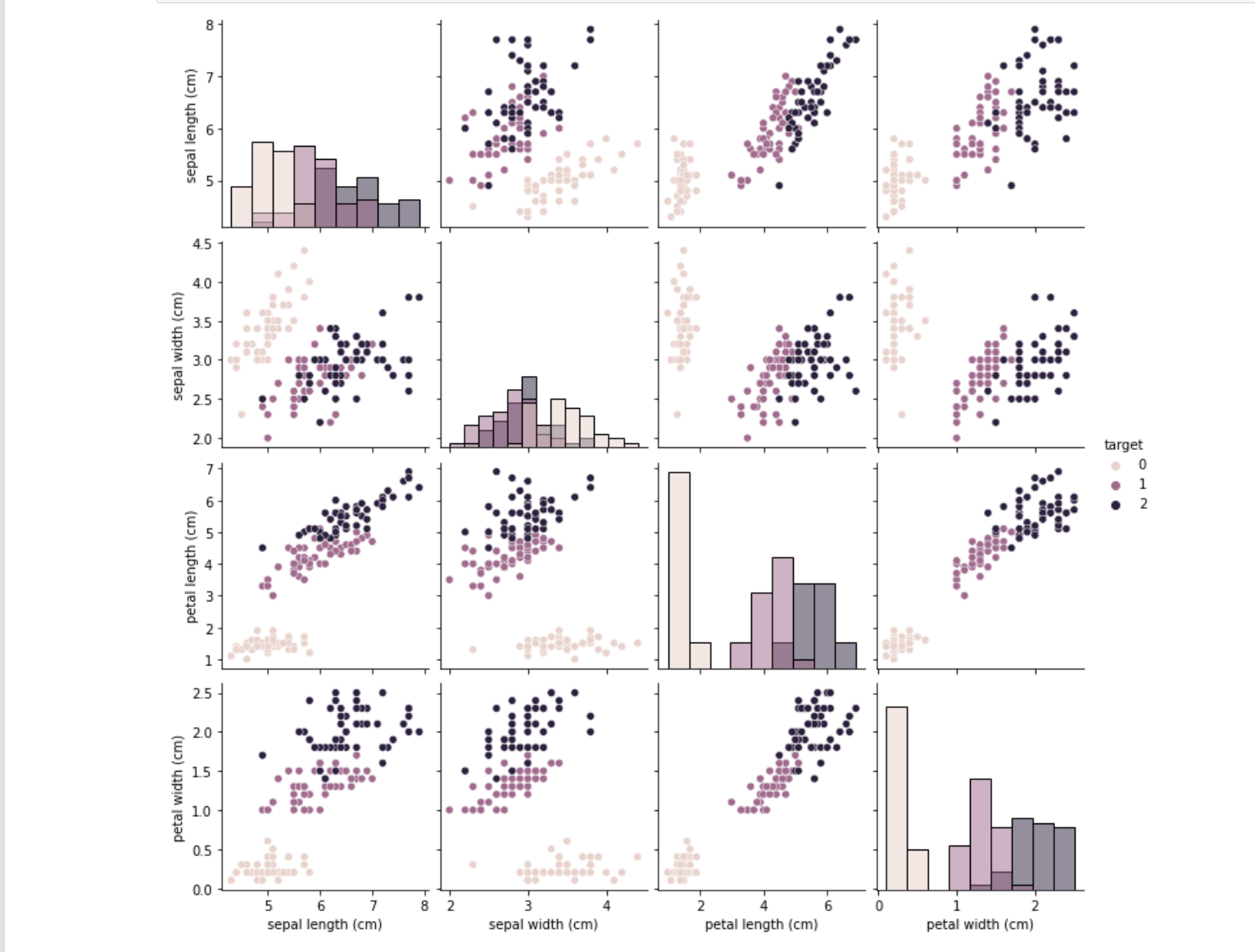
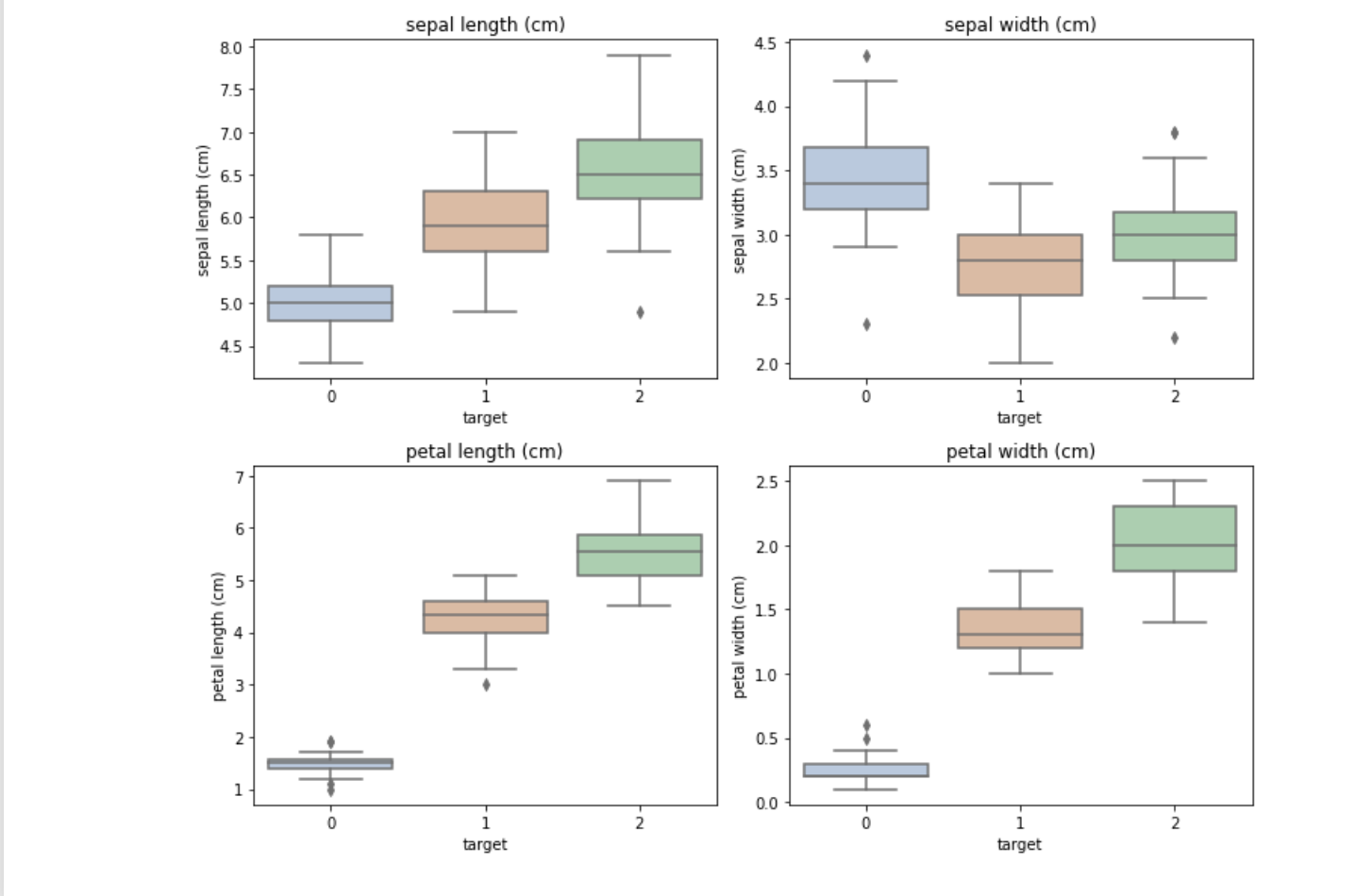
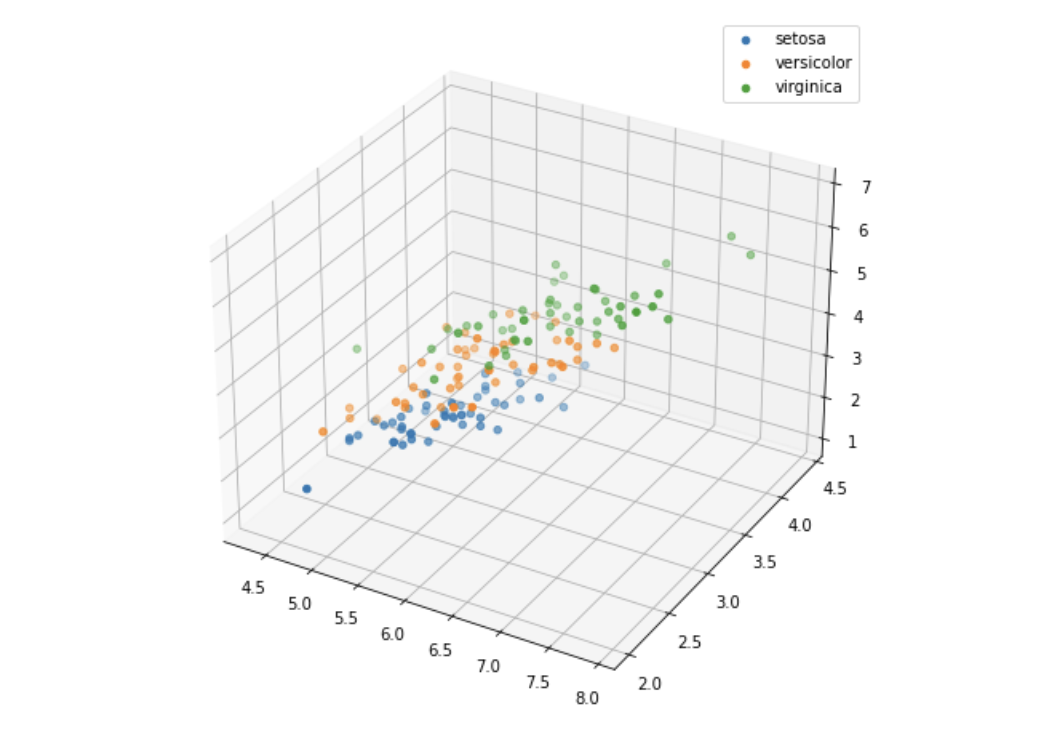
从结果可以发现,在2D情况下不同的特征组合对于不同类别的花的散点分布,以及大概的区分能力。 3.2 箱线图 ## 构建画布2x2 import matplotlib.pyplot as plt fig, axes = plt.subplots(nrows=2, ncols=2, figsize=(10, 8)) ## 可视化 for i, col in enumerate(iris_features.columns): sns.boxplot(ax=axes[i//2, i%2], x='target', y=col, saturation=0.5, palette='pastel', data=iris_all) axes[i//2, i%2].set_title(col) plt.tight_layout() plt.show()
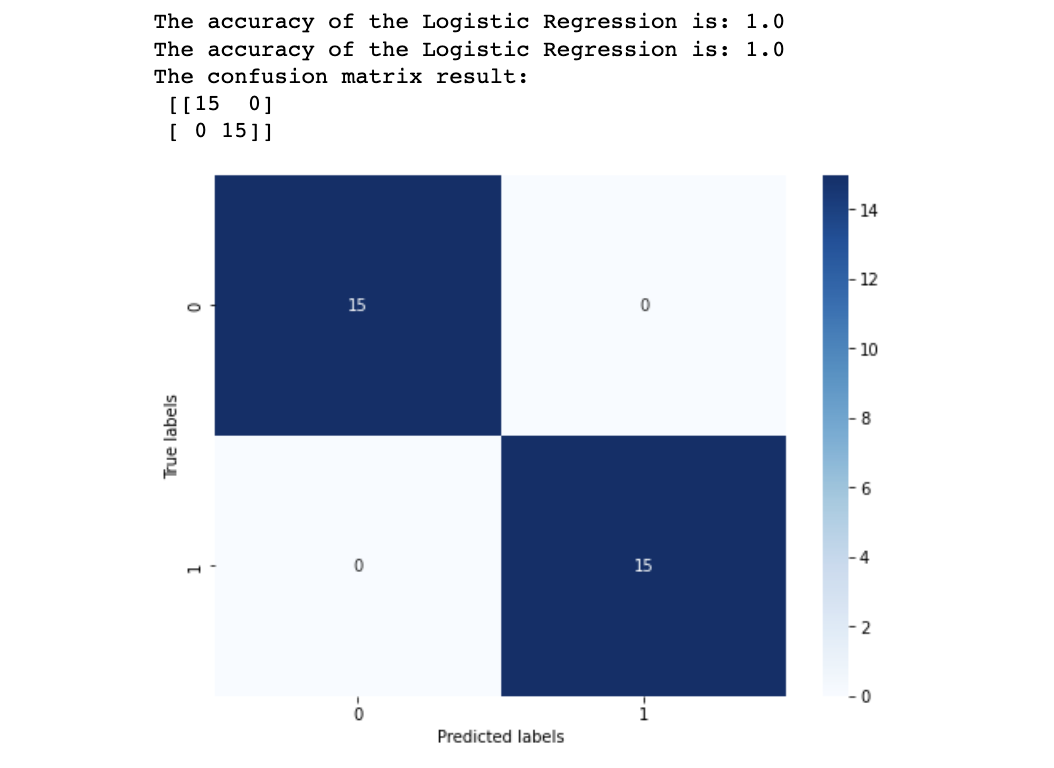
结果准确度为1,代表所有的样本都预测正确了,绝杀 4.2 多分类预测 ## 训练集测试集还是7/3分 x_train, x_test, y_train, y_test = train_test_split(iris_features, iris_target, test_size = 0.3, random_state = 2020) ## 建模 clf = LogisticRegression(random_state=0, solver='lbfgs') ## 训练模型 clf.fit(x_train, y_train)
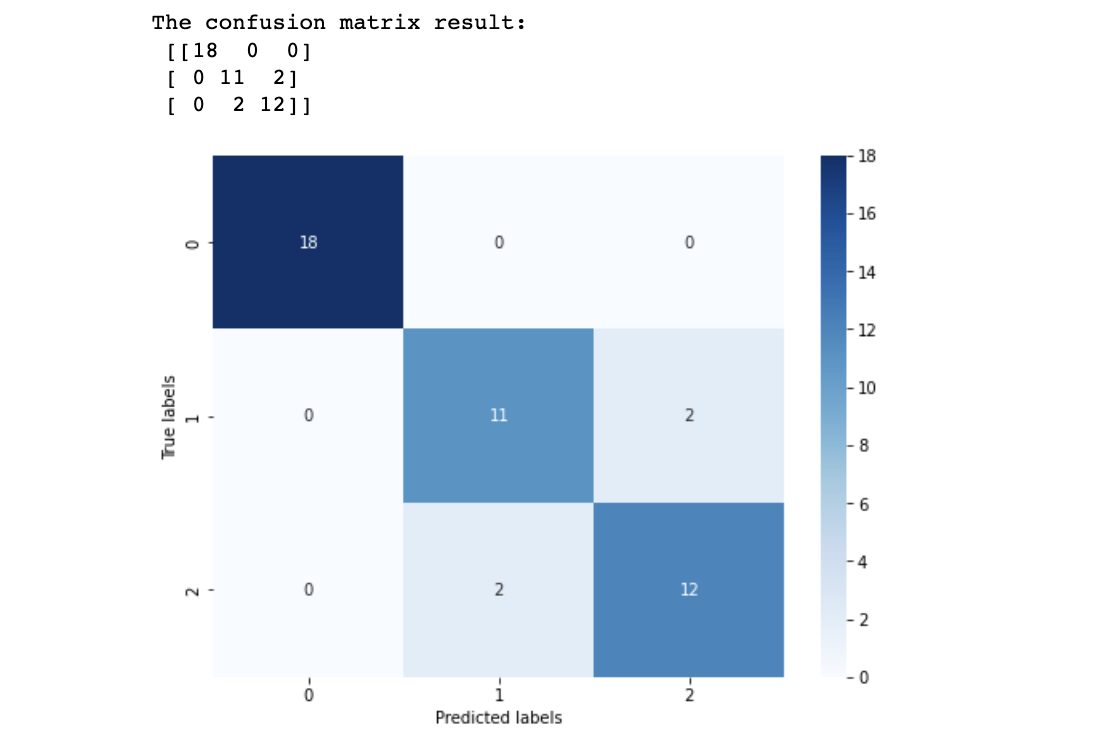
比起二分类的1略小,但均大于0.9 ## 查看混淆矩阵 confusion_matrix_result = metrics.confusion_matrix(test_predict,y_test) print('The confusion matrix result:\n',confusion_matrix_result) # 可视化 plt.figure(figsize=(8, 6)) sns.heatmap(confusion_matrix_result, annot=True, cmap='Blues') plt.xlabel('Predicted labels') plt.ylabel('True labels') plt.show()
根据结果发现,其在三分类的结果的预测准确度上有所下降,但好在测试集还有91%,这是由于versicolor(1)和 virginica(2)这两个类别的特征,我们从可视化的时候也可以发现,其特征的边界具有一定的模糊性(边界类别混杂,没有明显区分边界),所有在这两类的预测上出现了一定的错误。 5 讨论Logistic回归虽然名字里带“回归”,但是它实际上是一种分类方法,主要用于两分类问题(即输出只有两种,分别代表两个类别),所以利用了Logistic函数(或称为Sigmoid函数) 原理的简单解释:当z=>0时, y=>0.5,分类为1,当z |



【本文地址】
今日新闻 |
推荐新闻 |