【2024第一期CANN训练营】Ascend C算子开发进阶篇 |
您所在的位置:网站首页 › 进阶集训答案 › 【2024第一期CANN训练营】Ascend C算子开发进阶篇 |
【2024第一期CANN训练营】Ascend C算子开发进阶篇
|
文章目录
【2024第一期CANN训练营】Ascend C算子开发进阶篇1. 工程创建2. Kernel侧核函数实现2.1 核函数定义(add_custom.cpp)2.2 KernelAdd类实现
3. Host侧算子实现(add_custom_tiling.h ,add_custom.cpp)3.1 Tiling定义(add_custom_tiling.h )3.2 Tiling实现(add_custom.cpp)3.3 Shape推导函数实现(add_custom.cpp)3.4 算子原型注册(add_custom.cpp)
4. 算子编译部署(CMakePresets.json)5. 单算子调用(AclNNInvocation)5.1 准备验证代码工程5.2 单算子调用流程(op_runner.cpp)5.4 CMakeLists文件配置(CMakeLists.txt)5.5 数据生成(gen_data.py )5.6 编译与运行(run.sh)
【2024第一期CANN训练营】Ascend C算子开发进阶篇
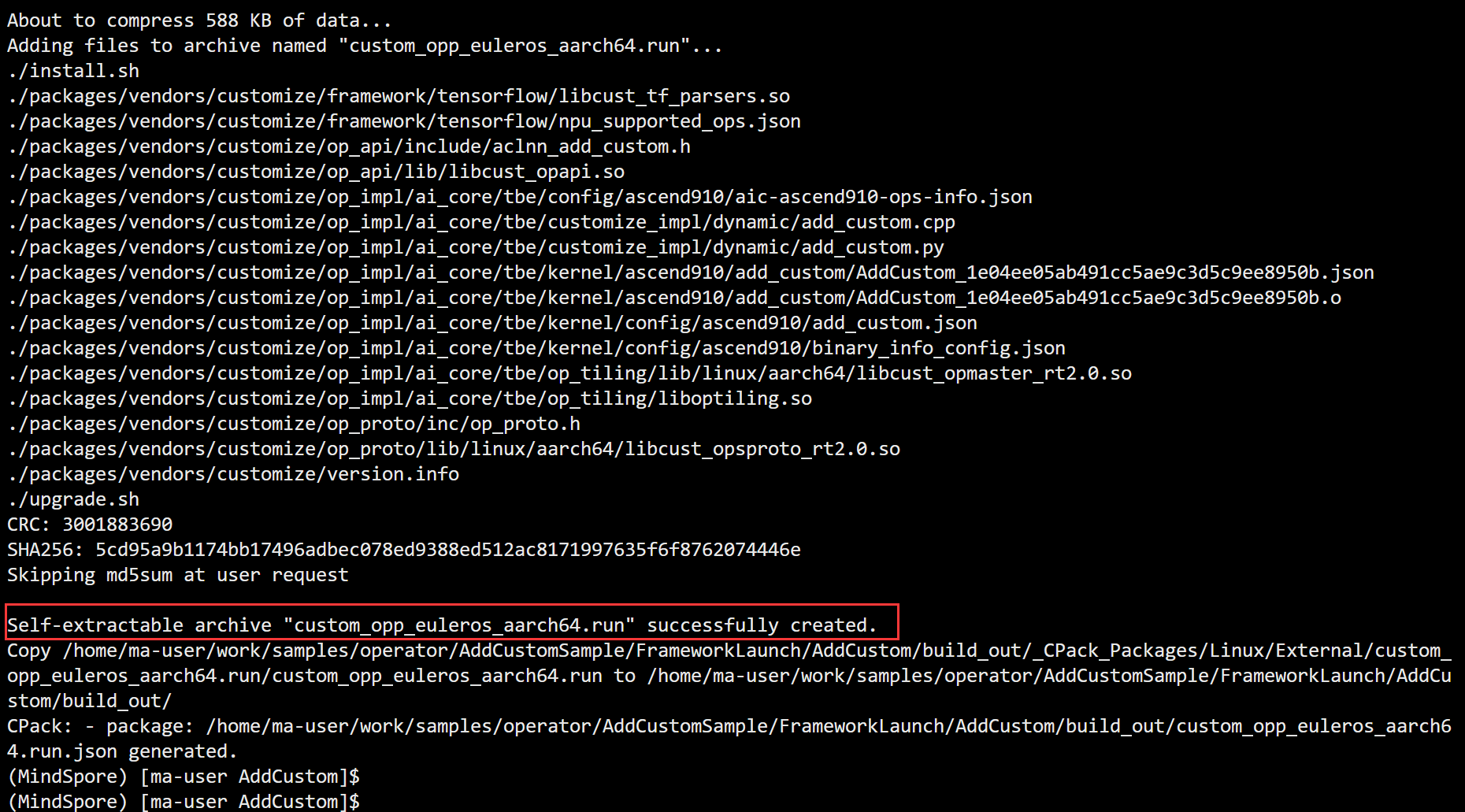
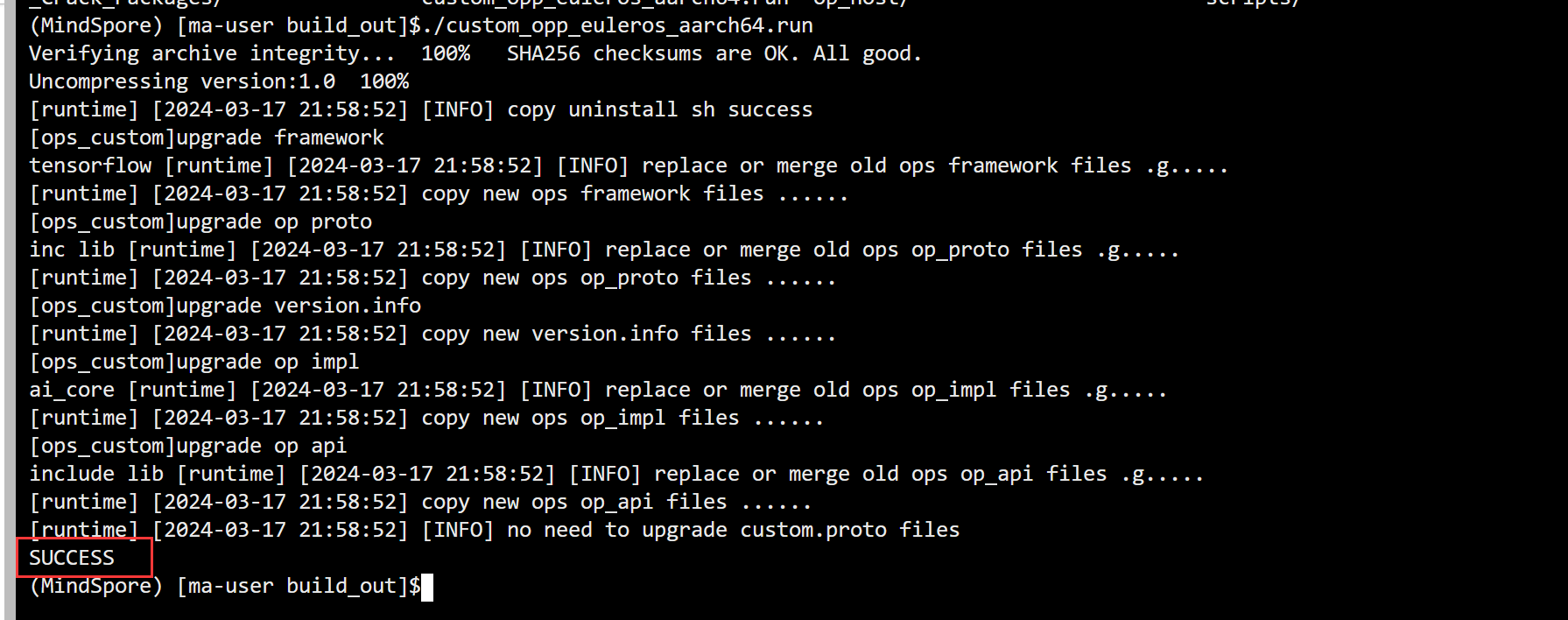
相比基础篇的算子开发,实际中的算子开发场景会更为灵活和复杂:算子的输入shape等信息不是固定不变的,开发者需要根据此信息来决定数据的并行切分策略,也就是需要写Tiling算法;算子开发完成后要完成单算子调用和网络中调用,不再局限于的基础调用。 本篇内容将会介绍标准的算子开发流程,完成一个实际场景下的算子开发,包括工程创建、算子核函数实现、Host侧算子实现、算子工程编译部署以及单算子调用。我们将以一个简单的Add算子为例,定义算子类型为AddCustom,以展示动态shape的算子开发过程。 1. 工程创建首先,我们需要创建一个新的Ascend C算子开发工程。CANN软件包中提供了工程创建工具msopgen,可以基于算子原型定义文件生成工程。 编写AddCustom算子的原型定义JSON文件。例如,创建一个名为add_custom.json的文件,内容如下: [ { "op": "AddCustom", "input_desc": [ { "name": "x", "param_type": "required", "format": ["ND"], "type": ["fp16"] }, { "name": "y", "param_type": "required", "format": ["ND"], "type": ["fp16"] } ], "output_desc": [ { "name": "z", "param_type": "required", "format": ["ND"], "type": ["fp16"] } ] } ]使用msopgen工具生成AddCustom算子的开发工程: ${INSTALL_DIR}/python/site-packages/bin/msopgen gen -i $HOME/sample/add_custom.json -c ai_core- -lan cpp -out $HOME/sample/AddCustom替换为你的昇腾AI处理器型号,例如Ascend910A。 下面是msopgen生成的开发目录 依次对以下5个文件进行开发:add_custom.cpp ,add_custom_tiling.h ,add_custom.cpp,CMakePresets.json,gen_data.py AddCustom ├── build.sh // 编译入口脚本 ├── cmake │ ├── config.cmake │ ├── util // 算子工程编译所需脚本及公共编译文件存放目录 ├── CMakeLists.txt // 算子工程的CMakeLists.txt ├── CMakePresets.json // 4.编译配置项 ├── framework // 算子插件实现文件目录,单算子模型文件的生成不依赖算子适配插件,无需关注 ├── op_host // host侧实现文件 │ ├── add_custom_tiling.h // 2.算子tiling定义文件 │ ├── add_custom.cpp // 3.算子原型注册、shape推导、信息库、tiling实现等内容文件 │ ├── CMakeLists.txt ├── op_kernel // kernel侧实现文件 │ ├── CMakeLists.txt │ ├── add_custom.cpp // 1.算子核函数实现文件 ├── scripts // 自定义算子工程打包相关脚本所在目录 │ ├── gen_data.py // 5.输入数据和真值数据生成脚本文件 │ ├── verify_result.py // 验证输出数据和真值数据是否一致的验证脚本 2. Kernel侧核函数实现 2.1 核函数定义(add_custom.cpp) extern "C" __global__ __aicore__ void add_custom(GM_ADDR x, GM_ADDR y, GM_ADDR z, GM_ADDR workspace, GM_ADDR tiling) { // 获取Host侧传入的Tiling参数 GET_TILING_DATA(tilingData, tiling); // 初始化算子类 KernelAdd op; // 算子类的初始化函数 op.Init(x, y, z, tilingData.totalLength, tilingData.tileNum); if (TILING_KEY_IS(1)) { // 完成算子实现的核心逻辑 op.Process(); } } 2.2 KernelAdd类实现定义KernelAdd类,包含初始化、核心处理和流水任务实现。 class KernelAdd { public: __aicore__ inline KernelAdd() {} // 初始化函数,完成内存初始化相关操作 __aicore__ inline void Init(GM_ADDR x, GM_ADDR y, GM_ADDR z, uint32_t totalLength, uint32_t tileNum) { // 使用获取到的TilingData计算得到singleCoreSize(每个核上总计算数据大小)、tileNum(每个核上分块个数)、singleTileLength(每个分块大小)等变量 ASSERT(GetBlockNum() != 0 && "block dim can not be zero!"); this->blockLength = totalLength / GetBlockNum(); this->tileNum = tileNum; ASSERT(tileNum != 0 && "tile num can not be zero!"); this->tileLength = this->blockLength / tileNum / BUFFER_NUM; // 获取当前核的起始索引 xGm.SetGlobalBuffer((__gm__ DTYPE_X*)x + this->blockLength * GetBlockIdx(), this->blockLength); yGm.SetGlobalBuffer((__gm__ DTYPE_Y*)y + this->blockLength * GetBlockIdx(), this->blockLength); zGm.SetGlobalBuffer((__gm__ DTYPE_Z*)z + this->blockLength * GetBlockIdx(), this->blockLength); // 通过Pipe内存管理对象为输入输出Queue分配内存 pipe.InitBuffer(inQueueX, BUFFER_NUM, this->tileLength * sizeof(DTYPE_X)); pipe.InitBuffer(inQueueY, BUFFER_NUM, this->tileLength * sizeof(DTYPE_Y)); pipe.InitBuffer(outQueueZ, BUFFER_NUM, this->tileLength * sizeof(DTYPE_Z)); } // 核心处理函数,实现算子逻辑,调用私有成员函数CopyIn、Compute、CopyOut完成矢量算子的三级流水操作 __aicore__ inline void Process() { int32_t loopCount = this->tileNum * BUFFER_NUM; for (int32_t i = 0; i tileLength], this->tileLength); DataCopy(yLocal, yGm[progress * this->tileLength], this->tileLength); // 将LocalTesor放入VECIN(代表矢量编程中搬入数据的逻辑存放位置)的Queue中 inQueueX.EnQue(xLocal); inQueueY.EnQue(yLocal); } // 计算函数,完成Compute阶段的处理,被核心Process函数调用 __aicore__ inline void Compute(int32_t progress) { // 将Tensor从队列中取出,用于后续计算 LocalTensor xLocal = inQueueX.DeQue(); LocalTensor yLocal = inQueueY.DeQue(); // 从Queue中分配输出Tensor LocalTensor zLocal = outQueueZ.AllocTensor(); // 调用Add接口进行计算 Add(zLocal, xLocal, yLocal, this->tileLength); // 将计算结果LocalTensor放入到VecOut的Queue中 outQueueZ.EnQue(zLocal); // 释放输入Tensor inQueueX.FreeTensor(xLocal); inQueueY.FreeTensor(yLocal); } // 搬出函数,完成CopyOut阶段的处理,被核心Process函数调用 __aicore__ inline void CopyOut(int32_t progress) { // 从VecOut的Queue中取出输出Tensor LocalTensor zLocal = outQueueZ.DeQue(); // 将输出Tensor拷贝到GlobalTensor中 DataCopy(zGm[progress * this->tileLength], zLocal, this->tileLength); // 将不再使用的LocalTensor释放 outQueueZ.FreeTensor(zLocal); } private: //Pipe内存管理对象 TPipe pipe; //输入数据Queue队列管理对象,QuePosition为VECIN TQue inQueueX, inQueueY; //输出数据Queue队列管理对象,QuePosition为VECOUT TQue outQueueZ; //管理输入输出Global Memory内存地址的对象,其中xGm, yGm为输入,zGm为输出 GlobalTensor xGm; GlobalTensor yGm; GlobalTensor zGm; // 每个核上总计算数据大小 uint32_t blockLength; // 每个核上总计算数据分块个数 uint32_t tileNum; // 每个分块大小 uint32_t tileLength; }; 3. Host侧算子实现(add_custom_tiling.h ,add_custom.cpp)完成核函数开发后,需要在Host侧实现算子的Tiling和原型注册。 3.1 Tiling定义(add_custom_tiling.h )修改add_custom_tiling.h文件,定义Tiling参数。 #ifndef ADD_CUSTOM_TILING_H #define ADD_CUSTOM_TILING_H #include "register/tilingdata_base.h" namespace optiling { BEGIN_TILING_DATA_DEF(TilingData) // 注册一个tiling的类,以tiling的名字作为入参 TILING_DATA_FIELD_DEF(uint32_t, totalLength); // 添加tiling字段,总计算数据量 TILING_DATA_FIELD_DEF(uint32_t, tileNum); // 添加tiling字段,每个核上总计算数据分块个数 END_TILING_DATA_DEF; // 注册算子tilingdata类到对应的AddCustom算子 REGISTER_TILING_DATA_CLASS(AddCustom, TilingData) } #endif 3.2 Tiling实现(add_custom.cpp)大多数情况下,Local Memory的存储,无法完整的容纳算子的输入与输出,需要每次搬运一部分输入进行计算然后搬出,再搬运下一部分输入进行计算,直到得到完整的最终结果,这个数据切分、分块计算的过程称之为Tiling。根据算子的shape等信息来确定数据切分算法相关参数(比如每次搬运的块大小,以及总共循环多少次)的计算程序,称之为Tiling实现。 TilingData、block_dim、TilingKey、workspace这些概念的具体解释如下: **TilingData:**切分算法相关参数,比如每次搬运的块大小,以及总共循环多少次,通过结构体存储,由开发者自行设计。**block_dim:**算子数据切分的份数。例如,需要计算8M的数据,每个核上计算1M的数据,block_dim设置为8,但是为了充分利用硬件资源,一般将block_dim设置为硬件平台的核数,根据核数进行数据切分。TilingKey(可选):不同的kernel实现分支可以通过TilingKey来标识,host侧设置TilingKey后,可以选择对应的分支。例如,一个算子在不同的shape下,有不同的算法逻辑,kernel侧可以通过TilingKey来选择不同的算法逻辑,在host侧Tiling算法也有差异,host/kernel侧通过相同的TilingKey进行关联。workspace size(可选):workspace是设备侧Global Memory上的一块内存。在Tiling函数中可以设置workspace的大小,框架侧会为其在申请对应大小的设备侧Global Memory,在对应的算子kernel侧实现时可以使用这块workspace内存。 namespace optiling { const uint32_t BLOCK_DIM = 8; const uint32_t TILE_NUM = 8; static ge::graphStatus TilingFunc(gert::TilingContext* context){ TilingData tiling; uint32_t totalLength = context->GetInputTensor(0)->GetShapeSize(); // 设置每个块的维度,设置TilingData context->SetBlockDim(BLOCK_DIM); tiling.set_totalLength(totalLength); // 设置总计算数据量 tiling.set_tileNum(TILE_NUM); // 设置每个核上的tile数量 // 将TilingData实例序列化并保存到TilingContext中,以便后续在kernel侧使用。 tiling.SaveToBuffer(context->GetRawTilingData()->GetData(), context->GetRawTilingData()->GetCapacity()); context->GetRawTilingData()->SetDataSize(tiling.GetDataSize()); // 设置TilingKey(可选),用于选择kernel实现分支 context->SetTilingKey(1); // 设置workspace大小(可选) // 如果需要在设备侧Global Memory上分配workspace内存,可以通过GetWorkspaceSizes获取大小指针并设置。 size_t *currentWorkspace = context->GetWorkspaceSizes(1); currentWorkspace[0] = 0; return ge::GRAPH_SUCCESS; } } 3.3 Shape推导函数实现(add_custom.cpp)网络模型中的Shape推导和dtype推导 在实际的网络模型生成过程中,除了算子的调用,还需要进行Tensor的shape和数据类型(dtype)的推导。推导的目的是为了在图执行之前确定各个Tensor的数据类型和形状,这样可以提前校验其正确性,并为算子的输出张量描述提供信息,包括形状、数据类型和数据排布格式。通过提前推理出算子的输出张量描述,可以在算子构图准备阶段为所有张量静态分配内存,从而避免动态内存分配带来的性能开销。AddCustom算子的InferShape实现 输出Tensor z的描述信息与输入Tensor x,y的描述信息相同,因此可以直接将任意一个输入Tensor的描述赋给输出Tensor。InferShape函数的实现代码如下: namespace ge { static graphStatus InferShape(gert::InferShapeContext* context) { const auto inputShape = context->GetInputShape(0); // 获取输入Tensor的形状 auto outputShape = context->GetOutputShape(0); // 获取输出Tensor的形状 *outputShape = *inputShape; // 将输入形状赋给输出形状 return GRAPH_SUCCESS; // 返回成功状态 } } 3.4 算子原型注册(add_custom.cpp)算子原型注册主要描述了算子的输入输出、属性等信息,以及算子在AI处理器上的相关实现信息。它还关联了Tiling实现、Shape推导等函数。这个过程对于确保算子能够正确地处理数据并在AI处理器上高效执行至关重要。 算子原型定义包括了算子的输入输出描述、数据类型、格式和属性等信息。例如,Add算子的输入x的描述信息包括它是必选的(ParamType REQUIRED),支持的数据类型(DataType),以及支持的格式(Format)。 在add_custom.cpp文件中注册算子原型。 namespace ops { class AddCustom : public OpDef { public: explicit AddCustom(const char* name) : OpDef(name){ this->Input("x") .ParamType(REQUIRED) .DataType({ge::DT_FLOAT16}) .Format({ge::FORMAT_ND}) .UnknownShapeFormat({ge::FORMAT_ND}); this->Input("y") .ParamType(REQUIRED) .DataType({ge::DT_FLOAT16}) .Format({ge::FORMAT_ND}) .UnknownShapeFormat({ge::FORMAT_ND}); this->Output("z") .ParamType(REQUIRED) .DataType({ge::DT_FLOAT16}) .Format({ge::FORMAT_ND}) .UnknownShapeFormat({ge::FORMAT_ND}); this->SetInferShape(ge::InferShape); this->AICore() .SetTiling(optiling::TilingFunc); this->AICore().AddConfig("ascend910"); } }; OP_ADD(AddCustom); } 4. 算子编译部署(CMakePresets.json)编译AddCustom工程,生成自定义算子安装包,并将其安装到算子库中。 修改CMakePresets.json中的ASCEND_CANN_PACKAGE_PATH为CANN软件包安装路径。 "ASCEND_CANN_PACKAGE_PATH": { "type": "PATH", "value": "/usr/local/Ascend/latest" // 替换为CANN软件包安装后的实际路径 }, "CMAKE_CROSS_PLATFORM_COMPILER": { // 替换为交叉编译工具安装后的实际路径 "type": "PATH", "value": "/usr/bin/aarch64-linux-gnu-g++" } 在算子工程目录下执行./build.sh命令进行编译。成功后,将在build_out目录下生成自定义算子安装包。 ./build.sh
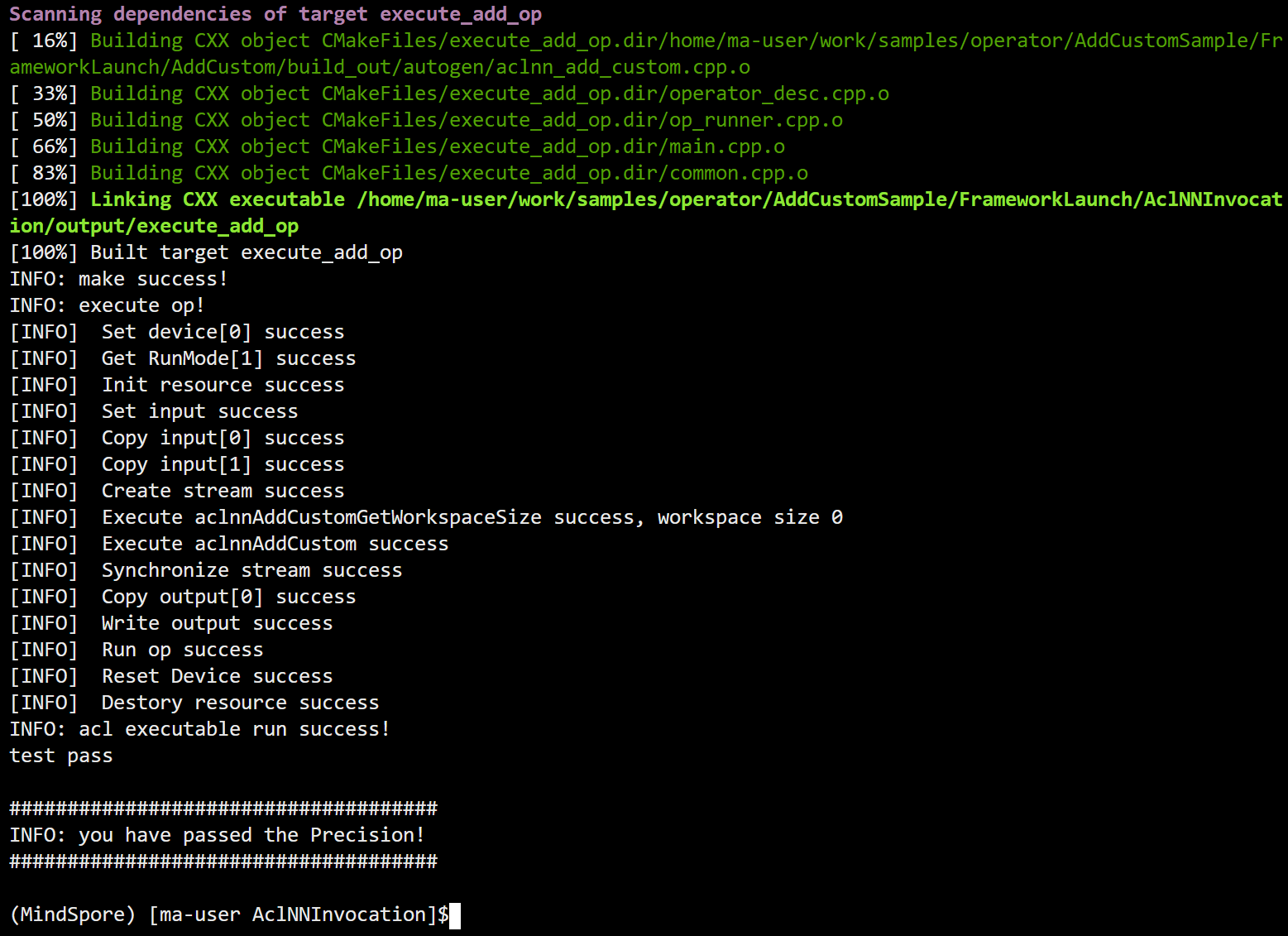
代码工程目录结构如下,您可以单击LINK,获取样例工程的完整样例: 依次修改op_runner.cpp,CMakeLists.txt,gen_data.py即可 ├──input // 存放脚本生成的输入数据目录 ├──output // 存放算子运行输出数据和真值数据的目录 ├── inc // 头文件目录 │ ├── common.h // 声明公共方法类,用于读取二进制文件 │ ├── operator_desc.h // 算子描述声明文件,包含算子输入/输出,算子类型以及输入描述与输出描述 │ ├── op_runner.h // 算子运行相关信息声明文件,包含算子输入/输出个数,输入/输出大小等 ├── src │ ├── CMakeLists.txt // 2.编译规则文件 │ ├── common.cpp // 公共函数,读取二进制文件函数的实现文件 │ ├── main.cpp // 将单算子编译为om文件并加载om文件执行 │ ├── operator_desc.cpp // 构造算子的输入与输出描述 │ ├── op_runner.cpp // 1.单算子编译与运行函数实现文件 ├── scripts │ ├── verify_result.py // 真值对比文件 │ ├── gen_data.py // 3.输入数据和真值数据生成脚本文件 │ ├── acl.json // acl配置文件 5.2 单算子调用流程(op_runner.cpp) 头文件导入:编写单算子的调用代码时,要包含自动生成的单算子API执行接口头文件。 #include "aclnn_add_custom.h" AscendCL初始化:执行此步骤以初始化AscendCL环境,为后续的算子调用和资源管理做准备。运行管理资源申请:在此阶段,您需要设置设备ID并获取当前运行模式,这将影响后续接口调用流程(如数据传输等)。申请内存存放算子的输入输出:为算子的输入和输出数据申请内存空间,确保算子可以正常读写数据。传输数据:将主机内存中的数据传输到设备内存,以便算子可以在设备上进行计算。计算workspace大小并申请内存:通过调用算子API的GetWorkspaceSize接口来确定执行算子所需的workspace大小,并据此申请相应的内存。 size_t workspaceSize = 0; aclOpExecutor *handle = nullptr; auto ret = aclnnAddCustomGetWorkspaceSize(inputTensor_[0], inputTensor_[1], outputTensor_[0], &workspaceSize, &handle); 执行算子:调用算子API的执行接口,开始算子的实际计算过程。 if (aclnnAddCustom(workspace, workspaceSize, handle, stream) != ACL_SUCCESS) { (void)aclrtDestroyStream(stream); ERROR_LOG("Execute Operator failed. error code is %d", static_cast(ret)); return false; } 同步等待:在计算完成后,使用同步操作等待所有计算任务完成,确保数据的完整性和准确性。处理执行算子后的输出数据:根据应用需求,对算子的输出数据进行后续处理,如显示、存储或其他分析。释放运行管理资源:在算子执行完毕后,释放之前申请的设备资源,维护系统的稳定性和性能。AscendCL去初始化:最后,结束AscendCL环境,确保资源得到正确释放,避免潜在的资源泄露问题。 5.4 CMakeLists文件配置(CMakeLists.txt) 设置AUTO_GEN_PATH变量:确保该变量正确指向算子工程的build_out/autogen目录,这是为了CMake能够找到自动生成的单算子API执行接口头文件和源文件。 set(AUTO_GEN_PATH "../../AddCustom/build_out/autogen") 增加头文件搜索路径:在CMakeLists.txt中,添加include_directories指令,将AUTO_GEN_PATH变量所指向的目录加入到头文件的搜索路径中,以便编译器能够找到并包含这些自动生成的头文件。 include_directories( ${AUTO_GEN_PATH} ) 生成可执行文件规则:在CMakeLists.txt中,使用add_executable指令来定义可执行文件的生成规则,包括目标名称和源文件列表。确保将自动生成的单算子API调用实现文件(如aclnn_add_custom.cpp)包含在内,以便链接成最终的可执行文件。 add_executable(execute_add_op ${AUTO_GEN_PATH}/aclnn_add_custom.cpp ) 链接nnopbase库:在CMakeLists.txt中,通过target_link_libraries指令将nnopbase库链接到您的可执行文件目标上。这是为了确保在运行时,程序能够正确链接到所需的库文件,从而能够调用单算子API。 target_link_libraries(execute_add_op nnopbase ) 5.5 数据生成(gen_data.py )以固定shape的add_custom算子为例,输入数据和真值数据生成的脚本样例如下:根据算子的输入输出编写脚本,生成输入数据和真值数据。 #!/usr/bin/python3 # -*- coding:utf-8__ # 版权所有 (c) 华为技术有限公司 2022-2023。 import numpy as np # 导入numpy库,用于科学计算 # 定义生成基准数据的函数 def gen_golden_data_simple(): # 生成两个大小为[8, 2048]的随机数矩阵,范围在[-100, 100]之间,数据类型为float16 input_x = np.random.uniform(-100, 100, [8, 2048]).astype(np.float16) input_y = np.random.uniform(-100, 100, [8, 2048]).astype(np.float16) # 计算两个矩阵的和,得到基准数据(golden data),数据类型为float16 golden = (input_x + input_y).astype(np.float16) # 将生成的输入矩阵input_x和input_y分别保存到二进制文件"./input/input_x.bin"和"./input/input_y.bin" # 将基准数据golden保存到二进制文件"./output/golden.bin",用于后续结果验证 input_x.tofile("./input/input_x.bin") input_y.tofile("./input/input_y.bin") golden.tofile("./output/golden.bin") if __name__ == "__main__": # 调用函数生成基准数据 gen_golden_data_simple() 5.6 编译与运行(run.sh) cd AclNNInvocation // 看到test pass则精度验证通过 bash run.sh
|
【本文地址】