除了AI换脸,深度学习在影视上还有哪些实际应用? |
您所在的位置:网站首页 › 还有什么换脸软件好用 › 除了AI换脸,深度学习在影视上还有哪些实际应用? |
除了AI换脸,深度学习在影视上还有哪些实际应用?
|
▲ 电影《阿凡达》中的表演捕捉
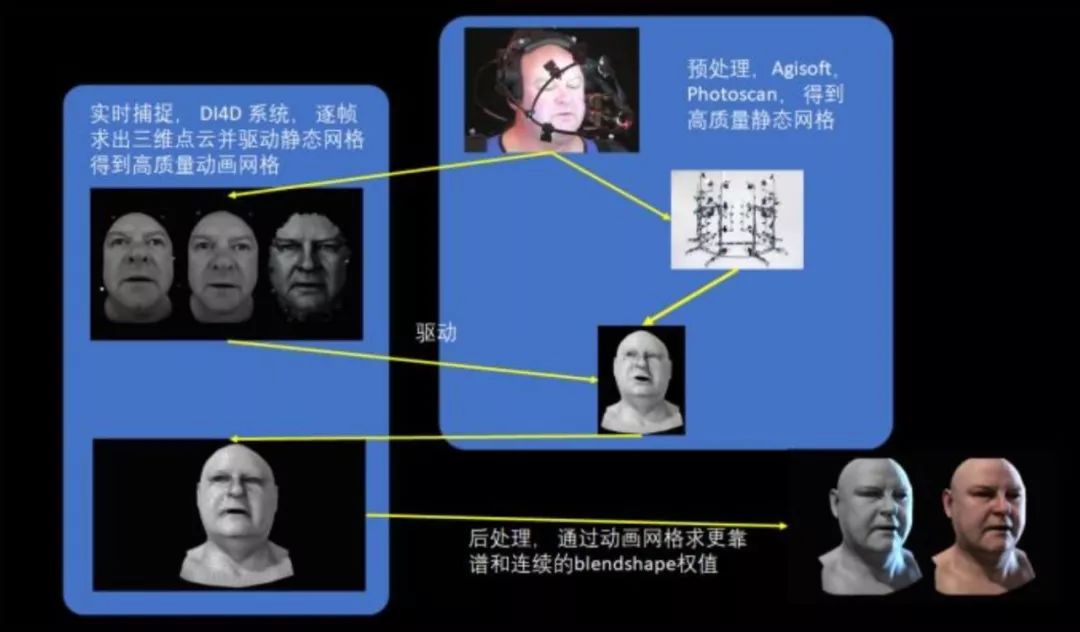
▲ 电影《阿丽塔》中的表情捕捉设备 这样的系统, 快准稳至关重要—— 一帧跳脱,所有前后帧都受牵连;艺术家是为了这几帧来手修,还是让演员为了这几帧来重新拍摄?! 既然讲到脸了, 我就再讲一个深度学习在影视级别特效中成功应用的例子,其中利用深度学习的方法和目的,恐怕跟大多数人想象得很不一样。 影视制作级表情捕捉, 有这么个专业系统被使用得比较多,它是—— DI4D PRO System。 它包括了几个标准的模块:数据捕捉、数据预处理,和数据后处理。
▲ 参考来源:Production-Level Facial Performance Capture Using Deep Convolutional Neural Networks, 章节1.2 先说数据捕捉,若要对一个人的表情进行实时表演捕捉,要先用一套离线系统(一套相机矩阵系统和软件PhotoScan)对演员面部进行数字扫描,然后离线从数字扫描的脸数据中建出“规则的网格”——我喜欢称它为“好Mesh”。 “好Mesh”需要网格的布线均匀、疏密得当,通常得混合利用不同工具,再加上人工制作才能得到。
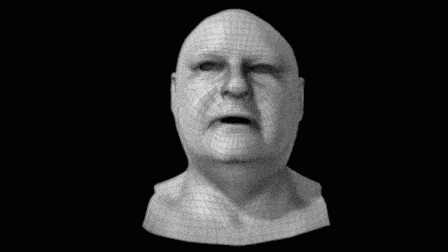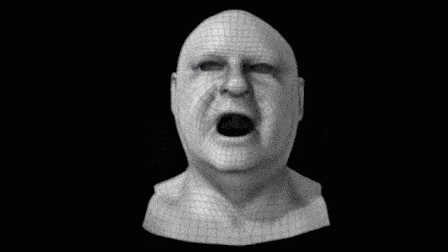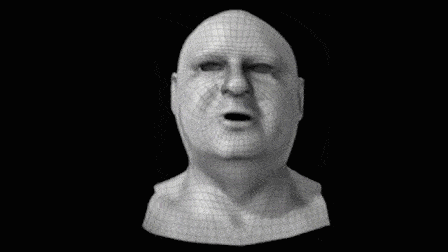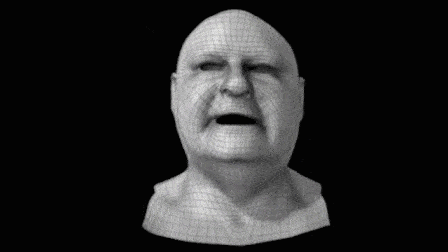
▲ 这是一个典型的“好Mesh” 然后, 用一种很传统的流程,实时拍下演员的面部动画,并基于深度相机等混合硬件构造出噪声很大的、逐帧的运动脸。 比如下图中的第三个:
可想而知,这样的脸是没法拿来用的,所以这个系统实际上最重要的一步是——将之前手工制得的“好Mesh”,与这个动画网格的第一帧拼接起来,再运用光流等混合技术手段来驱动手工网格的动画:
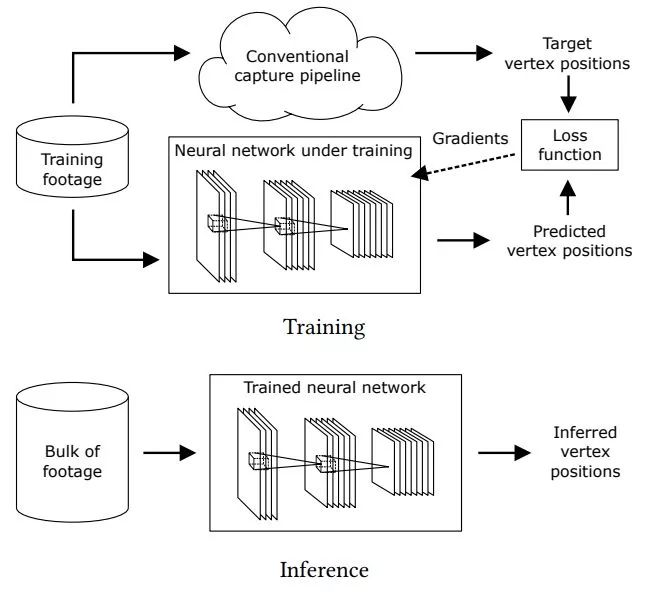
“好Mesh”每一个顶点的坐标,就是DI4D系统输出的最终结果——到此为止,没有任何深度学习在里面。 那么,在这项工作中, 深度学习到底是怎么被用起来的呢? 原来, 在“处理网格驱动”这一步骤中,由于光照/相机噪声等因素的存在,通常需要用人来大量手工清理驱动数据,否则会对结果带来十分糟糕的扰动。 如同论文中提出的:“我们先挑选出待处理数据中的一部分,做人工清理,然后训练一个深度神经网络,用来取代人力劳动,自动处理余下的数据。”
▲ 参考资料:论文原文 这样做的目的,就是把一个“不规则网格”映射到一个“规则网格”(好Mesh)。 处理过程如下:
在这个应用场景中,深度神经元网络的用法与大家以为的可能存在四点不同: 第一,这个网络只能专人专用, 换一个人就必须重新再训练。 用深度学习界的“行话”讲,就是——他们的算法,Overfit到了这一个演员身上。 Overfit(过拟合)指的是,如果一个训练得到的神经元网络,面对两个相似任务,在任务一表现优异、而任务二表现平平,则产生了过拟合。 过拟合是一般的深度学习都极力尝试避免的,于是就导致了得到的网络在所有任务上都表现“良好”。 面对这个特定应用场景,实际工程人员则不得不去犯“过拟合”的忌讳。即使让得到的网络无法做“由此及彼”的“智力推演”,也要让它成为针对一个特定任务“好用的苦力”。 在人工智能中,牺牲智能换取劳力,来满足影视制作对高品质的需求。 第二,这个网络的目的不是替代人类, 而是减少人类的重复性劳作。 第三,深度学习所用到的数据,都来自计算机的计算结果,而非源于实际采集数据。 数据输入端是计算机计算出的一个脏点云,输出端是经过人工挑选后,计算机再自动计算得到的规整网面计算机计算得出的一个规则网格。 最后,虽然此处用到了AI,但无法从本质上降低制作成本。因为它无论是训练数据、还是最后的应用,都是从一套十分昂贵的系统中来的。
“ 再一个能想到的是“抠图”。 目前最好的自动抠图(连头发丝和动态模糊都能抠好)是迪士尼在 Siggraph 2017提出的算法,这套算法不是基于深度学习技术的。 迪士尼这套系统带来的抠图效率提升,使得整个抠图流程所花费的时间降低到了原来10%。 通过下图,我们先来看下影视级自动抠图算法目前最好的呈现结果,这样的结果,深度学习算法极大可能做不出来:
抠图最难的地方是抠细节。 让艺术家抠一个原图和抠一个经过算法粗抠的图,要花费的时间没啥区别,所以深度学习必须做到“连头发丝都能抠好”这样的细节才足够实用,也才能被艺术家们用起来。 “ 然后是“场景建模”。 场景建模方面没啥好说的, 基于规则的程序化建模(Procedure Modeling)高效准确而且已经在影视业和游戏业用了很多年了。 以下两张图都是以这种方法自动建出来的城市,深度学习可能很难在这个领域再有革命性建树。
写到这里,我发现很多人喜欢把 自动化=AI=深度学习。 其实,自动化不等于AI、更不等于深度学习。 基于规则的算法给出的结果如果已经很好,就没有那么大的必要性去用深度学习。 “ 接下来谈“特效”。 计算特效领域,从科研角度讲,深度学习也在不断地尝试,但主要集中在辅助作用,而触碰不到核心的计算理论、算法,甚至程序。 因为在这个计算领域,核心诉求不是快或慢,而是“大”。 比如下面这个视频中的序列,仿真时每帧消耗掉用来存储每一个水粒子压强、速度、位置等物理信息的内存量就能高达200GB——注意,这是每帧数据量,数秒钟的仿真序列就能产生几十TB的序列。 仿真特效视频 >> 可能这单纯从数据量上就超出了很多深度学习系统的上限。 至于说解PDE(偏微分)方程用DL来解的朋友......我不完全说死,就说视情况而定吧; 而现实是,但凡能解出来的PDE方程,现有的数学解法一定都比DL的算法快准稳;但凡是解不出来的方程,就没有数据做训练...... 但DL+PDE这一块倒是有很多的工作在做,这些工作很有科学素养: 它不是着重于用DL来解方程,而是用DL来搜寻和探索混沌系统或宏/微观尺度的数学模型。 “ 在“角色动画”领域,强化学习其实很有前途。 但是对这一点,迪士尼的态度就有点暧昧: 迪士尼研究院虽然也做强化学习方面的研究,但最终变成“动画制作工具”的可能性,还不如“儿童玩具制作工具”来的更高...... 文末,我想就两点做下澄清: 第一,这里限定的是“影视”里使用的讨论, 至于游戏、手机应用、日常娱乐等领域,就欢迎读者发散思维、留言探讨了。 第二,我发现很多人误把“Siggraph 论文”等同于影视业就会用的技术、Siggraph的研究热点等同于影视技术研究的方向……这些完全不成立! Siggraph毕竟是一个科学性的学术会议,它的目标更任重道远;而且里面产生的技术,针对影视的只是一部分;对其它创意设计、图像处理、创意制造等行业,Siggraph也有着深远的影响。 一个技术实用与否、好用与否,都会有为期几个月、甚至数年的试错和论证在里头。Siggraph论文不一定就代表了影视业发展的方向,也不一定能暴露影视制作中的关键问题。 正确做法是,去听Siggraph的Production Session,听Disney、梦工厂、听(工业)光魔、Weta的人说他们制作流程中最后选用了什么技术、开发了怎样的代码和工具。 最后,我在这里也只是抛砖引玉,希望科研人员和实际影视/创意娱乐工作能有更多联系: 让实际问题被深度研究,科研成果用来更好的优化实际生产;相关企业发展出研发部门、学校孵化出优秀的创业项目。 ▼ 加入社群 / 转载事宜 / 商务合作返回搜狐,查看更多 |









【本文地址】
今日新闻 |
推荐新闻 |