Python实现过采样和欠采样 |
您所在的位置:网站首页 › 过采样和重采样 › Python实现过采样和欠采样 |
Python实现过采样和欠采样
|
B站账号@狼群里的小杨,记得点赞收藏加关注,一键三连哦!
过采样
1.过采样的原理
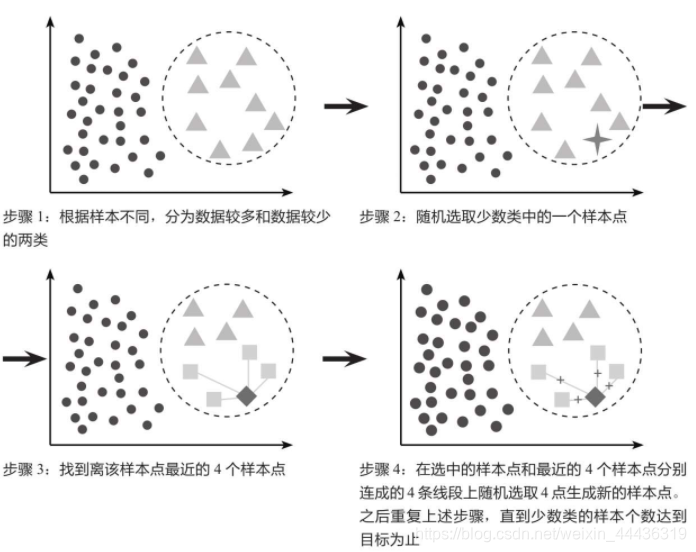
过采样的方法有随机过采样和SMOTE法过采样。 (1)随机过采样随机过采样是从100个违约样本中随机抽取旧样本作为一个新样本,共反复抽取900次,然后和原来的100个旧样本组合成新的1000个违约样本,和1000个不违约样本一起构成新的训练集。因为随机过采样重复地选取了违约样本,所以有可能造成对违约样本的过拟合。 (2)SMOTE法过采样SMOTE法过采样即合成少数类过采样技术,它是一种针对随机过采样容易导致过拟合问题的改进方案。假设对少数类进行4倍过采样,通过下图来讲解SMOTE法的原理。 使用SMOTE法进行过采样时,传入函数里面的数据必须都是数值类型,且不存在缺失值,即经过缺失值处理,数据转换、标准化或归一化之后的高质量数据才可以使用SMOTE否则就会出现报错 import pandas as pd from collections import Counter from imblearn.over_sampling import RandomOverSampler, SMOTE # 随机采样函数 和SMOTE过采样函数 data = pd.read_csv('数据.csv') print(data.info()) # 分别获取特征值和标签值 X = data.drop(columns='FLAG') y = data['FLAG'] # 对标签中的变量进行计数统计 print('原始标签数据统计:', Counter(y)) # 随机过采样方法 ros = RandomOverSampler(random_state=0) # random_state为0(此数字没有特殊含义,可以换成其他数字)使得每次代码运行的结果保持一致 X_oversampled, y_oversampled = ros.fit_resample(X, y) # 使用原始数据的特征变量和目标变量生成过采样数据集 print('随机过采样处理后', Counter(y_oversampled)) print(X_oversampled.info()) #随机采样后的特征数据信息 # SMOTE法过采样 smote = SMOTE(random_state=0) # random_state为0(此数字没有特殊含义,可以换成其他数字)使得每次代码运行的结果保持一致 X_smotesampled, y_smotesampled = smote.fit_resample(X, y) # 使用原始数据的特征变量和目标变量生成过采样数据集 print('Smote法过采样后', Counter(y_smotesampled)) 欠采样 1.欠采样的原理欠采样是从1000个不违约样本中随机选取100个样本,和100个违约样本一起构成新的训练集。欠采样抛弃了大部分不违约样本,在搭建模型时有可能产生欠拟合。 import pandas as pd from collections import Counter from imblearn.over_sampling import RandomUnderSampler, SMOTE # 随机欠采样函数 data = pd.read_csv('数据.csv') print(data.info()) # 分别获取特征值和标签值 X = data.drop(columns='FLAG') y = data['FLAG'] rus = RandomUnderSampler(random_state=0)# random_state为0(此数字没有特殊含义,可以换成其他数字),使得每次代码运行的结果保持一致 X_undersampled, y_undersampled = rus.fit_resample(X,y) # 使用原始数据的特征变量和目标变量生成欠采样数据集 print(Counter(y_undersampled)) print(X_undersampled.shape)在实战中处理样本不均衡问题时,如果样本数据量不大,通常使用过采样,因为这样能更好地利用数据,不会像欠采样那样很多数据都没有使用到;如果数据量充足,则过采样和欠采样都可以考虑使用。 |
【本文地址】
今日新闻 |
推荐新闻 |